







数据结构入门学习(全是干货)——基本概念
数据结构定义
- 数据结构(Data Structure)是指一种组织、管理和存储数据的方式,以便高效地访问和修改。数据结构不仅包括数据的存储格式,还包括操作这些数据的方法。
三个例子
a. 例1:如何在书架上摆放图书
- 在书架上摆放图书可以类比为一种数据结构的操作过程。通常,我们会根据书籍的主题、作者或字母顺序将它们分类,类似于数组中的有序排列。通过这种方式,可以在查找某一本书时更高效地进行访问。
b. 二分查找
-
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
二分查找的步骤:
- 首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字进行比较。
- 如果两者相等,则查找成功。
- 否则,利用中间位置记录将表分成前、后两个子表:
- 如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表。
- 如果中间位置记录的关键字小于查找关键字,则进一步查找后一子表。
- 重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
c. 例2:实现一个函数 PrintN 打印1到N的正整数
函数实现示例:
//循环实现
void PrintN ( int N )
{
int i;
for( i=1 ;i<=N ;i++){
printf("%d\n",i);
}
return;
}
//递归实现 弊端:递归的程序对空间的占用有的时候是很恐怖的
void PrintN ( int N )
{
if( N ){
printN( N - 1 );
printf("%d\n",N);
}
return;
}
//解决问题方法的效率,也跟空间的利用效率有关
功能描述:
- 函数
PrintN接收一个正整数N作为参数。 - 它会顺序打印从 1 到
N的所有正整数,每个整数占一行。
d. 例3:写程序计算给定多项式在给定点x处的值
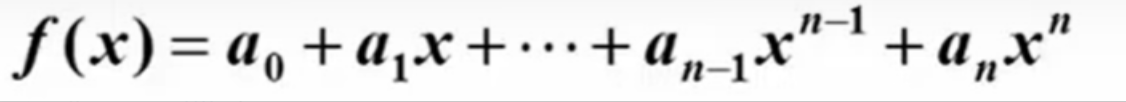
//直接翻译的结构
double f( int n, double a[], double x)
{
int i;
double p = a[0];
for ( i = 0 ; i <= n ; i++ ){
p += (a[i] * pow(x,i));
}
return p;
}
//秦久邵的方法
double f( int n, double a[], double x)
{
int i;
double p = a[n]
for( i = n ; i > 0 ; i-- ){
p = a[i-1] + x * p;
}
return p;
}
秦久邵的方法公式图
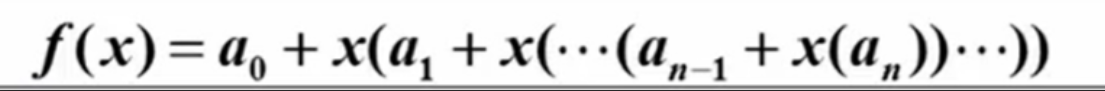
clock():捕捉从程序开始运行到clock()被调用时所耗费的时间。这个时间单位是clock tick,即"时钟打点"
常数CLK_TCK:机器时钟每秒所走的时钟打点数
//这套流程的模板
#include <stdio.h>
#include <time.h>
clock_t start,stop;//clock_t是clock()函数返回的变量类型
double duration;//记录被测函数的运行时间
int main()
{//不在测试范围内的准备工作写在clock()调用之前
start = clock();//开始计时
MyFunction();//把被测函数加在这里
stop = clock();//停止计时
duration = ((double)(stop - start))/CLK_TCK;//计算时间
//其他不在测试范围的处理写在后面,例如输出duration的值
return 0;
}
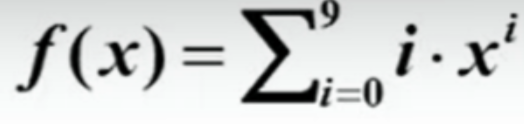
尝试计算这个图中的式子跑了多久
#include<stdio.h>
#include<time.h>
#include<math.h>
clock_t start,stop;
double duration;
#define ,MAXN 10 //多项式最大项数,即多项式阶数+1
double f1(int n , double a[] , double x);
double f2(int n , double a[] , double x);
int main()
{
int i;
double a[MAXN];//存储多项式的系数
for (i = 0; i < MAXN; i++) a[i] = (double)i;
//不在测试范围内的准备工作写在clock()调用之前
start = clock();//开始计时
f1(MAXN-1 , a , 1.1);//把被测函数加在这里
stop = clock();//停止计时
duration = ((double)(stop - start))/CLK_TCK;//计算时间
//其他不在测试范围的处理写在后面,例如输出duration的值
printf("ticks1 = %f\n",(double)(stop-start));
printf("duration1 = %6.2e\n",duration);
start = clock();//开始计时
f2(MAXN-1 , a , 1.1);//把被测函数加在这里
stop = clock();//停止计时
duration = ((double)(stop - start))/CLK_TCK;//计算时间
//其他不在测试范围的处理写在后面,例如输出duration的值
printf("ticks1 = %f\n",(double)(stop-start));
printf("duration2 = %6.2e\n",duration);
return 0;
}
//跑出来结果都是0,因为运行太快了,clock函数捕捉不到它的区别
//解决方案:让被测函数重复运行充分多次,使得测出的总的时钟打点间隔充分长,最后计算被测函数平均每次运行的时间即可
以下是解决方案修改后的函数,只截取修改的部分
#define ,MAXK 1e7 //被测函数最大重复调用次数
double f1(int n , double a[] , double x);
double f2(int n , double a[] , double x);
int main()
{
int i;
double a[MAXN];//存储多项式的系数
for (i = 0; i < MAXN; i++)//重复调用函数以获得充分多的时钟打点数
f1(MAXN-1,a,1.1);
stop = clock();
start = clock();//开始计时
duration = ((double)(stop - start))/CLK_TCK/MAXK;//计算函数单词运行的时间
//其他不在测试范围的处理写在后面,例如输出duration的值
printf("ticks1 = %f\n",(double)(stop-start));
printf("duration1 = %6.2e\n",duration);
//以下第二个f2保持不变进行对比
start = clock();//开始计时
f2(MAXN-1 , a , 1.1);//把被测函数加在这里
stop = clock();//停止计时
duration = ((double)(stop - start))/CLK_TCK;//计算时间
//其他不在测试范围的处理写在后面,例如输出duration的值
printf("ticks1 = %f\n",(double)(stop-start));
printf("duration2 = %6.2e\n",duration);
return 0;
}
解决问题方法的效率,跟算法的巧妙程度有关
什么是数据结构
1. 数据对象在计算机中的组织方式
a. 逻辑结构
- 线性结构(一对一):如链表、栈、队列。
- 树形结构(一对多):如二叉树、B树。
- 图的结构(多对多):如无向图、有向图。
b. 物理存储结构
- 顺序存储:数据存储在连续的存储单元中,如数组。
- 链式存储:数据存储在不连续的存储单元中,借助指针进行连接,如链表。
c. 抽象数据类型 (Abstract Data Type, ADT)
ⅰ. 数据类型
- 数据对象集:数据的种类、形态等,即“是什么东西”。
- 数据集合相关联的操作集:可以对这些数据执行哪些操作。
ⅱ. 抽象的特点
- 与具体的机器硬件无关。
- 与数据存储的物理结构无关。
- 与实现操作的算法和编程语言无关。
- 只描述数据对象集和相关操作集“是什么”,不关心“如何做到”。
2. 数据对象必定与一系列操作相关联
每个数据对象都有一组操作方法,完成这些操作的方式就是算法。
例4:矩阵的抽象数据类型定义
1. 类型名称:矩阵 (Matrix)

Multiply:代表矩阵的乘法操作。
举例:
- a是矩阵元素的值,可能使用二维数组、十字链表存储,但我们无需关心其具体存储方式。
Matrix Add(…):关于矩阵相加操作,不必关心按行或按列加,亦不涉及使用哪种编程语言。这体现了抽象的本质。
什么是算法
1. 定义
算法 (Algorithm) 是一种解决问题的有限指令集,具有以下特征:
- a:有限的指令集。
- b:接受输入(某些情况下不需要输入)。
- c:产生至少一个输出。
- d:在有限步骤内终止,避免无限循环。
- e:每条指令必须具有明确的目标。
- f:描述应抽象,不依赖于具体实现手段。
例1:选择排序算法的伪代码描述
void SelectionSort ( int List[], int N)
{
//将N个整数List[0]...List[N-1]进行非递减排序
for(i = 0; i < N; i++){
MinPosition = ScanForMin(List, i, N-1);
//ist[i]到List[N-1]中找最小元,并将其位置赋给MinPosition;
Swap(List[i],List[MinPosition]);
//排序部分的最小元换到有序部分的最后位置;
}
}
//这不是C语言,虽然他带有C语言的一些特征,但他for循环里面的内容是用自然语言来描述的.上面伪码描述特点:抽象
抽象----
List到底是数组还是链表(虽然看上去很像数组)? 其实不管是数组还是链表都不会报错
Swap用函数还是用宏去实现(虽然他看上去很像一个函数)? 但其实用宏写也可以,在我们使用算法的时候是不关心de
什么是好的算法?
1. 空间复杂度 S(n)
空间复杂度描述的是算法在执行时所占用的存储空间,通常与输入数据的规模n有关。如果空间复杂度过高,可能会导致程序使用过多的内存,进而引发内存超限或程序异常终止的情况。
2. 时间复杂度 T(n)
时间复杂度是指算法在执行过程中消耗的时间,与输入数据规模n直接相关。如果时间复杂度过高,算法的运行时间可能会非常长,甚至在大量数据的情况下,可能在现实时间内无法得到结果。
n 是输入数据的规模,程序的执行时间和所需空间与此规模紧密相关。
//递归实现 弊端:递归的程序对空间的占用有的时候是很恐怖的
void PrintN ( int N )
{
if( N ){
//假设N=10w,第一步就是10w-1,调用这个函数之前,你的系统需要把当前的这个函数所有的现有的状态都存到系统内存的某一个地方
//原本是存一下使用后就可以删掉了,使用递归之后在你执行10w-99999之前要把前面所有的运算先执行一遍而不是直接10w-99999,一次性存这么多内容,内存会爆掉的
//S(N)=C(常数)*N =>线性增长
printN( N - 1 );
printf("%d\n",N);
}
return;
}
借用上面例3的案例
//计算机算加减比算乘除快很多
//直接翻译的结构
double f( int n, double a[], double x)
{
int i;
double p = a[0];
for ( i = 0 ; i <= n ; i++ ){
p += (a[i] * pow(x,i));
}
return p;
}//这里一共运行了(1+2+...+n)=(n²+n)/2次乘法 时间复杂度:T(n) = C1n² +C2n
//秦久邵的方法
double f( int n, double a[], double x)
{
int i;
double p = a[n]
for( i = n ; i > 0 ; i-- ){
p = a[i-1] + x * p;
}
return p;
}//这里一共就运行了n次乘法 时间复杂度:T(n) = C *n

复杂度的渐进表示法
复杂度分析通常使用渐进表示法,包括:
- O(大O表示法):表示时间或空间复杂度的上界,通常是最小的那个上界。
- Ω(大Ω表示法):表示复杂度的下界,通常是我们能够找到的最大的下界。
通过这些表示法,可以对算法在最坏和最好情况下的性能进行理论分析。

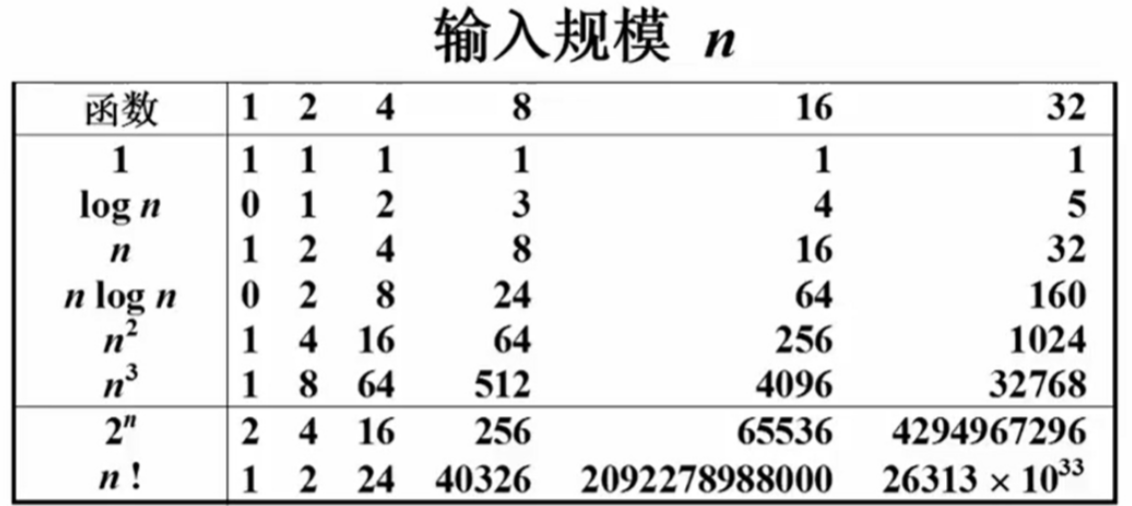
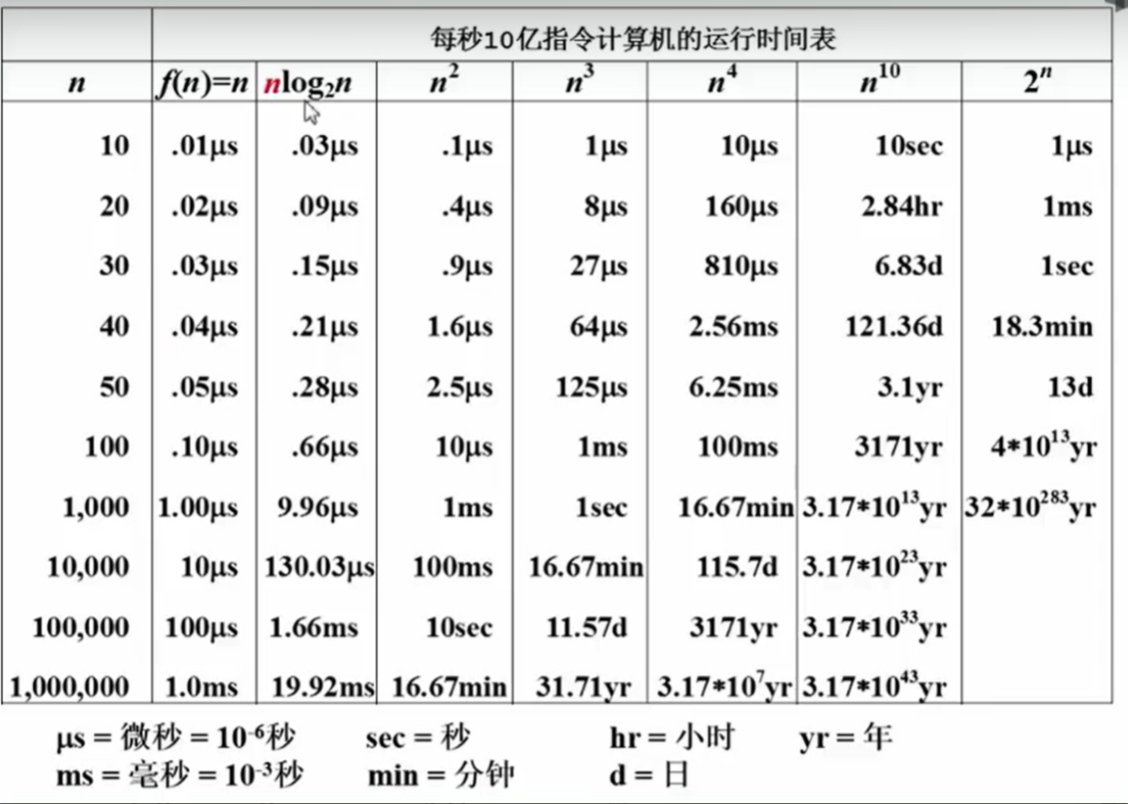
复杂度分析窍门

- 如果有两段算法,其总复杂度是两者复杂度的和,整体复杂度取两者中较大的那一项。
- 当两段算法嵌套时,复杂度为它们的复杂度乘积。
- 对于多项式复杂度T(n),只有最高次项的复杂度最为重要,其他次项可忽略不计。
例如,for循环的时间复杂度等于循环次数乘以循环体代码的复杂度。
应用实例:最大子列和问题

分治法分析最大子列和
在最大子列和问题中,算法的时间复杂度主要受输入规模n的影响,使用分治法时,可以将问题分为若干子问题求解。最大子列和可以通过以下几种方式求得:
- 区间 [L, mid] 的最大子列和。
- 区间 [mid, R] 的最大子列和。
- 区间 [L, mid] 的所有元素和,加上区间 [mid, R] 的最大前缀和。
- 区间 [mid, R] 的所有元素和,加上区间 [L, mid] 的最大后缀和。
//这是一个从Ai到Aj连续的一段子列的和
//复杂度:T(N) = O(N³),因为三层嵌套的for循环
//算法2:上面中的k循环其实是没有必要的,属于多余的。我只需要在前面一个j的基础上加一个元素就好了
int MaxSubseqSum1( int A[], int N)
{
int ThisSum,MaxSum = 0;
int i,j,k;
for( i = 0 ; i < N ;i++ ){
//i是子列左端位置
ThisSum = 0;//This是从A[i]到A[j]的子列和
for( j = i ; j < N; j++ ){
//j是子列右端位置
ThisSum += A[j];//对于相同的i,不同的j,只要在j-1次循环的基础上累加1项即可
if(ThisSum > MaxSum);//如果刚得到的这个子列和更大
MaxSum = ThisSum;//则更新结果
}//j循环结束
}//i循环结束
return MaxSum;
}
//复杂度是:T(N) = O(N²),因为两层嵌套的for循环
//算法3:分而治之:把一个比较大的复杂问题切分成小块,然后分头解决,最后再把结果合并起来,这就是分而治之
//第一步:先"分",也就是说把数组从中间一分为二(二分法),然后递归地去解决左右两边的问题
//递归地去解决左边的问题,我们会得到左边的一个最大子列和,同理得到右边的最大子列和
//特殊情况:跨越边界的最大子列和
//第二步:后"合"找到两个最大子列和和这个跨越边界的最大子列和后,最后的结果一定是这三个数中间最大的那一个
#include <stdio.h>
int Max3( int A, int B, int C )
{ /* 返回3个整数中的最大值 */
return A > B ? A > C ? A : C : B > C ? B : C;
}
int DivideAndConquer( int List[], int left, int right )
{ /* 分治法求List[left]到List[right]的最大子列和 */
int MaxLeftSum, MaxRightSum; /* 存放左右子问题的解 */
int MaxLeftBorderSum, MaxRightBorderSum; /*存放跨分界线的结果*/
int LeftBorderSum, RightBorderSum;
int center, i;
if( left == right ) { /* 递归的终止条件,子列只有1个数字 */
if( List[left] > 0 ) return List[left];
else return 0;
}
/* 下面是"分"的过程 */
center = ( left + right ) / 2; /* 找到中分点 */
/* 递归求得两边子列的最大和 */
MaxLeftSum = DivideAndConquer( List, left, center );
MaxRightSum = DivideAndConquer( List, center+1, right );
/* 下面求跨分界线的最大子列和 */
MaxLeftBorderSum = 0; LeftBorderSum = 0;
for( i=center; i>=left; i-- ) { /* 从中线向左扫描 */
LeftBorderSum += List[i];
if( LeftBorderSum > MaxLeftBorderSum )
MaxLeftBorderSum = LeftBorderSum;
} /* 左边扫描结束 */
MaxRightBorderSum = 0; RightBorderSum = 0;
for( i=center+1; i<=right; i++ ) { /* 从中线向右扫描 */
RightBorderSum += List[i];
if( RightBorderSum > MaxRightBorderSum )
MaxRightBorderSum = RightBorderSum;
} /* 右边扫描结束 */
/* 下面返回"治"的结果 */
return Max3( MaxLeftSum, MaxRightSum, MaxLeftBorderSum + MaxRightBorderSum );
}
int MaxSubseqSum3( int List[], int N )
{ /* 保持与前2种算法相同的函数接口 */
return DivideAndConquer( List, 0, N-1 );
}
int main() {
int k;
scanf("%d", &k);
int a[k] = {0};
for (int i = 0 ; i < k; i++)
scanf("%d", &a[i]);
printf("%d\n", MaxSubseqSum3(a, k));
return 0;
}
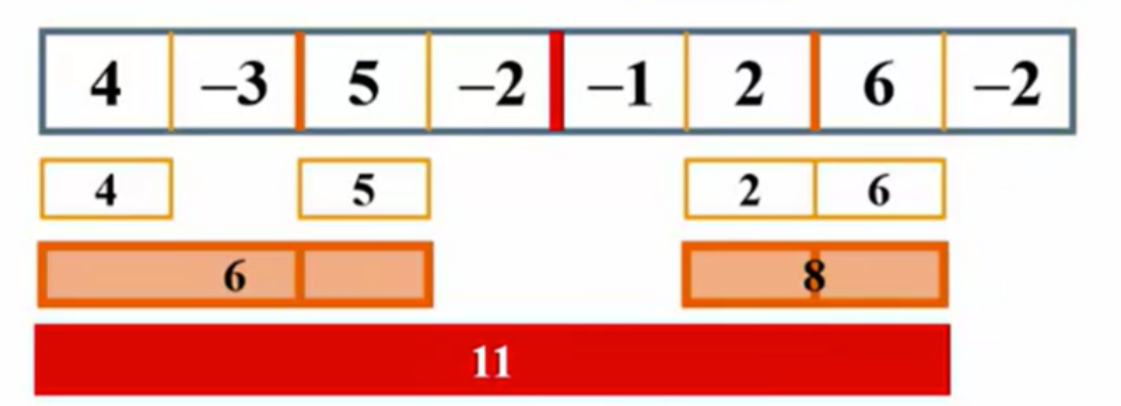
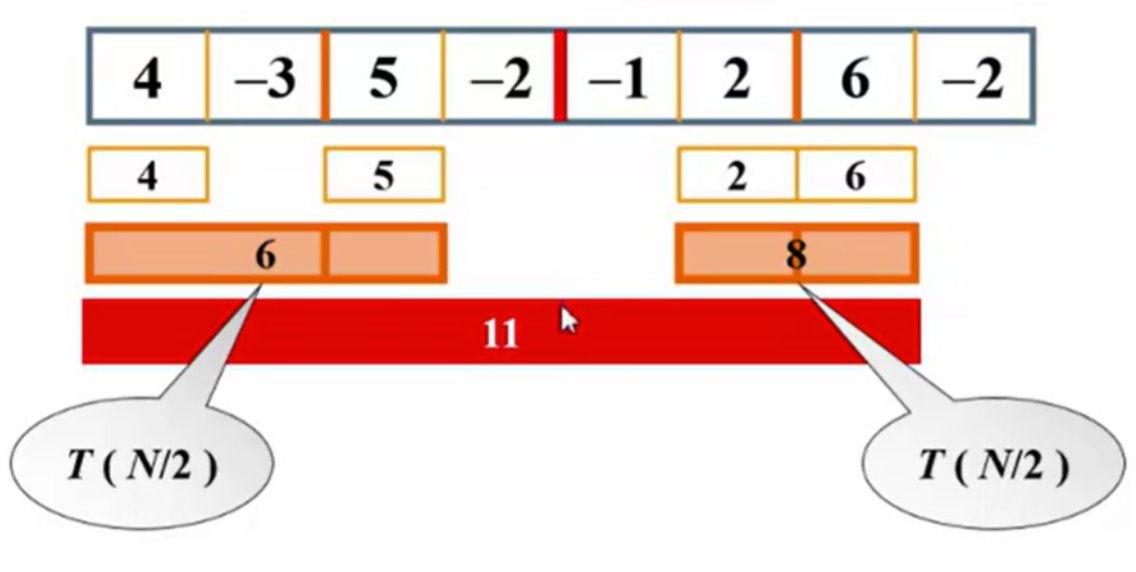
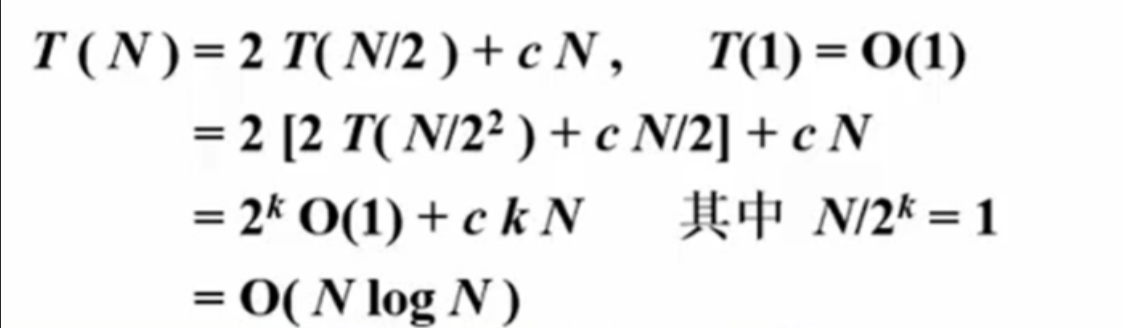
算法4:在线处理算法
在线处理是指算法可以处理一组输入数据,并在每次接收到新数据时立即处理,始终保持当前最优解。例如,在求解最大子列和问题时,每输入一个新元素,算法可以即时更新结果,无需等待所有输入完成后再计算。
int MaxSubseqSum4( int A[], int N ) {
int ThisSum = 0, MaxSum = 0;
for (int i = 0; i < N; i++) {
ThisSum += A[i]; // 向右累加
if (ThisSum > MaxSum)
MaxSum = ThisSum; // 更新当前最大和
else if (ThisSum < 0)
ThisSum = 0; // 如果当前子列和为负,抛弃这段子列
}
return MaxSum;
}
- 时间复杂度:T(N) = O(N),是线性的。
- 特点:该算法在任何时刻中止时,都能给出当前数据的最优解。它的运行效率很高,但某些情况下正确性可能不明显。















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









