







场景
第一次使用Intellij IDEA开发第一个spark应用程序?对 idea的操作相当不熟悉?听别人说spark高手更喜欢使用IDEA?
怎么在Intellij Idea导入 spark的源代码?使用 eclipse-scala阅读spark源代码相当不方便:没法在一个源文件中直接关联查询另一个源文件,必须另外从新ctrl+shift+t!
怎么编写脚本提交spark应用程序到spark集群中?
实验
实验环境
操作系统:Ubuntu Kylin 14.0.4
Intellij IDEA:Intellij IDEA 2016.1.1
JDK版本:1.8.0_77
scala版本:2.10.4
spark版本:1.6.0
第一个spark应用程序的开发
步骤
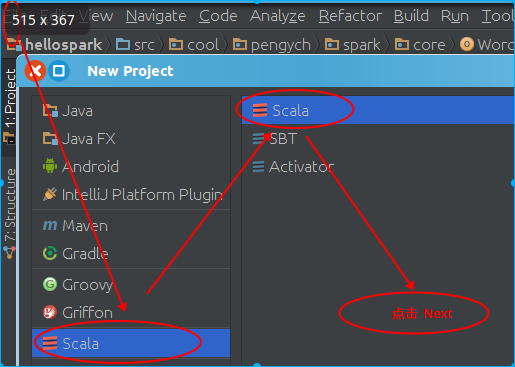
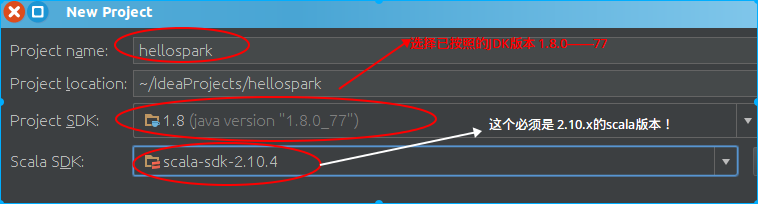
建一个新的项目
这里以新建一个名为hellospark的项目为例加以说明:
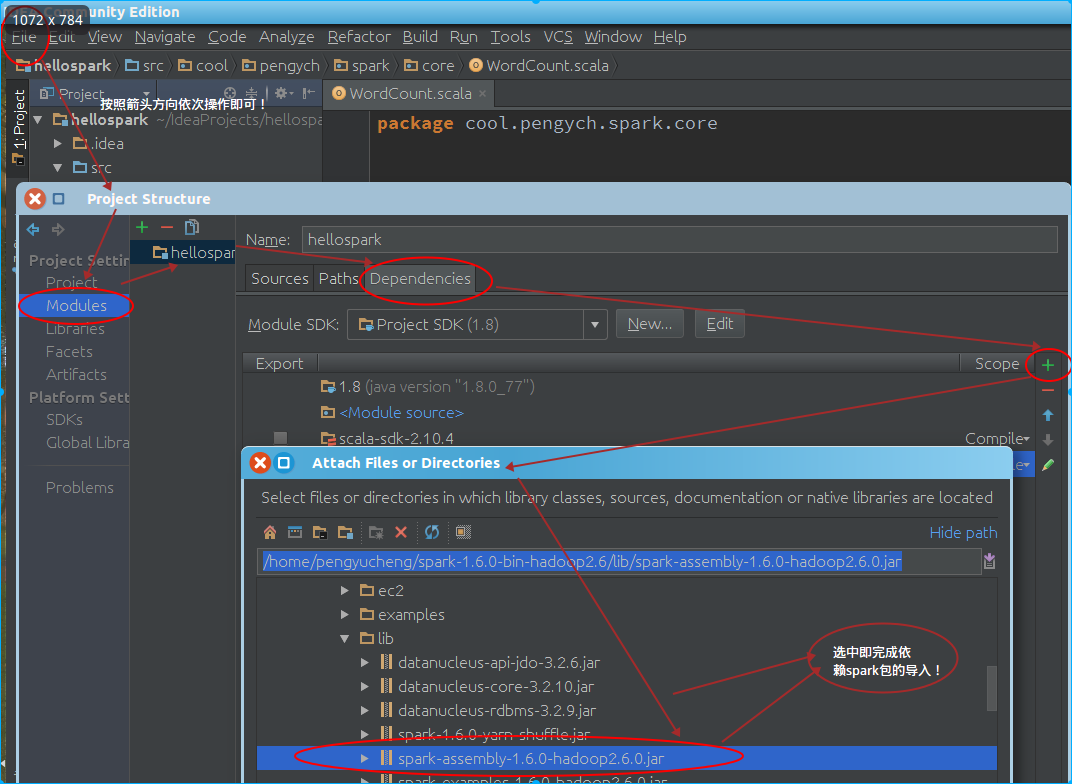
- 导入spark依赖包
- 编写wordcount应用程序
先建包,以 cool.pengych.spark.core为例:
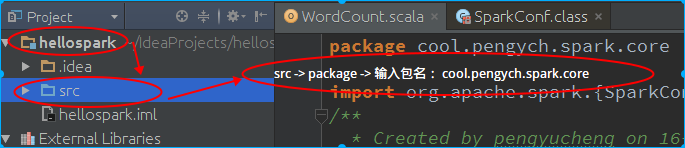
然后,选中包,鼠标右键 - New -> Scala Class -> 下拉框选择 object 输入对象名称: WordCount 。接下来编写 word count程序:
package cool.pengych.spark.core
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by pengyucheng on 16-4-28.
*/
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("my first spark app ")
val sc: SparkContext = new SparkContext(conf)
val lines = sc.textFile("hdfs://112.74.21.122:9000/input/test.log")
val words = lines.flatMap {line => line.split(" ") }
val pairs = words.map { word => (word,1) }
val wordCounts = pairs.reduceByKey(_+_).map(pair => (pair._2,pair._1)).sortByKey(false).map(pair => (pair._2,pair._1))
wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1 +":" + wordNumberPair._2))
sc.stop
}
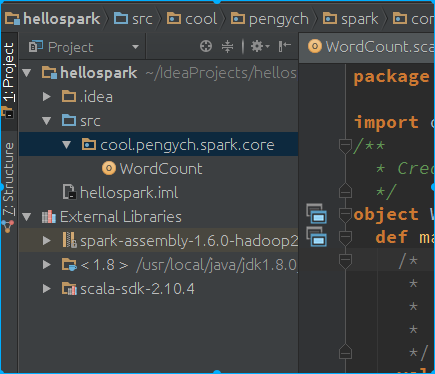
}此时的目录结构:
- 手动构建jar包
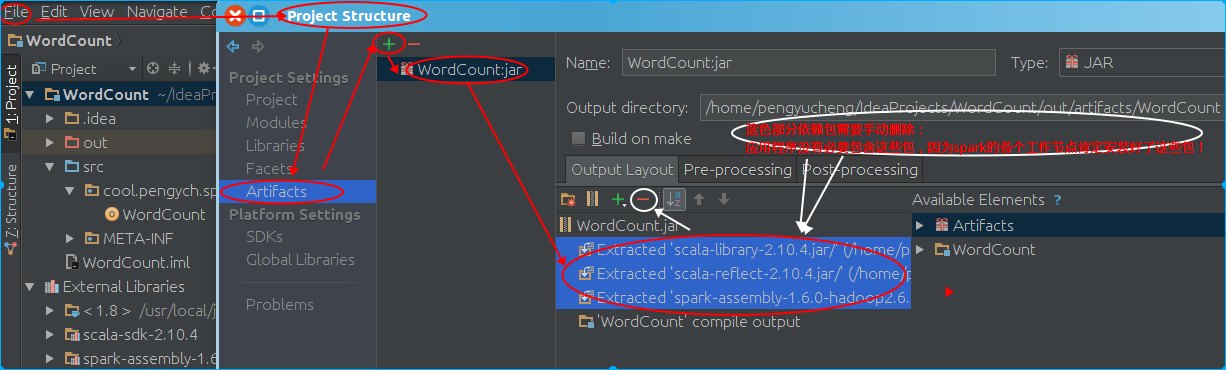
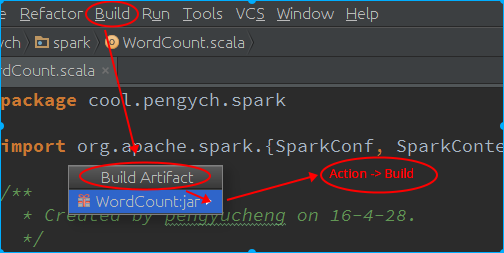
- 提交应用程序
这里假设把上面手动构建好的jar包,放在 /home/pengyucheng/resource目录下。这里假设你提交应用程序的机器的spark安装目录为:/home/hadoop/spark-1.6.0-bin-hadoop2.6且spark集群已经在运行了,master地址为:spark://sparker:7077。接下来在任意目录下,编写一个可执行脚本wordcount.sh,用于向spark集群提交该应用程序。脚本内容如下:
/home/hadoop/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class cool.pengych.spark.core.WordCount --master spark://sparker:7077 /home/pengyucheng/resource/WordCount.jar提交应用程序:
#./wordcount.sh
执行结果:

至此,成功的使用IDEA完成了第一个应用程序的开发与使用脚本提交到集群环境上运行!
源代码阅读环境搭建
编写好WordCount.scala应用程序后,如果想看看org.apache.spark.{SparkConf, SparkContext}等类的源文件怎么办呢? 当然,直接按下 ctrl+鼠标选中并点击会出现idea自动反编译后的源代码,但是没有注释,阅读相当费劲:

好,接下来我们开始导入spark源代码!
- 下载源代码
打开IntelliJ IDEA 后,在菜单栏中选择 VCS→Check out from Version Control→Git,之后在 Git Repository URL 中填入 Spark 项目的地址,并指定好本地路径,如下图所示:
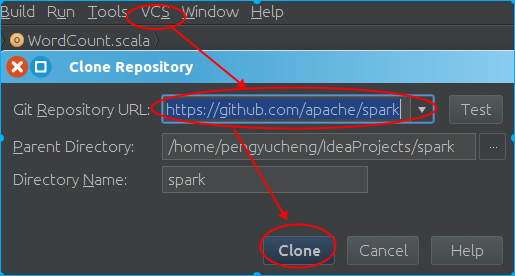
点击该窗口中的的 Clone 后,开始从 Github 中 clone 该项目,该过程试你网速而定,大概需要3-10分钟。
当 clone 完毕后,IntelliJ IDEA 会自动提示你该项目有对应的 pom.xml 文件,是否打开。这里直接选择 Open 该 pom.xml 文件,然后系统会自动解析项目的相关依赖,该步骤也会因你的网络和系统相关环境,所需时间不同。
- 关联源代码
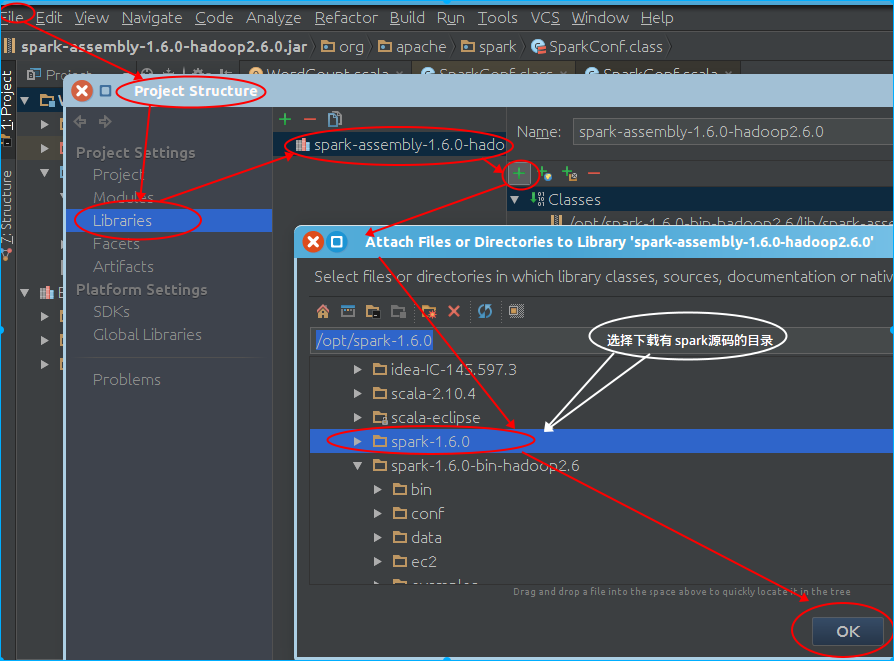
成功导入了源代码,现在再ctrl+鼠标选中点击相关spark相关类就可以看到有详细注释的源文件:
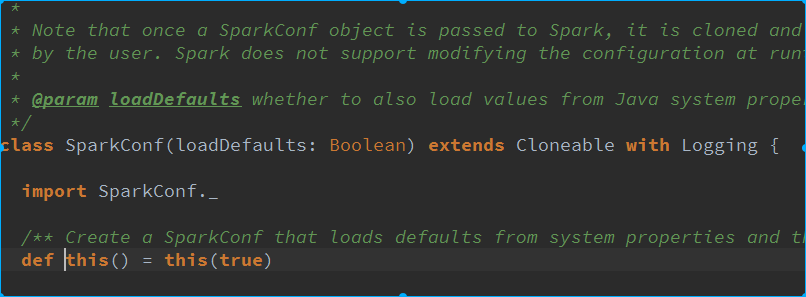
自我陶醉!成功的迈出了spark程序人生的第一步:开心啊!!!
[ 注 ] idea 常用操作基本快捷键
Ctrl+N 查找类
Ctrl+Shift+N 查找文件
Ctrl+Shift+Alt+N 查找类中的方法或变量
Ctrl+H 显示类结构图
Shift+F6 重构-重命名
Ctrl+X 删除行
Ctrl+D 复制行
Ctrl+/ 或 Ctrl+Shift+/ 注释(// 或者/…/ )
Ctrl+E 最近打开的文件
Alt+1 快速打开或隐藏工程面板















 2898
2898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









