









深入解读字符集:从 ASCII 到 Unicode
在现代计算机系统中,字符的表示方式对于程序的正确运行至关重要。字符集的概念为不同的语言、符号、数字等提供了一个统一的编码标准,确保在不同平台、设备之间能够正确传输和处理文本数据。本文将全面讲解字符集的基本概念,逐步介绍从 ASCII 到 Unicode 的发展历程,以及在实际开发中的应用。
1. 字符集的概念
字符集(Character Set),也称为编码表,是一种用于将字符映射到数字的标准。计算机只能处理二进制数据,因此字符必须转换为数字来进行存储和处理。字符集为此提供了具体的映射规则,使得计算机能够识别和处理不同的字符。
字符集中的每个字符都与一个唯一的数值(称为码点,Code Point)对应,计算机使用这些码点来表示和操作字符。
常见字符集包括:
- ASCII(American Standard Code for Information Interchange)
- ISO-8859 系列(如 ISO-8859-1,ISO-8859-5)
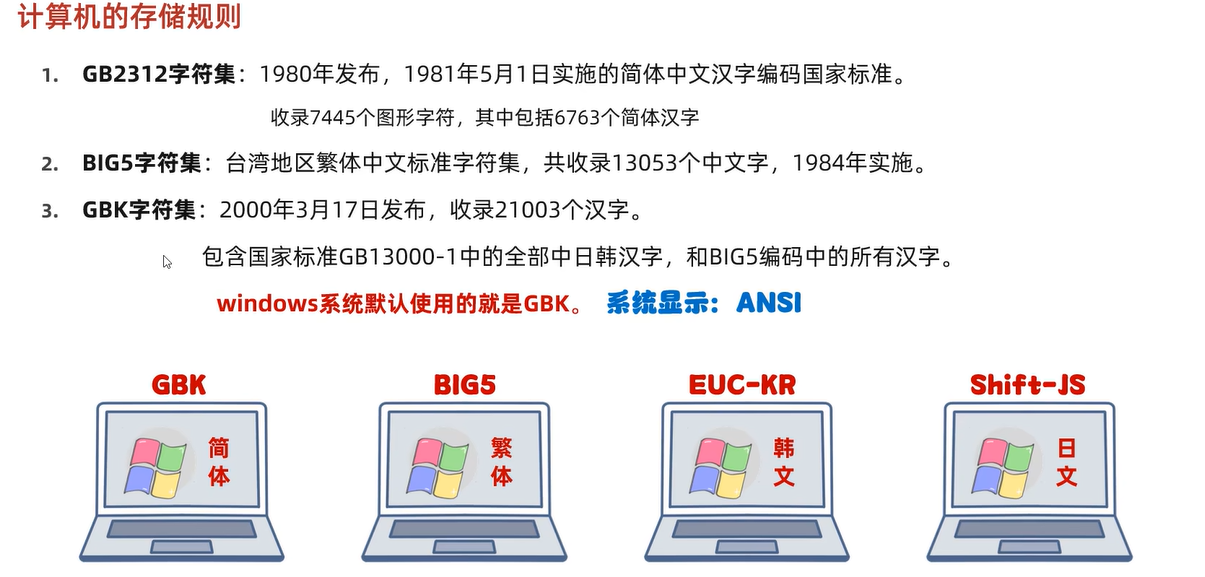
- GB2312/GBK(中国国家标准字符集)
- Unicode
2. ASCII 编码
2.1 ASCII 的背景
ASCII 是最早的字符集之一,它是美国信息交换标准代码(American Standard Code for Information Interchange)的缩写。该字符集诞生于 1960 年代,主要用于表示英文字符以及一些控制符号。

2.2 特点
- ASCII 使用 7 位(128 个字符)来表示基本的英文字母、数字、标点符号和控制字符。
- 每个字符对应一个 0 到 127 之间的数字,例如:
- 大写字母
A的 ASCII 码是 65。 - 小写字母
a的 ASCII 码是 97。
- 大写字母
ASCII 示例:
'A' -> 65
'a' -> 97
'0' -> 48
2.3 限制
- 局限性:由于仅有 128 个字符,ASCII 无法表示除英语以外的其他语言字符。对于多语言支持和扩展字符集(如中文、阿拉伯文等)显得力不从心。
3. 扩展字符集:ISO-8859 和 GB2312
为了满足其他语言的需求,在 ASCII 基础上出现了许多扩展字符集。
3.1 ISO-8859 系列
ISO-8859 是一系列字符集标准,其中每个标准用于不同的语言或字符集。最常用的是 ISO-8859-1,也叫做 Latin-1,主要用于西欧语言。
- ISO-8859-1 扩展了 ASCII,使用 8 位(256 个字符),增加了重音符、法语、德语等语言的特殊字符。
- 但它依旧无法满足更复杂语言(如中文、日文等)的需求。
3.2 GB2312 和 GBK(中文字符集)
为了支持中文字符,中国引入了 GB2312 编码,它使用两个字节(16 位)表示中文字符。后续 GBK 扩展了 GB2312,支持了更多的汉字和其他符号。
- GB2312:包括 6763 个汉字。
- GBK:基于 GB2312 扩展,支持简体和繁体字,包含约 21000 个汉字。
GB2312 示例:
'中' -> GB2312 编码为 0xD6D0
'国' -> GB2312 编码为 0xB9FA
4. Unicode 编码:全球统一字符集
随着互联网的普及,跨语言、跨国家的数据交换需求越来越强烈,ASCII 和 ISO-8859 等局部字符集无法满足全球字符处理的需求。于是,Unicode 编码应运而生。
4.1 Unicode 的概念
Unicode 是一个字符集标准,旨在为每个字符分配唯一的码点,能够表示全球几乎所有的书写系统,包括拉丁字母、汉字、日文、韩文、阿拉伯文等。
4.2 Unicode 的发展
Unicode 最初只使用 16 位表示字符(最多可表示 65536 个字符),这被称为 UCS-2。随着字符集的进一步扩展,Unicode 现已包含超过 100 万个字符,使用 UCS-4 或 UTF-32 表示完整的字符集。
- UCS-2:固定 16 位,无法表示超出基本多文种平面的字符。
- UTF-16:可变长度编码,使用 16 位或更多位表示字符,能够覆盖更多字符集。
- UTF-8:一种可变长度的编码方式,使用 1 到 4 个字节表示字符,是目前最广泛使用的编码方式。
4.3 UTF-8 编码

UTF-8 是 Unicode 的一种实现方式,它使用 1 到 4 个字节表示一个字符,具有良好的兼容性和空间效率。在英文字符上,UTF-8 保持与 ASCII 兼容,仅使用一个字节,而对于中文、阿拉伯文等复杂字符,则使用 3 到 4 个字节。
UTF-8 示例:
'A' -> 0x41 (与 ASCII 相同)
'中' -> 0xE4B8AD (占用 3 个字节)
'𝄞' -> 0xF09D849E (占用 4 个字节)

4.4 优点
- 全球支持:可以表示几乎所有已知语言的字符。
- 兼容性:UTF-8 与 ASCII 向下兼容,在处理英文字符时不浪费额外空间。
- 灵活性:UTF-8 具有可变长度,适合各种文本传输和存储场景。
5. 编码的选择与实践
在实际开发中,选择合适的字符集编码尤为重要。随着 Unicode 和 UTF-8 的广泛支持,开发者通常会选择它们来实现全球化的字符处理能力。
5.1 什么时候使用 UTF-8?
- 如果需要处理多语言文本,UTF-8 是最好的选择。
- 对于 Web 开发,UTF-8 是主流编码格式,几乎所有现代浏览器、操作系统和编程语言都默认支持 UTF-8。
- 文件传输和网络协议(如 HTTP、SMTP)中也普遍使用 UTF-8。
5.2 避免常见编码错误
- 字符编码不一致:确保文件的编码格式与程序中读取文件的编码格式一致,否则会导致乱码。
- 编码转换问题:在多语言环境中,特别是数据传输和数据库存储时,注意字符编码的转换,避免信息丢失或乱码。
5.3 在 Java 中处理字符集
在 Java 中,处理字符集时,可以使用 java.nio.charset.Charset 类或 String 的编码方法进行转换:
String str = "你好";
byte[] bytes = str.getBytes("UTF-8"); // 将字符串转为 UTF-8 字节数组
String decoded = new String(bytes, "UTF-8"); // 将字节数组转回字符串
6. 总结
字符集的演变是计算机历史中至关重要的一部分,从最早的 ASCII 到如今的 Unicode 和 UTF-8,字符编码标准为全球不同语言的交流提供了强大的支持。理解字符集的概念及其不同版本的应用,能够帮助开发者避免编码问题,提高程序的国际化能力。
符集的演变是计算机历史中至关重要的一部分,从最早的 ASCII 到如今的 Unicode 和 UTF-8,字符编码标准为全球不同语言的交流提供了强大的支持。理解字符集的概念及其不同版本的应用,能够帮助开发者避免编码问题,提高程序的国际化能力。
对于现代开发,UTF-8 几乎是默认的选择,其灵活性、兼容性和全球化支持使其成为处理文本数据的最佳实践。无论是开发 Web 应用、处理文件还是进行网络通信,UTF-8 和 Unicode 为我们的编码世界提供了广泛的解决方案。

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









