









在自己的windows环境下配置好了深度学习的环境,本文主要记录一下用深度学习的环境下实现一个简单的手写数字识别的模型训练和使用。
1、在pycharm中配置conda环境:
环境配置好以后,可以开始手写数字识别的代码了
2、加载tensorflow和 keras的库
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
3、如果本地环境是GPU的环境,需要配置GPU。
如果你不知道是否本地支不支持GPU,可以通过下面的代码打印出当前的GPU列表
gpuList = tf.config.list_physical_devices("GPU")
print(gpuList)
打印信息如下:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
配置GPU用于模型的训练
if gpuList:
usedGPU = gpuList[0]
tf.config.experimental.set_memory_growth(usedGPU, True)
tf.config.set_visible_devices([usedGPU], "GPU")
4、从网络导入MNIST 手写数字识别数据集
该数据集中包含了70000张手写数字的图片,其中每张图片的大小为 28281(灰度图片),MNIST数据集链接,本地选择了60000张作为训练集,10000作为验证集,该数据集已经被Keras集成,因此,可以直接通过Keras的datasets.mnist.load_data()函数导入数据,代码如下:
# trainImageSet 训练图片集合
# trainLabelSet 训练数据标签集合
# testImageSet 测试图片集合
# testLabelSet 测试数据标签集合
(trainImageSet, trainLabelSet), (testImageSet, testLabelSet) = datasets.mnist.load_data()
5、对图片进行预处理
trainImageSet = trainImageSet.reshape((60000, 28, 28, 1)) # 将数据变形成张量
testImageSet = testImageSet.reshape( (10000, 28, 28, 1)) # 将数据变形成张量
trainImageSet = trainImageSet / 255.0 # 将图片的像素值从[0,255]映射到 [0,1]之内
testImageSet = testImageSet / 255.0 # 将图片的像素值从[0,255]映射到 [0,1]之内
6、构建Keras模型
接下来构建一个下面的深度模型:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 64) 102464
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 121,930
Trainable params: 121,930
Non-trainable params: 0
_________________________________________________________________
实现代码如下:
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), # 卷积层1,卷积核3*3, 共32个卷积核
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样,最大池化
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层2,卷积核3*3,共64个卷积核
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样,最大池化
layers.Flatten(), # Flatten层,连接卷积层与全连接层,查资料发现是将所有数据转换成一维向量数据,为后面的全连接做准备。
layers.Dense(64, activation='relu'), # 全连接层,输出维度是64
layers.Dense(10) # 输出层,输出维度是10,代表0-9对应的标签的值
])
可以通过下面的代码来打印整个网络:
model.summary()
7、开始训练模型
设置优化器、损失函数、评价函数
model.compile(optimizer='adam', # 优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数
metrics=['accuracy']) # 评价函数
进行模型训练,将训练完的模型保存
history = model.fit(trainImageSet, trainLabelSet, epochs=10, # 迭代10次
validation_data=(testImageSet, testLabelSet))
model.save('recogNumber.h5') # 模型保存到 recogNumber.h5文件中
到此为止,已经完成了对模型训练的整个流程了
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 训练/识别分割线 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
接下来用训练好的模型进行使用
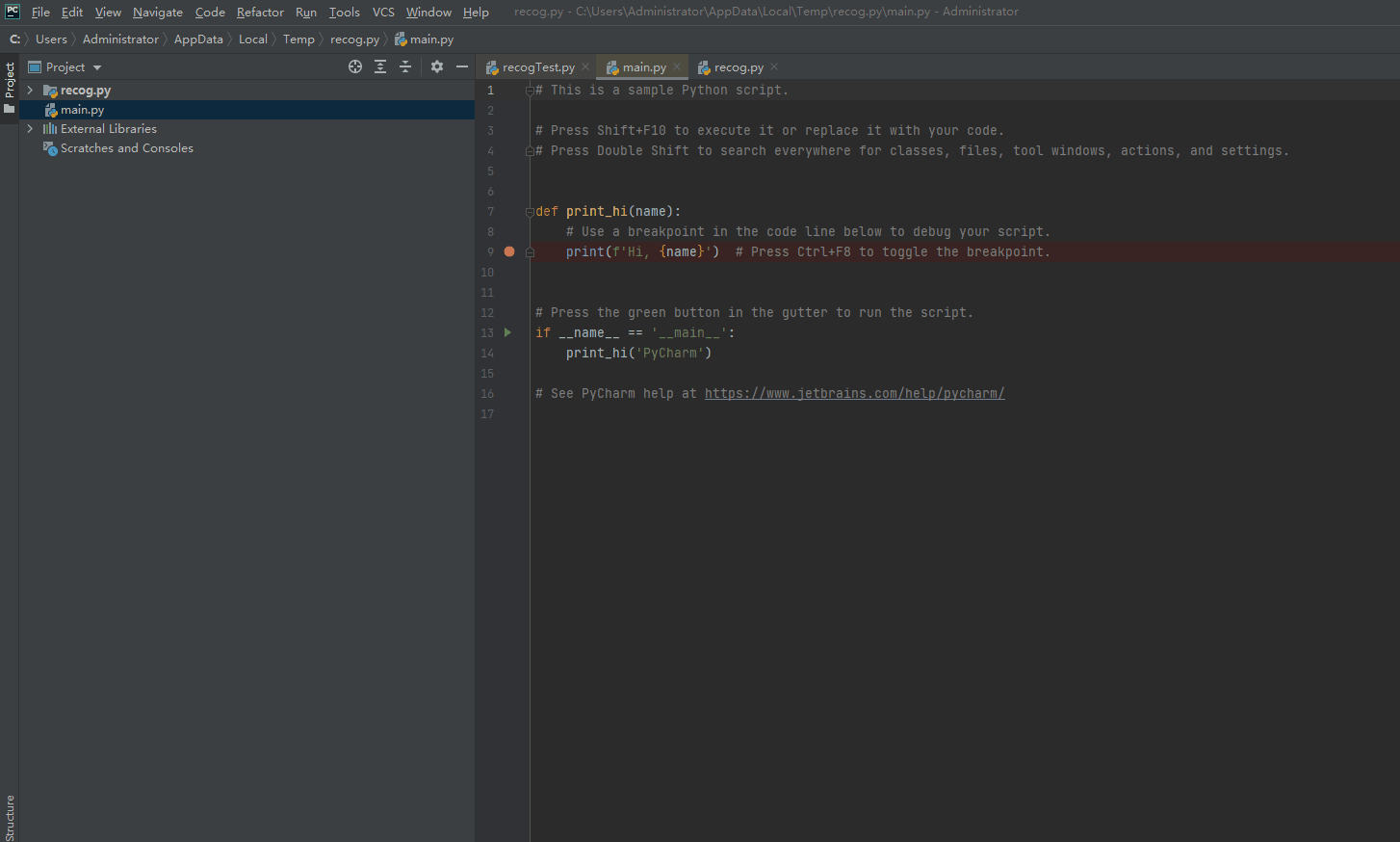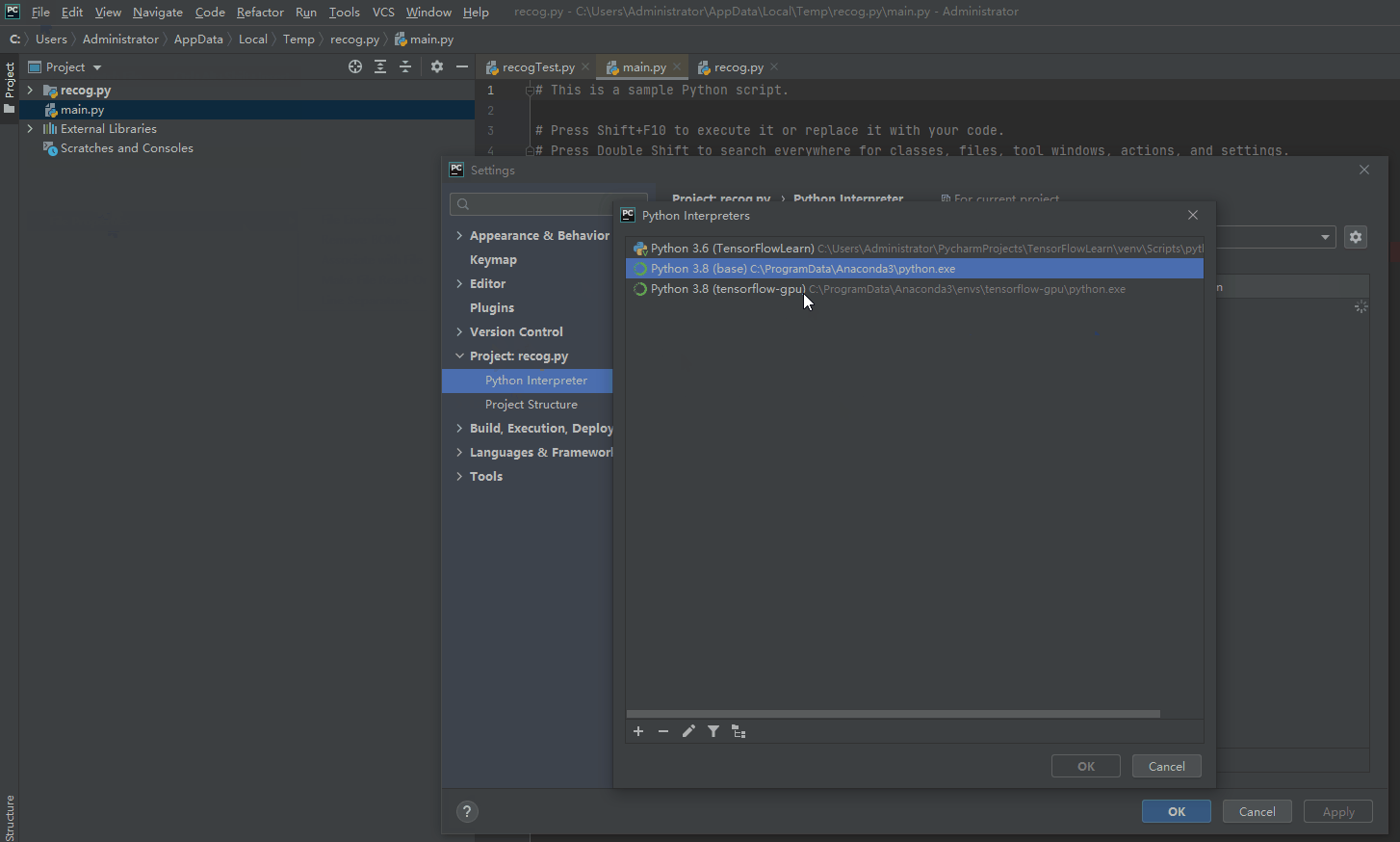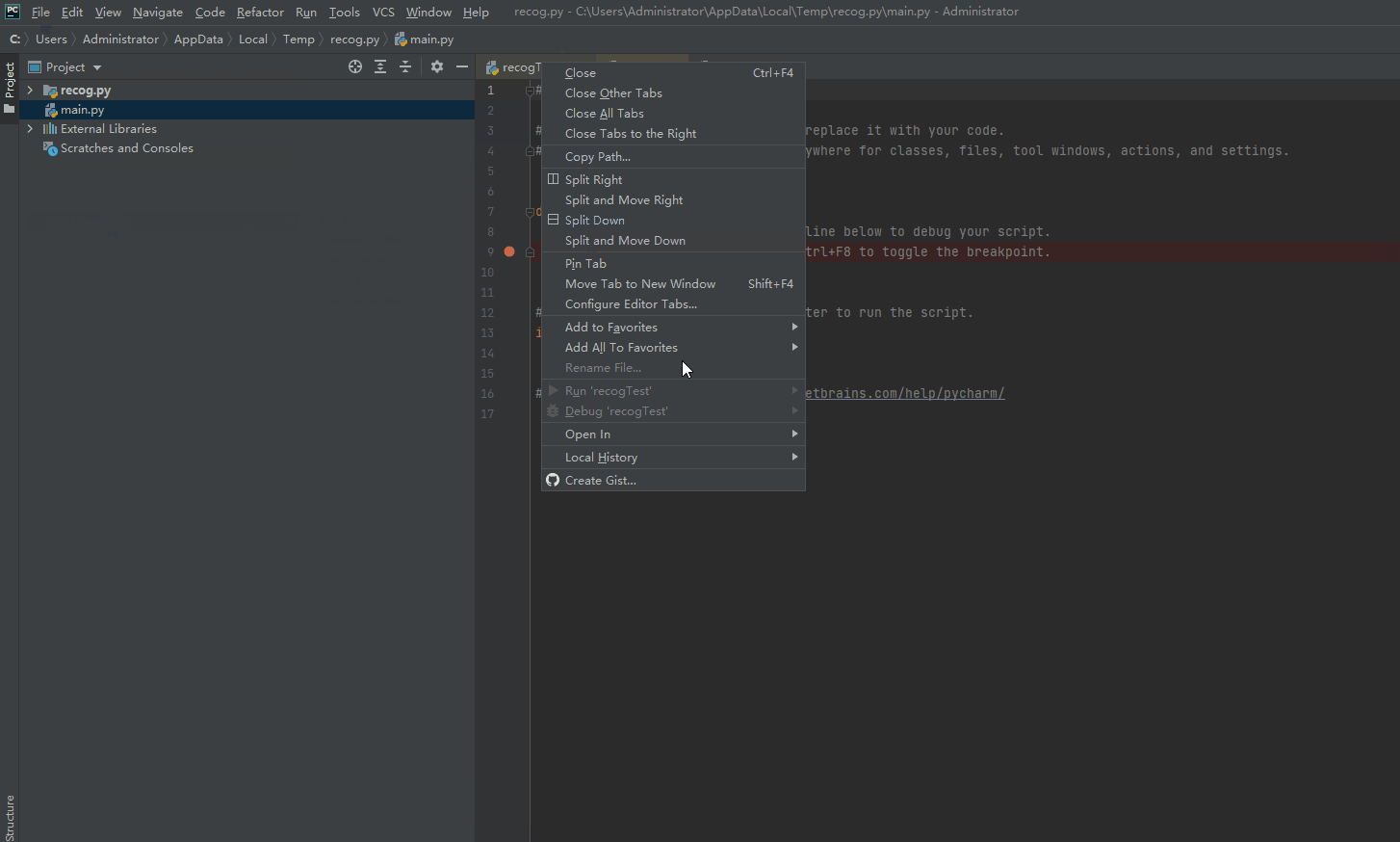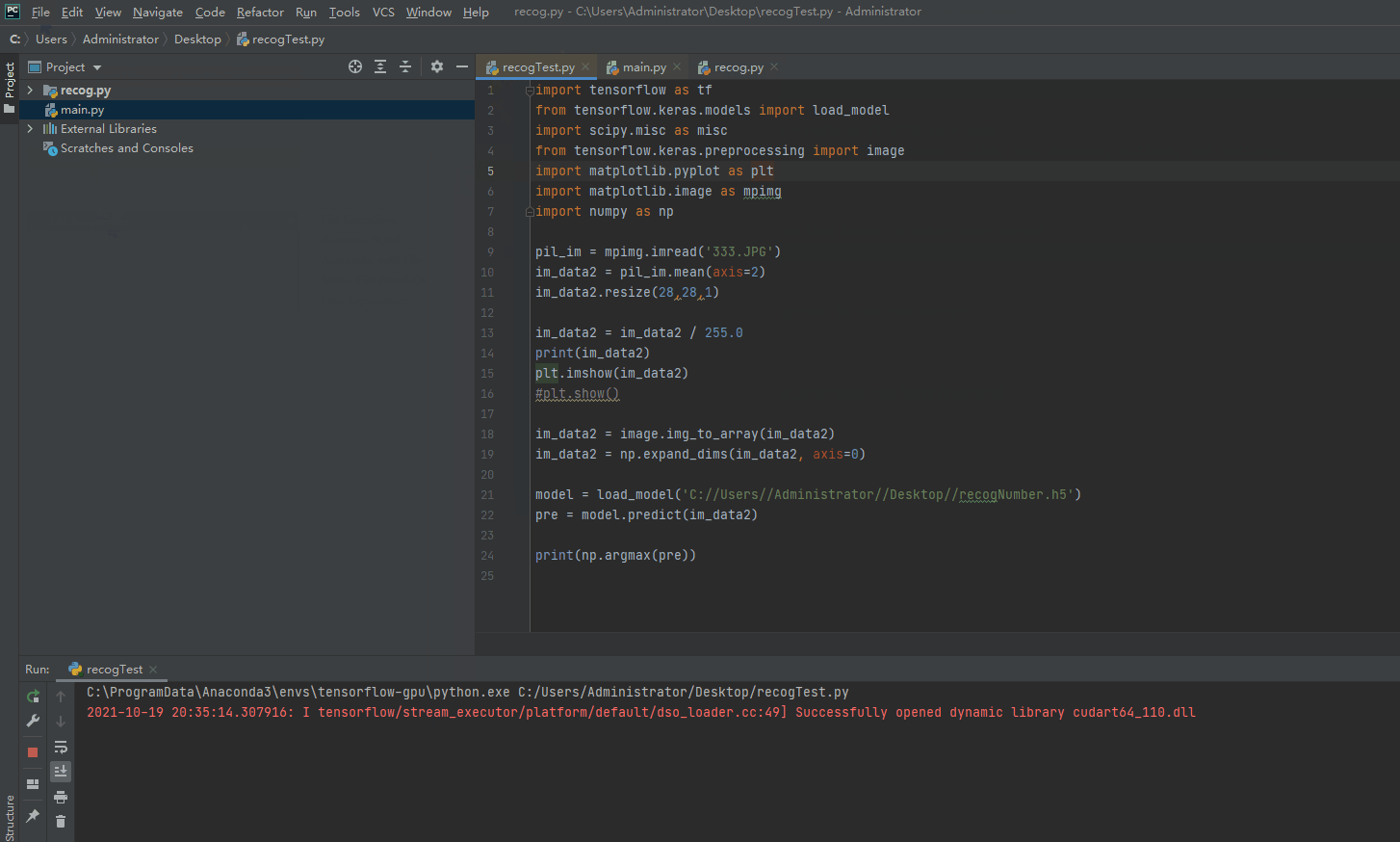
8、读取本地图片
通过matplotlib.image 读取本地图片,本地选择了一个数值是3的图片进行测试。
import tensorflow as tf
from tensorflow.keras.models import load_model
import scipy.misc as misc
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
pil_im = mpimg.imread('333.JPG')
9、图片预处理
对图片进行预处理,注意:本地的图片自己修改成28 * 28 * 1维的图片
im_data2 = pil_im / 255.0 # 数据归一化
print(im_data2)
plt.imshow(im_data2)
plt.show() # 显示图片,关闭图片后,程序才会继续往下走
im_data2 = image.img_to_array(im_data2)
im_data2 = np.expand_dims(im_data2, axis=0) # 将数据转换成np数组

10、加载模型并进行预测
model = load_model('C://Users//Administrator//Desktop//recogNumber.h5') # 加载模型
pre = model.predict(im_data2) # 模型进行预测
print(pre) # 打印当前所有标签的置信度
print(np.argmax(pre)) # 选出最大值置信度对应的下标,即标签
关闭图片后,输出结果向量和预测结果如下:
# 输出不同标签的可信度向量,下标对应标签 0-9
[[-11.468813 -1.7106687 -6.7820425 15.381593 -2.7402487 0.973804 -8.244136 -2.8609006 -1.9001967 -0.34003535]]
# 预测结果:
3
通过输出的结果来看,模型分类器的识别率还是很好的,除了3这个类别外,其他类别的值都基本都是小于0。
11、总结
深度学习的实例流程总结如下:
1、获取并加载数据集(训练数据集和测试数据集)
2、手动设置模型
3、进行模型的训练和模型的保存
4、用训练好的模型去使用
本以为很难,成功迈出第一步就容易很多,如果你看到这里,说明你的环境已经搭建好了,在你开心的情况下点个赞可好 ^ _ ^, 有问题欢迎留言。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









