







Rethinking Scanning Strategies with Vision Mamba in Semantic Segmentation of Remote Sensing Imagery - An Experimental Study

深度学习方法,尤其是卷积神经网络 (CNN) 和视觉变换器 (ViT),经常用于执行高分辨率遥感图像的语义分割。然而,cnn 受到其有限的接受领域的限制,而 vit 由于其二次复杂性而面临挑战。最近,具有线性复杂性和全局感受野的 mamba 模型在视觉任务中获得了广泛的关注。在此类任务中,需要对图像进行序列化以形成与 mamba 模型兼容的序列。许多研究工作已经探索了扫描策略来序列化图像,旨在增强 Mamba 模型对图像的理解。然而,这些扫描策略的有效性仍然不确定。
这项研究对主流扫描方向及其组合对遥感图像语义分割的影响进行了全面的实验研究。通过在 LoveDA,ISPRS Potsdam 和 ISPRS Vaihingen 数据集上进行的广泛实验,我们证明,无论其复杂性或所涉及的扫描方向数量如何,都没有单一的扫描策略能胜过其他扫描策略。简单的单个扫描方向被认为足以对高分辨率遥感图像进行语义分割。 还建议了未来研究的相关方向。

这份工作主要做了两点内容:
- 总结了现有视觉 mamba 中常用的 12 种独立的序列化扫描方向,并实验了 22 中不同策略(12 个独立的和 10 个组合变体)。
- 第一次基于特定设计的实验架构,在三个数据集上定量对比探究了视觉 mamba 不同扫描策略对遥感图像的语义分割准确性的影响。
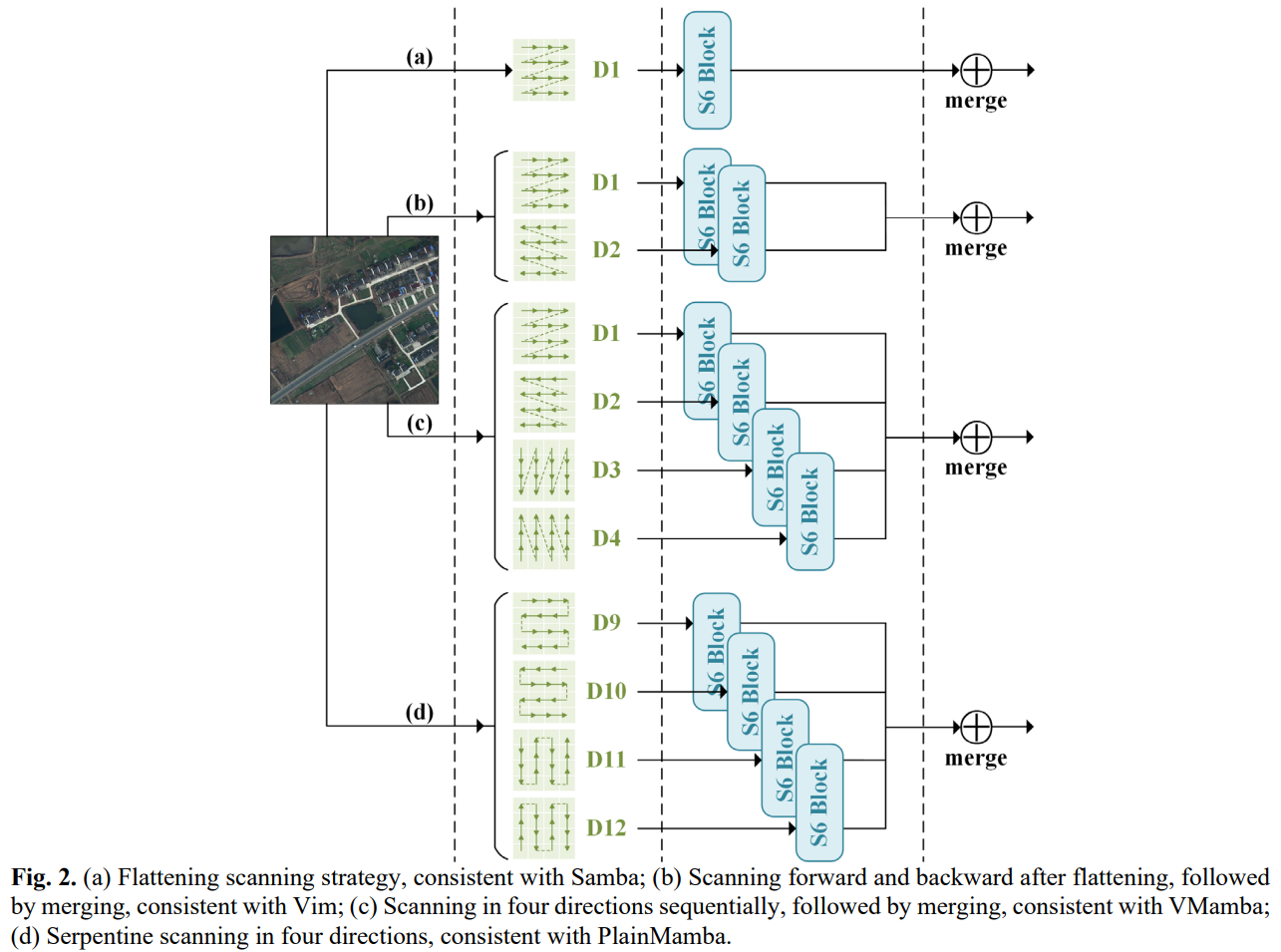
展示了现有方法的几种不同策略
**这些努力都是基于这样的假设,即图像补丁的不同扫描方向可以潜在地增强 Mamba 对图像的理解。**但是,在他们的工作中,缺乏对不同扫描方向下的模型性能进行全面和定量的比较。
- Vim 和 PlainMamba 缺乏必要的消融研究来验证其扫描方法。
- 在 VMamba 中,水平扫描组合的结果 (即,D1 和 D2) 没有报告,而四方向扫描 (即,与单向扫描 D1 相比,D1、D2、D3 和 D4) 在 ImageNet 上仅实现了 0.3% 高的精度。考虑到训练过程中模型性能的可能波动,这种边际改进不足以证实多向扫描的有效性。
而在分割任务的研究中,一些工作考虑了不同的扫描策略来测试它们对 mamba 图像理解能力的影响。
- U-Mamba 代表了将 Mamba 与 UNet 架构合并以进行医学图像语义分割的首次尝试。但是,由于其简单的建筑设计,其性能不及当时最先进的分割方法。
- 随后,出现了几种增强的方法使用 Vim 的双向扫描和/或使用 VMamba 的四向扫描。
- 在遥感领域,Samba 是第一个将 Mamba 引入遥感图像语义分割的研究,其中图像补丁以与 ViT 相同的方式进行展平,如图 2(a)。
- 后来,RS3Mamba 使用 VMamba 的四向扫描方法,构造了一个用于语义分割的辅助编码器。
- 同样,RSMamba 在的编码器 - 解码器体系结构中添加四个额外的对角线方向 (即,D5,D6,D7 和 D8) 。
实验设置
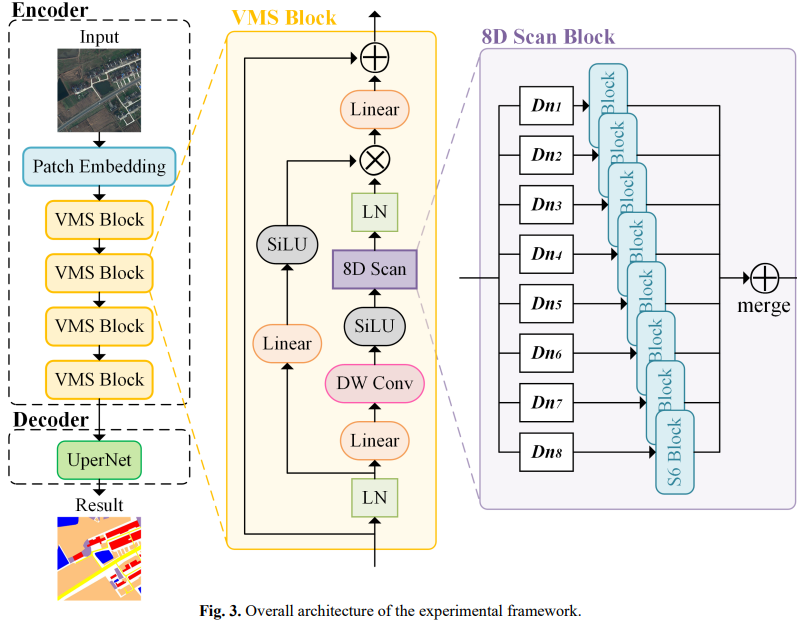
实验所使用的架构形式
图像划分为 patch,序列送入四个 VMS(Vision Mamba Scan)模块顺次下采样。并使用 UperNet 作为解码器预测分割结果。这里为了使用单个模型兼容所有的扫描组合形式,当所考虑的扫描方向的数目为 1、2 或 4 时,扫描方向分别重复 8、4 和 2 次,以填充八个潜在的扫描方向。(这个重复是否会对最终的性能有影响尚未可知)
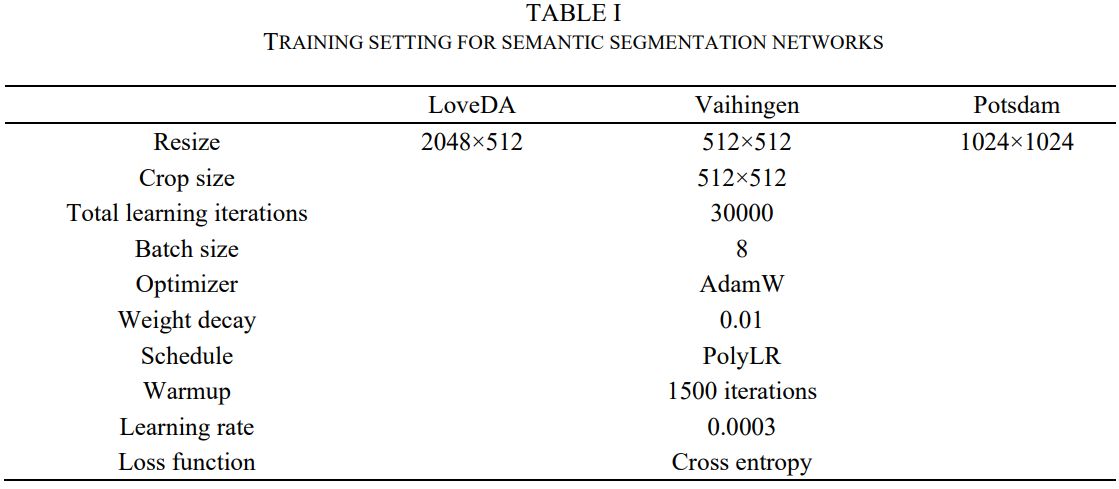
三个数据集的训练设置
- Random resize, random crop, random flip, and photometric distortion are consistently applied for data augmentation in our experiments.
- Experiments are performed using two RTX 4090D GPUs.
对 patch 和 stride 的实验
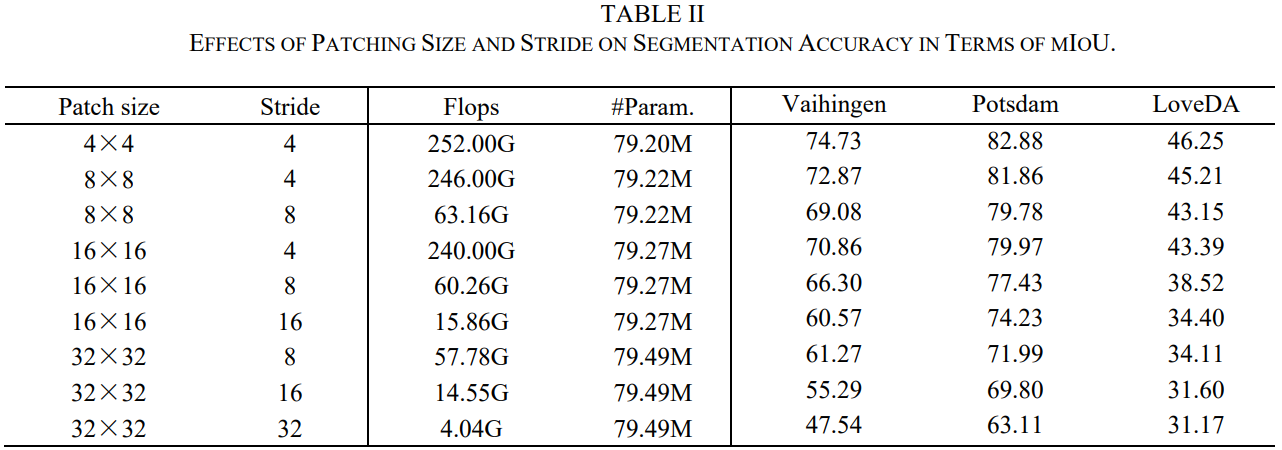
**用于图像裁剪的补丁大小和扫描过程中使用的步幅也会影响实验结果。**目前,大多数基于 mamba 的视觉任务都采用 4×4 大小的 patch 和 4 的步幅。为了探索最适合后续实验的补丁大小和步幅,本研究在三个数据集上进行了各种变体的消融实验。为了进行一致的比较,在消融实验中使用了 D1 扫描方向。
**步幅也起着至关重要的作用,因为它会影响序列的长度和计算负荷。**这里使用 FLOPs 量化计算负载,这是使用一个随机生成的 512×512 图像作为输入来计算的。加倍步幅将需要计算的像素数减少了四倍,从而使计算减少了大约四倍。
考虑到实用性,实验中最小步幅设为 4,较小步幅需要过高的计算资源,因此在两个 24G GPU 上进行训练是不切实际的。实验中考虑的 patch 大小包括 4×4、8×8、16×16 和 32×32,每个配对的步幅与相应的 patch 大小相同,用于分割整个图像。此外,还考虑了小于 patch 尺寸的步幅,这可以允许图像的重叠扫描。
表 II 列出了由各种修补尺寸和步幅组合的分割精度。从三个数据集的性能分析中可以看到一致的发现:当处理 512×512 的图像输入尺寸时,步幅为 4 的 4×4 补丁大小可产生所有三个数据集的最高分割精度。当将步幅依次减小到 4 并保持固定的 patch 大小,mamba 在处理这些长序列时没有出现瓶颈,这表明它有潜力有效处理更小的步幅。因此,mamba 在处理较小步幅的长序列方面显示出希望。固定步幅后,减小 patch 大小可改善分割性能,这表明 mamba 架构更擅长处理更精细的图像补丁。基于这些发现,在随后的实验中始终使用 4x4 的 patch 大小和 4 的步幅 (即,实验 1- 实验 22)。
对扫描策略的实验
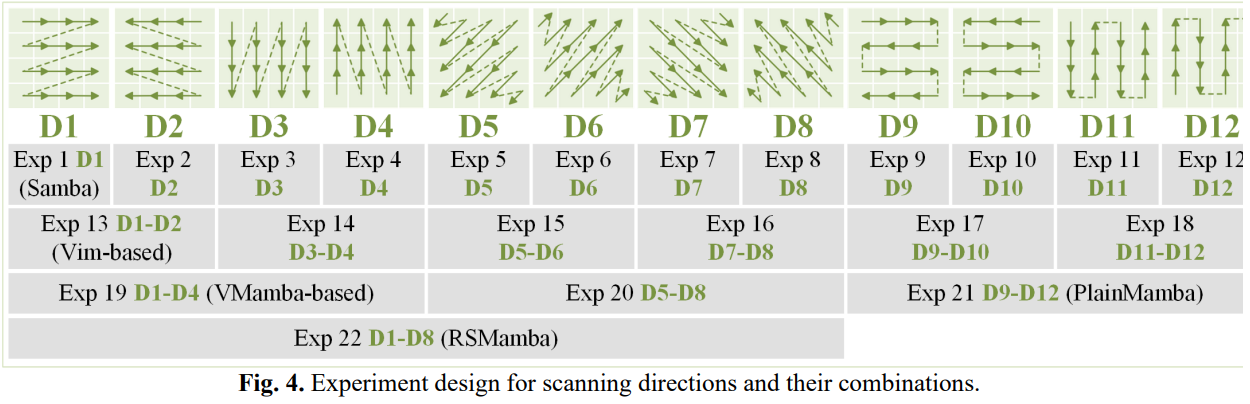
实验中对应的不同扫描组合形式
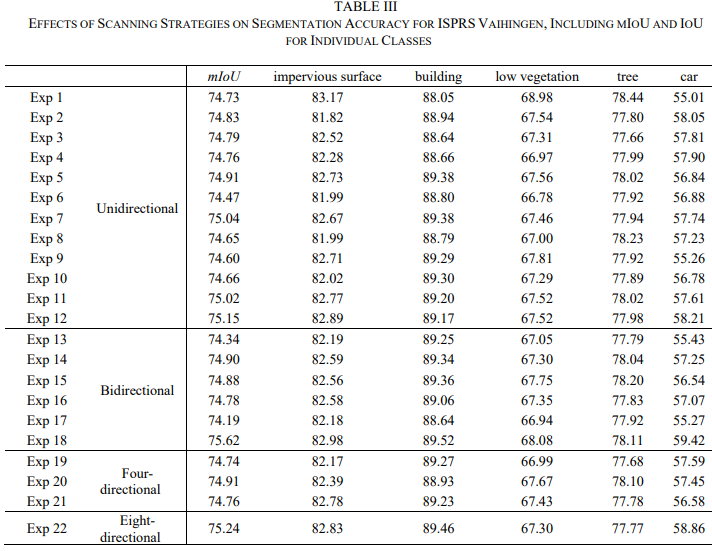
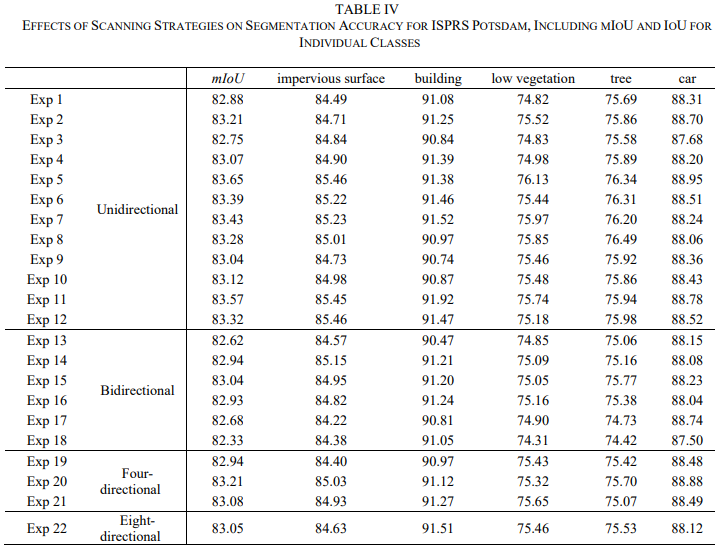
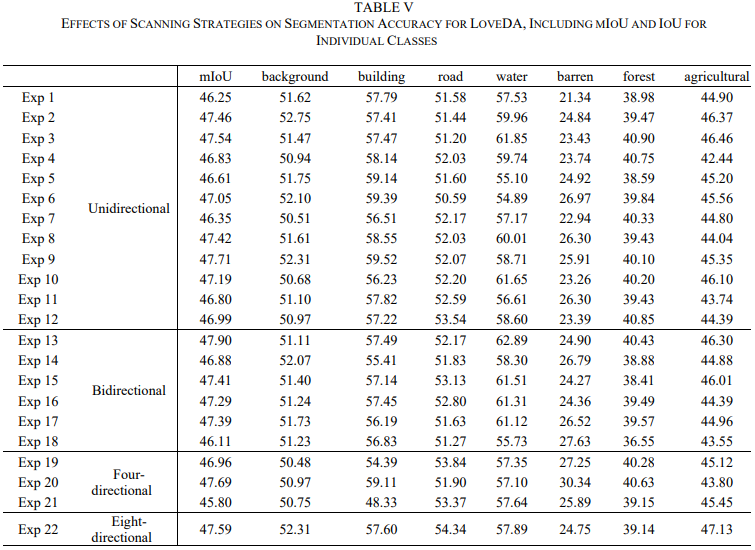
在实验中使用的所有三个数据集上观察到一个有趣的现象。22 种扫描策略产生的分割精度似乎相似。考虑到每个数据集内不同扫描策略之间的小性能差异,以及单个扫描策略在所有三个数据集中的性能差异,没有明显迹象表明任何特定的扫描策略都优于其他方法,无论它们的复杂性或涉及单个或多个扫描方向。观察到的任何轻微的性能波动都可能归因于训练过程的随机性。
总结
对于高分辨率遥感图像的语义分割,利用特定的扫描方向或不同扫描方向的组合,如现有的基于 mamba 的方法所提出的策略,并不能有效提高分割精度。因此,在 vision mamba 框架中,使用类似 ViT 的扁平化方法 (即,D1 扫描) 对于此类图像的语义分割仍然有效。此外,采用单向扫描策略 (例如 D1) 也降低了计算需求,从而允许在有限的计算资源内进行更深的网络堆叠。
探索语言模型在视觉任务上的泛化能力对于深度学习的发展至关重要。基于循环模型的最新进展 [Mamba, RWKV] 中,对将其集成到视觉任务中的有效方法进行着持续探索。当前的工作重点是设计扫描图像 patch 的策略,以增强模型对图像序列的理解。但是本文中对远程感知图像的语义分割的调查表明,基于 mamba 的模型对不同的扫描策略并不敏感。因此,可以说,应该将努力放到探索更有效的方式,而不是探索不同的扫描策略,以增强 mamba 模型对远程感知图像的理解。
我们的工作并不是要否定 Vision Mamba 为改进扫描策略所做的大量努力,而是要证明这些改进对遥感图像的语义分割效果有限。这种现象是可以解释的:遥感图像在特征方面与传统图像不同。
- 一方面,与人物图片等传统图像相比,遥感图像中代表相同语义的斑块在转换成序列时差异很小。
- 另一方面,其序列的因果联系也弱于传统图像。
不过,在其他类型的数据集(如 COCO-Stuff 和 Cityscapes)中,不同的扫描策略在序列中的因果关系更为明显,其有效性还有待验证,这也是未来工作的一个有趣领域。
在对不同 patch 方法的实验中,我们发现了一个有趣的现象:减小步长可以提高分割精度,但代价是增加了计算需求。这表明,在处理 512×512 像素的图像时,Mamba 在使用比实验中使用的最小步长 4 更小的步长时可能会有更好的表现。但是,由于计算资源有限,较小的步长会使序列长度呈指数增长,因此无法使用这些较小的步长进行实验。研究更高效的计算方法以适应更密集的扫描是未来研究的一个有意义的方向。















 4784
4784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









