






时序动作定位
时序动作定位(Temporal Action Localization/Detection) 要预测起止时刻+动作类别
基于滑动窗的算法
定义不同时长的滑动窗,沿时间轴滑动并判别。
Viola-Jones人脸检测:滑动窗+Adaboost
NMS(NonMaximum Suppression 非极大值抑制)
**S-CNN(Segment CNN)**候选网络+分类网络+定位网络(滑动窗数量和计算复杂度要权衡)
**TURN(Temporal Unit Regression Network时序单元回归网络)**对滑动窗边界进行修正,只预测起止时间不判断动作类别,利用动作开始前和结束后的信息辅助判断,最后用NMS去除冗余。
CBR(Cascaded Boundary Regression级联边界回归)可以渐近修正边界,最终进行动作类别检测。
基于候选区时序区间的算法
类比两阶段目标检测Faster R-CNN:候选区域网络+ROI汇合
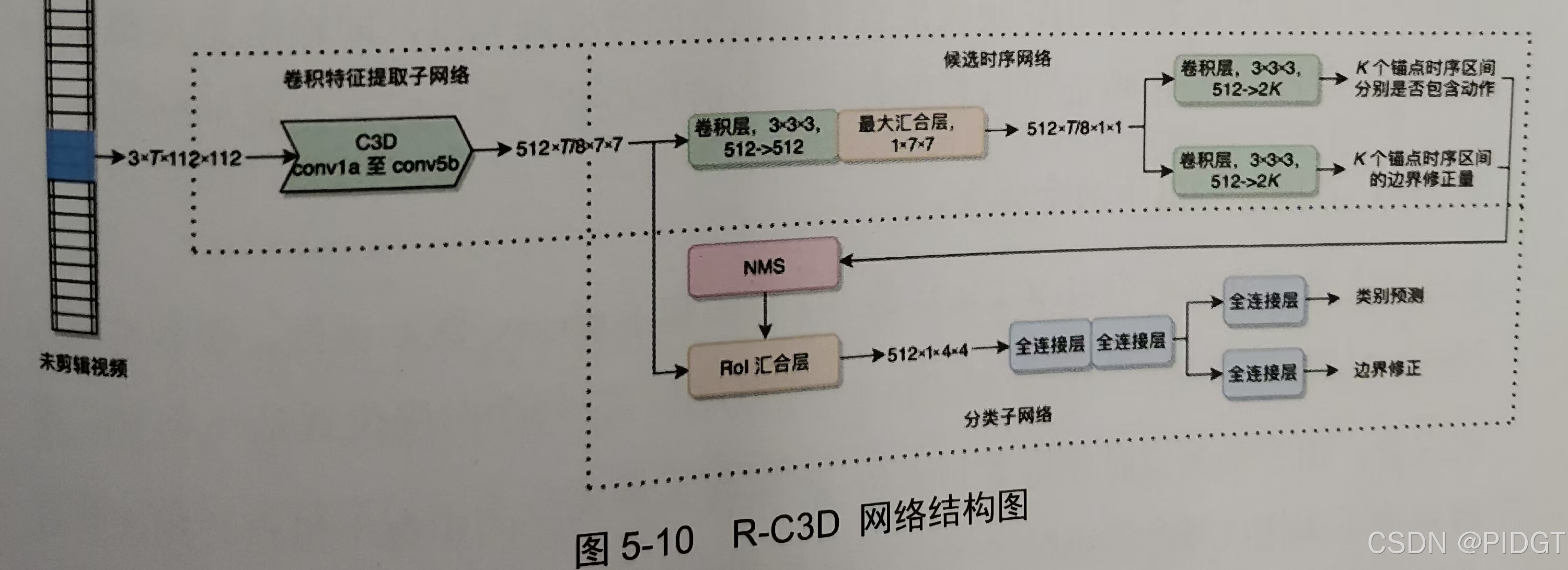
**R-C3D(Region Convolution 3D Network)**端到端训练,卷积特征提取+候选时序网络+ROI汇合+分类
TAL-Net(Temporal Action Localization Network时序动作定位网络)改进:感受野对齐(使用多塔结构,不同塔有不同的时序感受野大小,每个塔对应一种锚点时序,通过空洞卷积控制感受野大小)利用时序上下文信息,后融合(加入光流)
自底向上的算法
人体姿态估计(Human Pose Estimation):自底向上(关键点->组合)自顶向下(包围盒->关键点)
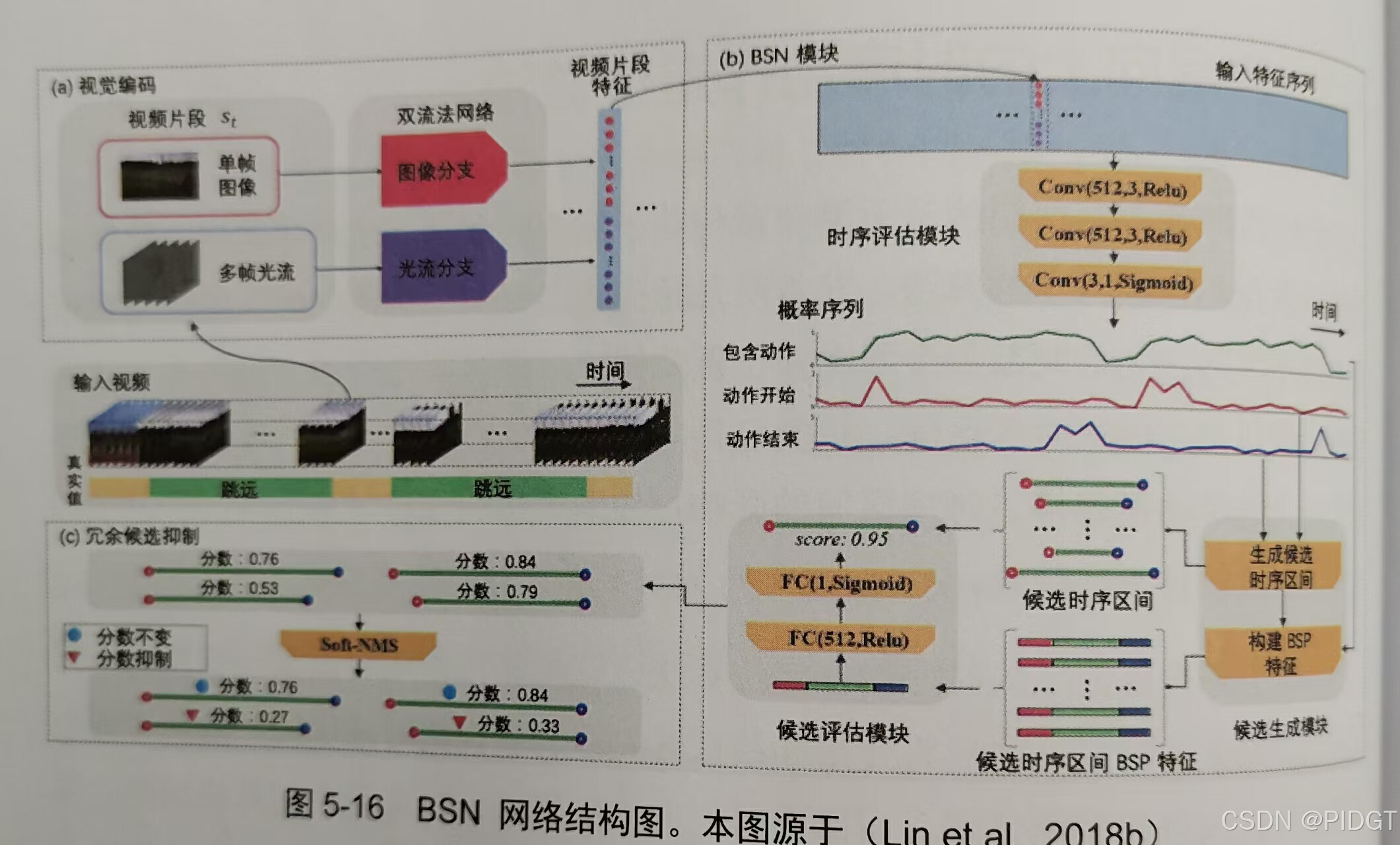
**BSN(Boundary Sensitive Network边界敏感网络)**视觉编码,BSN模块(时序评估+候选生成+候选评估),冗余候选抑制(SoftNMS有最大概率的候选时序区间计算和其他区间IoU衰减其他区间)
TSA-Net(Temporal Scale Aggregation Network)考虑了不同动作的持续时长变化很大,使用多空洞时序卷积,3个分支预测开始、中点、结束概率序列。
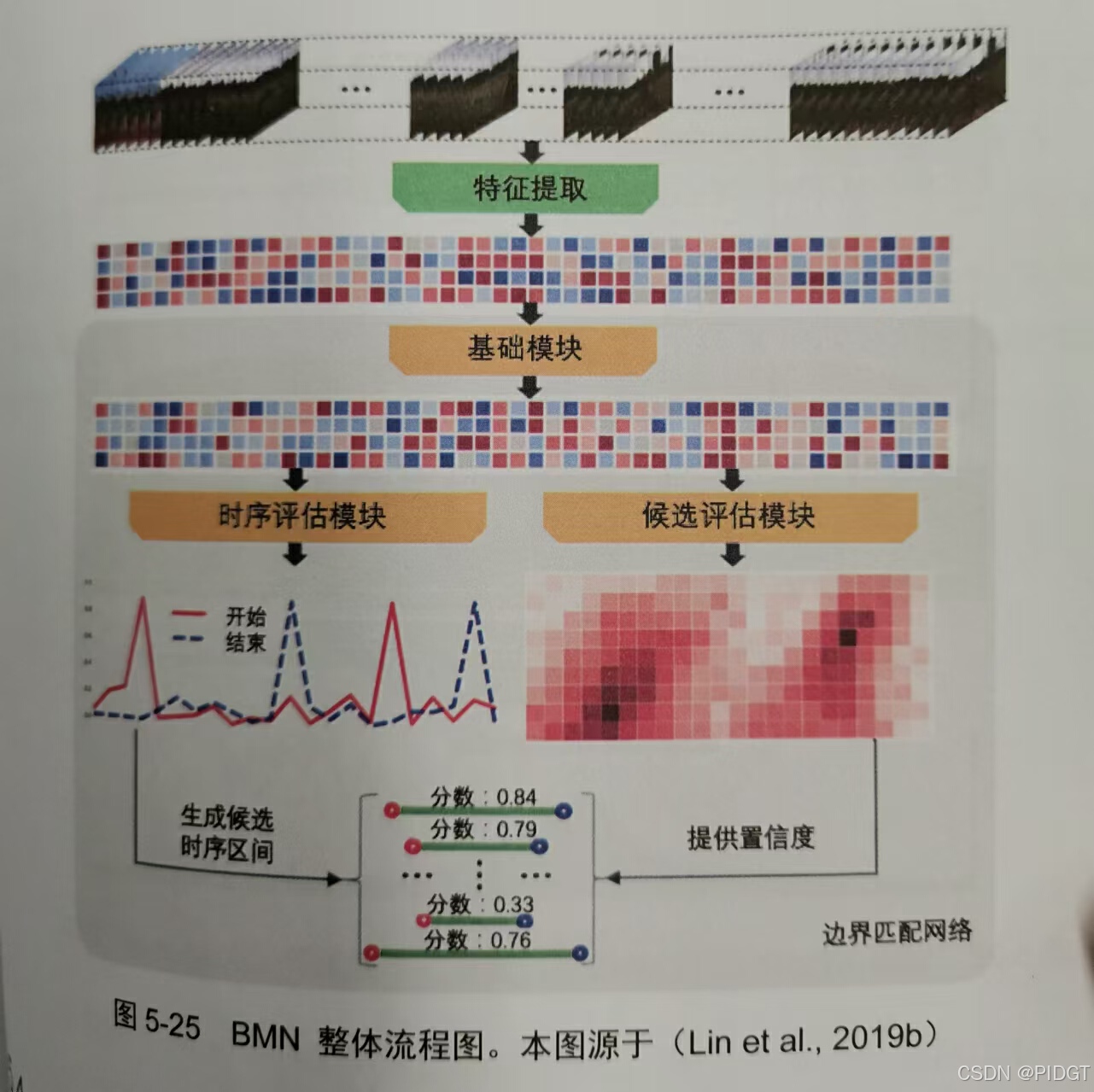
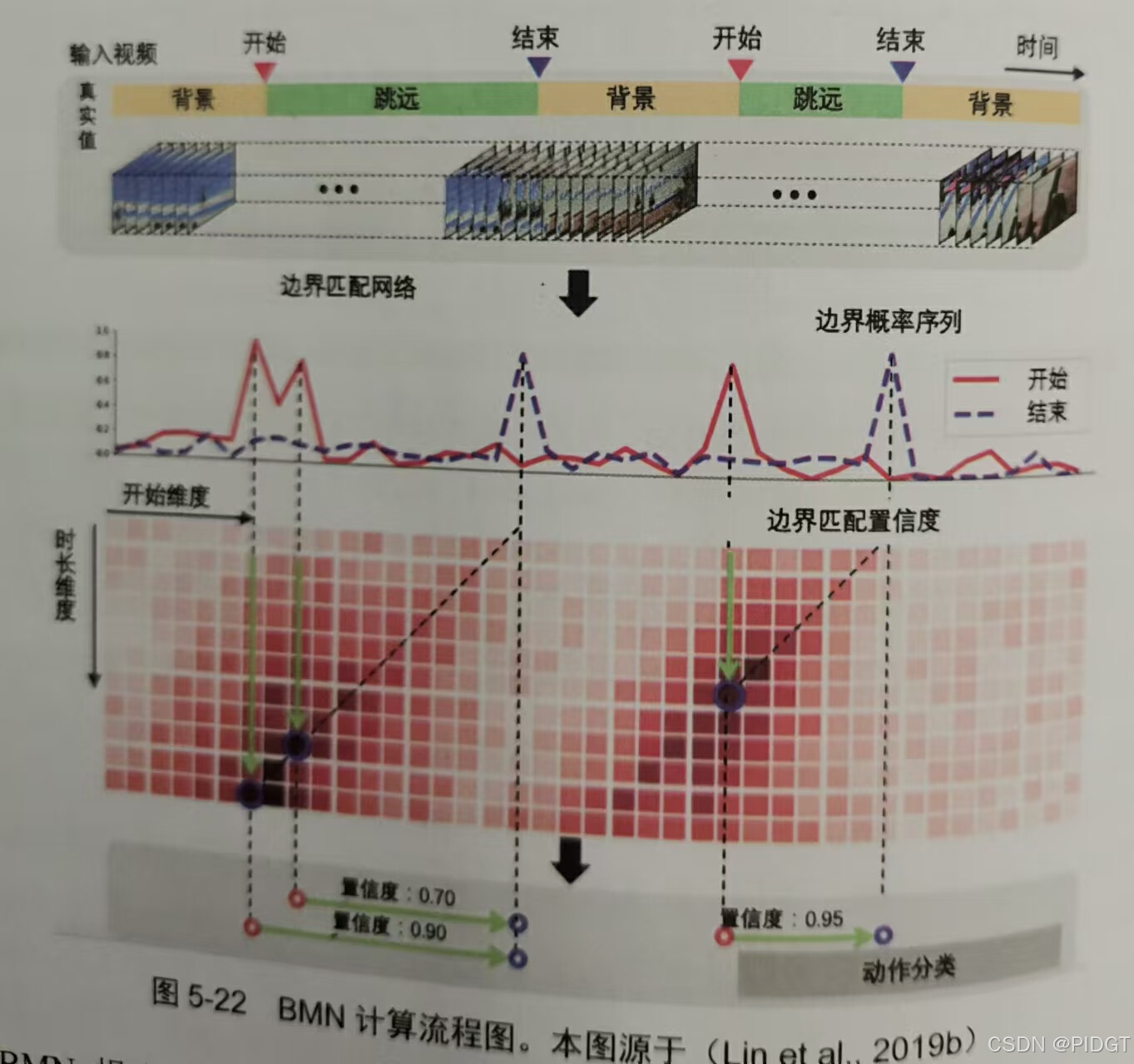
BMN(Boundary-Matching Network)用边界匹配机制代替原BSN的候选生成模块
对时序结构信息建模
SSN(Structured Segment Network)使用TAG(Temporal Actionness Grouping)时序动作分组,是分水岭算法,对动作不同阶段建模;使用STPP(Structured Temporal Pyramid Pooling)结构时序金字塔汇合
逐帧预测算法
CDC(Convolutional-De-Convolutional)
**反卷积(Deconvolution:Transposed Convolution)**反卷积广泛用于语义分割,使输出高宽和输入一致。
单阶段算法
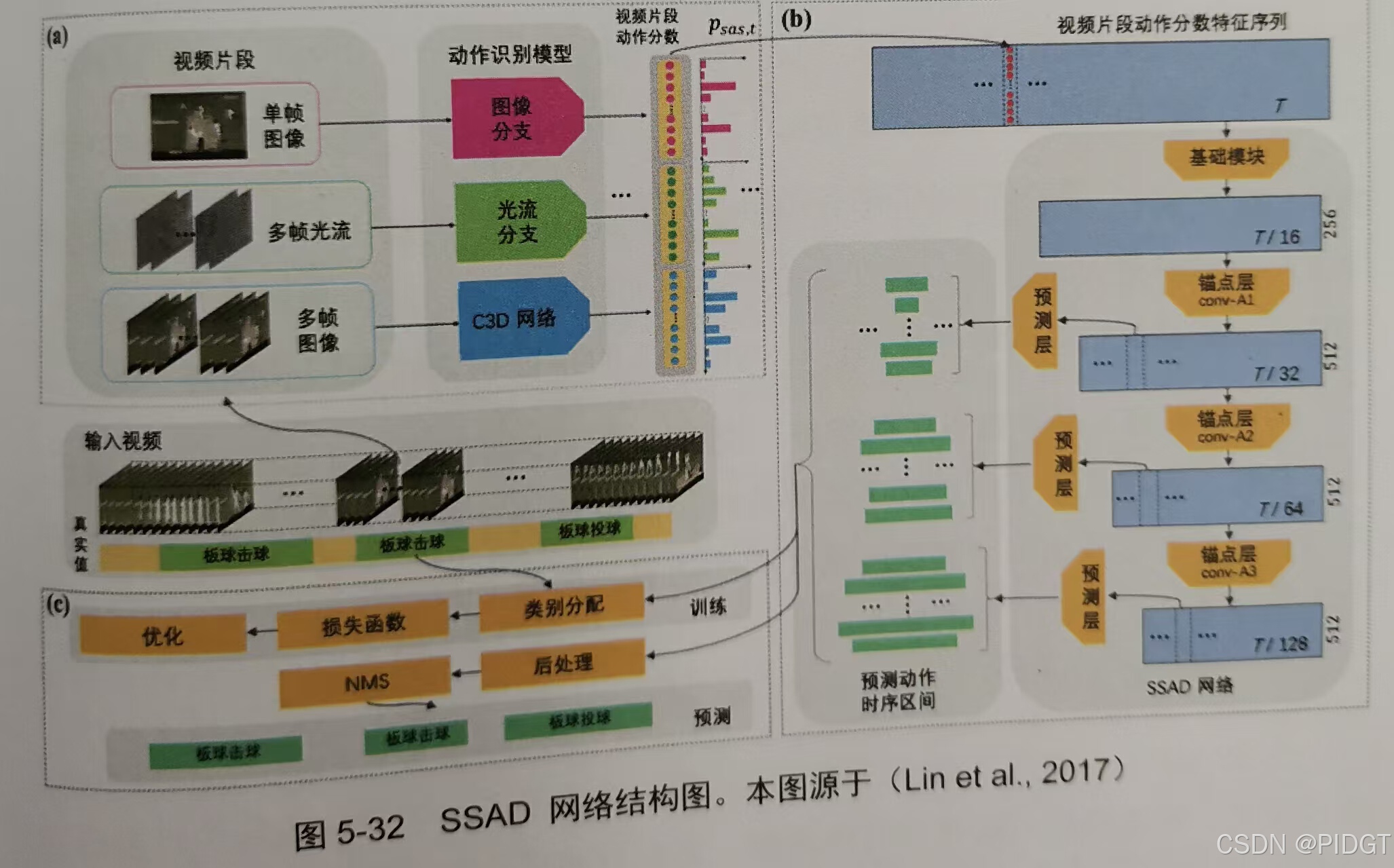
SSAD(Single Shot Action Detector)受YOLO9000启发,同时进行类别预测、时序区间偏移修正、IoU预估;受SSD启发,将不同尺寸的特征和不同大小的锚点时序区间对应
SS-TAD(Single-Stream Temporal Action Detection)单流时序动作检测,非常快(特征提取+PCA+GRU+辅助模块(记忆时序P+记忆动作C)+输出)
GTAN(Gaussian Temporal Awareness Network)用高斯核来考虑时序结构,多个高斯核组合。
视频Embedding
Embedding:嵌入,向量化。视频Embbeding是从视频中得到低维、稠密、浮点的特征向量表示。
基于视频内容无监督学习,构建伪标记(Pseudo Label)
1)编码-解码
2)视频序列验证,判断正确排序
3)视频和音频信息(音视频对应学习,预测是否对应)
4)视频和文本信息(视频和标题,视频和字幕,视频和语音识别)
ASR(Automatic Speech Recognition自动语音识别)
BERT(Bidirectional Encoder Representation from Transformer)BERT可以学习文本的Embedding
ViLBERT(Vision and Language BERT)可以学习图像和文本的Embedding
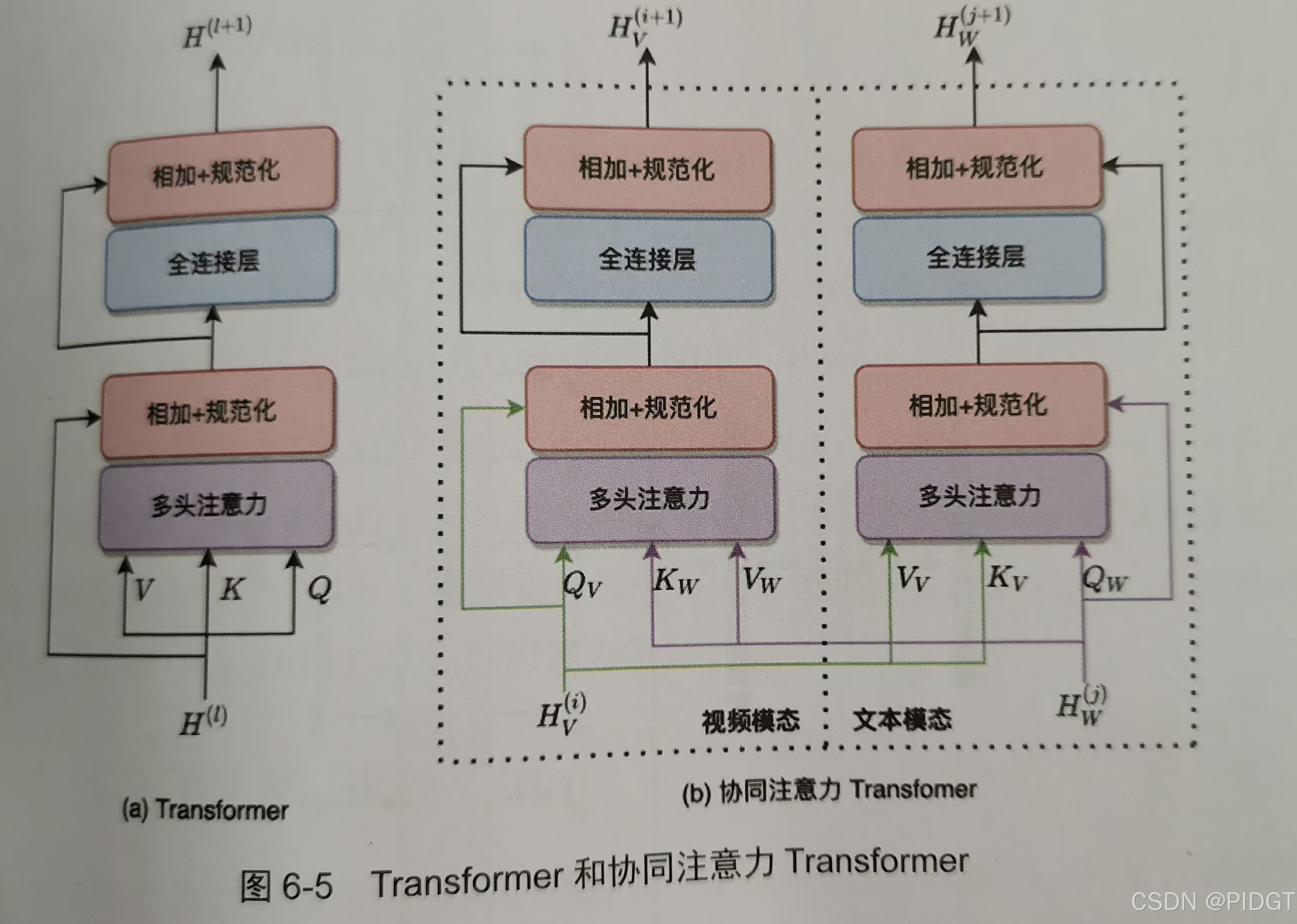
协同注意力Transformer,通过交换多头注意力(Multi-head Attention的Key 和Value)
有掩膜(Masked)的多模态学习,训练时15%掩盖,基于其他恢复
多模态对齐预测,二分类预测文本是否对应视频信息
Word2Vec 从海量文本语料中以无监督方式学习Embedding
CBOW(Continuous Bag of Words)多个词预测一个词
Skip-Gram一个词预测多个词与CBOW是对偶模型
构建词汇表+计算Embedding特征+计算输出结果(Embedding查找,不要真的乘)+计算损失函数
分层softmax 一个多分类问题=多个二分类问题。构建huffman树并训练多个二分类模型
负采样 将激活函数由Softmax改成Sigmoid。不遍历词汇表所有单词,从子集中构成负样本近似原来的结果。
Item2Vec 训练集由多个用户观看序列构成,去重后构成视频列表,最终学习每个视频Embedding。改进:短期兴趣:观看一定时长+排除超时;点赞视频序列;分桶离散化:合并属性相似的视频(视频属性/用户属性);学习细粒度差异,从没有看过的某类视频加入负样本
基于图的随机游走
DeepWalk 视频图上随机游走
Node2Vec根据随机权重选择下一个游走的点(DFS深度优先和BFS广度优先)
**LINE(Large-scale Information Network Embedding)**两个训练任务,基于一阶和二阶相似度学习。二阶相似度考虑每个结点和邻居结点集合
**SDNE(Structural Deep Network Embbeding)**无监督和有监督
基于图的邻居结点
**GCN(Graph Conovolution Network)**图谱卷积的一阶近似,利用图的邻接矩阵
**GraphSAGE(Graph Embedding with Sampling and Aggregation)**带采样和聚合的图Embedding
**GAT(Graph Attention Network)**由掩膜自注意力
多种信息学习视频Embedding 观看向量,搜索向量,地理属性,视频年龄,性别,登陆状态,年龄。隐式反馈,是否看完,观看记录


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









