









文章目录
连通块中点的数量
给定一个包含 n 个点(编号为 1∼n )的无向图,初始时图中没有边。
现在要进行 m 个操作,操作共有三种:
- C a b,在点 a 和点 b 之间连一条边,a 和 b 可能相等;
- Q1 a b,询问点 a 和点 b 是否在同一个连通块中,a 和 b 可能相等;
- Q2 a,询问点 a 所在连通块中点的数量;
输入格式
第一行输入整数 n 和 m 。接下来 m 行,每行包含一个操作指令,指令为
C a b,Q1 a b或Q2 a中的一种。输出格式 对于每个询问指令
Q1 a b,如果 a 和 b 在同一个连通块中,则输出 Yes,否则输出 No。对于每个询问指令
Q2 a,输出一个整数表示点 a 所在连通块中点的数量每个结果占一行。
数据范围
1 ≤ n,m ≤ 105
输入样例:
5 5
C 1 2
Q1 1 2
Q2 1
C 2 5
Q2 5
输出样例:
Yes
2
3
思路
关于合并集合方面的思想,请参考上一篇文章 http://t.csdnimg.cn/Ytcdj
因为与合并集合题目中唯一不同的是,多了记录合并集合中连通块的个数
通过size数组记录以当前点x为祖先节点的集合中的连通块个数
for(int i = 0; i <= n; i ++) {
p[i] = i;
//用祖先节点记录当前合并集合的size
size[i] = 1;
}
初始化,让自己指向自己,同时标记自己为祖先节点下,有多少个连通块,初始为1
什么时候改变连通块的个数呢?
合并的时候
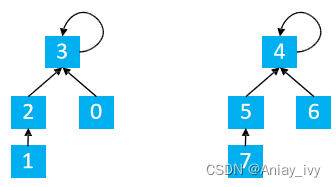
显然,将1,5合并
find(1) = 3 find(5) = 4
p[3] = 4
这时候有8个点相连接
合并的数目更新方式:
size[3] = 4 以3为根节点下有4个连通块
size[4] = 4 以4为根节点下有4个连通块
更新4节点的连通块情况
size[4] = size[4] + size[3] = 8
代码
java
import java.util.*;
public class Main{
static int n, m;
static int N = 100010;
static int[] p = new int[N], size = new int[N];
public static int find(int x){
if(x != p[x]) p[x] = find(p[x]);
return p[x];
}
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
for(int i = 0; i <= n; i ++) {
p[i] = i;
//用祖先节点记录当前合并集合的size
size[i] = 1;
}
while(m -- > 0){
String opt = sc.next();
if(opt.equals("C")){
int a = sc.nextInt();
int b = sc.nextInt();
if(find(a) == find(b)) continue;
// 下面两行代码注意顺序
size[find(b)] += size[find(a)];
p[find(a)] = find(b);
}else if(opt.equals("Q1")){
int a = sc.nextInt();
int b = sc.nextInt();
if(find(a) == find(b)) System.out.println("Yes");
else System.out.println("No");
}else{
int a = sc.nextInt();
System.out.println(size[find(a)]);
}
}
}
}
C++ 代码
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int p[N], s[N];
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main(){
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++){
p[i] = i;
s[i] = 1;
}
while(m --)
{
char op[5];
int a, b;
scanf("%s", op);
if(op[0] == 'C'){ //合并
scanf("%d%d", &a, &b);
if(find(a) == find(b)) continue;
s[find(b)] += s[find(a)];
p[find(a)] = find(b);
}
else if(op[1] == '1'){ //Q1
scanf("%d%d", &a, &b);
if(find(a) == find(b)) puts("Yes");
else puts("No");
}
else{
scanf("%d", &a);
printf("%d\n", s[find(a)]);
}
}
return 0;
}
食物链
动物王国中有三类动物 A,B,C ,这三类动物的食物链构成了有趣的环形。
A 吃 B ,B 吃 C ,C 吃 A 。
现有 N 个动物,以 1∼N 编号。
每个动物都是 A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 N 个动物所构成的食物链关系进行描述:
第一种说法是
1 X Y,表示 X 和 Y 是同类。第二种说法是
2 X Y,表示 X 吃 Y 。此人对 N 个动物,用上述两种说法,一句接一句地说出 K 句话,这 K 句话有的是真的,有的是假的。
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
- 当前的话与前面的某些真的话冲突,就是假话;
- 当前的话中 X 或 Y 比 N 大,就是假话;
- 当前的话表示 X 吃 X ,就是假话。
你的任务是根据给定的 N 和 K 句话,输出假话的总数。
输入格式
第一行是两个整数 N 和 K ,以一个空格分隔。以下 K 行每行是三个正整数 D,X,Y ,两数之间用一个空格隔开,其中 D 表示说法的种类。
若 D=1 ,则表示 X 和 Y 是同类。
若 D=2 ,则表示 X 吃 Y 。
输出格式
只有一个整数,表示假话的数目。数据范围
1 ≤ N ≤ 50000 ,
0 ≤ K ≤ 100000
输入样例:
100 7
1 101 1
2 1 2
2 2 3
2 3 3
1 1 3
2 3 1
1 5 5
输出样例:
3
带扩展域的并查集
首先, 在带扩展域的并查集 中 x 不再只是一个 值,而是一个事件;
规定 x 为 "事件 x 为 A 类动物";
规定 x + N 为 "事件 x 为 B 类动物";
规定 x + N * 2 为 "事件 x 为 C 类动物";
p[find(X)] = find(Y) 表示
事件 X 为 A 类动物 和 事件 Y 为 A 类动物 同时发生
X 与 Y 为同种动物 等价于
p[ find(X) ] = find(Y);
p[ find(X + N)] = find(Y + N);
p[ find(X + N * 2)] = find(Y + N * 2);
p[find(X)] = find(Y + N) 表示
事件 X 为 A 类动物 和 事件 Y 为 B 类动物 同时发生
X 吃 Y 等价于
p[ find(X) ] = find(Y + N);
p[ find(X + N)] = find(Y + N * 2);
p[ find(X + N * 2)] = find(Y);
代码
#include<iostream>
using namespace std;
const int N = 5e4 + 10, M = N * 3;
int n, m;
int p[M];
inline int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
cin >> n >> m;
for (int i = 1; i < M; i++) p[i] = i;
int res = 0;
while (m--)
{
int d, a, b;
scanf("%d%d%d", &d, &a, &b);
if (a > n || b > n)
{
res ++;
continue;
}
if (a == b)
{
if (d == 2) res ++;
continue;
}
if (d == 1)
{
// 如果 a 吃 b 或者 b 吃 a ,则 a 与 b 是同类是假话
if (find(a) == find(b + N) || find(a + N) == find(b))
{
res++;
continue;
}
p[find(a)] = find(b);
p[find(a + N)] = find(b + N);
p[find(a + N * 2)] = find(b + N * 2);
}
else
{
// 如果 b 吃 a 或者 a 与 b 是同类 ,则 a 吃 b 是假话
if (find(a + N) == find(b) || find(a) == find(b))
{
res++;
continue;
}
p[find(a)] = find(b + N);
p[find(a + N)] = find(b + N * 2);
p[find(a + N * 2)] = find(b);
}
}
cout << res;
return 0;
}
带边权的并查集
数组d的真正含义以及find()函数调用过程
核心代码
int find(int x)
{
if(p[x] != x)
{
int tmp = find(p[x]);
d[x] += d[p[x]];
p[x] = tmp;
}
return p[x];
}
注意事项,即明白 d[i] 的含义
d[i]的正确理解,应是第 i 个节点到其父节点距离,而不是像有些人所讲的,到根节点的距离!!这点大家一定要搞清楚,之所以有这样的误会,是因为find()函数进行了路径压缩,当查询某个节点 i 时,如果 i 的父节点不为根节点的话,就会进行递归调用,将 i 节点沿途路径上所有节点均指向父节点,此时的 d[i] 存放的是 i 到父节点,也就是根节点的距离。

代码
C ++
#include<iostream>
using namespace std;
const int N = 5e4 + 10;
int n, k;
int p[N], d[N];
int res;
int find(int x)
{
if (p[x] != x)
{
int t = find(p[x]); //开始递归;最终用t储存根节点
d[x] += d[p[x]]; //在递归过程中求得每个点到根节点的距离
p[x] = t; //将每个点的父节点指向根节点
}
return p[x]; //返回父节点
}
int main()
{
cin >> n >> k;
for (int i = 0; i < n; i++) p[i] = i;
while (k--)
{
int c, x, y;
cin >> c >> x >> y;
int px = find(x), py = find(y); //px,py分别储存根节点
if (x > n || y > n) res++;
else if (c == 1)
{
if (px == py && (d[x] - d[y]) % 3) res++;
if (px != py)
{
p[px] = py;
d[px] = d[y] - d[x]; //(d[x]+d[px]-d[y])%3==0
}
}
else if (c == 2)
{
if (px == py && (d[x] - d[y] - 1) % 3) res++;
if (px != py)
{
p[px] = py;
d[px] = d[y] + 1 - d[x]; //(d[x]+d[px]-d[y]-1)%3==0
}
}
}
cout << res;
return 0;
}
Java
import java.util.*;
import java.io.*;
public class Main {
static int N = 50010;
static int n, m; //n个动物,m句话
static int[] p = new int[N];//p[]是父节点
static int[] d = new int[N];//d[]表示到父节点的距离,在find之后,x的父节点变成祖宗节点,所以变成了到根节点的距离
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
public static void main(String[] args ) throws IOException{
String[] str = br.readLine().split(" ");
n = Integer.parseInt(str[0]);
m = Integer.parseInt(str[1]);
for(int i = 0; i < n; i ++ ) p[i] = i; //初始化并查集
int res = 0;// 记录谎话的个数
while(m -- > 0)
{
String[] strs = br.readLine().split(" ");
int t = Integer.parseInt(strs[0]);
int x = Integer.parseInt(strs[1]);
int y = Integer.parseInt(strs[2]);
if(x > n || y > n) res ++; //X或Y比N大是假话
else
{
int px = find(x), py = find(y); //先找到x,y的根节点px,py
if(t == 1) //表示说x和y是同类
{
if(px == py && (d[x] - d[y]) % 3 != 0) res ++; //但寻找根节点发现不是同类,那么是谎话
else if(px != py)//如果还没在一个集合中,那就加到一个集合中,并更新d[],由于是第一次说xy关系,所以是真话
{
p[px] = py;//px的根节点指向py
d[px] = d[y] - d[x]; //因为px和py之间也有一条边,所以得更新权值
}
}
else //吃的关系
{
if(px == py && (d[x] - d[y] - 1) % 3 != 0) res ++; //在一个集合里面,不满足x吃y的关系,那么为假话
else if(px != py)
{
p[px] = py;
d[px] = d[y] + 1 - d[x];
}
}
}
}
System.out.println(res);
}
static int find(int x) ///返回x的祖宗节点,也就是返回x的所在集合编号 + 路径压缩
{
if(p[x] != x) //如果x不是树根
{
int t = find(p[x]);
d[x] += d[p[x]];
p[x] = t;
}
return p[x];
}
}















 4059
4059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









