






2023年9月2日,由平台工程技术社区与数澈软件Seal联合举办的⌈AIGC时代下的平台工程⌋——2023平台工程技术大会在北京圆满收官。吸引了近300名平台工程爱好者现场参会,超过3000名观众在线上直播平台观看了本届大会。
万物新生集团技术工程部负责人贾胜謇出席本届大会并发表题为《万物新生工程平台实践》的演讲,本文为演讲实录。

万物新生集团技术工程部负责人 贾胜謇
各位来宾,大家上午好。我叫贾胜謇,来自万物新生集团,可能这个名字大家比较陌生,如果提到“爱回收”大家可能比较熟悉。爱回收是我们集团最开始创立的一个品牌,也许大家在各大商场里都可以看到爱回收的招牌,它主要回收一些 3C 电子产品,比如手机、电脑,现在业务也在进行拓展,包括名酒、奢侈品回收之类的都是有的。

另外,我们还有一个品牌叫拍机堂,主要服务 B 端用户,是一个 B 端的 3C 二手产品的交易平台。另外,我们还有依托于京东集团的拍拍,面向C端用户销售一些二手优品。
大约在5、6年前,我们开始拓展海外市场,打造了 AHS Device 平台,为海外客户提供服务。此外,为了响应政府号召,进行垃圾分类,我们开拓了一个新项目叫爱分类,它是一个自动的回收机,为居民提供有偿的可回收物的回收服务。目前在全国40多个城市中均有部署,大约上万家小区已经使用。

万物新生集团维持如此庞大的业务量的正常运转离不开底层的技术支持,也就是我们技术工程部。我们主要负责的是运维、DBA、DevOps的工作,甚至包括提供中间件工具。今天我主要想和大家分享万物新生集团这些年来的云原生架构的演进,以及我们的效率工具如何在架构演进的基础上发展的。
另外,我们也在思考当前效率工具面临着怎样的挑战?为什么要采用平台工程来应对这些挑战?以及我们在落地平台工程的过程中采用了哪些策略?
01 十年的技术架构演进
首先我们先来回顾过去。为了这次分享,我在内部做了很多考古工作。万物新生集团(即爱回收)成立于2011年,从2011年至今我们没有用过任何 IDC 或是机房,那么2011年我们是如何维持业务稳定运行的呢?
从2012年开始,我们就开始购买阿里云的服务器,所以可以说我们是“生在云上”。现在大家都在说“云原生”这个概念,其实我们原生就是一个云。那个时候我们只有1台服务器,上面部署应用服务、数据库,一共5个工程师维护,其中2个是实习生。
当时的服务很简单,我们直接上传 War 包到 Tomcat 里,就可以对外提供服务了。为了提升效率,我们使用 shell 脚本进行部署,这是最简单的自动化。

2012年到2015年期间容器化非常火,我们的工程师都怀揣着技术梦想,十分期待拥抱最新技术。所以这个时候我们已经开始进行 Docker 容器化的工作,通过 Docker 容器化,我们可以更好地完成构建工作,并且实现环境隔离。但是当中存在一个很大的问题——在众多服务器上部署了不同的容器,但是对外只有一个应用或是API,那么它应该如何真正地找到它对应的服务器资源?
于是,我们一群怀揣梦想的工程师就字眼了一个叫 Whales 的部署工具来完成整个路由工作,那么它是怎么实现的?实际上是在发布过程中,通过 Whales 构建镜像后,根据不同的端口来区分服务,并自动找到比较空闲的 ECS,然后将服务部署在这个 ECS 上。
有了端口、有了服务,我们还会通过这个工具来调通阿里云的API,进而去调整 SLB 上的配置,让我们的流量可以路由到真正的 ECS 服务器上。与此同时,之前的 shell 脚本已经无法满足我们的需求了,于是我们将编译构建的工作交给了 Jenkins 来处理。

随着业务规模越来越大,几十个微服务已经无法满足我们的业务需求。并且由于我们当时购买了云服务,所以十分纠结还需不需要一个专门的运维工程师。因为当时很多人的想法是,当购买了云服务之后,就相当于运维外包给云厂商了。但是后来我们遇到过一次 Docker 的某个进程起不来的情况,导致网站宕机几个小时。于是我们发现为了整体的稳定,团队内部还是得有分工。所以这个时候,我们有了第一个运维工程师。
当时我们团队已经有40多个工程师了,只有1个运维。当时运维看到我们自研的系统很粗糙,所以开始拥抱 Kubernetes。于是,运维协同其他工程师把整体架构都迁移到 Kubernetes 上。
但是大家都知道 Kubernetes 是很复杂的,很多人都会自嘲自己是 Yaml Boy。我们当时天天就在写 Yaml,这是一件很繁琐的事,所以我们也不愿意让工程师自己写 yaml,于是我们自研了一个发布系统,叫 Nova。这个系统可以完成整个服务的部署工作,工程师只需要告诉它需要发布哪段代码即可。Yaml 文件时集中编写出来的,然后将其交给 Kubernetes。与此同时微服务越来越多,于是引入了分布式链路追踪系统 SkyWalking。
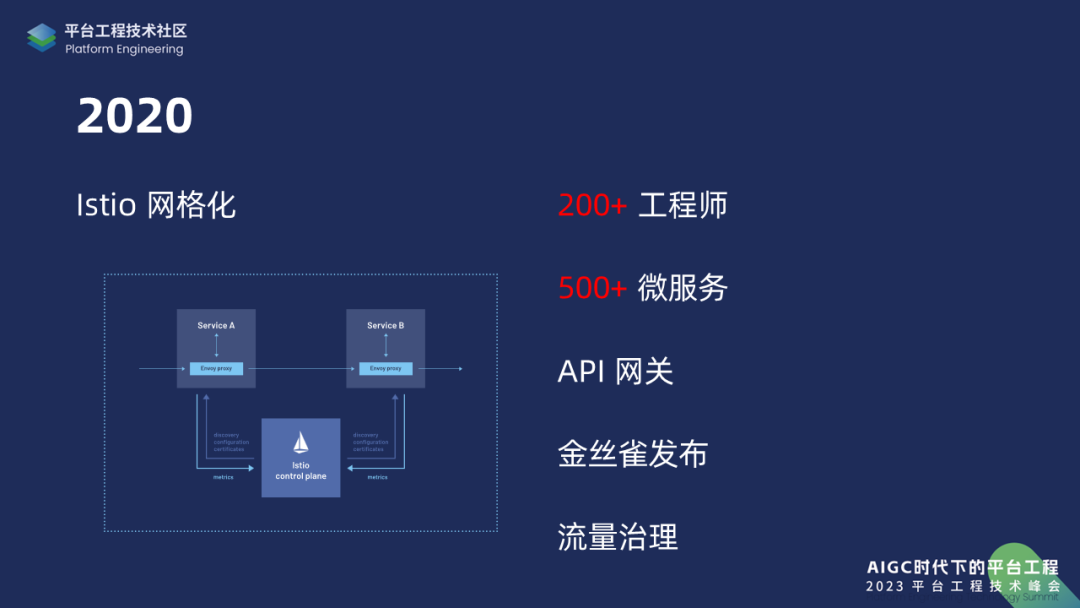
2018年是我们整个集团业务壮大的开始,拍机堂就是在那年孵化出来的。那么到了2020年,我们已经拥有了200多个工程师,500多个微服务,此时微服务治理成为一个很大的问题。我们当时自己研发了一个 API 网关,把所有的流量都接入这个网关来管理,同时我们发现 Istio 社区十分活跃,于是使用 Istio 把整个 Kubernetes 集群网格化,并借助 Istio 的功能完成了金丝雀发布,也完成了流量治理。
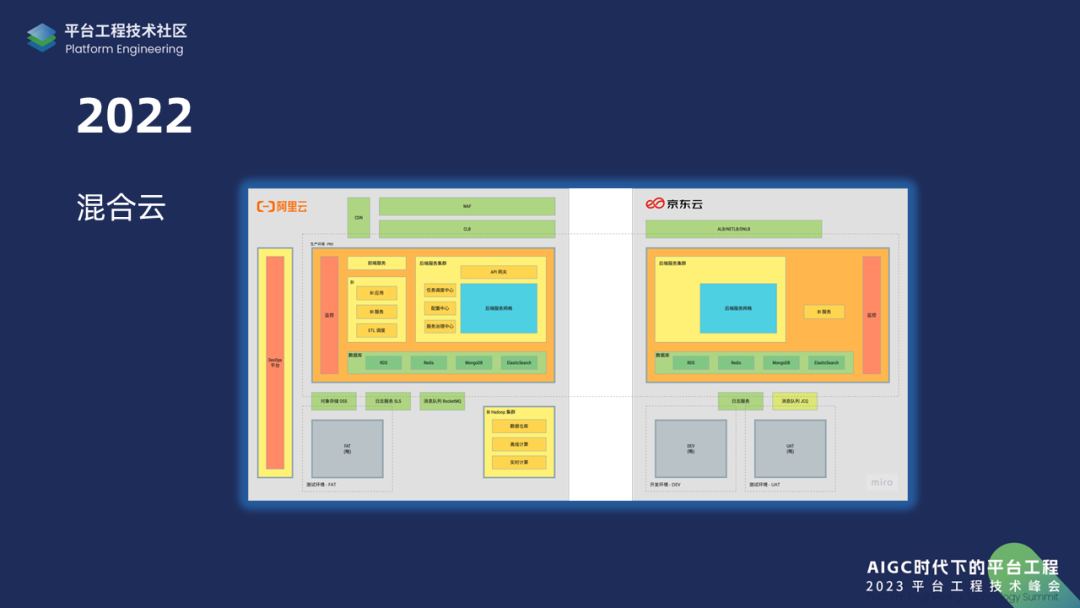
到了去年,基于成本以及稳定性的考量,我们再次升级了架构——混合云架构。我们借助云原生的一些技术把集群升级为单网格多集群的微服务架构,任何一个集群都可以正常工作。
02 工程效率的挑战与应对方法

随着业务的发展,我们面临的挑战也越来越大。对于技术工程部来说最大的挑战是工程效率。工程效率到底是什么?主要包括两大块:一是部署,即代码开发完毕后,如何让代码在服务器上正常运行;二是稳定,即代码部署完成后,如何观测它们。为了解决这一问题,我们引入了非常多的组件。
部署方面,我们最关注的是 Git workflow,也就是整个代码开发的流程应该怎么做,我们使用了 GitLab 等工具。另外,资源管理也是部署过程中必须要考量的因素,因为每部署一个新功能、新应用,都需要操作一些资源,除了云上的 IaaS 资源(网络或是服务器)还应用了大量的 PaaS 资源,包括 Redis、消息队列等。
此外,还需要考虑微服务本身的一些配置工作。我们引入了携程的 Apollo 来完成配置管理,借助 XXL job 来完成任务管理,包括任务的调度和部署。同时,我们为了保证开发流程区分了很多环境,包括联调环境、测试环境、生产环境,这些都需要开发工程师进行部署。
关于稳定性,最重要的是可观测性的情况。我们引入了Prometheus、Grafana、Skywalking等工具,此外报警和诊断工作也需要涉及,因为不仅仅要报警,还需要告诉业务研发到底发生了什么。最终,我们发现业务研发至少要接触30多个工具。

每进行1次部署,都需要跨各种工具来完成。根据统计,我们生产环境每年都要进行14000次的变更,加上其他环境一共有10万次变更,同时还管理着3000+的云上资源,这对于我们来说是个很大的挑战。
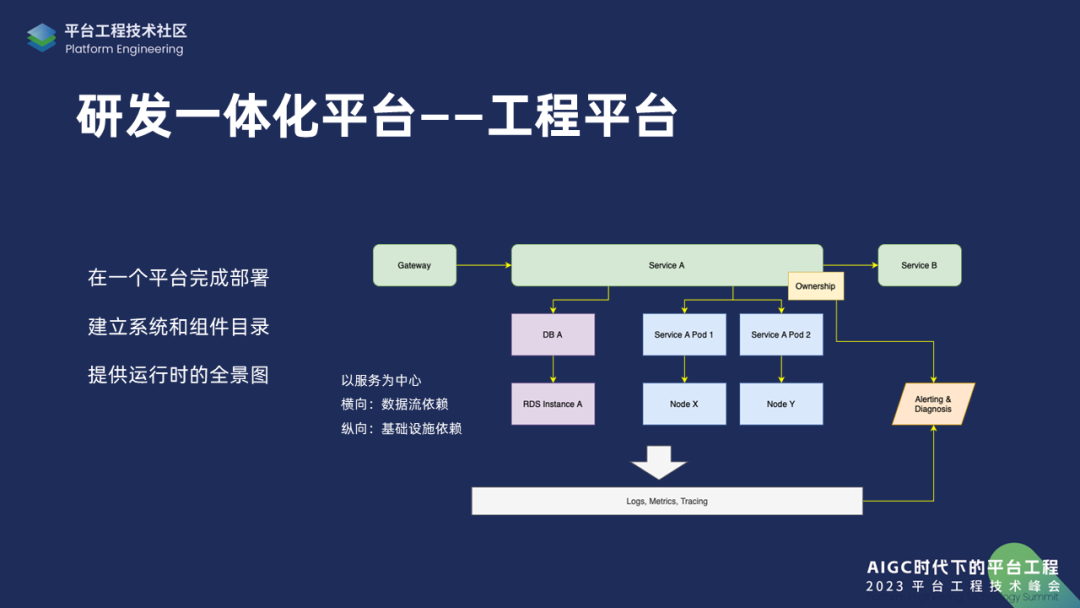
参考了很多业界的实践,我们决定做一个统一的开发者平台,我们内部称其为研发一体化平台,现在我们把它叫做工程平台。这个平台要解决什么问题?首先是在一个统一的平台上完成部署的工作,不需要不停地切换 context,以降低错误率。另外,要建立系统和组件目录,因为之前研发工程师很难告诉其他人我们的系统架构和组件到底是怎么样的结构,甚至可能不知道流量是怎么路由到服务的,那么当生产环境出现问题的时候,故障排查的效率会非常低。于是我们还会提供运行时的全景图,帮助研发定位问题,并且在发现问题之后我们工程团队也能够及时地通知对应的研发团队。
因为我们之前是微服务架构,所以这里我们设想以服务为中心往上、下来扩展这个平台架构图。
横向的话,是想要根据网络数据的流程来涉及,比如怎么从网关到某个服务,然后这个服务上游又是有哪些服务?那么纵向的话,是基础设施的依赖,比如 PaaS 的服务数据库或是消息中间件,它到底依赖哪个实例?或者依赖哪个库?以及我们的 Kubernetes 当中是哪一个 pod 在运行?这个 Pod 是部署在哪一个 Node 上?把这个全景图建立起来之后,还构建了统一的日志追踪,即 log metric 和 tracing。
把所有的数据集中起来管理之后,出现问题即可很快能定位到具体环节和具体负责人。

目前全景图仍在制作过程中,现在我们已经完成了发布系统的替换——让工程平台下的发布系统完成所有的发布工作,并且响应业务研发的需求开发了命令行工具:Cockpit,通过 homebrew 来安装这个 CLI 工具来完成发布。我们通过命令来完成任务,比如想要查看有哪些服务,直接输入命令 list services 即可看到很多细节。

那么平台工程和工程平台到底是什么关系呢?实际上,我们最早是叫研发一体化平台,也就是现在提到的 IDP,Internal Developer Portal,即内部开发者门户。我们之前也做过一个门户网站,但是那个网站只是把各个系统的链接堆在上面,收益甚小。于是,我们决定做研发一体化平台的时候,大量借鉴了 DevOps 社区的情况。
如果大家有关注过平台工程的话,可能会知道那条 Twitter:Devops is dead long life to platform engineering。我看到这条 Twitter 的第一反应是老外又开始创造新词了,这不还是原来那套东西吗?但后来去搜索平台工程的内容的时候,发现还是有一些新的东西。
在 platformengineering.org 里,有一篇博客在介绍到底什么是平台工程,里面提到平台工程是一门云原生时代下工程师如何设计和构建自动化工作流工具链的学科。那么 IDP 是平台工程团队的工程师们所创造的一个产品。

所以这里就非常明显了,平台工程是一门学科,所谓这些运维、DevOps 是这门学科所研究的一个对象,其中还有很多概念、方法论。
这里再稍微扩展一下,我们在学校里都有学过一个叫“软件工程”的课,这其实是一个更大的学科。而我认为平台工程在当下是软件工程中相当重要的组成部分。工程平台就更为简单,它是我们现在使用的 IDP 产品,承载了我们具体的工具和流程,它是企业内部平台工程实践的产出物。
03 平台工程的落地策略
我们目前已经进行了一年多的实践,我们在实际的落地过程中以及和其他社区交流的过程中,给我们带来了一些启发,接下来我来分享我们的落地策略和认知。

我们在进行平台工程建设的时候,首先需要进行组织建设。我认为工程效率本质是技术管理模式,无论是发布流程、安全与合规实践、资源申请流程,本质上都是管理问题,而组织架构的设计体现了管理思想,大家知道康威定律是牢不可破的。很幸运的是,我们集团的组织建设还是不错的,因此我们可以更好地落地平台工程。

目前,我们主要是两个组织对此负责:技术委员会和技术工程部。他们是怎么分工的呢?技术委员会主要由业务研发 Leader 组成,他们是最懂业务诉求的。技术工程部主要是 SRE 和 DevOps 工程师,针对委员会提出的诉求,运用产品思维来解决问题。
两个团队之间应该如何沟通呢?首先闭门造车是很危险的,曾经技术工程部门自己开发了一个发布平台,甚至把项目管理纳入其中,但最后无人使用,也浪费了很多资源。于是,我们需要委员会制定一些规范,比如开发规范、安全规范、编码规范,为了保障规范落地执行,技术工程部门需要开发一些配套工具。

针对两个组织的配合,我们内部有一个非常有意思的比喻,技术委员会是“业委会”,技术工程部则是“物业”。比如你的小区里水管漏了,那第一时间就是打电话给物业,让他们上门修理。业委会也会发现一些问题,比如停车很乱,需要建一个车棚。车棚的地点由业委会投票决定,最终实施方是物业。
同理,云基础设施资源就是我们的整个房子,当它出现的问题时候,第一时间会找到技术工程部门负责维修。委员会负责提出架构的变更或升级的诉求。

已经明确了我们需要一个开发者门户,那么接下来需要确定怎么做。当中有很多方法:自研、外包、采购或者是使用开源方案。我们最终采用的是核心域自研、支撑域外包、通用域采购的方案,这是 Thoughtworks 之前提出的一种方式,这也指导了我们的工作。
但是会发现其中漏掉了一个部分,那就是”开源“。我们之前踩过很多坑——我们之前认为开源和自研是一样的,反正代码都有了,可以为所欲为。但经过实践之后,我们发现这会导致很大的问题:之前我们把一个开源软件引入到系统里,但它不符合我们的诉求,于是我们直接开始修改代码,过了一两年之后,发现合不进去了,全都是魔改,社区的新功能我们没办法用,安全补丁也没办法安装。
于是,我们现在的思路是开源软件最好不要动,拿来即用,如果发现无法支持我们的某个诉求,那么就提交 issue 跟社区讨论是否可以新增某个功能,甚至我们会提交 module request,为开源社区做贡献。那这更像是在通用域采购的位置。

再回到我们的核心域,即 3C 数码产品的回收,也就是业务研发正在做的事情,而 DevOps、运维主要起到支撑的作用,那么是不是外包才是最佳解决方案呢?由于考虑到两个比较重要的问题,我们最终从没有选择外包:一是我们技术架构迭代的速度是很快的,如果要外包的话,他们的产品也需要根据我们的架构迭代进行调整,换句话说我们需要一个长期的外包团队,那么这与内部自己搭建一个团队差不多;二是支撑域与其他领域不一样的,负责这一块的必须得是技术人员,并且清晰地了解我们的需求,技术人员会更倾向于自己写软件。于是我们最终选择了自己搭建团队来开发软件。
当然,在这个过程中我们并不是闭门造车,而是保持着开放的心态,不断地与其他社区进行交流,我们也希望当中的一些核心组件、功能来自于其他社区,不需要重复造轮子。

最后想和大家聊聊,到底什么是平台?对于软件从业者来说,平台这个词并不陌生,主要有以下几个特性:
-
制定标准
-
开放扩展
-
用户接入
那在公司内部,用户真的会接入吗?这其实是一个管理问题了。我们工程部负责平台研发时,可能计划业务团队自己写 yaml 文件往平台上扩展,或者类似于 Backstage 一样,提供一个大框架,然后业务团队自己写前端或后端来扩展这个平台。但这是很困难的,因为业务团队的主要任务是解决业务问题,支持核心域。所以业务研发不会自己写 yaml,所以用户是不会接入的,那就只有我们部门自己来接入。
也就是说,我们需要自己完善整个平台的功能,比如 Grafana、Prometheus 等报警、监控功能的接入。所以这个平台并不是传统意义上的用户接入。那么我们自研的平台就无需进行开放扩展的设计,因为我们自己直接用代码进行扩展即可。

最后总结一下,平台工程的落地过程并非一蹴而就,是随着企业的技术架构迭代、组织建设形式而慢慢演进和调整的,我们也希望能与整个社区一起探索和前行。最后感谢平台工程技术社区和数澈软件举办了这场大会,让我们可以在这个平台上共同交流,推动平台工程的发展,谢谢大家!
04 大会资料
如果您想随时回顾本届大会内容,可以访问下方链接查看大会回放:
https://space.bilibili.com/3537110606810058/channel/seriesdetail?sid=3597069


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









