







GAN面临的问题
生成式对抗网络(GAN, Generative Adversarial Networks),使用判别器(Discriminator)对生成器(Generator)进行不断优化,并需要Discriminator和Generator共同进步才行,但Discriminator往往不稳定,很容易出现梯度消失的情况。
Discriminator一般使用JS散度(Jensen-Shannon Divergence, JSD)来计算两个分布之间的差异,如果真实数据和生成数据没有重合,那么JSD的结果都是 l o g 2 log2 log2梯度就会消失(数学推导见后文)就没有办法往更好的方向进行训练,有可能就突然坏掉了
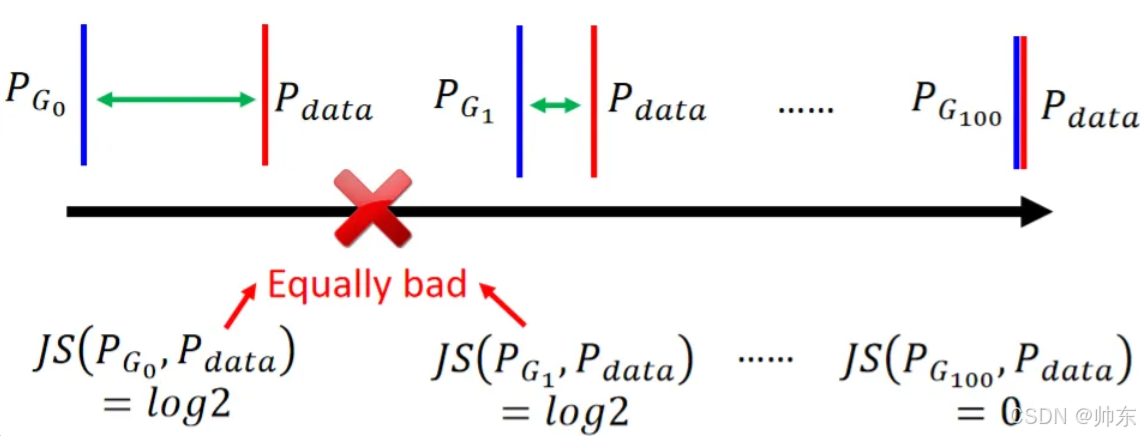
为什么真实数据和生成的数据会没有重合?
- sample的点不够多
- 在高维度上来看想要每次都重合概率很低。就像在1维上选取2个范围,它们还挺容易重叠,但如果在二维上选取2个范围,它们重合的概率就大大降低了。
实验效果
实验训练的是一个随机生成动漫头像的模型,1W张动漫一个Epoch,一个Epoch输出100张中间图片,接下来看看实际效果。

前面都还好好的,第18次的时候就完全崩掉了,而且后面怎么也训练不起来了。
WGAN介绍
Wasserstein GAN简称WGAN,17年1月份提出,目的是为了解决GAN训练不稳定的问题。训练 WGAN 不需要在判别器和生成器的训练中保持仔细的平衡,也不需要仔细设计网络架构。
核心思想
用 Wasserstein-1距离(Earth-Mover距离) 替代JS散度,衡量两个分布(真实分布、生成分布)之间的差异,解决GAN的训练不稳定、梯度消失问题。
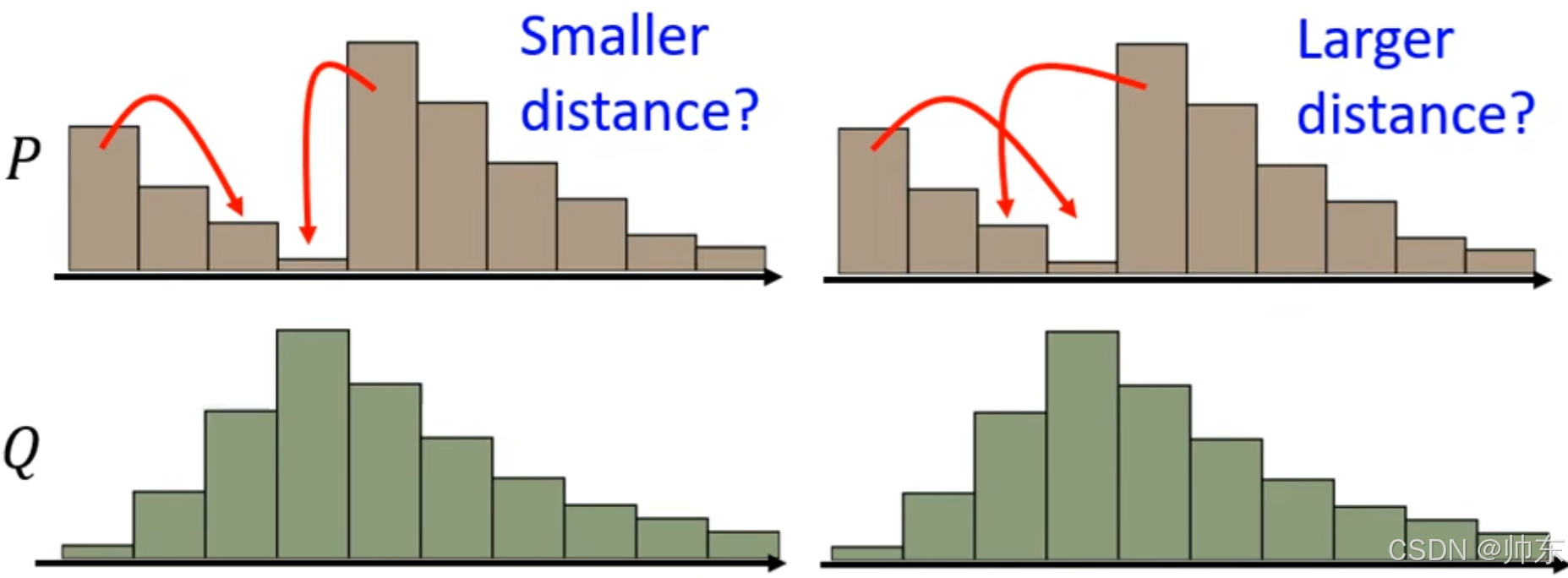
我们要找到所有把P分布,移动到Q分布的方法,在这些方法里面找到最小的移动距离,这个距离就是P、Q分布的距离,两个分布总是有距离的,Simple出来的分布不同,距离往往不同,所以WGAN就会很稳,梯度消失的概率就很低。
先不管作者是怎么推导出来的(数学推导见后文),但是这个思路是OK的,接下来就是看具体怎么训练,代码怎么写了。

- 设置默认值 α = 0.00005 \alpha = 0.00005 α=0.00005, c = 0.01 c = 0.01 c=0.01, m = 64 m=64 m=64, n critic = 5 n_{\text{critic}}=5 ncritic=5
- 循环直到 θ \theta θ 收敛
- 循环训练5次critic(批评家)
- 抽取一组真实数据
- 抽取一组之前的样本(随便从正态分布中选)
- 计算gradient
- 使用 RMSProp \text{RMSProp} RMSProp更新参数
- 参数裁剪(限制在[-0.01,0.01])
- 抽取一组之前的样本(随便从正态分布中选)
- 计算Generator的gradient
- 使用 RMSProp \text{RMSProp} RMSProp更新参数
- 循环训练5次critic(批评家)
作者还把Discriminator改了一个名字叫做Critic,毕竟不再使用二元分类的办法区分了,也不用再叫做鉴别者了
乍一看感觉和理论没有任何关系,感觉和之前也没多大差别,对参数就行裁剪就OK?
Weight clipping is a clearly terrible way to enforce a Lipschitz constraint. If the clipping parameter is large, then it can take a long time for any weights to reach their limit, thereby making it harder to train the critic till optimality. If the clipping is small, this can easily lead to vanishing gradients when the number of layers is big, or batch normalization is not used (such as in RNNs). We experimented with simple variants (such as projecting the weights to a sphere) with little difference, and we stuck with weight clipping due to its simplicity and already good performance. However, we do leave the topic of enforcing Lipschitz constraints in a neural network setting for further investigation, and we actively encourage interested researchers to improve on this method.
如果裁剪参数很大,则任何权重都可能需要很长时间才能达到极限,从而使训练批评者达到最优变得更加困难。如果裁剪很小,当层数很大或未使用批量归一化时,这很容易导致梯度消失。我们坚持使用权重裁剪,因为它简单且性能已经很好,我们积极鼓励感兴趣的研究人员改进这种方法。
一句话总结:当时还没有找到更好的办法,参数裁剪的实验效果还可以,就先用它
GAN和WGAN在实际效果上的差异
we show a proof of concept of this, where we train a GAN discriminator and a WGAN critic till optimality. The discriminator learns very quickly to distinguish between fake and real, and as expected provides no reliable gradient information. The critic, however, can’t saturate, and converges to a linear function that gives remarkably clean gradients everywhere. The fact that we constrain the weights limits the possible growth of the function to be at most linear in different parts of the space, forcing the optimal critic to have this behaviour.
我们训练 GAN 鉴别器和 WGAN 批评器,直到达到最优。 鉴别器可以很快学会区分 假的和真的,并且如预期的那样没有提供可靠的梯度 信息。然而,批评家无法饱和,并且会聚 变成一个线性函数,在各处都能给出非常干净的梯度。 事实上,我们限制了权重,从而限制了可能的 函数在不同部分的增长至多为线性 空间,迫使最佳评论家采取这种行为。
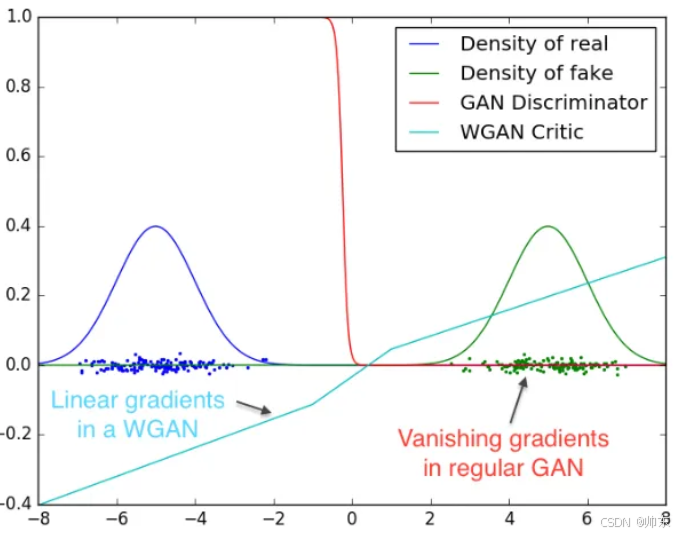
搞笑:老张家的人能力强,梯的猛;还是老C力度把控好,稳定又持久。
实验效果

虽然效果没有特别好,训练也慢,但过程很稳定,不会突然吃个饭回来就垮掉了
简单对比
| 特性 | GAN | WGAN |
|---|---|---|
| 距离度量 | JS散度 | Wasserstein距离 |
| 约束方式 | 无约束 | 权重裁剪(强制Lipschitz) |
| 梯度稳定性 | 差(易梯度消失) | 好 |
| 训练难度 | 不稳定,易崩溃 | 稳定但收敛慢 |
数学推导
1.为什么是log2
KL散度(Kullback-Leibler Divergence,KLD),又称相对熵,是信息论中用于衡量两个概率分布差异的重要工具。它不是一个真正的“距离”(因为不对称),但可以量化一个分布 P 相对于另一个分布 Q 的不相似性。
D K L ( P ∥ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) D_{KL}(P \| Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)logQ(x)P(x)
JS散度是基于KL散度,取了一个平均值来定义:
J S ( P ∥ Q ) = 1 2 D K L ( P ∥ M ) + 1 2 D K L ( Q ∥ M ) JS(P \| Q) = \frac{1}{2} D_{KL}(P \| M) + \frac{1}{2} D_{KL}(Q \| M) JS(P∥Q)=21DKL(P∥M)+21DKL(Q∥M)
M = 1 2 ( P + Q ) M = \frac{1}{2}(P + Q) M=21(P+Q),最终公式:
J S ( P ∥ Q ) = 1 2 ∑ x P ( x ) log P ( x ) M ( x ) + 1 2 ∑ x Q ( x ) log Q ( x ) M ( x ) JS(P \| Q) = \frac{1}{2} \sum_{x} P(x) \log \frac{P(x)}{M(x)} + \frac{1}{2} \sum_{x} Q(x) \log \frac{Q(x)}{M(x)} JS(P∥Q)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









