







《深度学习视频理解》记录
动作识别
个人读书记录,方便以后查阅。
传统算法
VLAD(Vector of Locally Aggregated Descriptor局部聚合描述向量) 将所有特征划分成多个聚类,对聚类内的特征汇合,将所有汇合的特征拼接成一个全局特征向量(特征聚类+特征分配+差值求和)。
HOG(Histogram of Oriented Gradient 方向梯度直方图)
HOF(Histogram of Optical Flow 光流直方图)
MBH(Motion Boundary Histogram 运动边界直方图)
Bag of Features(将图像视为由多个局部特征组成的集合,类似于文档中的词汇)
FisherVector(提取特征后,训练出高斯混合模型GMM,聚合对应的偏导数并归一化得到特征的统计信息)
Optical Flow光流法:计算视频沿水平、垂直和时间方向的梯度,反应了物体运动情况。基于亮度恒定假设。Lucas-Kanade方法,加入邻域光流相似假设。主流光流算法如TV-L1,深度学习后有FlowNet,FlowNet2.0。可视化要用两张图表示运动信息,用箭头或者不同颜色就可以用一张图表示。
传统动作识别算法DT(Dense Trajectories) 1)不同空间尺度密集采样特征点 2)特征点轨迹跟踪 3)特征提取(HOG/HOF/MBH/特征点位移向量) 4)特征编码+SVM分类
iDT DT+对相机运动估计(假设相邻帧变化小,用投影矩阵估计相邻帧关系,用人体检测器避免人的动作影响)+改进特征规范化方式 + Bag of Feature->Fisher Vector
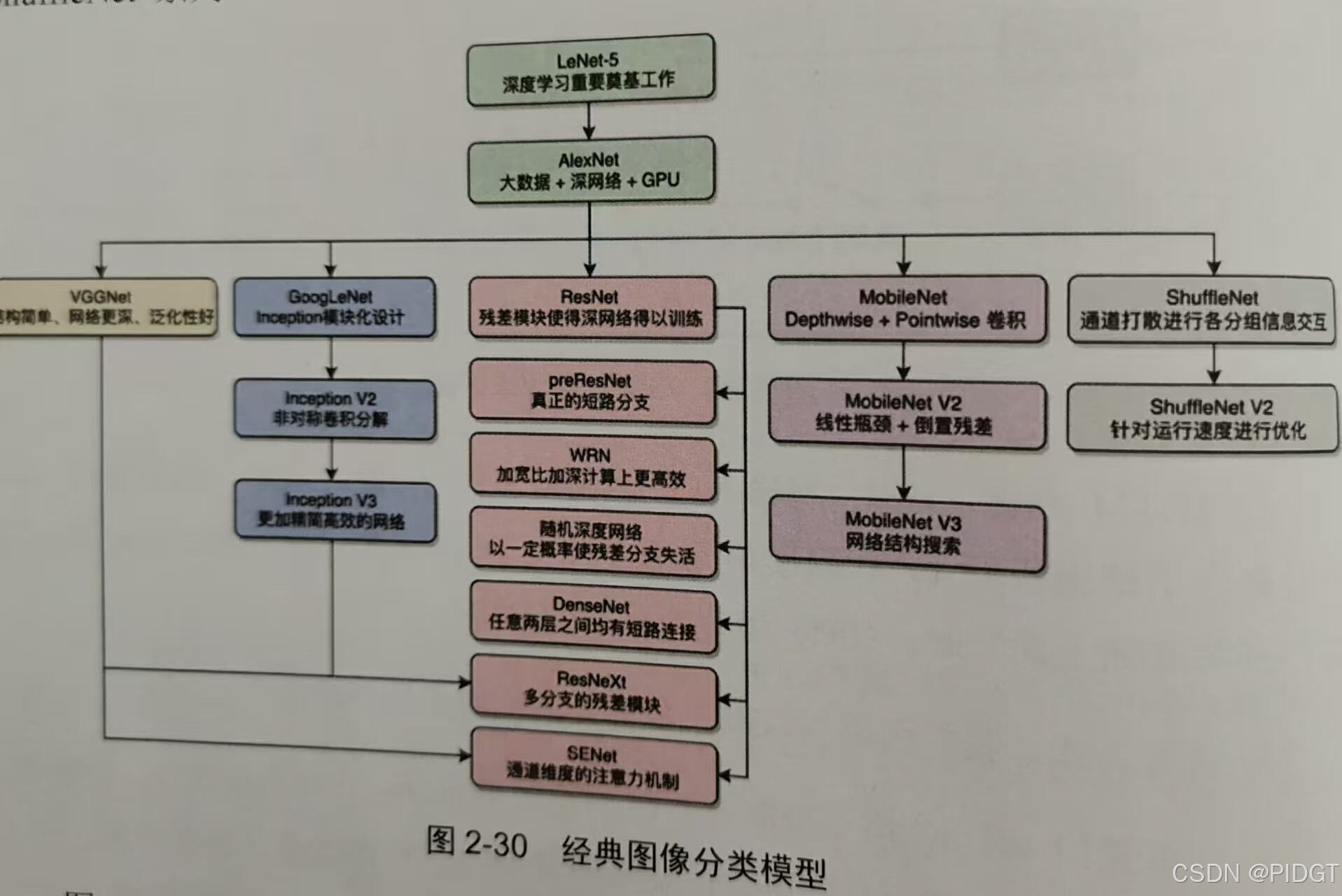
经典网络结构回顾
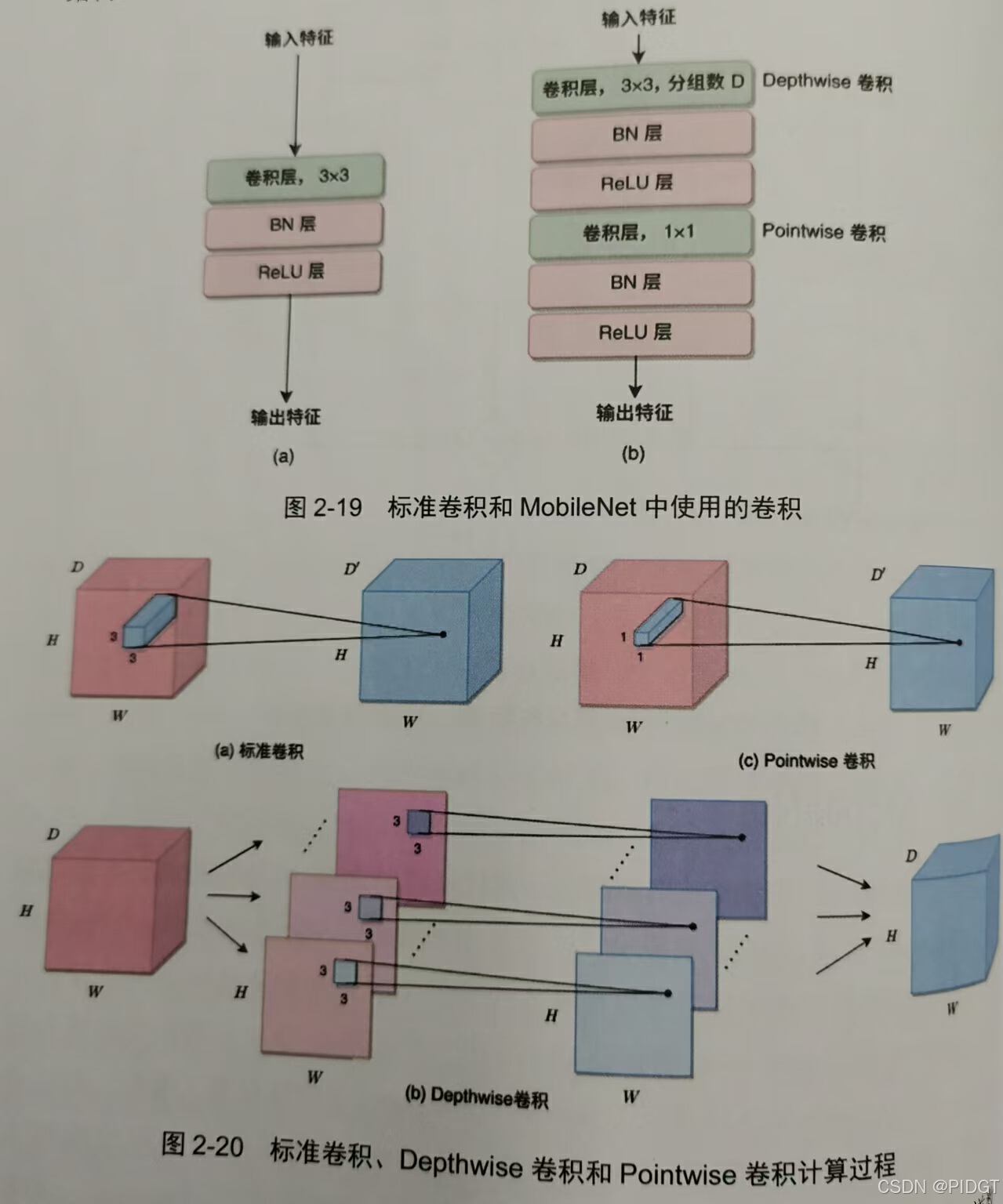
MobileNet:将一个D组标准的3x3卷积替换成一个Depthwise+一个Pointwise
参数量:9D^2 参数量9D 参数量D ^2
计算量:9D^2HW 计算量9DHW 计算量D ^2 HW
当D>>9,mobilnet的卷积 / 标准卷积=1/D+1/9(参数量和计算量都是,比值大概是1/9)
MobileNetv2: Pointwise+Depthwise+Pointwise(先升维再降维,ReLu6)
MobileNetv3:(NAS Network Architecture Search ;激活函数h-swish f(x)= x*ReLu6(x+3)/6;Squeeze-and-Excitation(SE)模块可以自适应地重新校准通道特征的重要性;优化网络尾部结构)
基于2D卷积的动作识别
平均汇合(Average Pooling) 1)对各帧图像特征进行平均汇合;2)或者对softmax的概率向量平均汇合
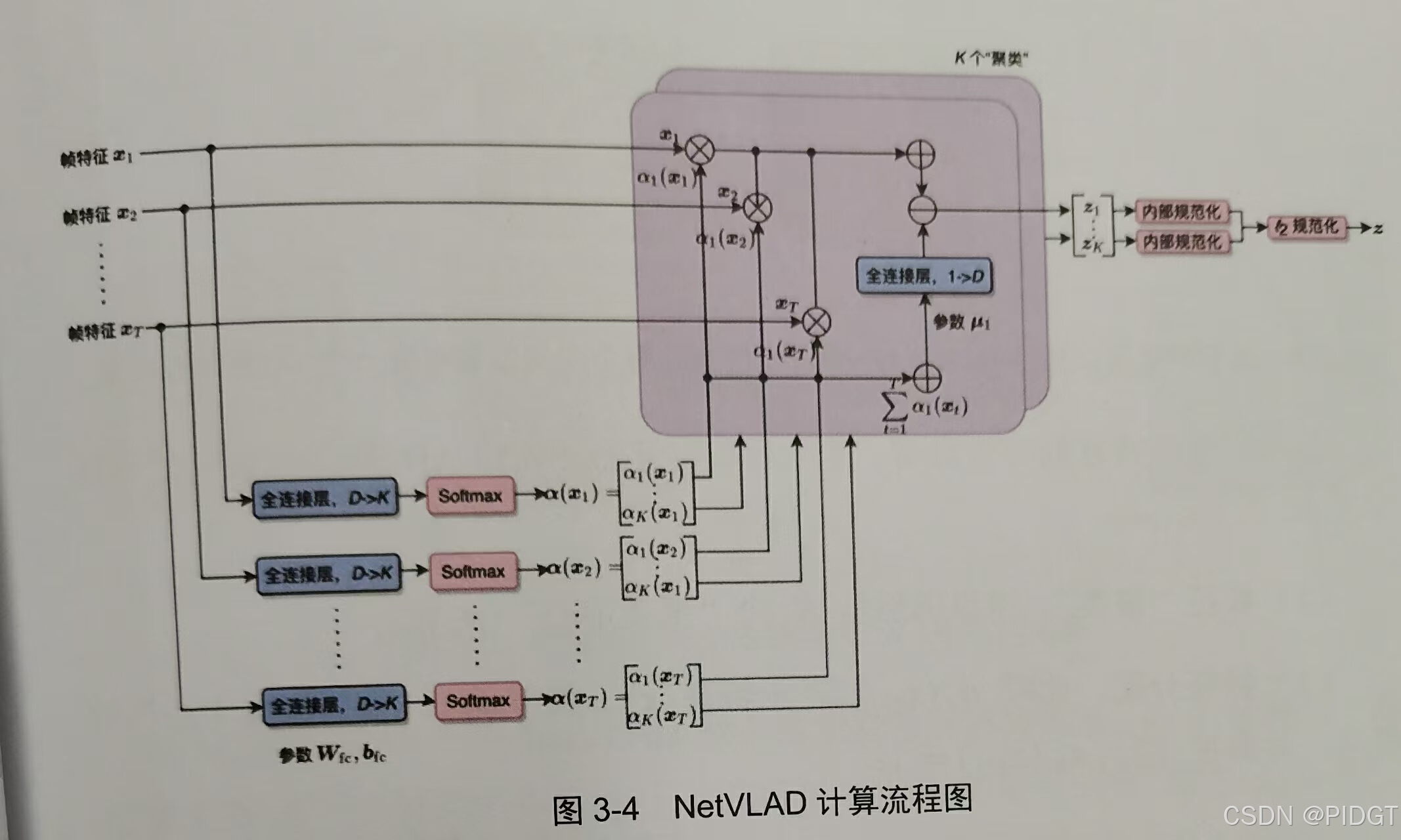
NetVLAD(聚类中心让网络学习+分配softmax(wx+b)+差值求和) 对分类模型的全连接层特征进行NetVLAD,或者对最后一个卷积层的特征进行NetVLAD。
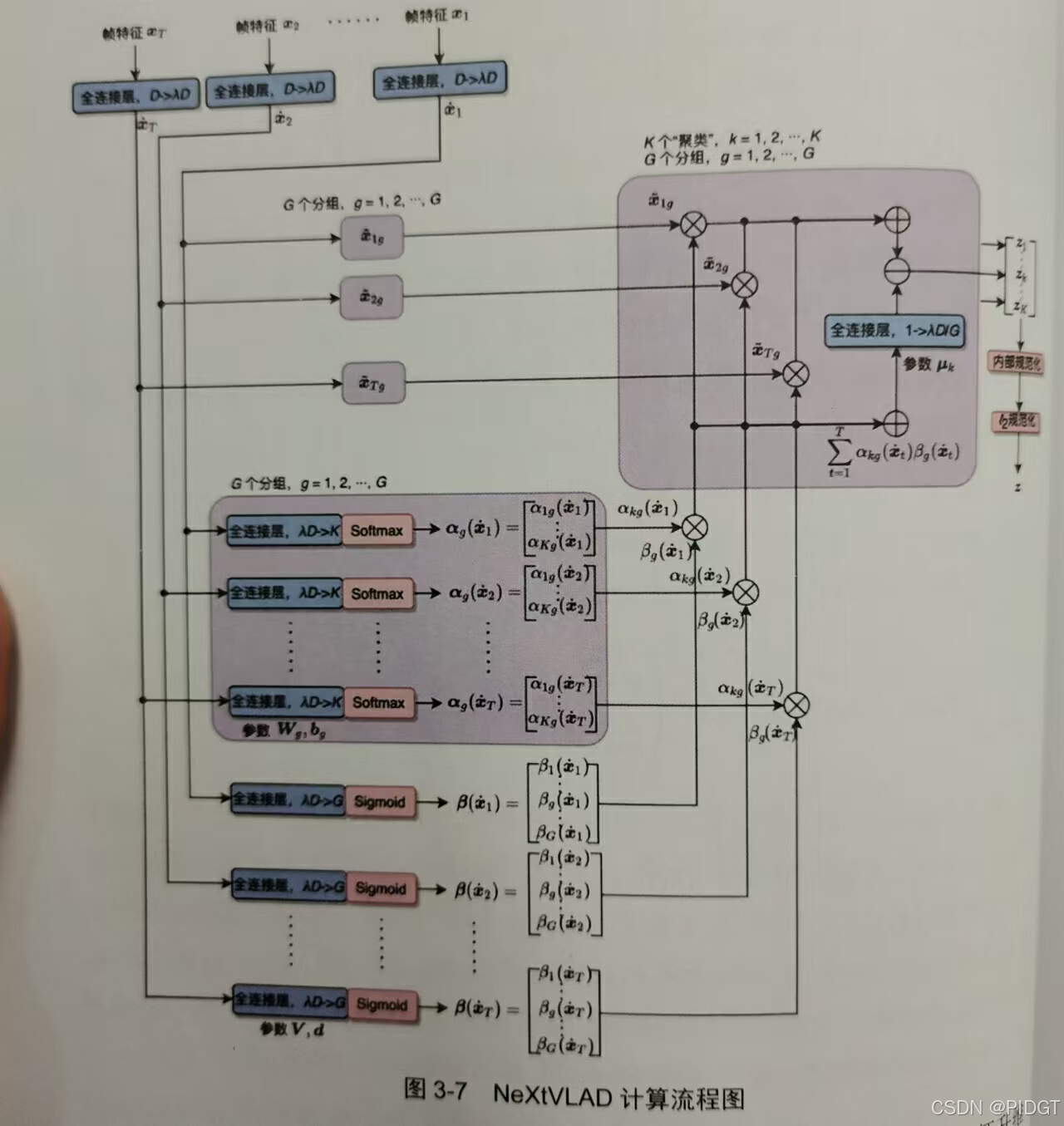
NeXtVLAD对特征进行分组,各个分组卷积后进行合并(特征升维分组+聚类+分配+差值求和)
上下文门控(Context Gating) 通道维度的注意力机制 y=sigm(Wx+b)⊙x (⊙是逐元素相乘,W和b是可学习参数,sigm(Wx+b)用于对x进行门控) 上下文门控作用是1)引入输入特征x的非线性交互,2)对x各维数值大小重新校正,抑制和预测类别不想管的信息。
MoE(Mixture of Experts混合专家) 每个专家模块相当于一个分类器
RNN(Recurrent Neural Network)
LSTM(Long Short-Term Memory,属于RNN,主要用于处理和预测时间序列数据中的长期依赖问题。细胞状态可以短路,类似ResNet的残差逼近思想)


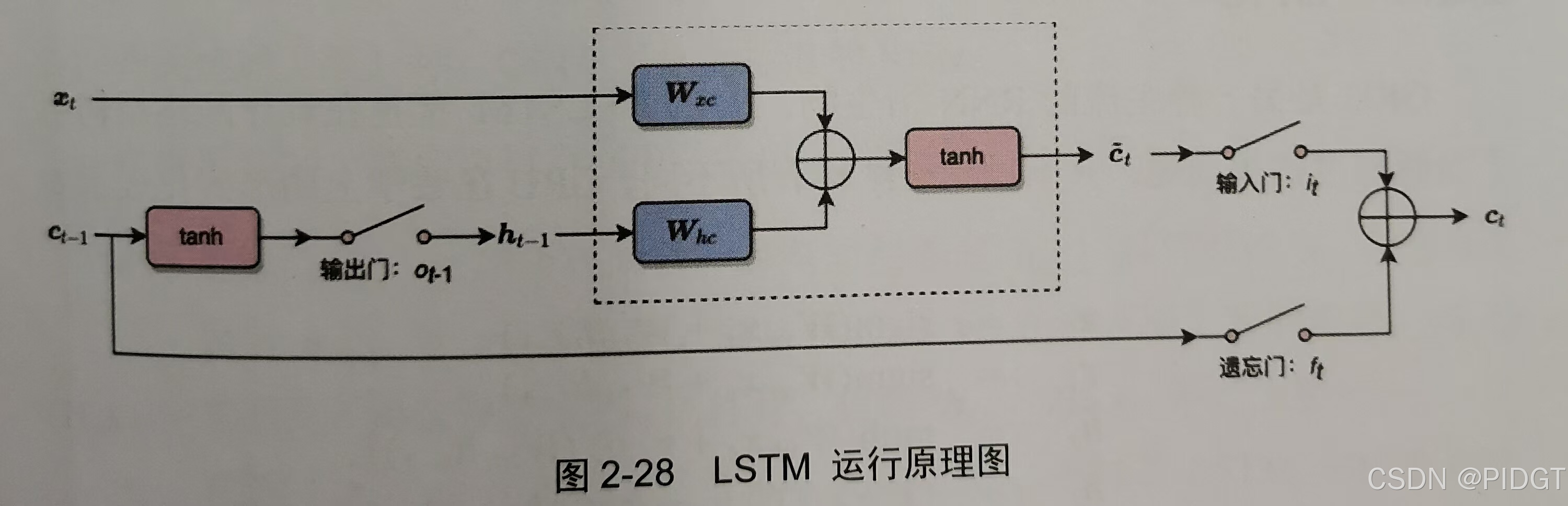
2D+RNN 有两类1)对特征做RNN汇合出一个特征;2)各个特征分别汇合出多个特征。图像分类模型提取特征+LSTM/GRU捕获葛铮的时序关系。
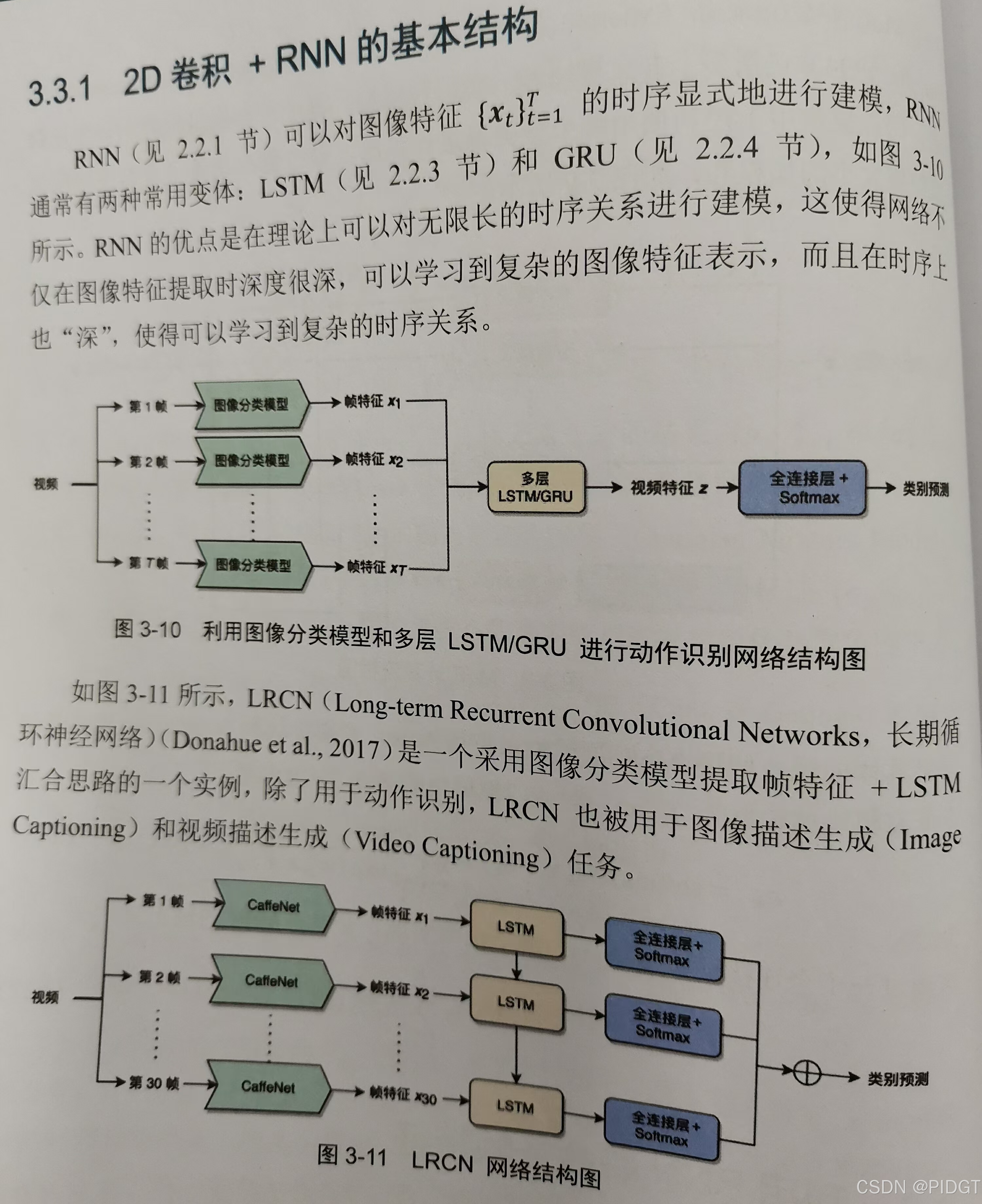
LSTM层数增多 多了之后要短接部分
ConvLSTM 将LSTM的矩阵乘法改成卷积运算。
3D卷积
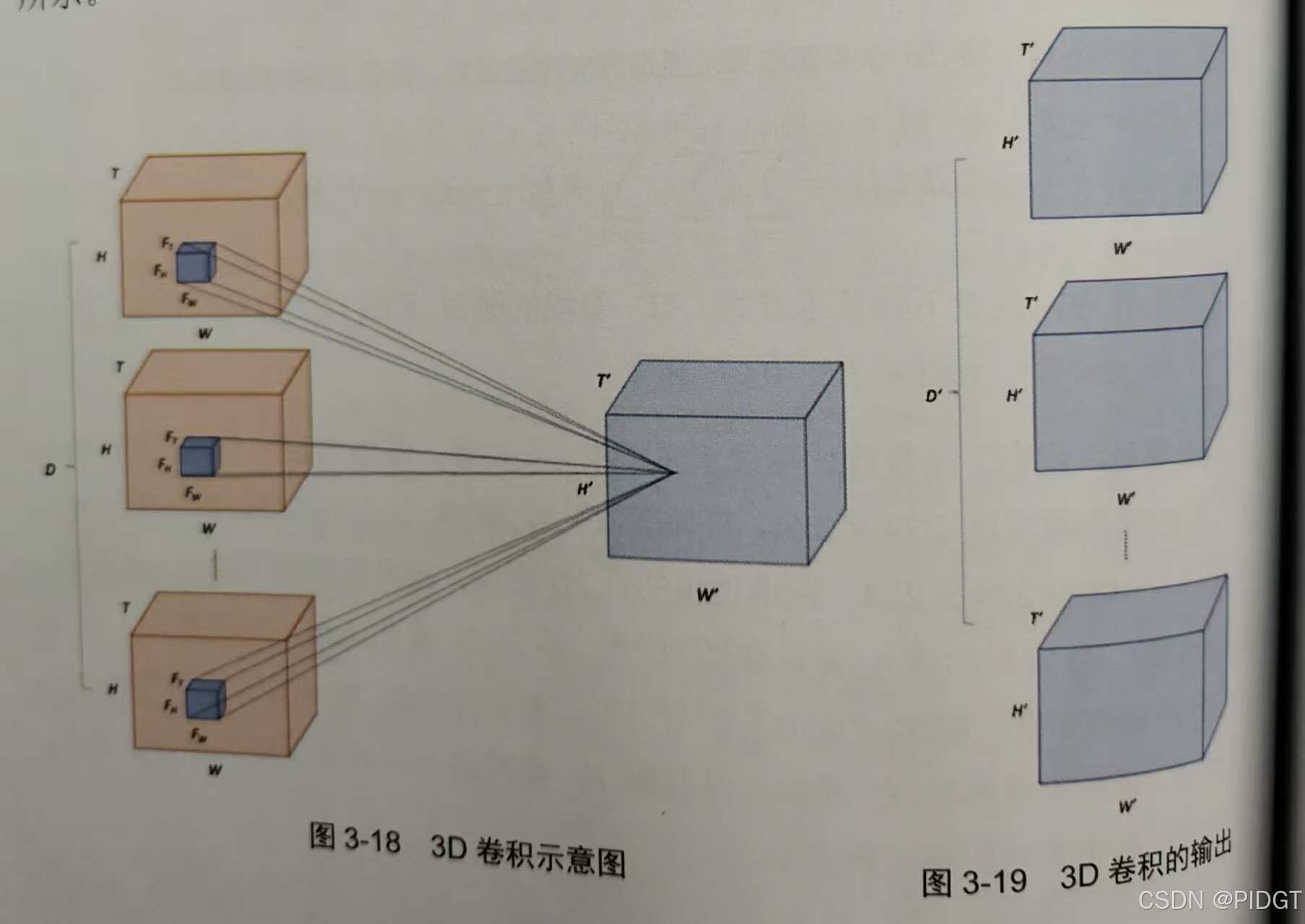

**ECO(Efficent Convolution Network)**图像分类提取特征后用3D卷积融合,视频分T段,每段随机采样一帧
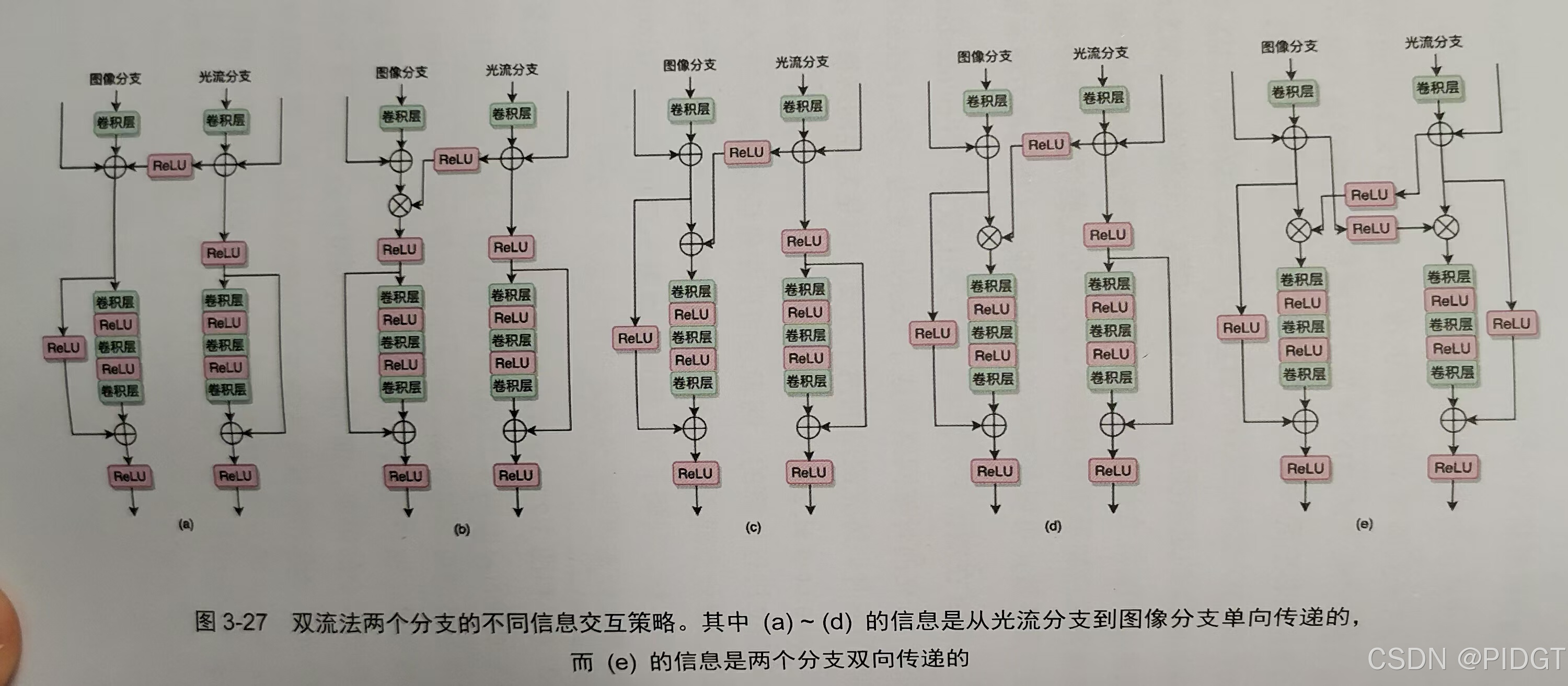
双流法 两个网络,一个进行图像分类,一个从光流中挖掘时序运动关系。2个softmax平分,或者将两个分支规范化后进行SVM训练。训练时光流需要减去所有光流向量的平均值。
对接后用三维卷积和3D汇合,类似ECO。
端到端同时训练两个分支,很容易在图像分支过拟合。过拟合原因可能在于两个分支独立计算,如果双向信息传递,图像分支特征会主导光流分支。
时序稀疏采样 对时序依赖捕获的加强
**TSN(Temporal Segment Networks时序分段网络)**T段,均匀采样一帧图像和若干帧光流,两类分别平均汇合。稀疏+全局。数据增广,进行尺度抖动和长宽比抖动
ActionVLAD 融合位置提前,平均汇合->NetVLAD
**StNet(Spatial-temporal Network)**局部时序用连续5帧,在ResNet后插入两个3D卷积(学习长距离时序关系),网络整体以2D为主。
TRN(Temporal Relation Network时序关系网络)

TDD 结合两种传统算法(iDT+光流)和深度学习算法(双流法):卷积特征->时空规范化+通道规范化 ->基于轨迹汇合->用FisherVector得到TDD特征->SVM分类
基于3D卷积的动作识别
C3D 3D版的VGGNet(时间维度为3,16帧视频片段,前馈速度比双流快,但参数量大,从头训练难度大)
Res3D
LTC (Long-term Temporal Convolution长距离时序卷积) 16~60帧,60帧显著优于16帧。
I3D(two-stream Inflated 3D ConvNets)把双流法的2D卷积神经网络扩展为3D卷积神经网络。用ImageNet预训练参数初始化,沿时间复制
低秩近似 y=Wx~=uvx (对W进行秩1近似)
F(st)CN(Factorized Spatio-Temporal Convolution Network)将3D卷积分解成一个2D卷积+一个1D卷积。底层2D卷积学习空间特征,顶层1D卷积学习时间特征。用帧差替代光流。
P3D(Pseudo 3D) 1x3x3 和3x1x1近似原来3x3x3
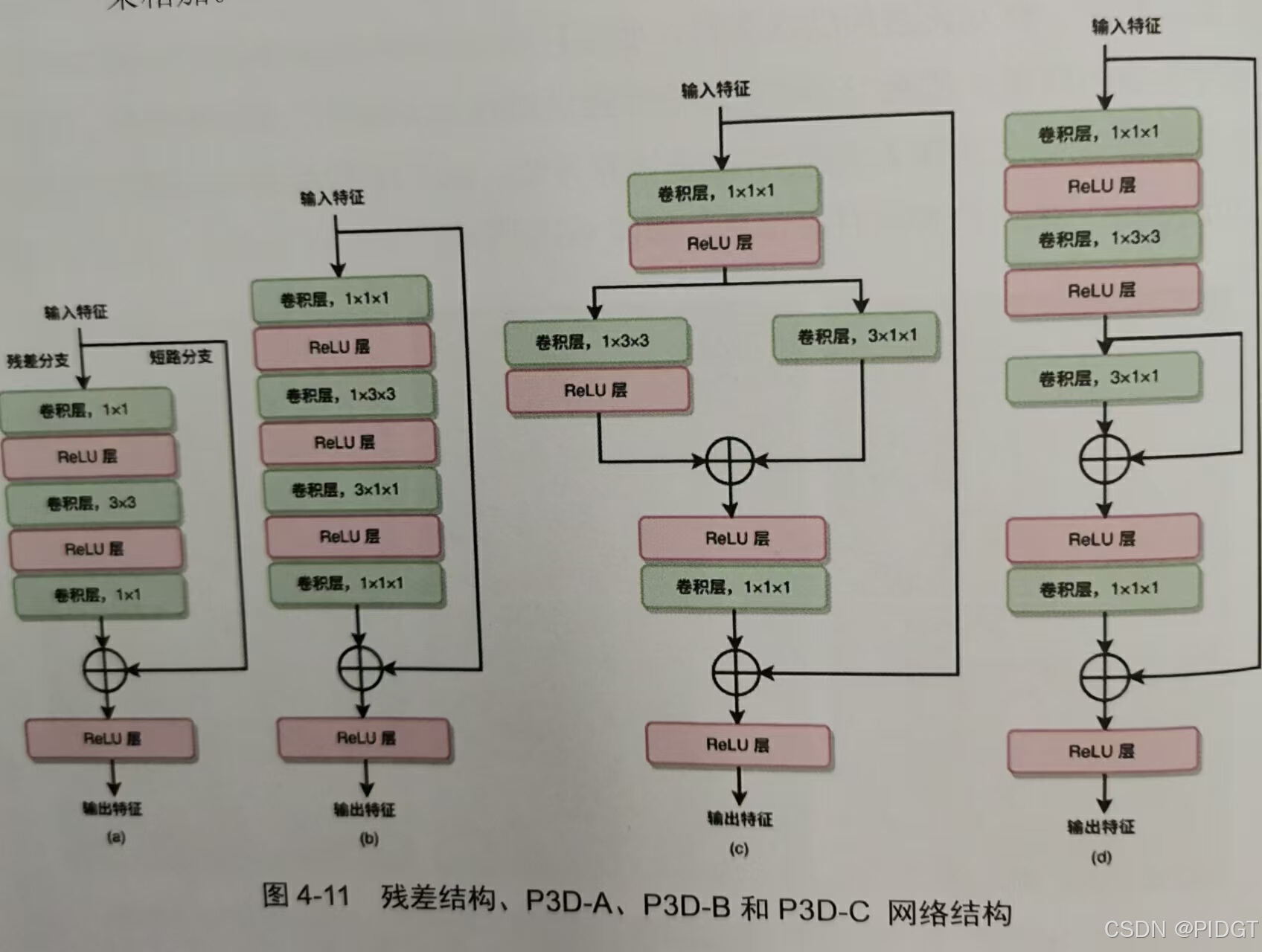

R(2+1)D 类似于P3D-A
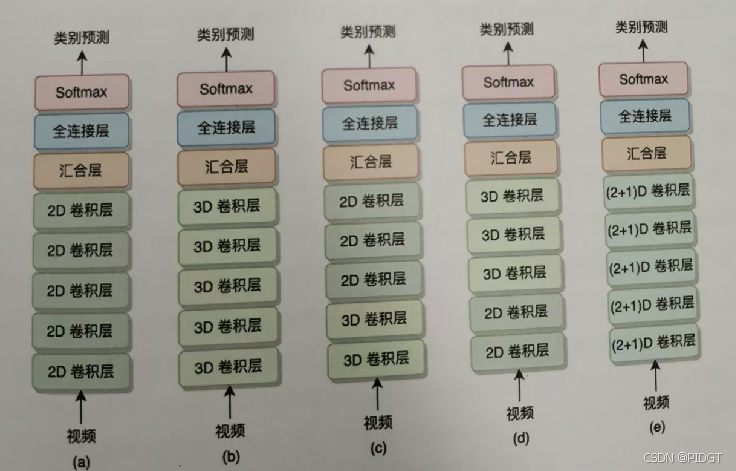
S3D 底层2D顶层3D,Top-heavy结构准确率更高,计算也轻量
TSM(Temporal Shift Module)用2D近似3D,部分通道沿时间维度移位。残差结构,可插入到任意2D卷积
3D+RNN 局部时序+全局时序
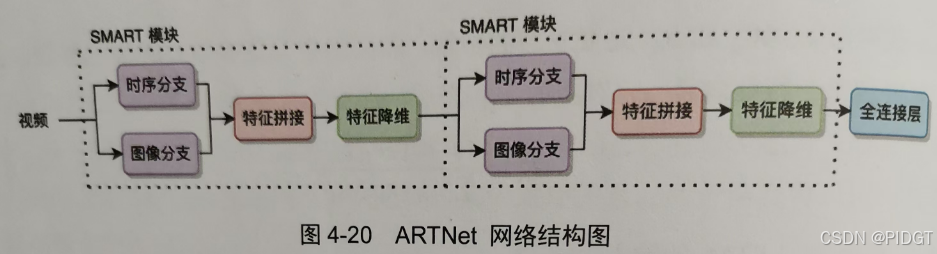
ARTNet(Apperance and Relation Network表象和关系网络)

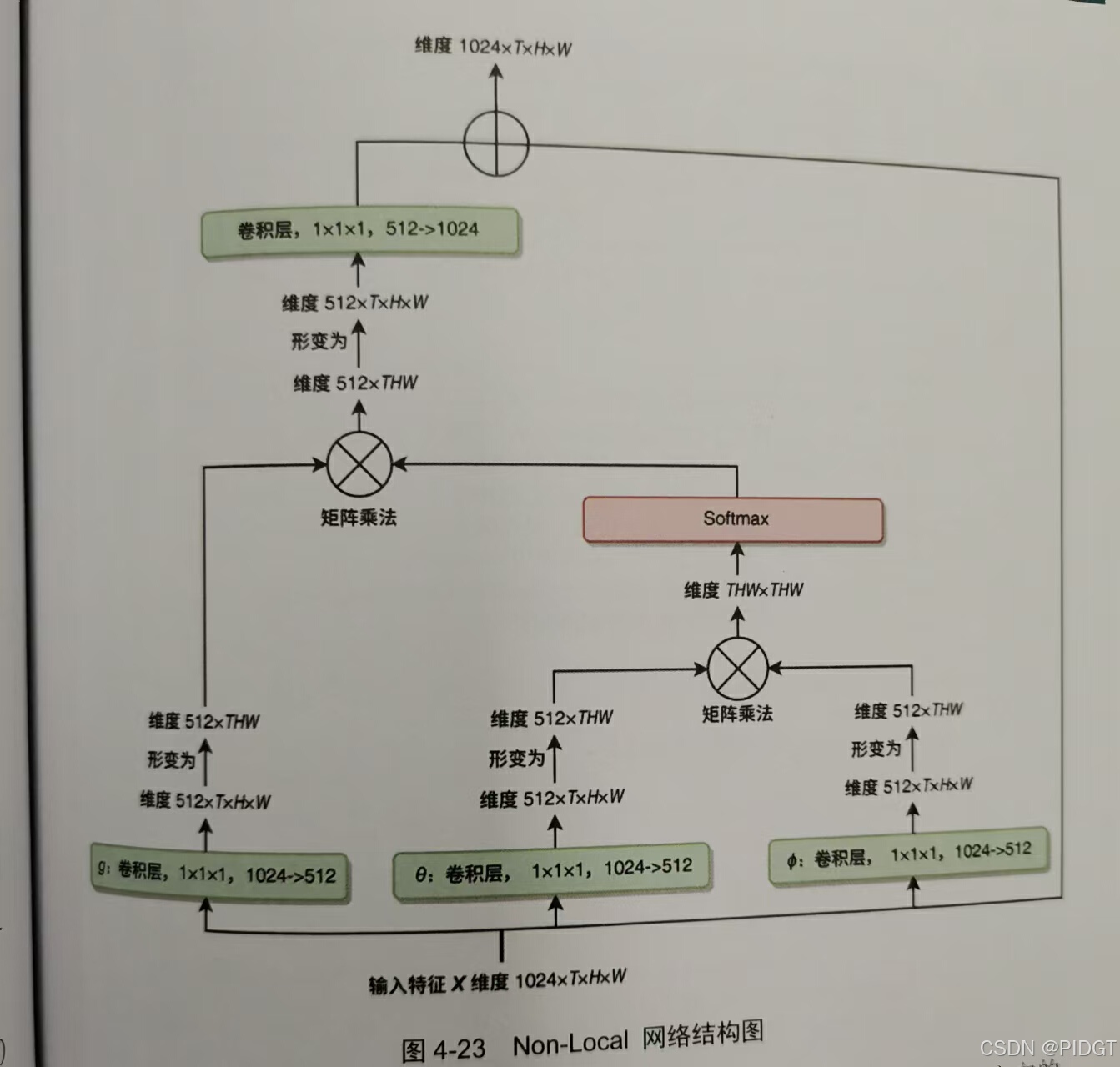
NonLocal 所有空间位置和时间位置的特征加权平均 实际上使用了Embedding后高斯作为f(xi,xj)。在结果yi加了1x1x1卷积和BN层,使输入和输出通道数一致,加入短接变成残差结构。


SlowFast 用两个分支处理慢和块的运动。Slow较少T,较大D,底层2D高层3D;Fast使用较多帧数aT(a=8),较少通道数bD(b=1/8),大量使用3D
多网格训练 BxDxTxHxW,B:batch size批量大小,D=3:视频通道数,T:视频帧数。T,H,W比较大,训练准确率高,B比较小,训练会比较慢。可以考虑早期B较大,较小的T,H,W,后期B小,较大T,H,W
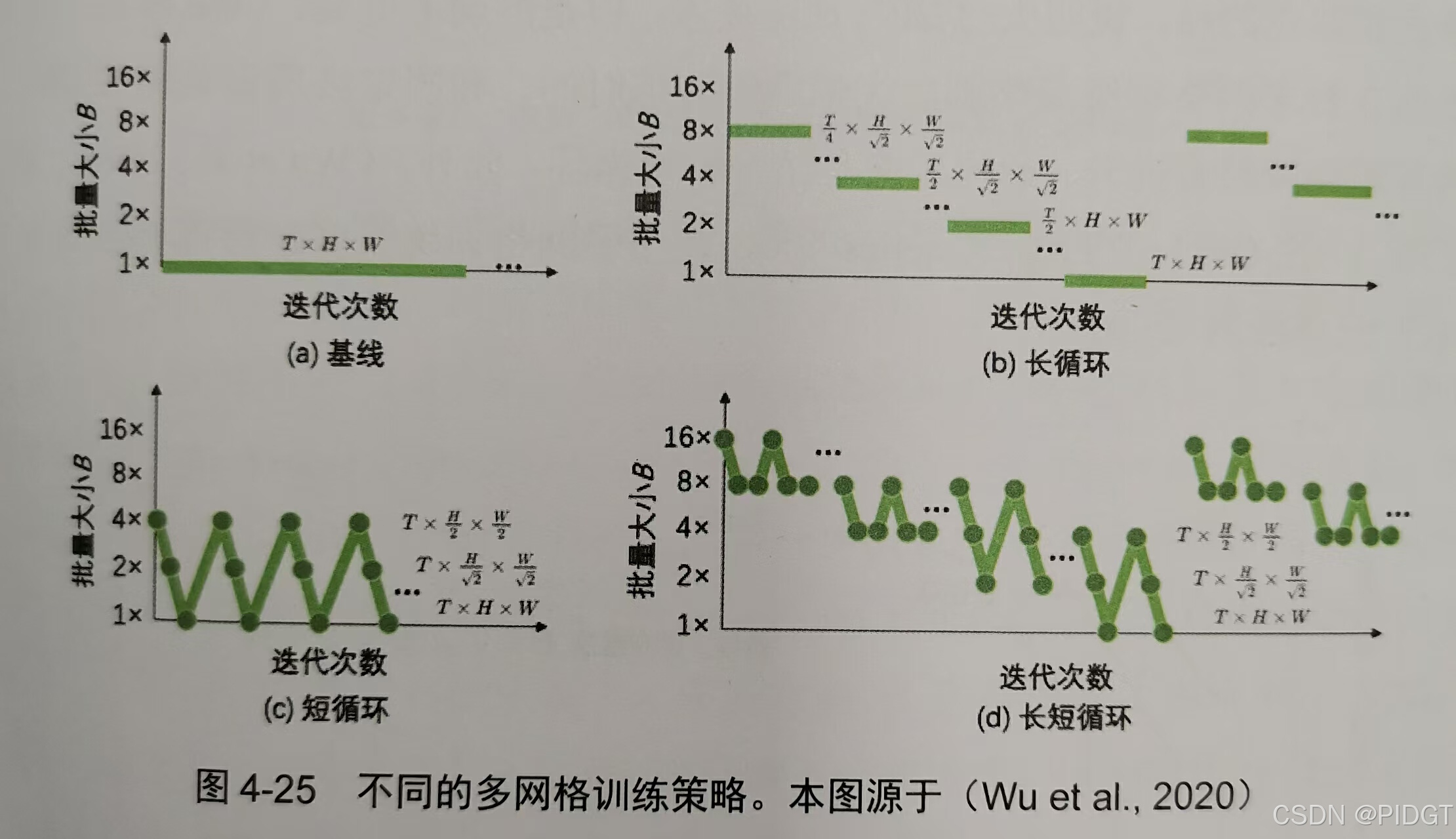
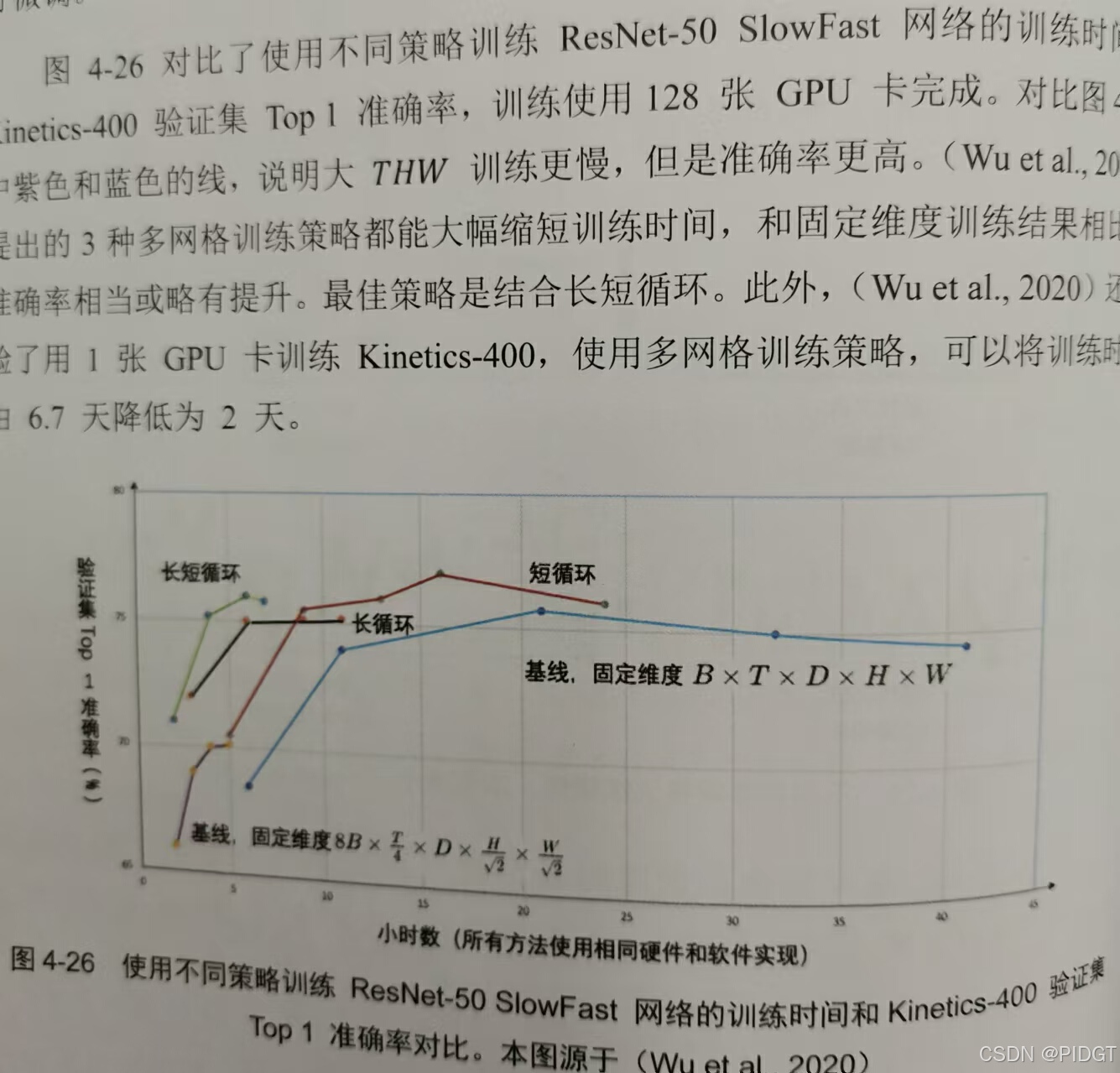
X3D(Expand 3D)希望计算每部最优维度选择。第一次扩展瓶颈宽度,第二次扩展采样率,第三次扩展空间维度,第四次扩展网络深度。较大的空间和时间维度伴随较小的通道数,计算量小,分类准确率也很好,类似于Fast分支。
感谢
图像和文字资料来源张皓的《深度学习视频理解》,部分描述由豆包产生,不得不说目前还是书上的描述更好。

















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









