









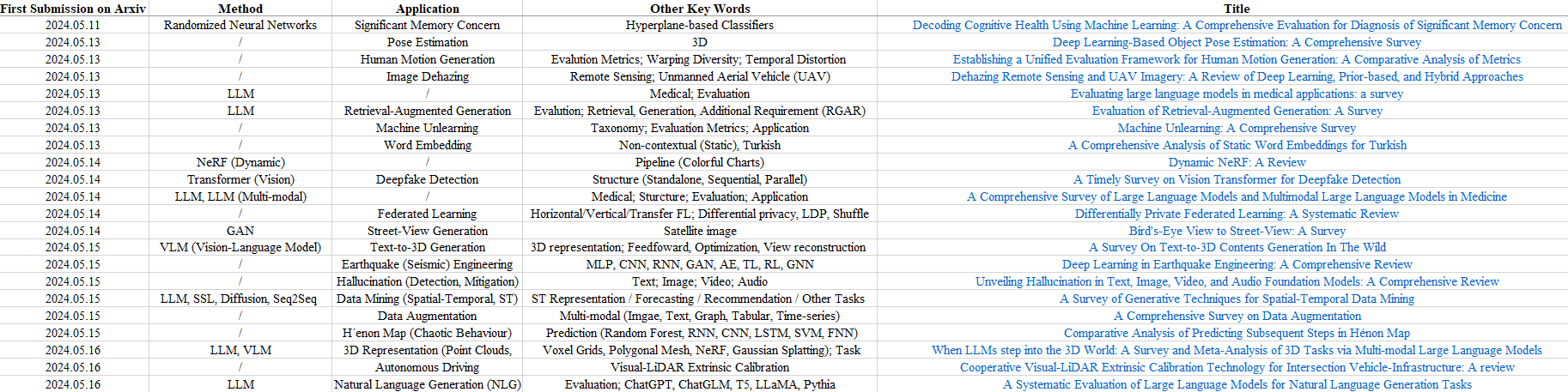
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
每周末更新,完整版进群获取。
Q 群在群文件,VX 群每周末更新。
目录
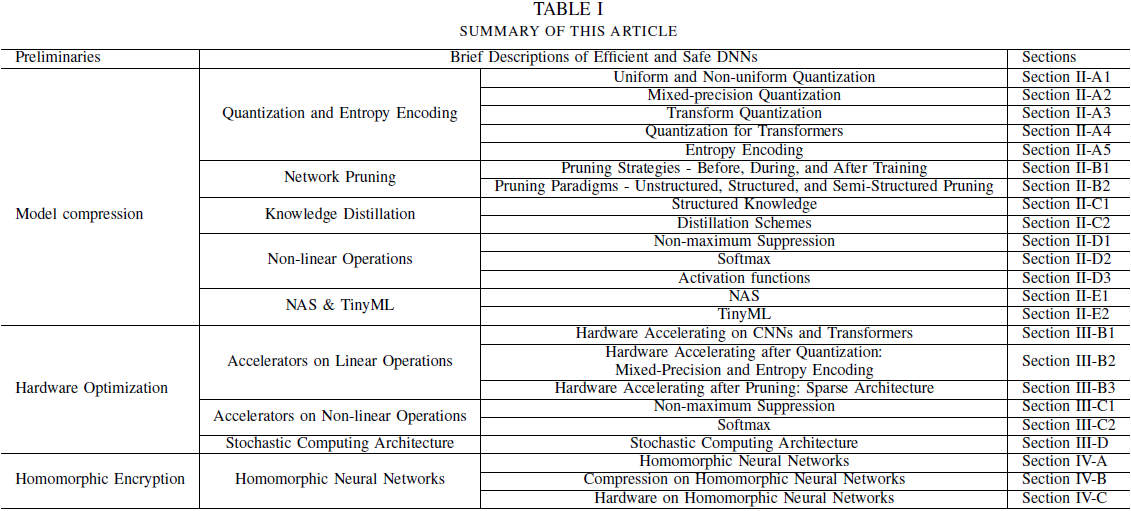
1. From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
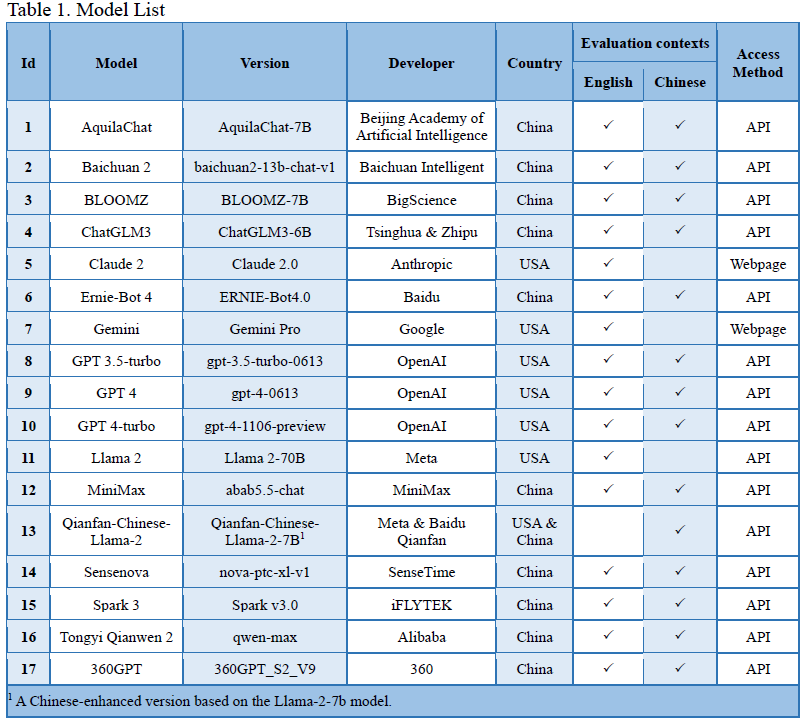
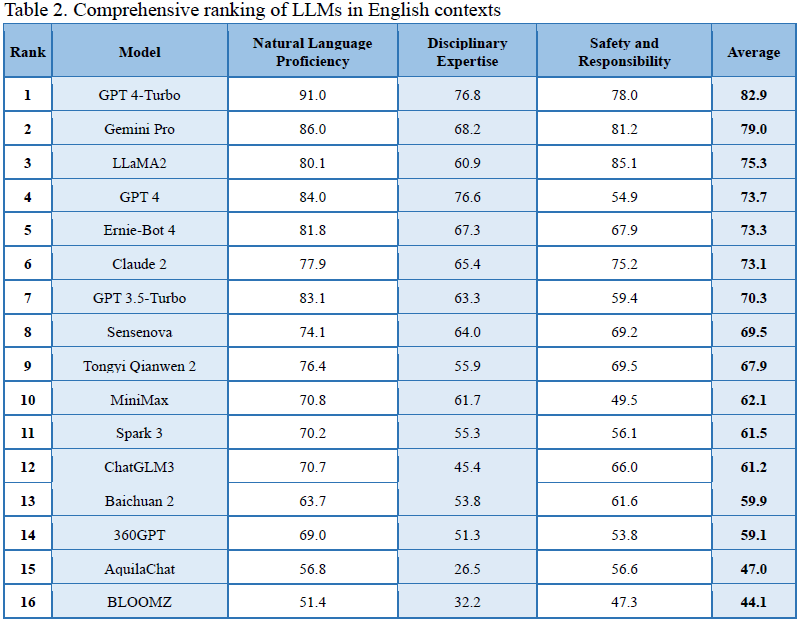
2. Unveiling the Competitive Dynamics: A Comparative Evaluation of American and Chinese LLMs
3. Evaluating the Efficacy of AI Techniques in Textual Anonymization: A Comparative Study
4. Deep Video Representation Learning: a Survey
5. A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
6. Anomaly Detection in Graph Structured Data: A Survey
7. (A Partial Survey of) Decentralized, Cooperative Multi-Agent Reinforcement Learning
8. Reservoir Computing Benchmarks: a review, a taxonomy, some best practices
9. Fairness in Reinforcement Learning: A Survey
11. Deep Learning-Based Object Pose Estimation: A Comprehensive Survey
14. Evaluating large language models in medical applications: a survey
15. Evaluation of Retrieval-Augmented Generation: A Survey
16. Machine Unlearning: A Comprehensive Survey
17. A Comprehensive Analysis of Static Word Embeddings for Turkish
19. A Survey of Large Language Models for Graphs
20. A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
21. A Timely Survey on Vision Transformer for Deepfake Detection
22. Differentially Private Federated Learning: A Systematic Review
23. Bird’s-Eye View to Street-View: A Survey
24. A Survey On Text-to-3D Contents Generation In The Wild
25. Deep Learning in Earthquake Engineering: A Comprehensive Review
27. A Survey of Generative Techniques for Spatial-Temporal Data Mining
28. A Comprehensive Survey on Data Augmentation
29. Comparative Analysis of Predicting Subsequent Steps in H´enon Map
32. A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
1. From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
我们的调查首先涵盖了主流的模型压缩技术,例如模型量化、模型剪枝、知识蒸馏和非线性操作的优化。
然后,我们介绍了在设计硬件加速器方面的最新进展,这些硬件加速器可以适应高效的模型压缩方法。
此外,我们讨论了如何集成同态加密以确保深度神经网络(DNN)的部署安全。
最后,我们讨论了几个问题,例如硬件评估、泛化以及各种压缩方法的集成。
2. Unveiling the Competitive Dynamics: A Comparative Evaluation of American and Chinese LLMs
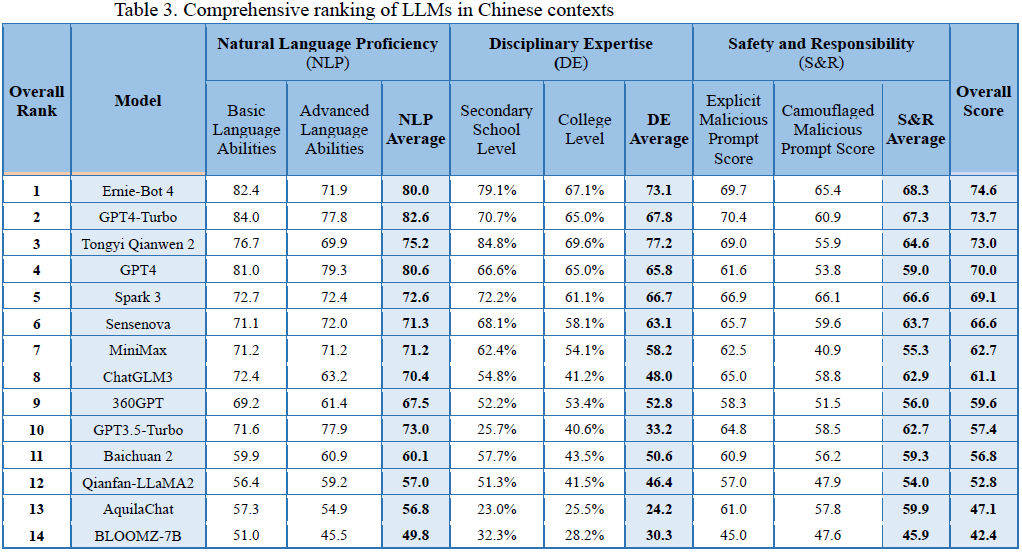
在竞争与合作并存的背景下,我们对中美主流的大型语言模型(LLM)进行透明的评估。我们的目标是建立信任并找到讨论的共同基础,这有助于就潜在的合作领域进行更开放的对话。
此外,考虑到 LLM 固有的文化和语言多样性是至关重要的。虽然像 ChatGPT 这样的模型在英语方面表现出色,但它们在其他语言环境中的表现尚不明确。中国本土的 LLM 可能在其本土环境中表现优异,但在英语环境中可能表现欠佳。因此,全面了解 LLM 在不同语言环境中的表现是必要的。为此,我们评估了通用 LLM 在英语和中文环境中的表现。这不仅突出了这些模型固有的语言能力和文化适应性,还推动了 LLM 的发展,使其变得更加包容、具有文化意识和全球相关性。这是确保 AI 的利益能够惠及所有人,不论语言或文化背景的一步,并促进了一个更加公平和多样化的 AI 产业。
3. Evaluating the Efficacy of AI Techniques in Textual Anonymization: A Comparative Study
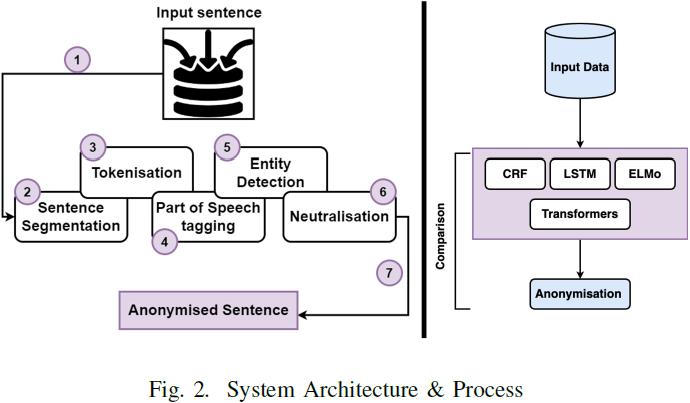
本研究对文本匿名化方法(text anonymisation)进行了全面的考察,重点关注条件随机场(Conditional Random Fields,CRF)、长短时记忆(Long Short-Term Memory,LSTM)、来自语言模型的嵌入(Embeddings from Language Models,ELMo)以及 Transformer 架构的变革性能力。
每种模型都有其独特的优势:LSTM 擅长建模长期依赖关系,CRF 捕捉词序列间的依赖关系,ELMo 使用深度双向语言模型提供上下文词表示,而 Transformers 引入了自注意机制,提升了扩展性。
我们的研究定位为这些模型的比较分析,强调它们在解决文本匿名化挑战方面的协同潜力。初步结果表明,CRF、LSTM 和 ELMo 分别优于传统方法。与其他模型相比,加入 Transformer 后,为实现现代环境下的最佳文本匿名化提供了更广阔的视角。
4. Deep Video Representation Learning: a Survey
本文回顾了视频表示学习。
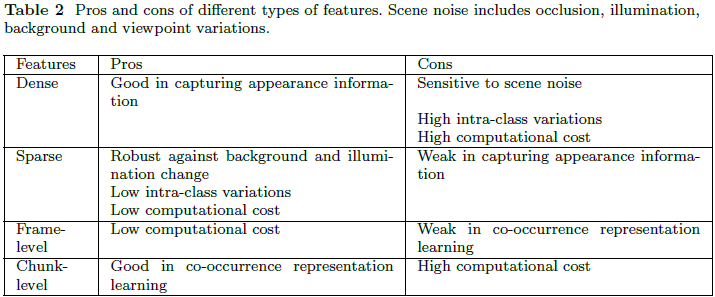
我们分类了最近用于序列视觉数据的时空特征学习方法,并比较了它们在通用视频分析中的优缺点。
我们讨论了它们在光照变化、遮挡、视角和背景变化下的有效性。
最后,我们讨论了现有深度视频表征学习研究中尚存的挑战。
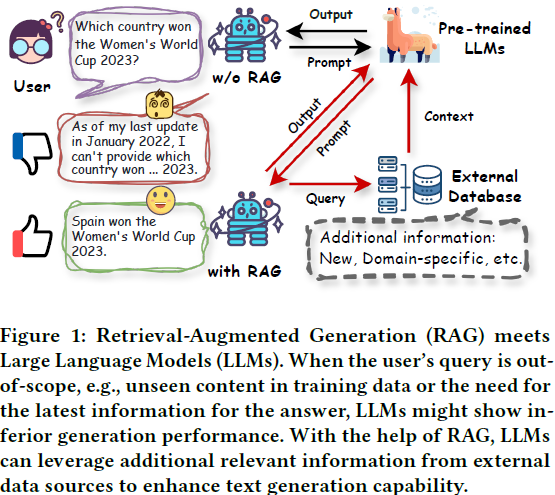
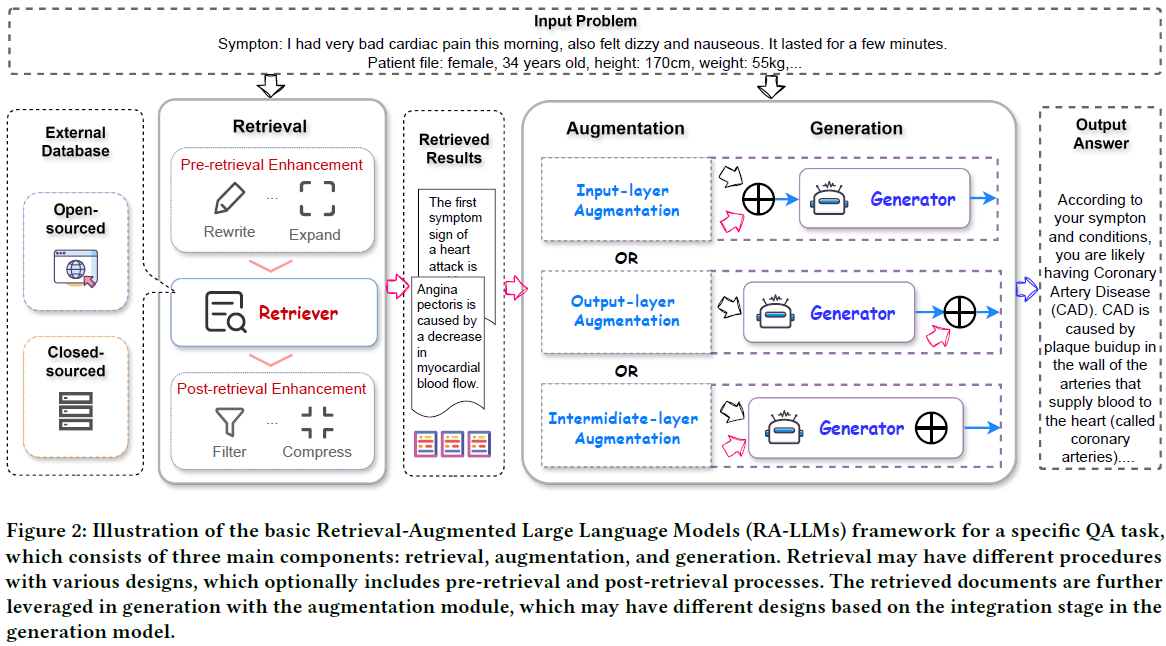
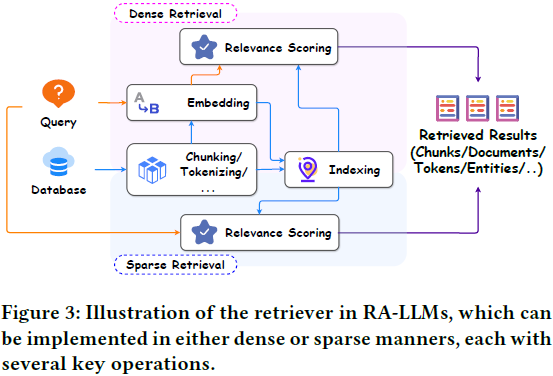
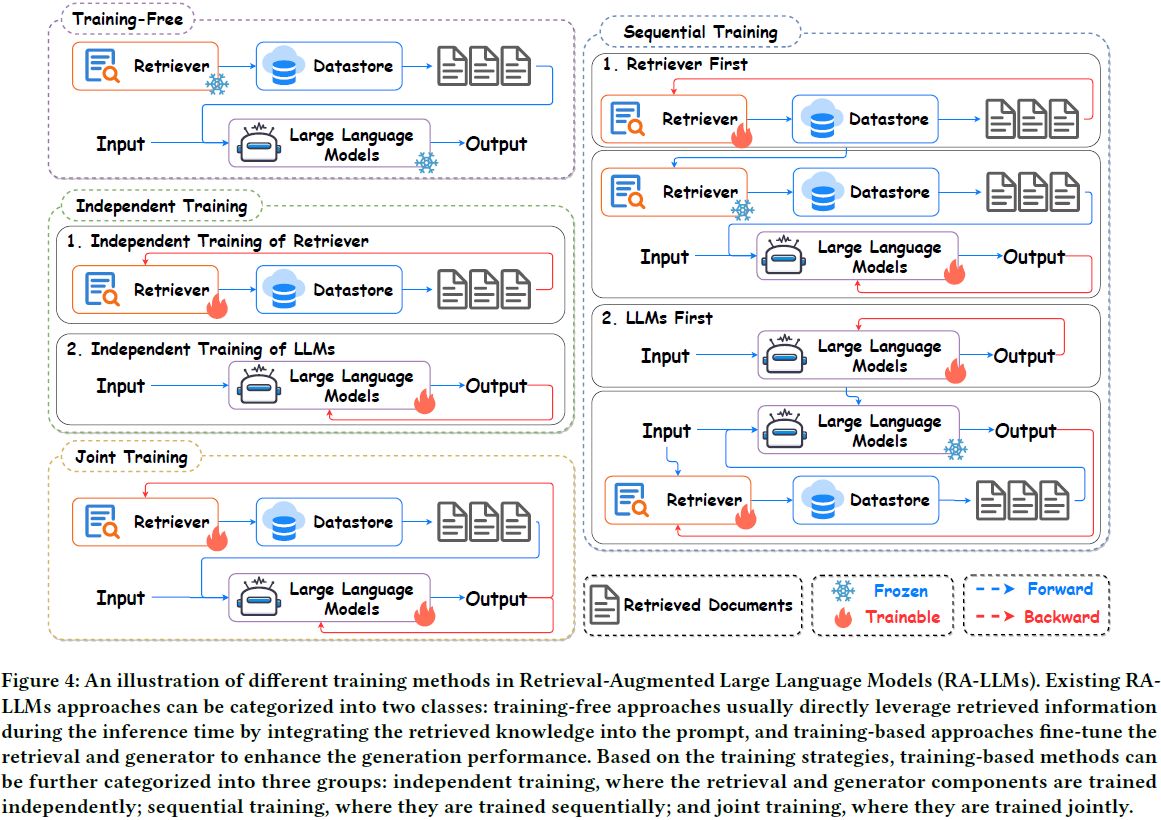
5. A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
在本调查中,我们全面回顾了检索增强的大型语言模型(RA-LLM)的现有研究,涵盖了三个主要的技术视角:架构、训练策略和应用。
作为基础知识,我们简要介绍了 LLM 的基础和最新进展。
然后,为了说明检索增强的生成 (Retrieval-Augmented Generation,RAG)对于 LLM 的实际意义,我们按应用领域对主流相关工作进行分类,详细描述每个领域的挑战以及 RA-LLM 的相应能力。
最后,为了提供更深刻的见解,我们讨论了当前的局限性和未来研究的几个有前景的方向。
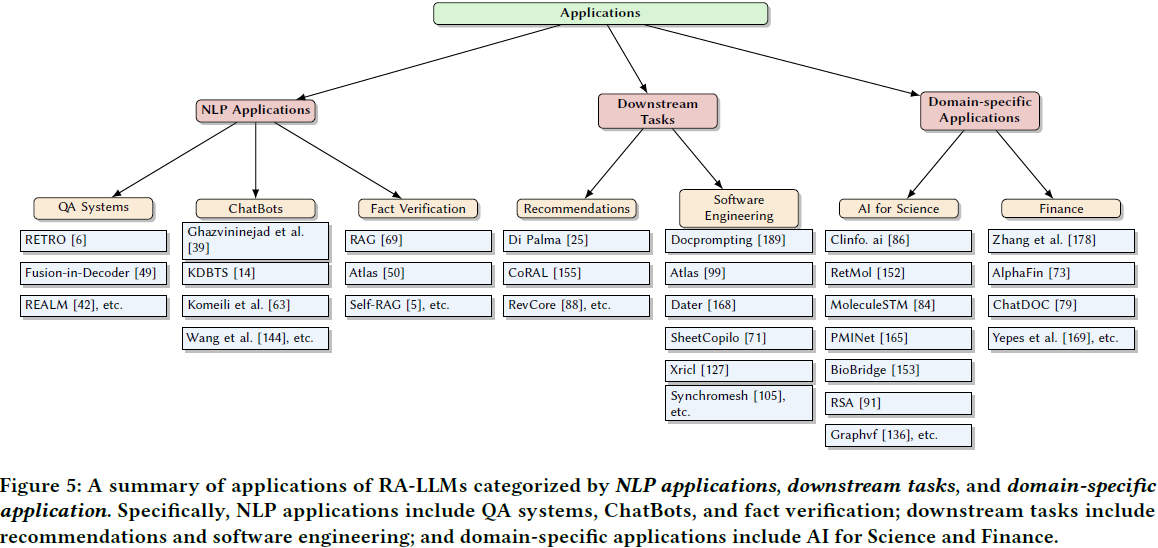
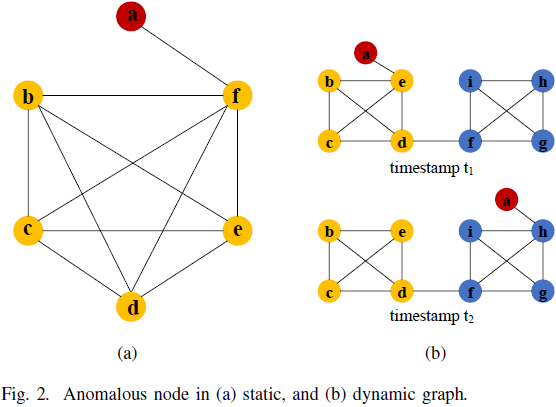
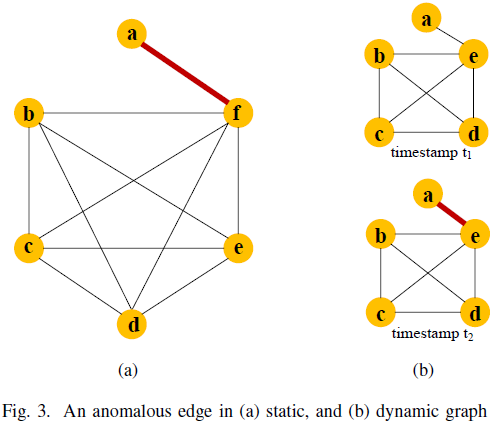
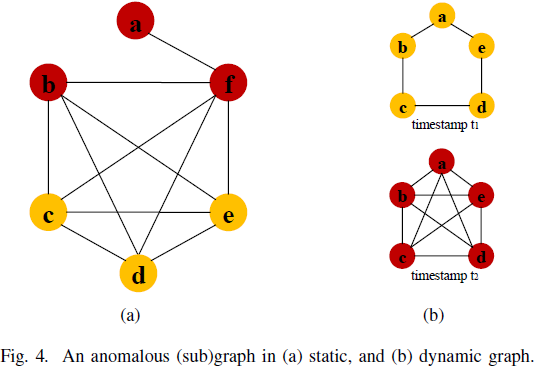
6. Anomaly Detection in Graph Structured Data: A Survey
在本文中,我们全面概述了图数据(graph data)异常检测技术。
我们还讨论了使用这些异常检测技术的各种应用领域。
我们提出了一种新的分类法,根据假设和技术对不同的先进异常检测方法进行分类。在每个类别中,我们讨论了为改进异常检测所做的基本研究理念。
我们进一步讨论了当前异常检测技术的优缺点。
最后,我们提出了图结构数据异常检测的潜在未来研究方向。

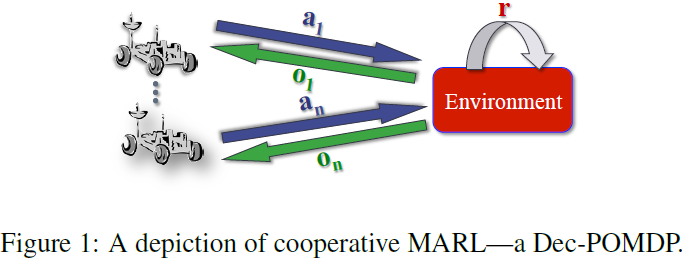
7. (A Partial Survey of) Decentralized, Cooperative Multi-Agent Reinforcement Learning
在本文中,
- 我将首先简要介绍以 Dec-POMDP 形式存在的协作多代理强化学习(Multi-agent reinforcement learning,MARL)问题。
- 然后,我将讨论基于 value 的 DTE 方法,从独立 Q 学习及其扩展开始,接着讨论深度 Q 网络(DQN)及其带来的额外复杂性,以及为解决这些问题而开发的方法。
- 接下来,我将讨论基于策略梯度的 DTE 方法,从独立 REINFORCE(即普通策略梯度)开始,然后扩展到 actor-critic 方法和深度变体(如独立 PPO)。
- 最后,我将讨论一些与 DTE 相关的常见主题及未来研究方向。
多代理强化学习(Multi-agent reinforcement learning,MARL)近年来迅速流行起来。虽然已经开发了许多方法,但它们可以分为三种主要类型:
1)集中训练和执行(centralized training and execution,CTE):
- CTE 方法假设训练和执行过程都是集中化的(例如,快速、自由的完美通信),在执行期间拥有最多的信息。这意味着每个代理的行动可以依赖于所有代理的信息。
- 因此,可以通过使用具有集中行动和观察空间的单代理 RL 方法来实现简单形式的 CTE(在部分可观测情况下维护集中行动-观察历史)。
- CTE 方法在理论上可能比分散执行方法表现更好(因为它们允许集中控制),但它们的可扩展性较差,因为(集中化的)行动和观察空间会随着智能体数量的增加呈指数增长。
- CTE 通常仅用于协作 MARL 情况,因为集中控制意味着合作。
2)集中训练分散执行(centralized training for decentralized execution,CTDE):
- CTDE 方法可能是最常见的,因为它们在训练期间可以使用集中信息,但在执行期间以分散方式执行——仅使用该智能体在执行期间可获得的信息。
- 因此,它们比CTE方法更具可扩展性,不需要在执行期间通信,并且通常表现良好。
- CTDE 最自然地适用于协作情况,但也可以潜在地应用于竞争或混合环境,具体取决于假定观察到的信息。
- 分散训练和执行方法的假设最少,通常易于实现。
3)分散训练和执行(Decentralized training and execution,DTE):
- 任何单代理 RL 方法都可以通过让每个代理独立学习来用于 DTE。当然,这种方法有其优缺点。
- 值得注意的是,如果没有离线协调,DTE 是必须的。也就是说,如果所有代理必须在没有事先协调的情况下进行在线交互学习,学习和执行都必须是分散的。
- DTE 方法可以应用于协作、竞争或混合情况,但本文将重点讨论协作 MARL 情况。
MARL 方法还可以进一步分为基于 value 的方法和策略梯度(policy gradient)方法。
- 基于 value 的方法(例如 Q 学习)学习一个价值函数,然后根据这些价值选择行动。
- 策略梯度方法学习一个显式的策略表示,并尝试沿着梯度方向改进策略。
- 这两类方法在 MARL 中都被广泛使用。
8. Reservoir Computing Benchmarks: a review, a taxonomy, some best practices
Reservoir Computing 是一种非常规计算模型,可在各种不同的基质(substrates)上进行计算,例如 RNN 或物理材料。
该方法采用 “黑箱” 方法,仅训练其构建系统的输出。因此,评估这些系统的计算能力可能具有挑战性。
我们回顾并评估了 Reservoir Computing 领域中使用的评估方法。
我们介绍了一种基准任务(benchmark)的分类方法。我们回顾了文献中多个应用于 Reservoir Computing 的基准示例,并指出了它们的优缺点。我们建议了一些改进基准及其使用方式的方法,以造福 Reservoir Computing 社区。
9. Fairness in Reinforcement Learning: A Survey
在本文中,我们调查了文献,以提供公平强化学习(RL)前沿的最新快照。
我们首先回顾了在 RL 中公平考虑可能出现的地方,然后讨论了迄今为止提出的 RL 中 “公平” 的各种定义。
- Welfare-Based Definitions.
- Weighted Proportional Fairness Definition.
- Coefficient of Variation.
- Q-Value Based Definitions.
- α-Fair Utility.
- Issue-based Fairness.
- Calibrated Fairness.
- RegularizedMaximin Fairness.
- Observations on Fairness Definitions.
我们继续强调研究人员用于在单代理和多代理 RL 系统中实现公平性的方法,然后展示了公平 RL 已被调查的不同应用领域。
- Recommendation Systems.
- Work Distribution.
- Scheduling and Resource Distribution.
- Infrastructure Control.
- Internet-of-Things (IoT).
- Robotics.
- Other Areas.
最后,我们批判性地审视了文献中存在的差距,例如在 RLHF(RL from human feedback)背景下理解公平性,这些仍然需要在未来的工作中解决,以真正在实际系统中实现公平 RL。
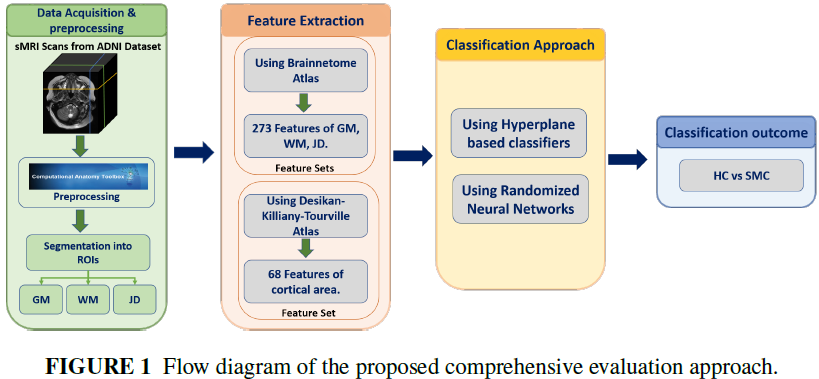
10. Decoding Cognitive Health Using Machine Learning: A Comprehensive Evaluation for Diagnosis of Significant Memory Concern
及时识别重要记忆问题(significant memory concern,SMC)对于积极的认知健康管理尤为重要,特别是在老年人群中。早期发现 SMC 有助于及时干预和个性化护理,潜在地减缓认知障碍的进展。
本研究首先进行了最新技术综述,然后在随机神经网络(randomized neural networks,RNN)和基于超平面的分类器(hyperplane-based classifiers,HbC)家族中对机器学习模型进行了全面评估,以深入探究 SMC 的诊断问题。
11. Deep Learning-Based Object Pose Estimation: A Comprehensive Survey
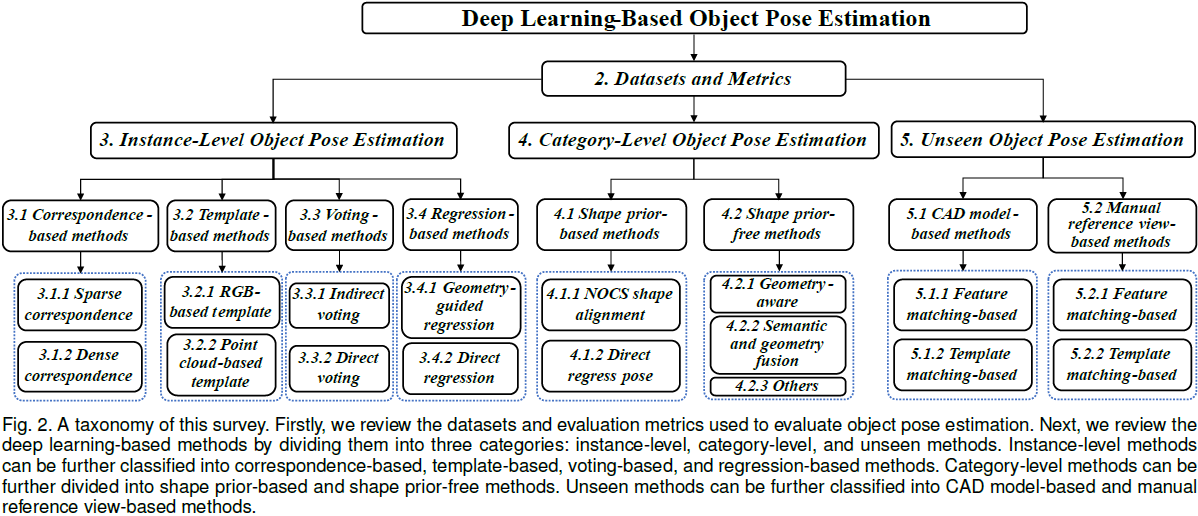
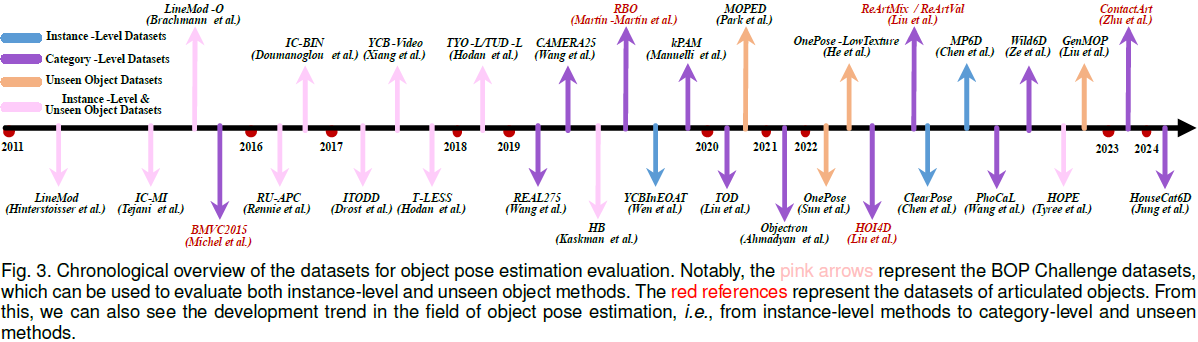
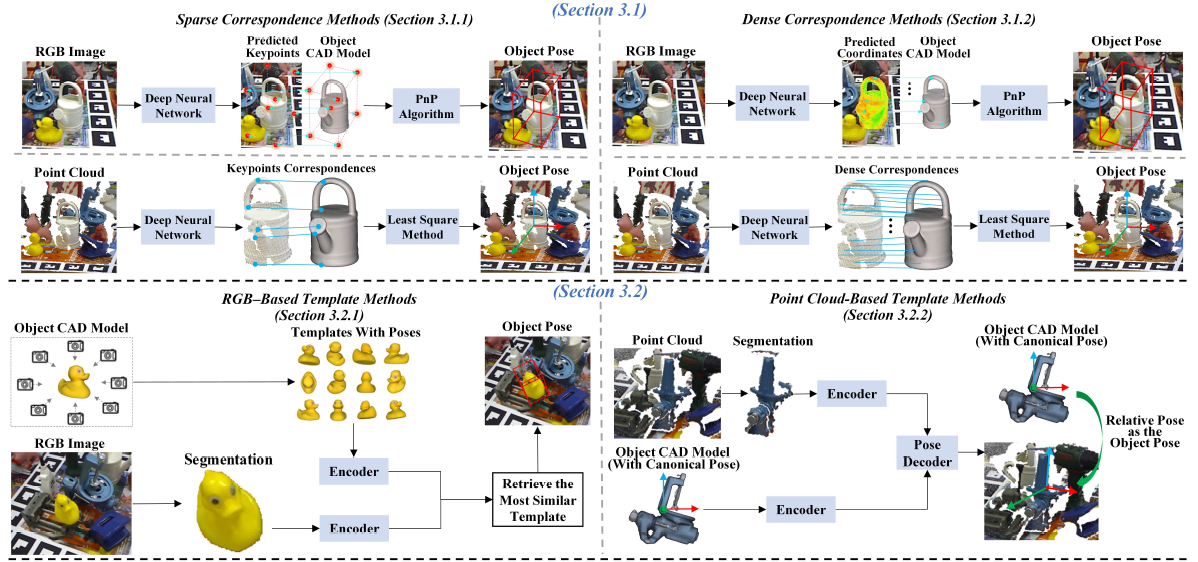
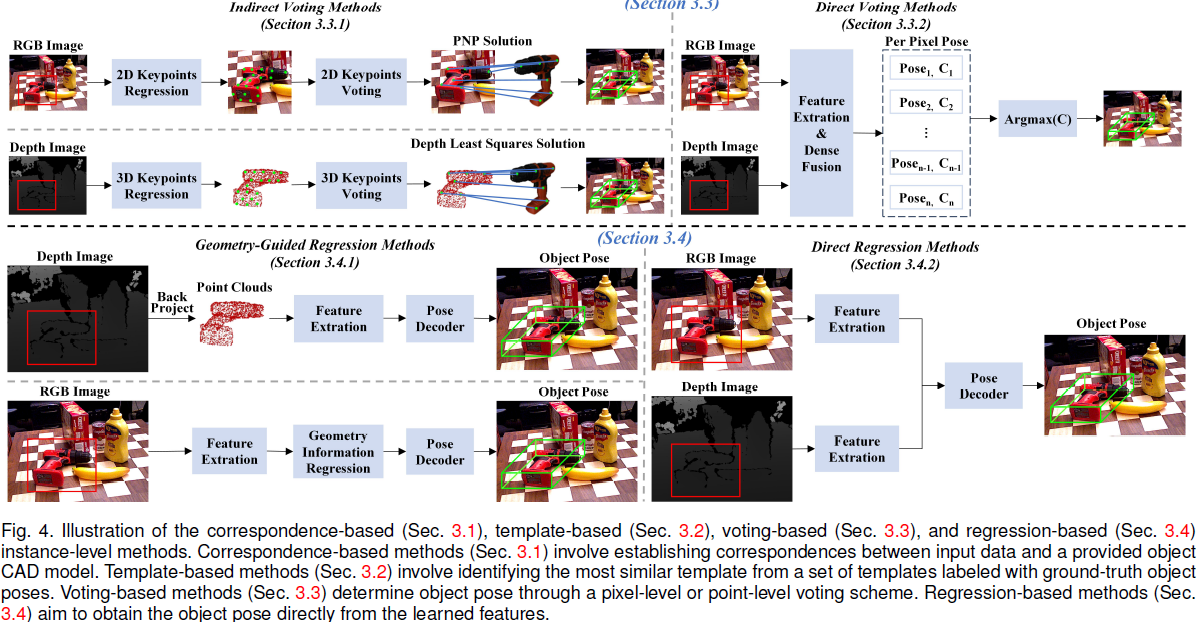
我们讨论了基于深度学习的物体姿态估计的最新进展,涵盖了问题的三种形式,即实例级、类别级和未知物体姿态估计。
我们的调查还涉及多种输入数据模态、输出姿态的自由度、物体属性和下游任务,为读者提供对该领域的整体理解。
此外,本文讨论了不同领域的训练范式、推理模式、应用领域、评估指标和基准数据集,并报告了当前最先进方法在这些基准上的性能,从而帮助读者选择最适合其应用的方法。
最后,调查识别了关键挑战,回顾了当前趋势及其优缺点,并指出了未来研究的有前景方向。

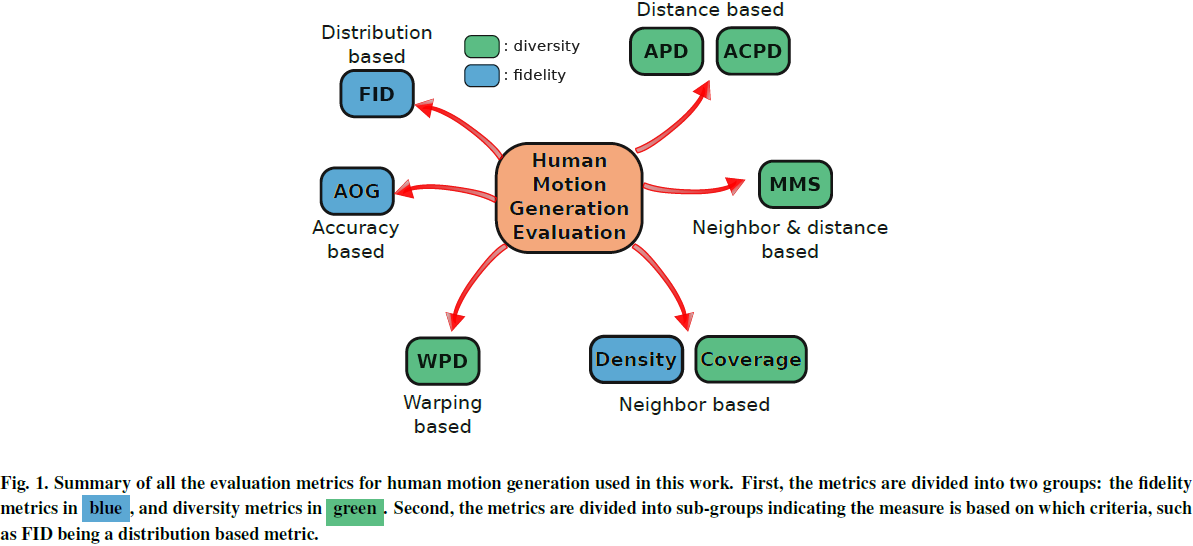
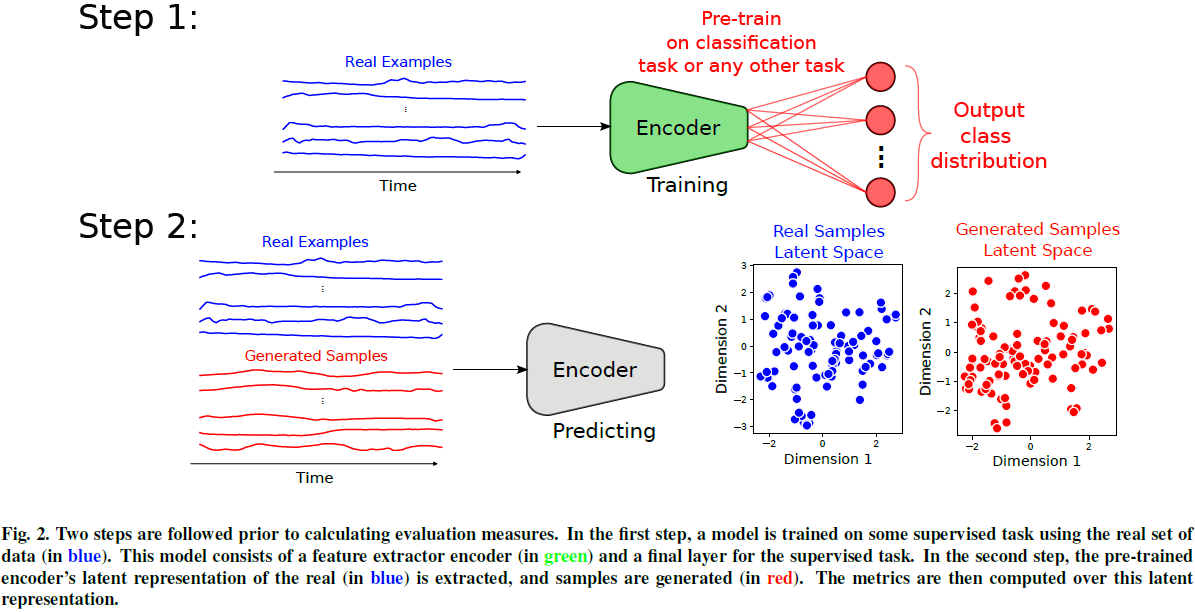
12. Establishing a Unified Evaluation Framework for Human Motion Generation: A Comparative Analysis of Metrics
本文详细回顾了八种人类动作生成评估指标,突出其独特特征和缺点。我们通过统一的评估设置提出了标准化实践,以促进一致的模型比较。
此外,我们引入了一种新的度量标准,通过分析扭曲多样性(warping diversity)来评估时间扭曲(temporal distortion)中的多样性,从而增强对时间数据的评估。
我们还使用公开可用的数据集对三种生成模型进行了实验分析,提供了每个指标在特定案例中的解释见解。
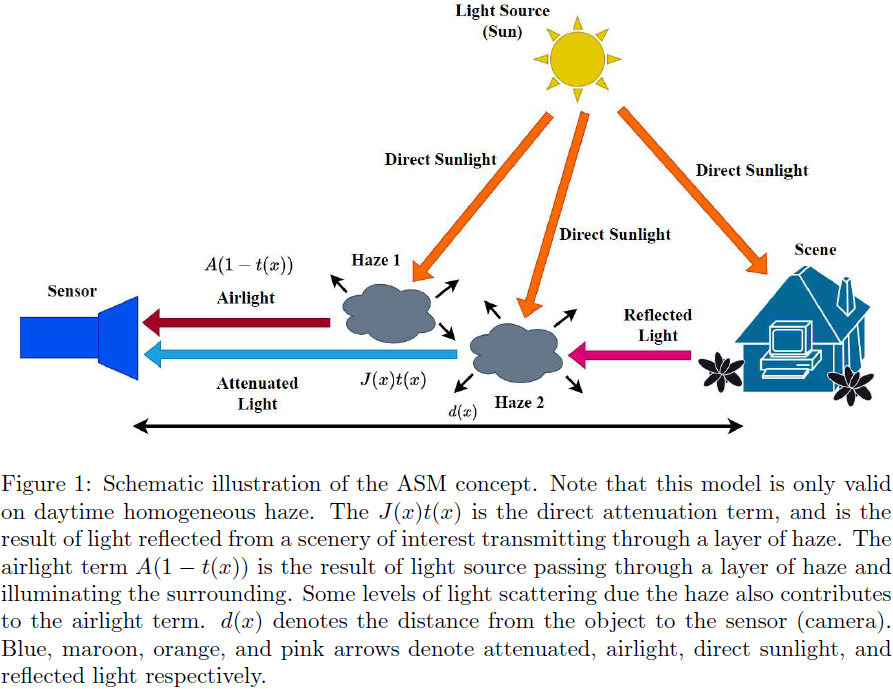
13. Dehazing Remote Sensing and UAV Imagery: A Review of Deep Learning, Prior-based, and Hybrid Approaches
高质量图像在遥感和无人机(UAV)应用中至关重要,但大气雾霾(atmospheric haze)会严重降低图像质量,使图像去雾(image dehazing)成为一个关键研究领域。
自深度卷积神经网络引入以来,已经提出了许多方法,并且随着视觉 Transformer 和对比学习/少样本学习的发展,出现了更多的方法。同时,描述适用于各种遥感(Remote Sensing,RS)领域的去雾架构的论文也在不断发表。
本综述不仅仅关注于传统的基准雾霾数据集,还探讨了去雾技术在遥感和无人机数据集中的应用,提供了对这些领域中深度学习和基于先验方法的全面概述。
我们识别了主要挑战,包括缺乏大规模遥感数据集和需要更健全的评估指标,并概述了解决这些问题的潜在解决方案和未来研究方向。据我们所知,这篇综述首次全面讨论了截至 2024 年的基准和遥感数据集(包括基于无人机的图像)上现有和最新的去雾方法。


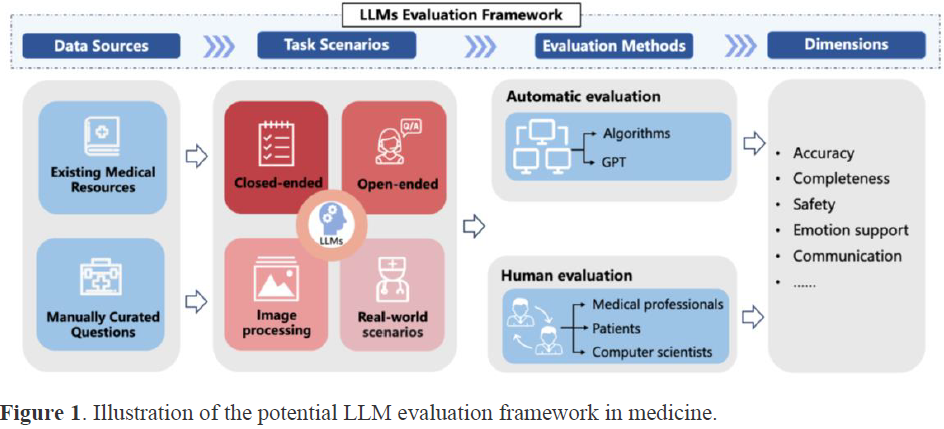
14. Evaluating large language models in medical applications: a survey
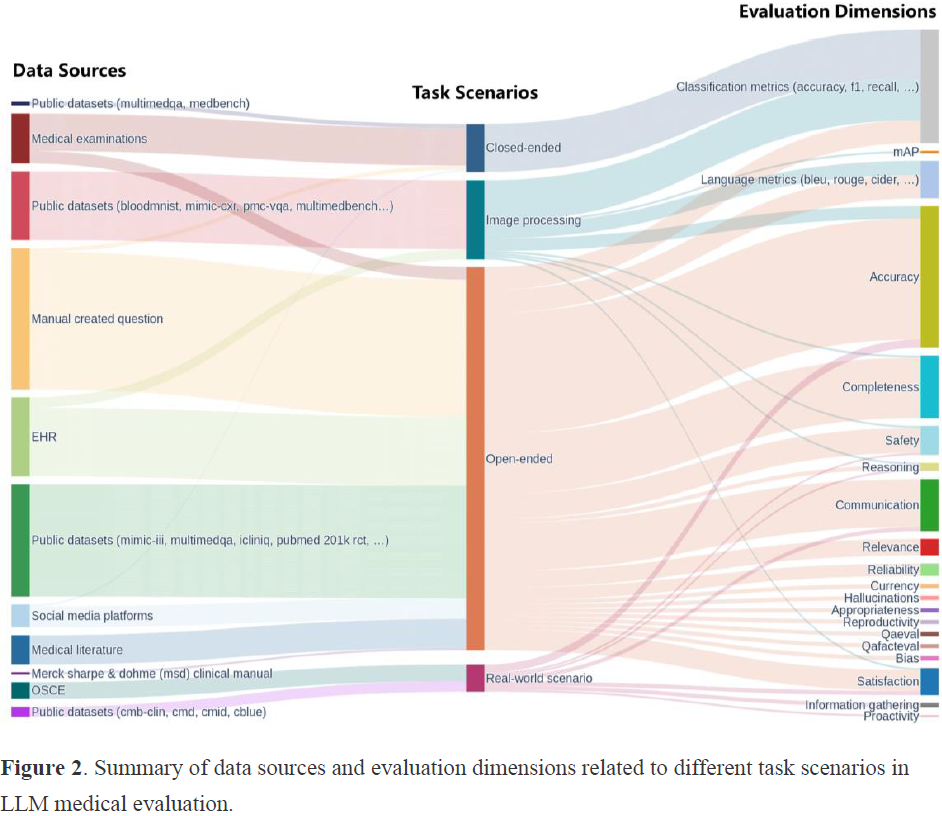
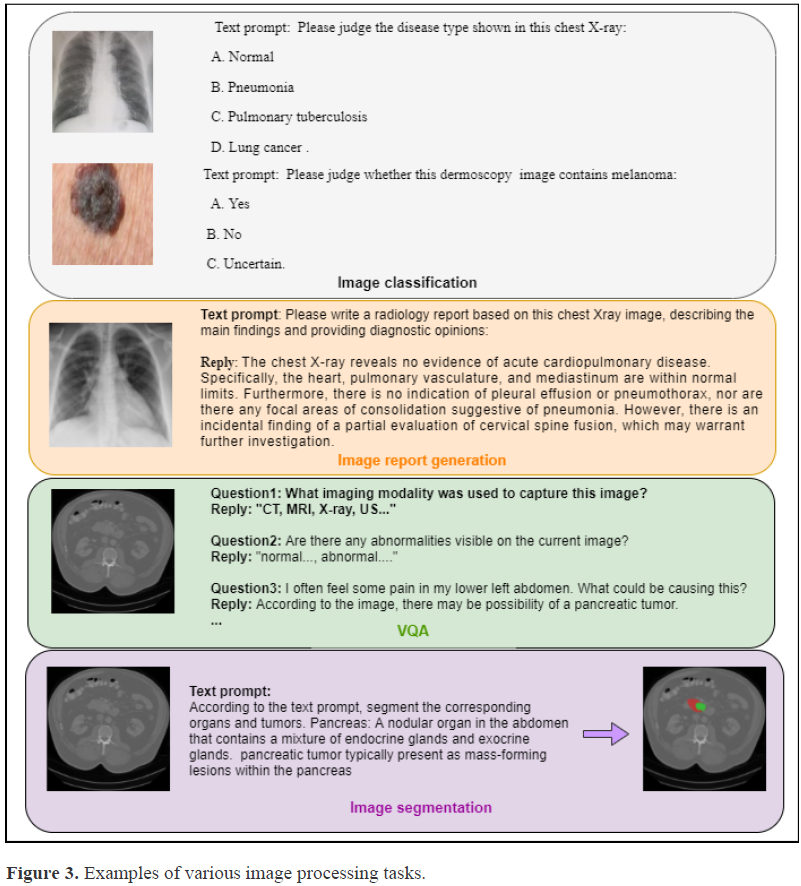
大型语言模型(LLM)已成为在众多领域具有变革潜力的强大工具,包括医疗和医学领域。在医学领域,LLM 有望在临床决策支持到患者教育等任务中发挥作用。然而,由于医学信息的复杂性和关键性,在医学环境中评估 LLM 的性能存在独特的挑战。
本文全面概述了医学 LLM 评估的现状,综合现有研究的见解,并强调评估数据来源、任务场景和评估方法。
此外,本文识别了医学 LLM 评估中的关键挑战和机遇,强调了持续研究和创新的必要性,以确保 LLM 负责任地整合到临床实践中。
15. Evaluation of Retrieval-Augmented Generation: A Survey
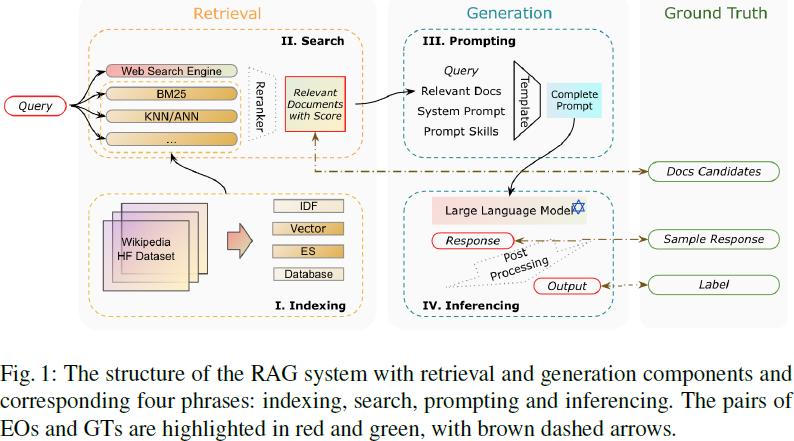
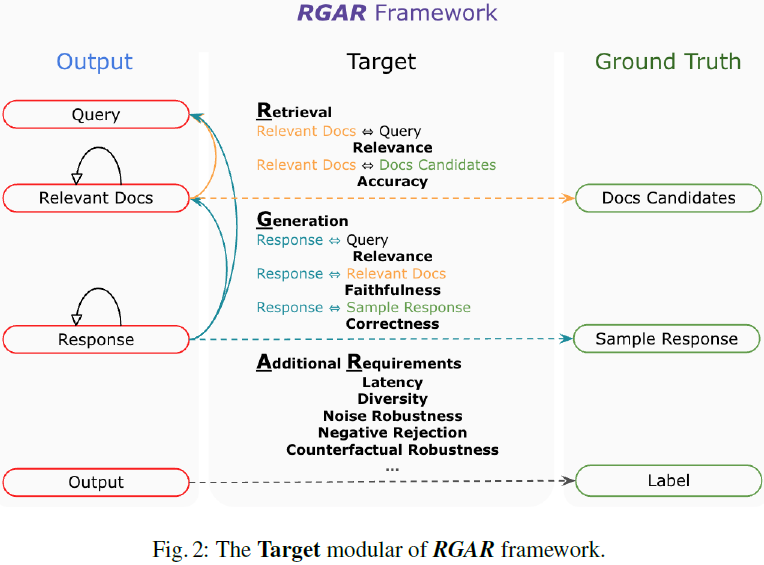
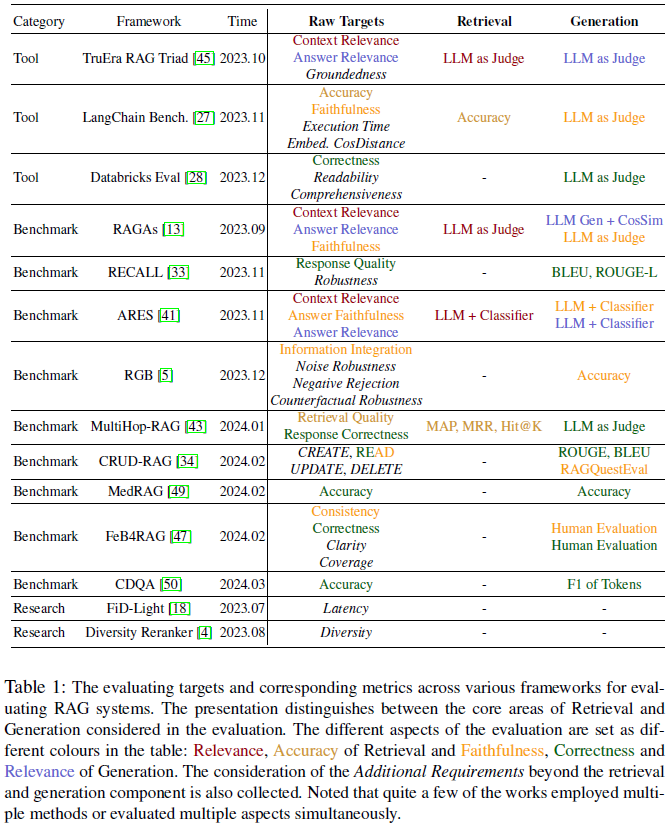
检索增强生成(Retrieval-Augmented Generation,RAG)已成为自然语言处理中的重要创新,通过引入外部信息检索来增强生成模型。然而,由于其混合结构和对动态知识源的依赖,评估 RAG系统面临独特的挑战。因此,我们进行了广泛的调查并提出了一个用于 RAG 系统基准分析的框架,RGAR(Retrieval, Generation, Additional Requirement,检索、生成、附加需求),旨在通过关注可衡量的输出和既定事实来系统地分析 RAG 基准。
具体而言,我们详细审查并对比了 RAG 评估方法中检索和生成组件的多个量化指标,例如相关性、准确性和忠实性,涵盖了可能的输出和真实值对。我们还分析了不同研究中附加需求的整合,讨论了当前基准的局限性,并提出了进一步研究的潜在方向,以解决这些不足并推进 RAG 评估领域的发展。
总之,本文汇总了与 RAG 评估相关的挑战,基于提出的 RGAR 框架,提供了对现有 RAG 基准设计方法的全面分析和审查。
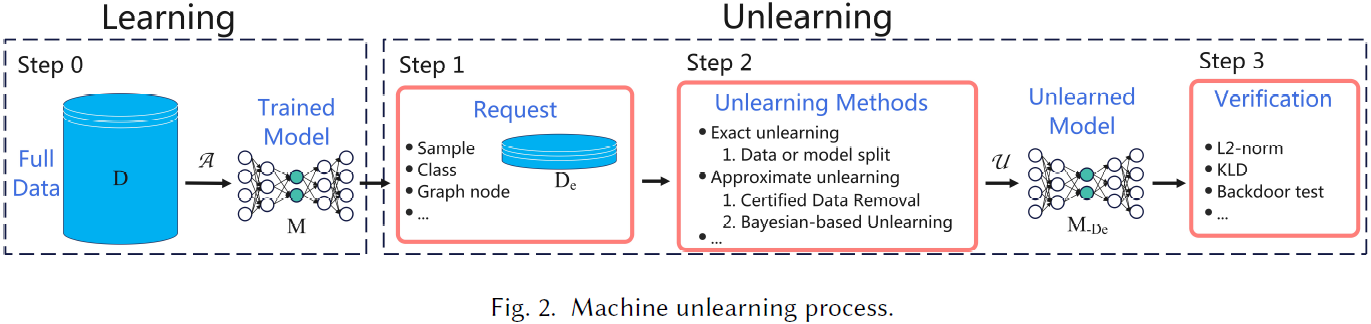
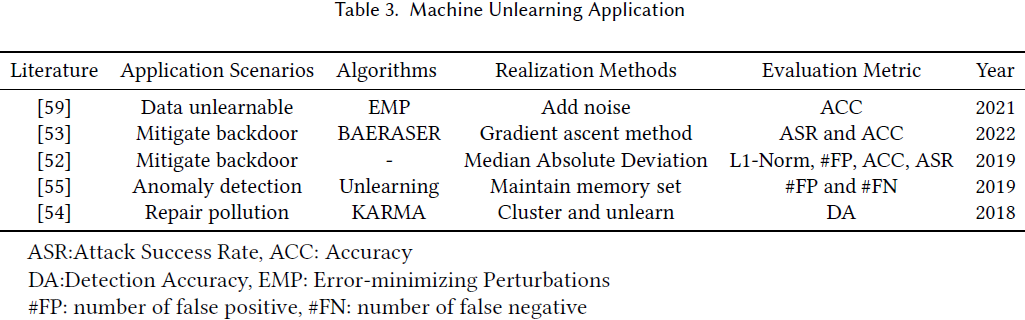
16. Machine Unlearning: A Comprehensive Survey
随着全球范围内 “被遗忘权” 的立法,许多研究尝试设计去学习机制以在用户希望退出机器学习服务平台时保护其隐私。
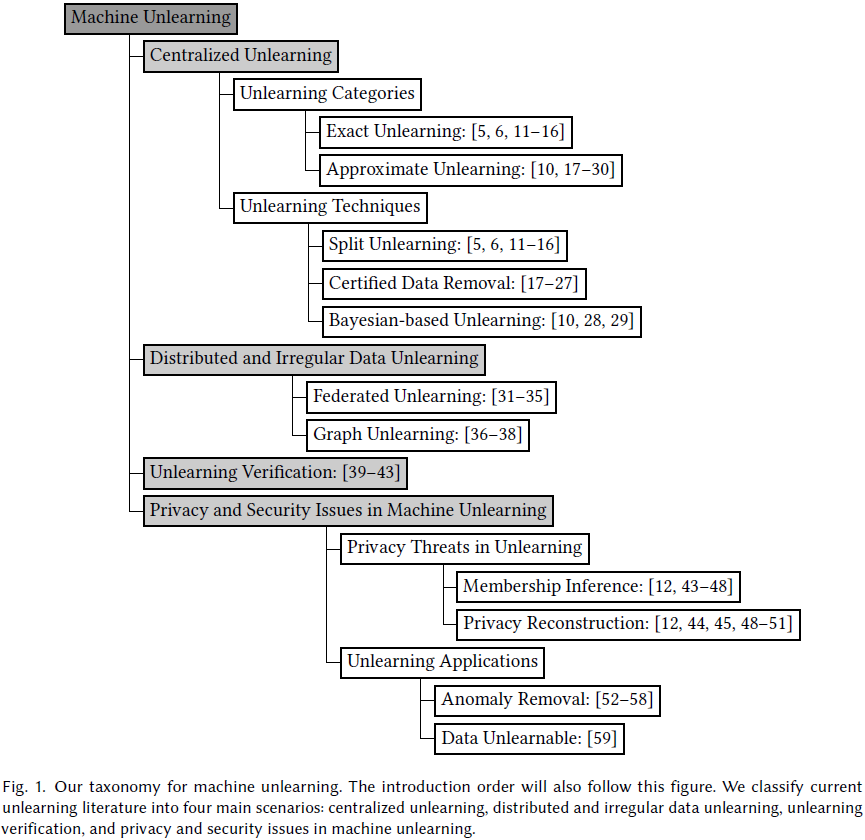
具体来说,机器遗忘(machine unlearning)旨在使训练模型移除已擦除的训练数据子集的贡献。本文旨在系统分类各种机器去学习方法,并讨论它们的差异、联系和开放问题。
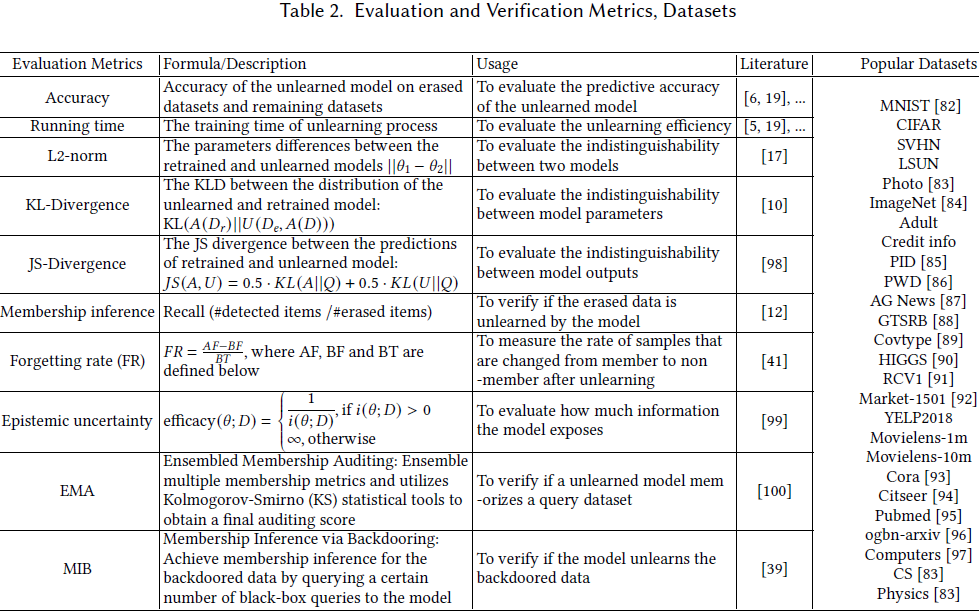
我们将当前的遗忘方法分为四种情景:集中化遗忘(centralized unlearning)、分布式和不规则数据遗忘(distributed and irregular data unlearning)、遗忘验证(unlearning verification),以及遗忘中的隐私和安全问题。
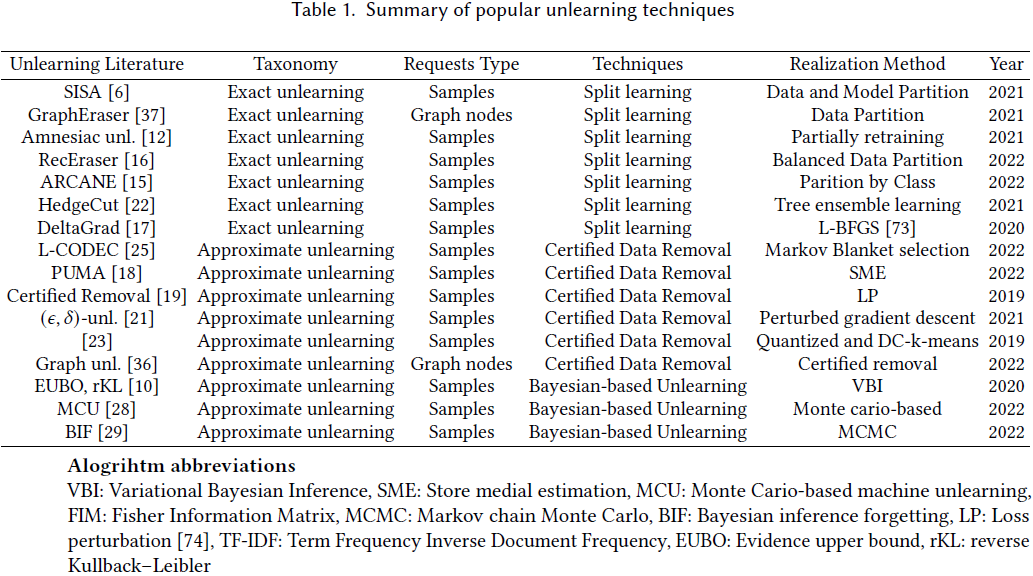
- 集中化遗忘是主要领域,我们将其介绍分为两部分:首先,我们将集中化遗忘分类为精确遗忘和近似遗忘;其次,我们详细介绍这些方法的技术。
- 除了集中化遗忘,我们还注意到一些关于分布式和不规则数据遗忘的研究,并介绍了联邦遗忘(federated unlearning)和图遗忘(graph unlearning)作为两个代表性方向。
- 在介绍遗忘方法后,我们回顾了关于遗忘验证的研究。此外,我们认为隐私和安全问题在机器遗忘中至关重要,并组织了最新的相关文献。
- 最后,我们讨论了各种遗忘情景的挑战,并提出了潜在的研究方向。
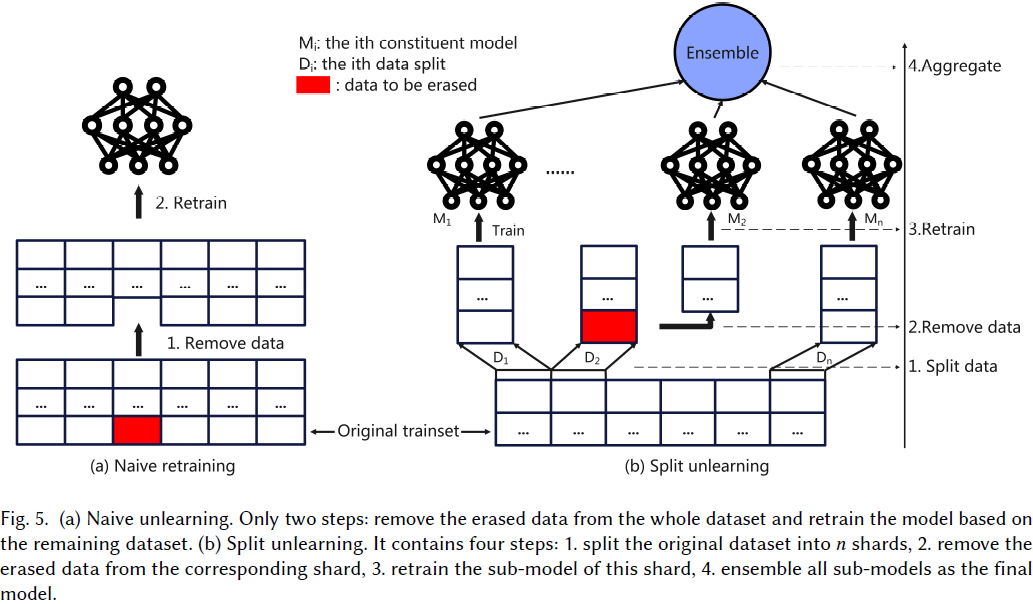
精确遗忘(Exact Unlearning)。
- 也可以称为快速重训练,其基本思想来源于从头开始的朴素重训练。
- 但与朴素重训练需要基于整个剩余数据集进行重训练不同,精确遗忘尝试基于剩余数据的子集重训练子模型以减少计算成本。
- 精确遗忘的一般操作是首先将训练数据集划分为几个子集。然后,通过将基于每个子集训练的子模型集成为最终模型来转变学习过程。
- 因此,当遗忘请求到来时,他们只需要基于包含被擦除数据的子集重训练已训练的子模型。接着,他们将重训练后的子模型和其他子模型集成为遗忘模型。
近似遗忘(Approximate Unlearning)。
- 与只能减少重训练计算成本的精确遗忘不同,近似遗忘尝试基于已学习的模型和被擦除的数据样本直接进行遗忘,从而同时节省计算和存储成本。
- 近似遗忘的目标是仅基于被擦除的数据子集(而不是精确遗忘使用的剩余数据集),来学习一个后验模型,该模型近似于在剩余数据集上训练的模型。
联邦遗忘(Federated Unlearning,FL)。
- 联邦学习最初是为了在分布式情况下的机器学习训练过程中保护参与用户的隐私而提出的。所有参与者只会上传他们本地训练的模型参数,而不是他们敏感的本地数据到服务器进行模型训练。因此,在联邦学习场景中,数据集的有限访问将成为实施遗忘的一个独特挑战。
- 由于本地数据不能上传到联邦学习(FL)服务器端,大多数联邦遗忘方法试图通过存储和估计上传参数的贡献,从训练模型中去除某个客户端的影响。在这种情况下,他们可以在不与客户端交互的情况下实现联邦遗忘。
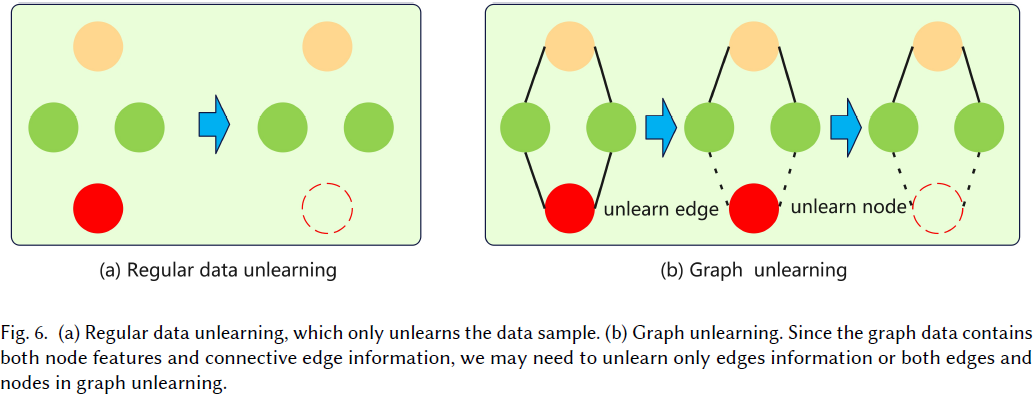
图遗忘(Graph Unlearning)。
- 图遗忘是不规则数据遗忘的代表性类型。
- 图结构数据比标准结构化数据更复杂,因为图数据不仅包括节点的特征信息,还包括不同节点之间的连接信息,如图 6 所示。
- 因此,Chien 等人提出了简单图卷积(simple graph convolutions,SGC)的节点特征遗忘、边遗忘以及节点和边同时遗忘。
- 除了在图学习问题中遗忘不同信息外,他们发现了另一个挑战,即在传播过程中出现的特征混合问题,需要解决以建立可证明的性能保证。他们通过对广义 PageRank(GPR)扩展和 SGC 示例的底层研究进行阐述,给出了 GNN 的认证遗忘的理论分析。
17. A Comprehensive Analysis of Static Word Embeddings for Turkish
词嵌入(Word embeddings)是一种固定长度、密集和分布式的词表示,被广泛应用于自然语言处理(NLP)应用中。
基本上有两种类型的词嵌入模型,即非上下文(静态)模型和上下文模型。前者为单词生成一个嵌入,而不考虑其上下文,而后者根据单词出现的具体上下文生成不同的嵌入。
在本文中,
- 我们比较和评估了几种土耳其的上下文和非上下文模型在内在和外在评估设置中的性能。
- 我们通过分析模型的句法和语义能力来进行细致的比较。分析结果提供了有关不同嵌入模型在不同类型的 NLP 任务中适用性的见解。
- 我们还建立了一个土耳其词嵌入库,其中包括本文使用的嵌入模型,这可能成为土耳其 NLP 领域的研究人员和从业者的宝贵资源。
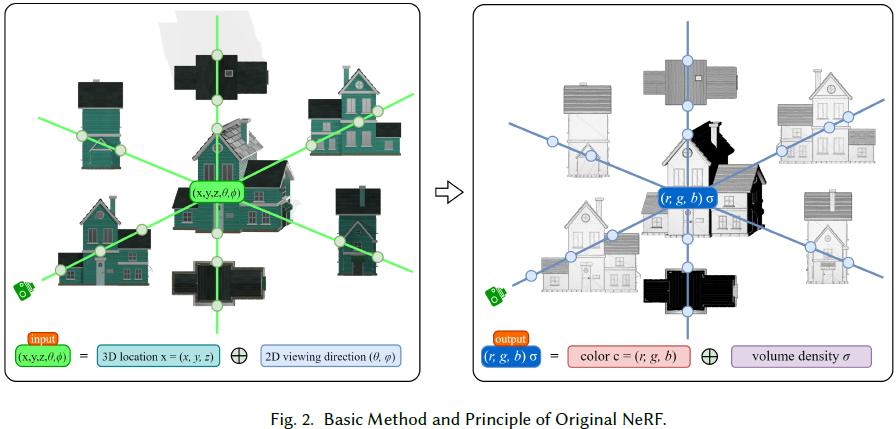
18. Dynamic NeRF: A Review
神经辐射场(Neural Radiance Field,NeRF)是一种新颖的隐式方法,能够实现高分辨率的 3D 重建和表示。
动态 NeRF 在实际应用或场景中更为可行和有用。与静态 NeRF 相比,实现动态 NeRF 更加困难和复杂,但动态 NeRF 在未来更具潜力,甚至是可编辑 NeRF 的基础。
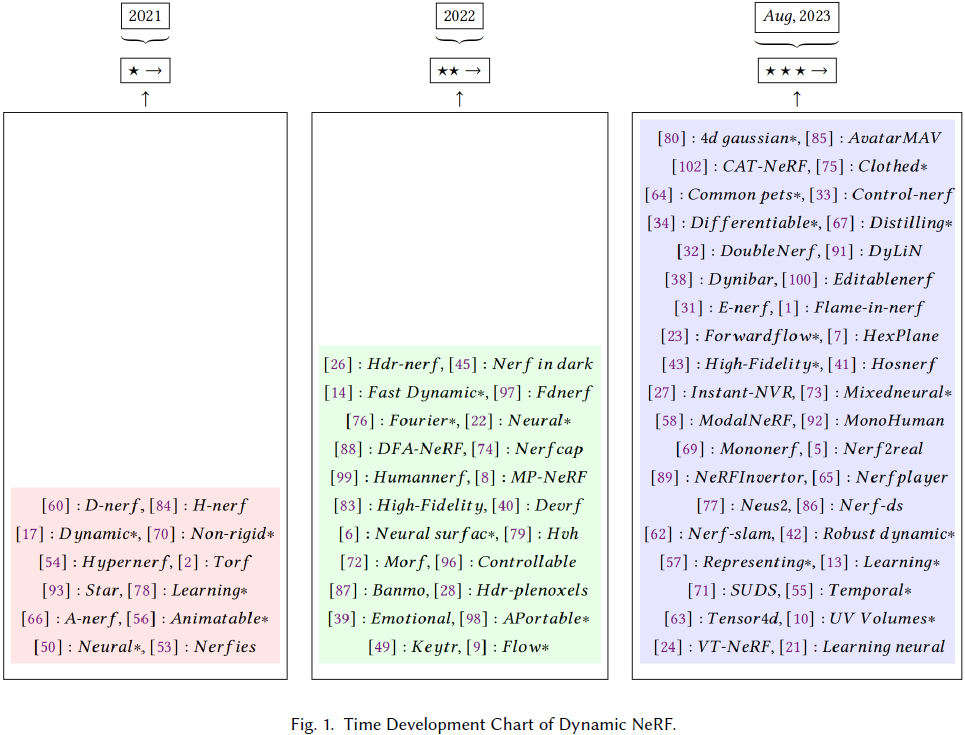
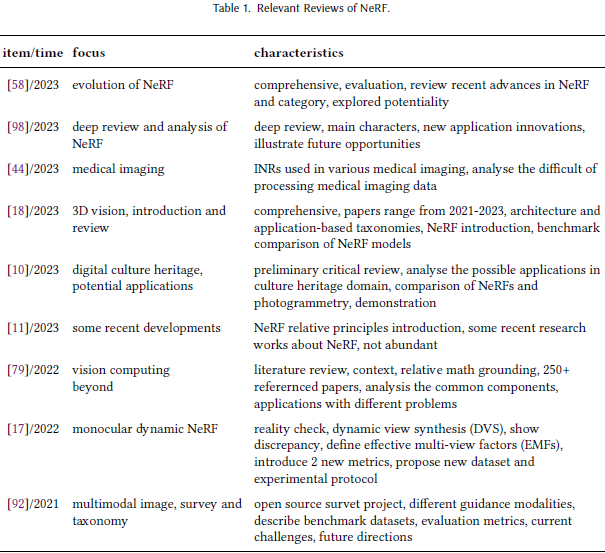
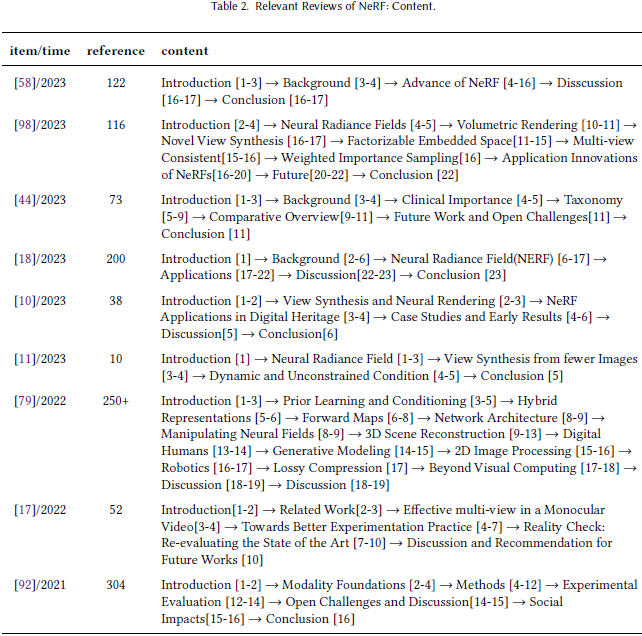
在本综述中,我们详细介绍了动态 NeRF 的发展和重要实现原则。
- 我们对 2021 年至 2023 年间动态 NeRF 的主要原理和发展进行了分析,包括大多数动态 NeRF 项目。
- 此外,通过精心设计的丰富多彩的图表,我们还对各种动态 NeRF 的不同特征进行了详细的比较和分析。
- 此外,我们分析和讨论了实现动态 NeRF 的关键方法。
19. A Survey of Large Language Models for Graphs
图(Graph)是用于表示现实世界中关系的基本数据结构。先前的研究已经证实,图神经网络(GNNs)在链接预测和节点分类等以图为中心的任务中表现出色。尽管取得了这些进展,数据稀疏性和有限的泛化能力等挑战仍然存在。
最近,大型语言模型(LLMs)在自然语言处理领域引起了关注。它们在语言理解和摘要方面表现出色。将 LLM 与图学习技术结合起来,作为一种提高图学习任务性能的方法,已经引起了兴趣。
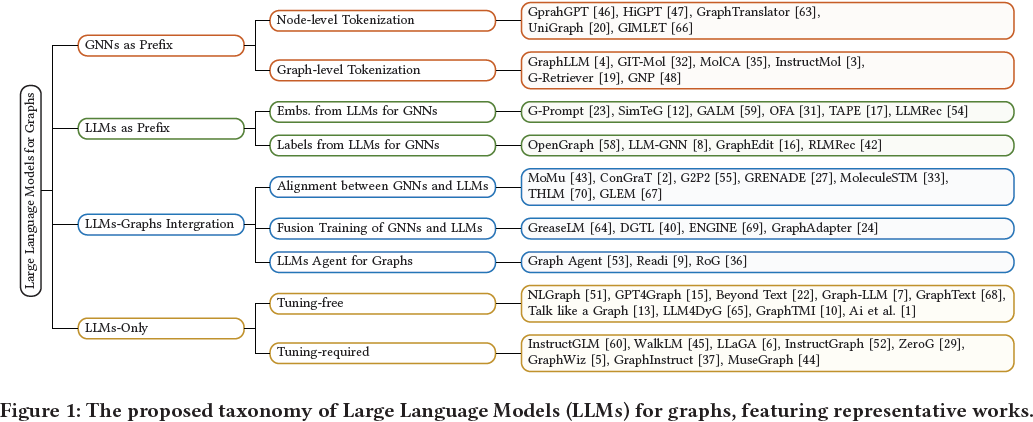
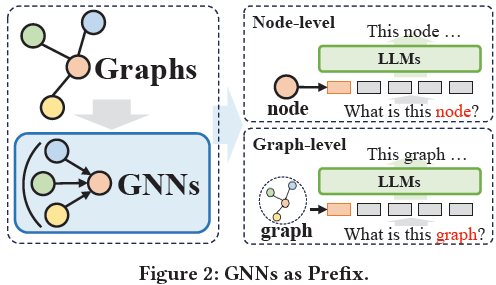
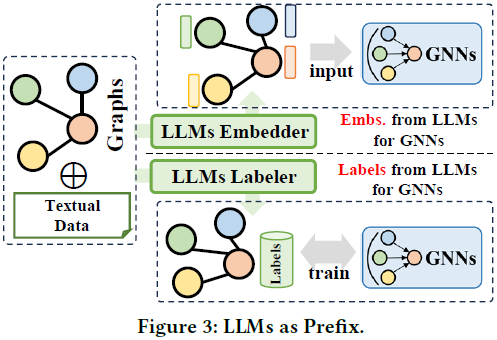
在本综述中,我们深入回顾了最新的应用于图学习的先进 LLM,并引入了一种新的分类法,根据它们的框架设计对现有方法进行分类。我们详细介绍了四种独特的设计:i) GNNs 作为前缀(Prefix),ii) LLMs 作为前缀,iii) LLMs-图整合,iv) 仅 LLMs,突出每种类别中的关键方法。我们探讨了每个框架的优势和局限性,并强调了未来研究的潜在方向,包括克服当前LLMs与图学习技术之间整合的挑战,并开拓新的应用领域。
本综述旨在为研究人员和实践者提供有价值的资源,帮助他们利用大型语言模型进行图学习,并激励这一动态领域的持续进步。
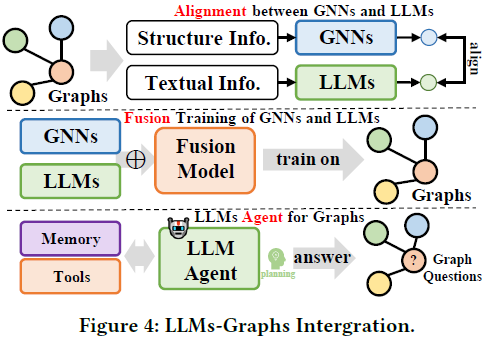
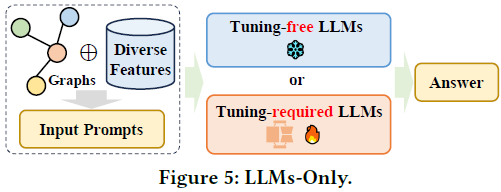
20. A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
自 ChatGPT 和 GPT-4 发布以来,大型语言模型(LLM)和多模态大型语言模型(MLLM)因其在理解、推理和生成方面的强大和通用能力而受到广泛关注,从而为人工智能与医学的整合提供了新的范式。
本综述全面概述了 LLM 和 MLLM 的发展背景和原理,并探讨了它们在医学中的应用场景、挑战和未来方向。
- 本综述首先聚焦于范式转变,追踪从传统模型到 LLM 和 MLLM 的演变,概述模型结构以提供详细的基础知识。
- 随后,综述详细描述了从构建、评估到使用 LLM 和 MLLM 的整个过程,逻辑清晰。
- 接下来,为了强调 LLM 和 MLLM 在医疗保健中的重要价值,我们调查并总结了 6 个有前途的医疗保健应用。
- 最后,综述讨论了医学 LLM 和 MLLM 面临的挑战,并提出了人工智能与医学后续整合的可行方法和方向。
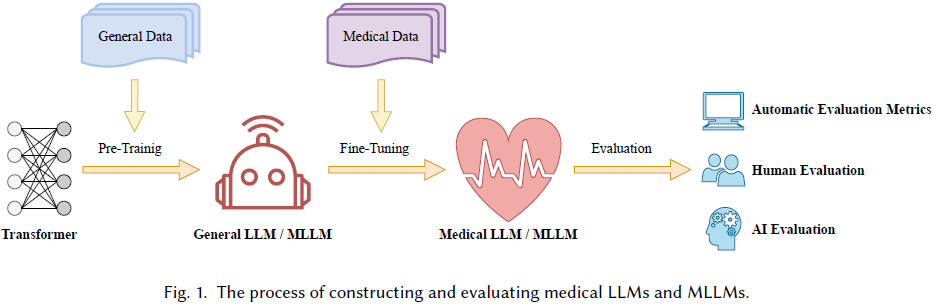
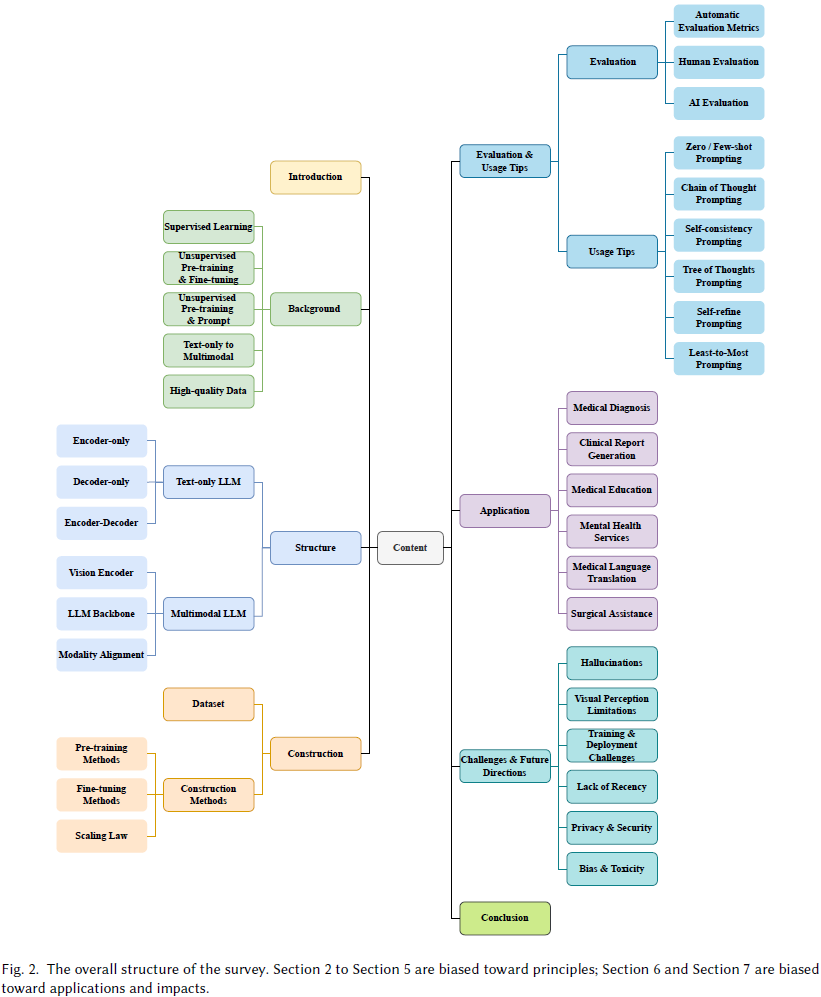
21. A Timely Survey on Vision Transformer for Deepfake Detection
近年来,随着深度伪造技术的快速发展,内容创作发生了革命性的变化,降低了伪造成本的同时提升了质量。然而,这一进展也带来了个人权利侵犯、国家安全威胁和公共安全风险等紧迫问题。为了应对这些挑战,各种检测方法应运而生,其中基于视觉 Transformer(ViT)的方法在通用性和效率方面表现出色。
本综述概述了基于 ViT 的深度伪造检测模型,分为独立、顺序和并行(standalone, sequential, and parallel)架构。
此外,综述简明地描绘了每种模型的结构和特征。
通过分析现有研究并探讨未来方向,本综述旨在为研究人员提供对 ViT 在深度伪造检测中关键作用的深入理解,作为该领域学术和实际应用的宝贵参考。

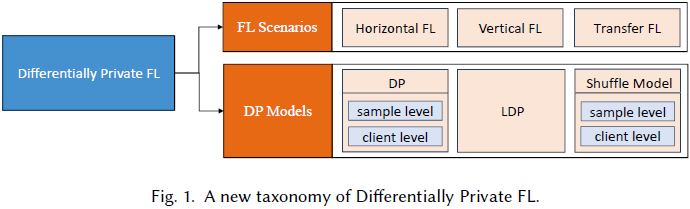
22. Differentially Private Federated Learning: A Systematic Review
近年来,机器学习中的隐私和安全问题推动了可信联邦学习(federated learning)成为研究的前沿。差分隐私(Differential privacy)由于其严谨的数学基础和可证明的保障,已成为联邦学习中隐私保护的事实标准。
我们的工作提供了一个差分隐私联邦学习的系统概述。
- 现有分类法未能充分考虑差分隐私在联邦学习中提供的对象和隐私保护级别。为了弥补这一差距,我们基于差分隐私的定义和保障以及联邦场景,提出了一种新的差分隐私联邦学习分类法(taxonomy of differentially private federated learning)。
- 我们的分类方法清晰地划分了不同差分隐私模型中受保护的对象及其在联邦学习环境中的相应邻域级别。
- 此外,我们还探讨了差分隐私在联邦学习场景中的应用。
23. Bird’s-Eye View to Street-View: A Survey
近年来,街景图像已成为地理空间数据收集和城市分析中最重要的来源之一,这有助于生成有意义的见解并辅助决策。由于外观和视点在两个领域之间存在显著差异,从相应的卫星图像合成街景图像是一项具有挑战性的任务。
在本研究中,我们筛选了 20 篇最近的研究论文,全面回顾了如何从相应的卫星图像合成街景图像的最新进展。主要发现如下:
- 需要新的深度学习技术来合成更真实和准确的街景图像;
- 需要收集更多的公共使用数据集;
- 需要研究更多特定的评价指标来适当评估生成的图像。
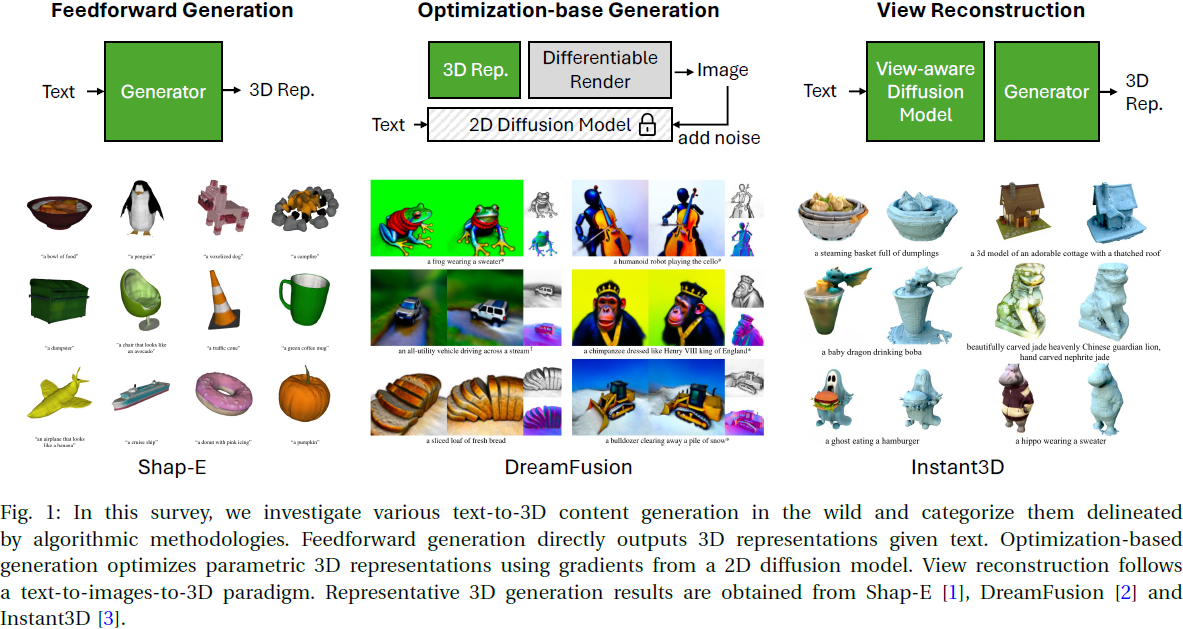
24. A Survey On Text-to-3D Contents Generation In The Wild
3D 内容创建在游戏、机器人模拟和虚拟现实等各种应用中起着至关重要的作用。然而,这一过程劳动强度大且耗时,需要熟练的设计师投入大量精力来创建单个 3D 资产(asset)。为了解决这一挑战,文本到 3D 生成技术作为一种有前途的解决方案应运而生,用于自动化 3D 创建。
利用大型视觉语言模型的成功,这些技术旨在根据文本描述生成 3D 内容。尽管该领域最近取得了进展,现有解决方案在生成质量和效率方面仍面临重大限制。
在本调查中,我们对最新的文本到 3D 创建方法进行了深入研究。
- 我们提供了关于文本到 3D 创建的全面背景,包括对训练中使用的数据集和用于评估生成 3D 模型质量的评价指标的讨论。
- 然后,我们深入探讨了作为 3D 生成过程基础的各种 3D 表示方法。此外,我们对快速增长的生成流程文献进行了全面比较,将其分类为前馈生成器、基于优化的生成和视图重建方法。通过审查这些方法的优缺点,我们旨在阐明它们各自的能力和限制。
- 最后,我们指出了几个未来研究的有前途方向。
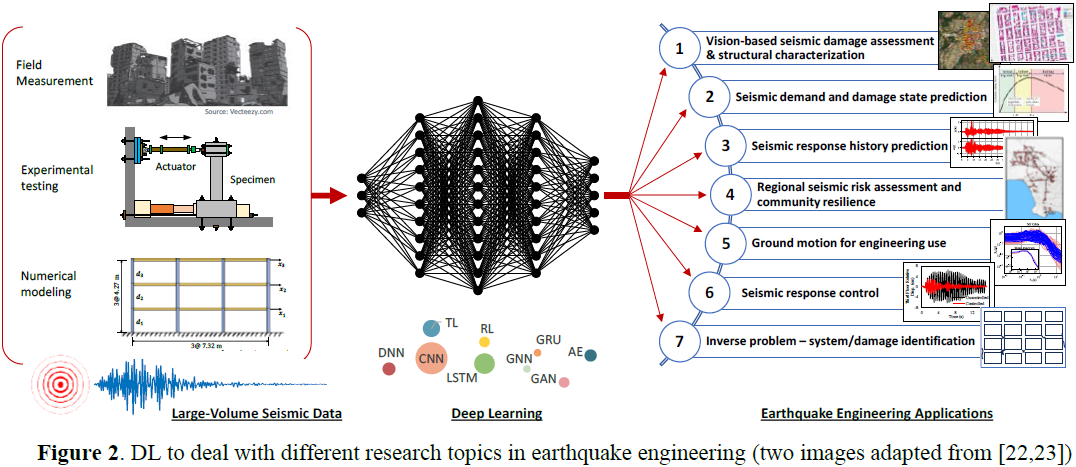
25. Deep Learning in Earthquake Engineering: A Comprehensive Review
本文综述了利用深度学习(DL)作为强大工具来解决地震(earthquake)工程中挑战性问题的日益增长的兴趣。尽管在领域知识方面已经有数十年的进步,但诸如地震发生的不确定性、不可预测的地震荷载、非线性结构响应和社区参与等问题仍难以通过特定领域的方法解决。
深度学习通过其数据驱动的非线性映射、序列数据建模、自动特征提取、降维、最优决策等能力,提供了有前途的解决方案。然而,文献中缺乏系统覆盖深度学习与地震工程交叉领域的一致性综述。
为了填补这一空白,
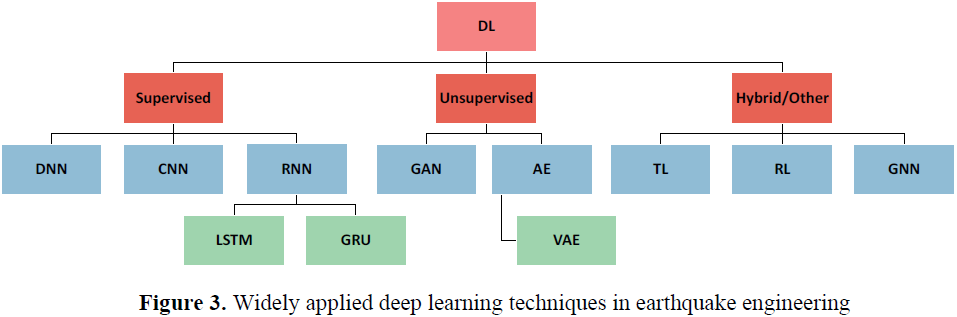
- 本文首先讨论了各种适用的深度学习技术,如多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)、自编码器(AE)、迁移学习(TL)、强化学习(RL)和图神经网络(GNN)的方法进展。
- 接下来,通过探索不同研究主题中的各种深度学习应用,揭示了全面的研究现状,包括基于视觉的地震(seismic)损伤评估和结构表征、地震需求和损伤状态预测、地震响应历史预测、区域地震风险评估和社区韧性、工程使用的地动(ground motion,GM)、地震响应控制以及系统/损伤识别的逆问题。
- 为每个研究主题确定了合适的深度学习技术,强调了 CNN 在基于视觉的任务中的优越性、RNN 在序列数据中的应用、RL 在社区韧性中的作用,以及无监督学习在地震动分析中的应用。
- 本文还讨论了在地震工程研究和实践中利用深度学习的机遇和挑战,强调了开放获取多模态大数据的需求以及提高模型可解释性和将物理信息纳入深度学习的努力。
26. Unveiling Hallucination in Text, Image, Video, and Audio Foundation Models: A Comprehensive Review
基础模型(foundation models,FM)在语言、图像、音频和视频领域的快速进展展示了在各种任务中的显著能力。
然而,基础模型的广泛应用带来了一个关键挑战:生成幻觉(Hallucination)输出的潜在风险,尤其是在高风险应用中。基础模型生成幻觉内容的倾向可以说是其在实际场景中广泛采用的最大障碍,特别是在可靠性和准确性至关重要的领域。
本文综述了最近在识别和缓解基础模型幻觉问题方面的进展,涵盖了文本、图像、视频和音频模态。本文建立了一个清晰的框架,包括定义、分类法和应对多模态基础模型幻觉的检测策略,为这一重要领域的未来研究奠定基础。
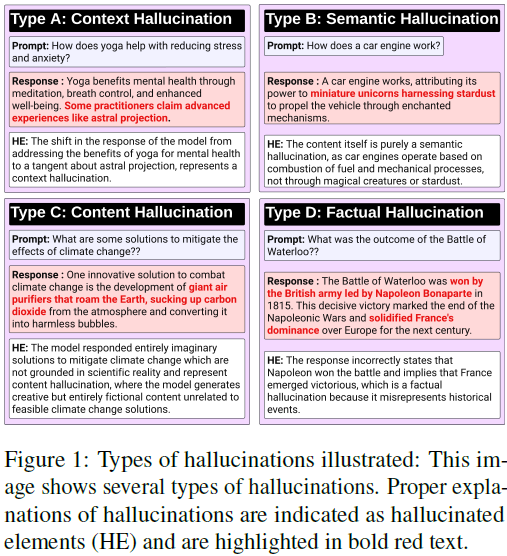
大型基础模型中的幻觉现象可以以多种形式出现,每种形式都带来了独特的挑战,并需要量身定制的缓解策略。这些幻觉类型可以分类如下:
-
上下文脱节:模型在不同模态下生成的输出或内容与用户提供或期望的上下文不一致或不同步。
-
语义扭曲:生成内容中出现的一种不一致或错误,其中输入的语义或基本含义在输出中被误传或改变。
-
内容幻觉:生成的输出特征或元素在给定上下文中不真实或在输入数据中不存在。
-
事实不准确:在生成的输出中出现不准确、欺骗性或与已知事实不符的信息。
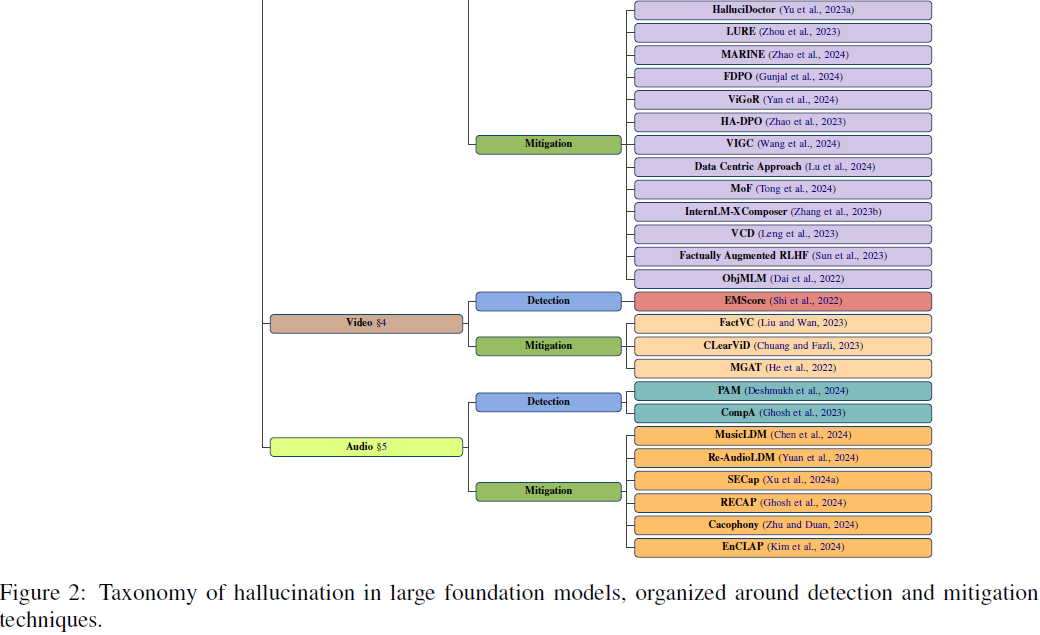
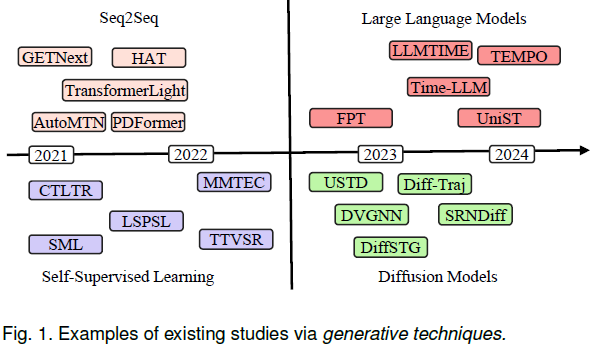
27. A Survey of Generative Techniques for Spatial-Temporal Data Mining
考虑到时空数据的显著增长和多样性,本文聚焦于生成技术在时空数据挖掘中的整合。随着RNN、CNN 及其他非生成技术的发展,研究人员探索了它们在捕捉时空数据中的时间和空间依赖性方面的应用。然而,生成技术的兴起,例如 LLM、SSL(Self-Supervised Learning)、Seq2Seq 和扩散模型,为进一步增强时空数据挖掘开辟了新的可能性。
本文对基于生成技术的时空方法进行了全面分析,并介绍了专门为时空数据挖掘流程设计的标准化框架。
- 通过提供详细的回顾和利用生成技术的时空方法的新分类法,本文使人们对该领域使用的各种技术有了更深入的理解。
- 本文还突出了有前景的未来研究方向,呼吁研究人员深入研究时空数据挖掘。它强调需要探索未开发的机会,推动知识边界,以解锁新的见解并提高时空数据挖掘的有效性和效率。


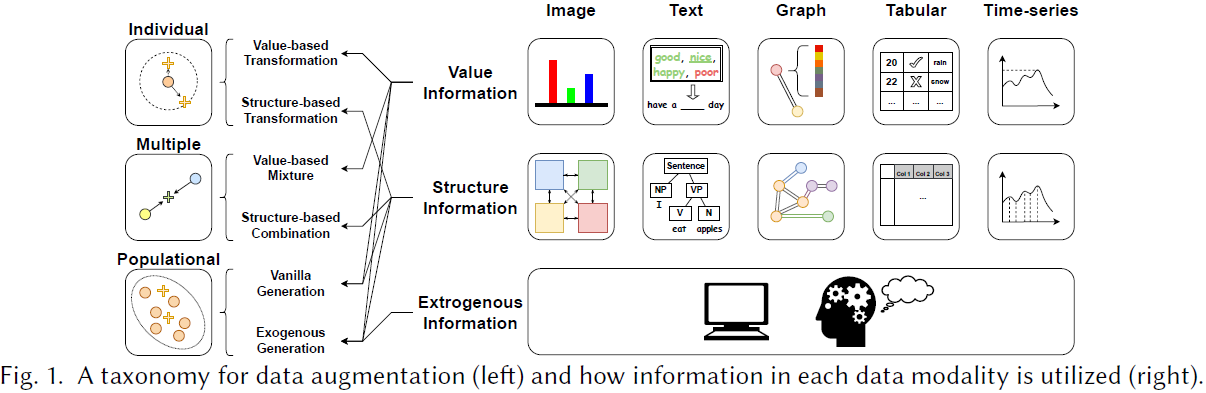
28. A Comprehensive Survey on Data Augmentation
数据增强是一系列通过操纵现有数据样本生成高质量人工数据的技术。通过利用数据增强技术,人工智能模型在处理稀缺或不平衡数据集的任务中可以显著提高适用性,从而大大增强模型的泛化能力。
现有的文献综述仅关注某一特定模态数据的特定类型,并从模态特定和操作中心的角度对这些方法进行分类,缺乏对多种模态数据增强方法的一致总结,限制了对现有数据样本如何服务于数据增强过程的理解。
为弥补这一差距,我们提出了一种更具启发性的分类法,涵盖了不同常见数据模态的数据增强技术。
- 具体而言,从数据中心的角度来看,本综述通过研究如何利用数据样本之间的内在关系,提出了一种模态无关的分类法,包括单样本、双样本和群体样本数据增强方法。
- 此外,我们通过统一的归纳方法对五种数据模态的数据增强方法进行了分类。
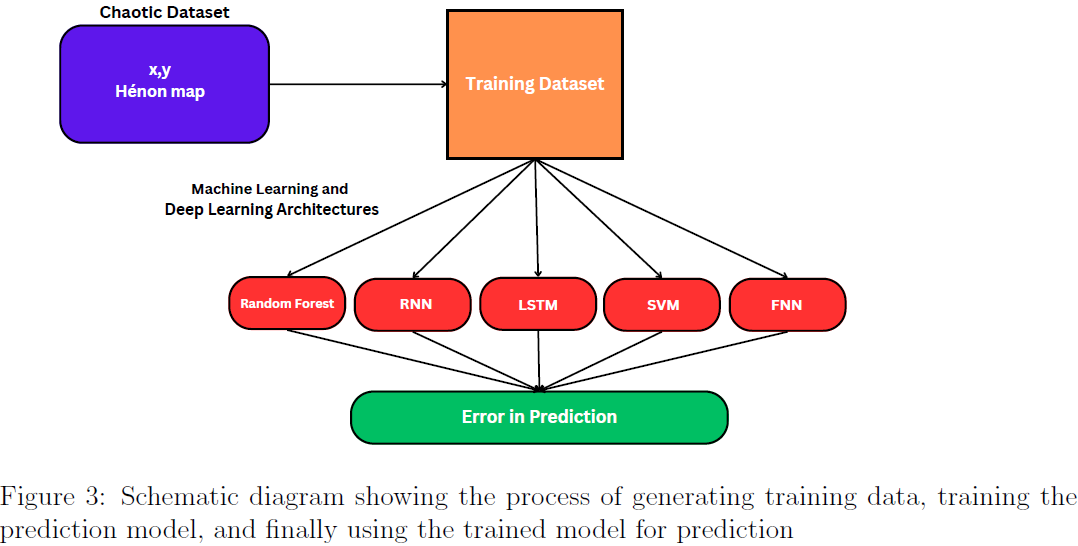
29. Comparative Analysis of Predicting Subsequent Steps in H´enon Map
本文探讨了使用各种机器学习技术预测 Hénon 映射后续步骤的可能性。Hénon 映射因其混沌行为(chaotic behaviour)而闻名,并在密码学、图像加密和模式识别等多个领域中有广泛应用。
机器学习方法,尤其是深度学习,正日益成为理解和预测混沌现象的关键。
本研究评估了不同机器学习模型在预测 Hénon 映射演化方面的性能,包括随机森林(Random Forest)、循环神经网络(RNN)、长短期记忆网络(LSTM)、支持向量机(SVM)和前馈神经网络(FNN)。结果表明,
- LSTM 网络在预测准确性方面表现优越,尤其是在极端事件预测方面。
- LSTM 与 FNN 模型的比较显示,LSTM 在较长预测周期和较大数据集情况下具有优势。
30. When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
随着大型语言模型(LLM)的发展,它们与 3D 空间数据的集成(3D-LLM)进展迅速,提供了前所未有的理解和交互物理空间的能力。
本综述全面概述了使 LLM 能够处理、理解和生成 3D 数据的方法。
- 我们强调了 LLM 的独特优势,如上下文学习、逐步推理、开放词汇能力和广泛的世界知识,突显了它们在体感人工智能(AI)系统中显著提升空间理解和交互能力的潜力。
- 我们的研究涵盖了从点云到神经辐射场(NeRF)等各种 3D 数据表示形式,探讨了它们与 LLM 在 3D 场景理解、描述、问答和对话等任务中的集成,以及基于 LLM 的空间推理、规划和导航代理。
- 本文还简要回顾了其他集成 3D 和语言的方法。
本文呈现的元分析显示了显著的进展,但也强调了需要新的方法来充分利用 3D-LLM 的潜力。因此,通过本文,我们旨在为未来研究制定路线,探索和扩展 3D-LLM 在理解和交互复杂 3D 世界中的能力。


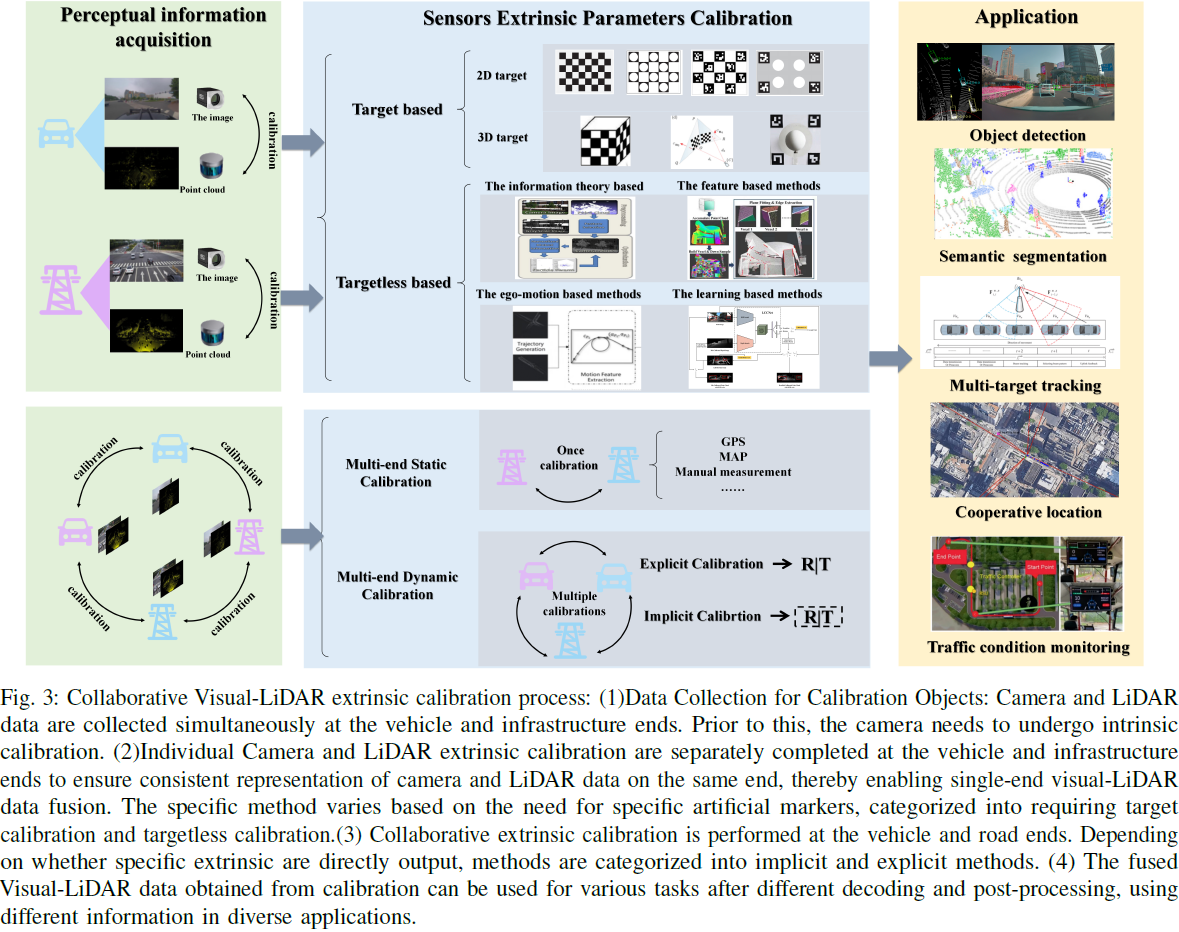
31. Cooperative Visual-LiDAR Extrinsic Calibration Technology for Intersection Vehicle-Infrastructure: A review
在典型的城市交叉路口场景中,车辆和基础设施均配备了视觉和 LiDAR 传感器。通过成功整合来自车载和道路监控设备的数据,可以实现更全面和准确的环境感知和信息获取。
作为自动驾驶技术的重要组成部分,传感器校准始终受到高度关注。尤其是在涉及多传感器协同感知和定位挑战的场景中,传感器间校准的需求变得至关重要。
近年来,多端协作的概念逐渐兴起,其中基础设施捕捉并传输周围环境信息给车辆,增强其感知能力的同时降低成本。然而,这也带来了技术复杂性,突显了多端校准的迫切需求。摄像头和 LiDAR 作为自动驾驶的基础传感器,具有广泛的适用性。
本文全面审视并分析了从车辆、路侧和车路协作角度出发的多端摄像头-LiDAR 校准,概述了其相关应用和深远意义。最后,我们总结了研究内容并提出了面向未来的构想和假设。
32. A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
最近的研究努力评估了大型语言模型(LLM)在常识推理、数学推理和代码生成等领域的表现。然而,据我们所知,尚未有工作专门调查 LLM 在自然语言生成(natural language generation,NLG)任务中的表现,这是确定模型优劣的关键标准。
因此,本文在 NLG 任务的背景下对知名且高性能的 LLM 进行了全面评估,包括 ChatGPT、ChatGLM、基于 T5 的模型、基于 LLaMA 的模型和基于 Pythia 的模型。
- 我们选择了涵盖对话生成和文本摘要的英文和中文数据集。
- 此外,我们提出了一个通用的评估设置,包括输入模板和后处理策略。
- 我们的研究报告了自动结果,并附有详细分析。

















 5650
5650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









