







 HashMap源码和面试题
HashMap源码和面试题
HashMap的数据结构
JDK1.7 数据结构为:数组+链表的数据结构
构造方法
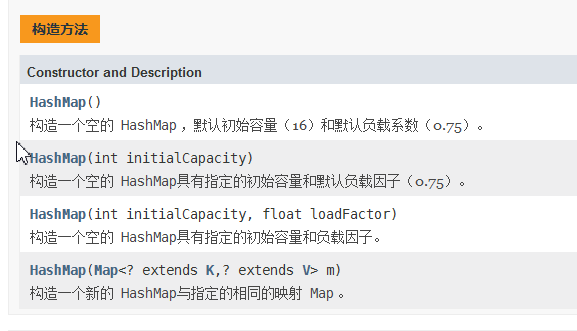
一般我们常用的是第一种,无参构造,这时默认初始容量就是16,默认负载因子是0.75。
这里我们只讨论上面的三个构造,通过查看源码得知,前两个构造方法内部都使用的是第三个构造第三个构造内部首先对传进来的容量和负载因子做判断,主要是看数据是否合规,此时,让扩容阈值等于了初始容量。注意这个时候仅仅是给一些必要的参数赋值,并没有在此时初始化HashMap,没有分配空间。
- put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) { //判断是否内容为空,这里的table是一个键值对数组,默认是空的。
inflateTable(threshold); //如果内容为空,则首先初始化
}
if (key == null) //如果传入的key是null,则调用下面的方法
return putForNullKey(value);
int hash = hash(key); //如果key是存在的,那么计算key的hash
int i = indexFor(hash, table.length);//计算完哈希后,根据哈希和数组长度去计算对应的索引,也就是这个key应该在数组里哪里存储
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//数组中的每个元素是一个链表,已经计算除了索引,所以遍历该索引位置上的链表,目的是为了检查传进来的key是否已经存在在表里
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//如果发现链表上的元素和传进来的key各方面都一样(hash,地址,内容)那么就说明表里已经有了,那么就保持key不变,更新value,并返回旧的value
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++; //被修改次数加一,这个值主要是为了线程安全考虑,和本方法的业务无关
addEntry(hash, key, value, i); //如果是一个新key,则添加元素。
return null;
}
1.初始化具体做了哪些东西“inflateTable(threshold);”
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);//这里可以看到,初始化时,无论传进来的初始容量是多少,都会向上取整为2的幂。也就是说,虽然构造方法中可以让用户自定义容量大小,但是进来后也会向上转成2的幂。当然,如果本身就是2的幂,那么就不会转换了,这里看源码,会发现他做了一个-1操作,目的就是为了防止把正确容量也翻一倍。比如你传进来的是15,那么向上取整为16.如果传进来的是16,向上取整就成了32,这是不合理的,所以任何数在取整时都先-1.
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//计算扩容阈值
table = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2804
2804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









