









Shifting More Attention to Video Salient Object Detection
原始文章:https://www.yuque.com/lart/papers/vrkwzi
好久没有更新了,今天看了下这篇文章。这篇文章主要提出了一个大规模的视频显著性目标检测数据集Densely Annotated VSOD (DAVSOD)。另外也针对视频显著性目标检测的现有研究中的几个关键问题进行了分析。
主要改进
数据集层面

- 现有的视频显著性目标检测数据集没有考虑选择性注意和注意力转移这两个重要的动态注意特性,它们的标注过程大多没有考虑动态的人眼注视点数据,而是将视频拆成单独的静态帧来分别标注,并不能揭露人在观察期间真实的注意行为。
- 现有数据集数据量太少,且没有充足且精细的逐帧标记,这对于对数据严重依赖的深度学习模型而言,还是不够的。
- 另外现有数据集提供的标注类型单一,而新提出的数据集包含丰富的注释,包括显著性偏移、目标/实例级别的mask标注、显著性目标数量、场景/目标类别和相机/目标移动状态,对于后续的更加贴近于真实动态场景的研究提供了巨大的帮助。
模型层面

完整模型架构
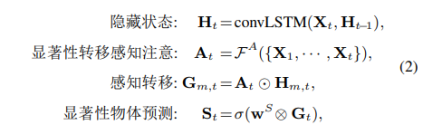
显著性转移感知模块流程
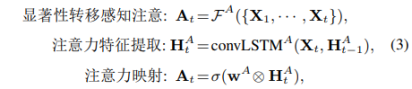
显著性转移感知注意网络F__A
总体损失函数
显式训练与隐式训练对比
- 针对注意力转移这一重要特定使用显著性转移感知模块来进行充分的学习。通过对附加ASPP的ResNet50提取得到的静态显著性特征,使用显著性转移感知模块(卷积LSTM+显著性转移感知注意机制)来进行结合,从而考虑时序变化和显著性转移来得到相应的结果。
- 显著性转移感知注意机制主要过程如前式(2)所示,这里的Xt表示t时刻的静态特征(来自ASPP),可以看到,这里的“显著性转移感知注意”考虑了t时刻和之前的所有时刻的特征,这里的关键组件是其中的显著性转移感知注意网络F,这里再F之后又引入了一个小的卷积LSTM来进一步模拟注意力转移,这里如式(3)所示。
- 针对是否有人眼注释标注数据将训练模式分为显示和隐式训练模式。通过使用一个指示函数 l ( ⋅ ) l(\cdot) l(⋅)(存在人眼注释数据,值为1,反之为0)来构建损失。损失函数如式(4)所示。所以,如果不存在人眼注释数据,则这里的F以隐式模式训练,存在的时候,则为显式训练(显式训练与隐式训练对比可见表(5)),借助于LSTM结构,F可以将VSOD模型的注意力转移到重要的对象上。另外,这里的Latt和Lvsod都是交叉熵损失函数。
实验设置
- ResNet-50,最后两个阶段的不进行下采样,所以总体下采样8倍。
- 输入473473,下采样最后输出为6060*2048。
- ASPP结构:一个残差连接+四个扩张卷积分支(d=2,4,8,16)。
- 训练数据:和[Pyramid dilated deeper convLSTM for video salient object detection]保持一致,但没有使用MSRA-10k,另外,进一步利用DAVSOD的验证集来显式训练显著性转移感知注意模块。
实验比较















 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









