







文章目录
Faster R-CNN(2016)
文章书写匆忙,有些使用了网上其他朋友的文字以及图片,但是没有及时复制对应的链接,在此深表歉意,以及深深的感谢。
如有朋友看到了对应的出处,或者作者发现,可以留言,小弟马上修改,添加引用。
论文翻译: http://noahsnail.com/2018/01/03/2018-01-03-Faster R-CNN论文翻译——中英文对照/
论文arxiv: https://arxiv.org/abs/1506.01497
论文解析:
- https://senitco.github.io/2017/09/02/faster-rcnn/
- https://www.cnblogs.com/guoyaohua/p/9488119.html
- https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
luminoth代码注释: https://github.com/lartpang/luminoth/tree/master/luminoth/models/fasterrcnn
网络结构
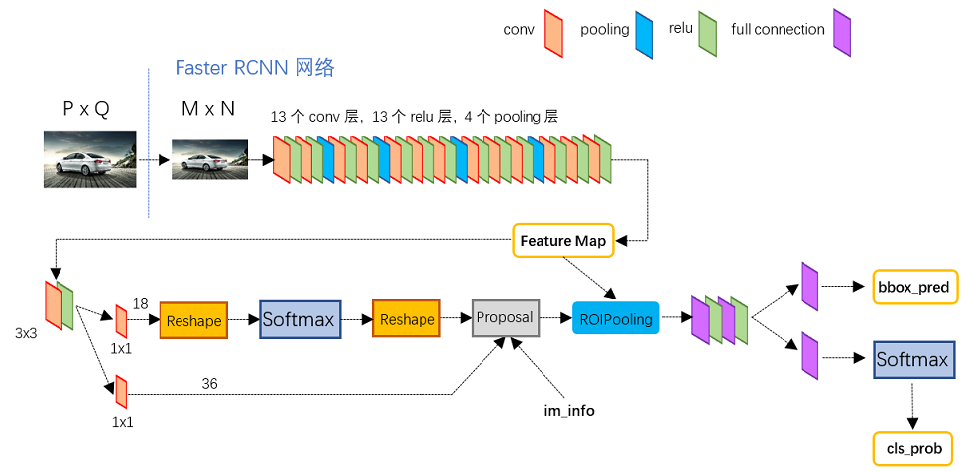
图为Faster R-CNN测试网络结构(网络模型文件为faster_rcnn_test.pt),可以清楚地看到图像在网络中的前向计算过程。
- 对于一幅任意大小P×Q的图像,首先缩放至固定大小M×N(源码中是要求长边不超过1000,短边不超过600)
- 然后将缩放后的图像输入至采用VGG16模型的Conv Layer中,最后一个feature map为conv5-3,特征数(channels)为512
- RPN网络在特征图conv5-3上执行3×3卷积操作, 对于每个滑窗位置都映射一个低维度的特征(如256-d)
- 后接两路1x1卷积,分别用于anchors的分类和回归,再通过计算筛选得到proposals
- RoIs Pooling层则利用Proposal从feature maps中提取Proposal feature进行池化操作,送入后续的Fast R-CNN网络做分类和回归
RPN网络和Fast R-CNN网络中均有分类和回归,但两者有所不同.
RPN中分类是判断conv5-3中对应的anchors属于目标和背景的概率(score),并通过回归获取anchors的偏移和缩放尺度,根据目标得分值筛选用于后续检测识别的Proposal.
Fast R-CNN是对RPN网络提取的Proposal做分类识别,并通过回归参数调整得到目标(Object)的精确位置。
新架构主要解决的问题?
对于Fast R-CNN,其仍然需要selective search方法来生产候选区域,这是非常费时的。
为了解决这个问题,Faster R-CNN模型(The Faster Region-based Convolutional Network, S. Ren and al. 2016)引入了RPN (Region Proposal Network)直接产生候选区域。
Faster R-CNN可以看成是RPN和Fast R-CNN模型的组合体,即Faster R-CNN = RPN + Fast R-CNN。
RPN的细节?
RPN旨在有效预测具有广泛尺度和长宽比的区域提议。与使用图像金字塔(图1,a)或滤波器金字塔(图1,b)的流行方法[8],[9],[1]相比,我们引入新的“锚”盒作为多种尺度和长宽比的参考。我们的方案可以被认为是回归参考金字塔(图1,c),它避免了枚举多种比例或长宽比的图像或滤波器。这个模型在使用单尺度图像进行训练和测试时运行良好,从而有利于运行速度。

解决多尺度和尺寸的不同方案。(a)构建图像和特征映射金字塔,分类器以各种尺度运行。(b)在特征映射上运行具有多个比例/大小的滤波器的金字塔。(c)我们在回归函数中使用参考边界框金字塔。
传统的目标检测方法中生成候选框都比较耗时,例如使用滑动窗口加图像金字塔的方式遍历图像,获取多尺度的候选区域;以及R-CNN、Fast R-CNN中均使用到的Selective Search的方法生成候选框。
而Faster R-CNN则直接使用RPN网络,将检测框Proposal的提取嵌入到网络内部,通过共享卷积层参数的方式提升了Proposal的生成速度。
RPN的作用就是代替了Fast RCNN的Selective search,但是速度更快.
因此Faster R-CNN无论是训练还是预测都可以加速。
RPN的处理流程
-
对于RPN网络,先采用一个CNN模型(一般称为特征提取器)接收整张图片并提取特征图
-
然后在这个特征图上采用一个N*N(文中是3*3)的滑动窗口,对于每个滑窗位置都映射一个低维度的特征(如256-d)
-
然后这个特征分别送入两个全连接层,一个用于分类预测,另外一个用于回归, 继而计算得到特征图conv5-3映射到输入图像的所有anchors,并通过RPN网络前向计算得到anchors的score输出和bbox回归参数
prediction_dict = {} # Get the RPN feature using a simple conv net. Activation function # can be set to empty. # 得到第一个3x3卷积的结果, 后加了个ReLU激活函数 rpn_conv_feature = self._rpn(conv_feature_map) rpn_feature = self._rpn_activation(rpn_conv_feature) # Then we apply separate conv layers for classification and regression. # 获得类别得分和边界框预测, 这里各自只是经过了一次1x1的卷积, 就直接得到结果. rpn_cls_score_original = self._rpn_cls(rpn_feature) rpn_bbox_pred_original = self._rpn_bbox(rpn_feature) # rpn_cls_score_original has shape (1, H, W, num_anchors * 2) # rpn_bbox_pred_original has shape (1, H, W, num_anchors * 4) # where H, W are height and width of the pretrained feature map. # 因为使用的是3x3 padding=1 以及 1x1的卷积, 所以宽高不变, 而且这里也不能变, # 因为还要与原始的特征图所对应 # Convert (flatten) `rpn_cls_score_original` which has two scalars per # anchor per location to be able to apply softmax. # 这里的操作是实现了一个flatten的操作, 但是对于每个anchor都有对应的两个值 # 也就是前景和背景的概率(目标/非目标) rpn_cls_score = tf.reshape(rpn_cls_score_original, [-1, 2]) # Now that `rpn_cls_score` has shape (H * W * num_anchors, 2), we apply # softmax to the last dim. # 对每个anchors应用一个softmax分类器得到类别预测 rpn_cls_prob = tf.nn.softmax(rpn_cls_score) # 数据存档 prediction_dict['rpn_cls_prob'] = rpn_cls_prob prediction_dict['rpn_cls_score'] = rpn_cls_score # 与上面类似的操作, 进行了把各个anchor全部展开 # Flatten bounding box delta prediction for easy manipulation. # We end up with `rpn_bbox_pred` having shape (H * W * num_anchors, 4). rpn_bbox_pred = tf.reshape(rpn_bbox_pred_original, [-1, 4]) # 数据存档 prediction_dict['rpn_bbox_pred'] = rpn_bbox_pred -
由anchors坐标和bbox回归参数计算得到预测框proposal的坐标
-
处理proposal坐标超出图像边界的情况(使得坐标最小值为0,最大值为宽或高)
-
滤除掉尺寸(宽高)小于给定阈值的proposal
-
对剩下的proposal按照目标得分(fg score)从大到小排序,提取前pre_nms_topN(e.g. 6000)个proposal
-
对提取的proposal进行非极大值抑制(non-maximum suppression,nms),再根据nms后的foreground score,筛选前post_nms_topN(e.g. 300)个proposal作为RPN最后的输出
# We have to convert bbox deltas to usable bounding boxes and remove # redundant ones using Non Maximum Suppression (NMS). # 将bbox增量转换为可用的边界框并使用NMS删除冗余 # 这些操作都在self._proposal中实现了, 输出来的就是调整处理后的山下来的结果 proposal_prediction = self._proposal( rpn_cls_prob, rpn_bbox_pred, all_anchors, im_shape) # 数据存档 prediction_dict['proposals'] = proposal_prediction['proposals'] prediction_dict['scores'] = proposal_prediction['scores']
RPN的结构
对于每个窗口位置一般设置k个不同大小或比例的先验框(anchors, default bounding boxes),这意味着每个位置预测 k k k个候选区域(region proposals)
# 3x3的卷基层
self._rpn = Conv2D(
output_channels=self._num_channels,
kernel_shape=self._kernel_shape,
initializers={'w': self._rpn_initializer},
regularizers={'w': self._regularizer},
name='conv'
)
...
rpn_conv_feature = self._rpn(conv_feature_map)
rpn_feature = self._rpn_activation(rpn_conv_feature)
对于分类层,其输出大小是2k,我们对每个锚点输出两个预测值:它是背景(不是目标)的分数,和它是前景(实际的目标)的分数。
# 分类分支, 输出的通道数目是 2k(k即为anchors数目)
self._rpn_cls = Conv2D(
output_channels=self._num_anchors * 2, kernel_shape=[1, 1],
initializers={'w': self._cls_initializer},
regularizers={'w': self._regularizer},
padding='VALID',
name='cls_conv'
)
而回归层输出4k个坐标值,对于回归或边框调整层,我们输出四个预测值:Δxcenter、Δycenter、Δwidth、Δheight,我们将会把这些值用到锚点中来得到最终的建议。
# BBox prediction is 4 values * number of anchors.
# 预测分支, 输出通道数目为 4k
self._rpn_bbox = Conv2D(
output_channels=self._num_anchors * 4, kernel_shape=[1, 1],
initializers={'w': self._bbox_initializer},
regularizers={'w': self._regularizer},
padding='VALID',
name='bbox_conv'
)
RPN 是用完全卷积的方式高效实现的,用基础网络返回的卷积特征图作为输入。首先,我们使用一个有 512 个通道和 3x3 卷积核大小的卷积层,然后我们有两个使用 1x1 卷积核的并行卷积层,其通道数量取决于每个点的锚点数量。


RPN架构图
对于原论文中采用的ZF模型,conv5的特征数为256,全连接层的维数也为256; 对于VGG模型,conv5-3的特征数为512,全连接的的维数则为512,相当于feature map上的每一个点都输出一个512维的特征向量。
RPN的anchor
我们的目标是寻找图片中的边框。这些边框是不同尺寸、不同比例的矩形。设想我们在解决问题前已知图片中有两个目标。那么首先想到的应该是训练一个网络,这个网络可以返回 8 个值:包含(xmin, ymin, xmax, ymax)的两个元组,每个元组都用于定义一个目标的边框坐标。
这个方法有着根本问题,例如,图片可能是不同尺寸和比例的,因此训练一个可以直接准确预测原始坐标的模型是很复杂的。
另一个问题是无效预测:当预测(xmin,xmax)和(ymin,ymax)时,应该强制设定 xmin 要小于 xmax,ymin 要小于 ymax。
另一种更加简单的方法是去预测参考边框的偏移量。
使用参考边框(xcenter, ycenter, width, height),学习预测偏移量(Δxcenter,Δycenter,Δwidth,Δheight),因此我们只得到一些小数值的预测结果并挪动参考变量就可以达到更好的拟合结果。
锚点是用固定的边框置于不同尺寸和比例的图片上,并且在之后目标位置的预测中用作参考边框。
我们在处理的卷积特征图的尺寸分别是 conv_width×conv_height×conv_depth,因此在卷积图的 conv_width×conv_height 上每一个点都生成一组锚点。很重要的一点是即使我们是在特征图上生成的锚点,这些锚点最终是要映射回原始图片的尺寸。
因为我们只用到了卷积和池化层,所以特征图的最终维度与原始图片是呈比例的。
数学上,如果图片的尺寸是 w×h,那么特征图最终会缩小到尺寸为 w/r 和 h/r,其中 r 是次级采样率。如果我们在特征图上每个空间位置上都定义一个锚点,那么最终图片的锚点会相隔 r 个像素,在 VGG 中,r=16。
RPN 接受所有的参考框(锚点)并为目标输出一套好的建议。它通过为每个锚点提供两个不同的输出来完成。
第一个输出是锚点作为目标的概率。如果你愿意,可以叫做「目标性得分」。注意,RPN 不关心目标的类别,只在意它实际上是不是一个目标(而不是背景)。我们将用这个目标性得分来过滤掉不好的预测,为第二阶段做准备。
第二个输出是边框回归,用于调整锚点以更好的拟合其预测的目标。
Anchor是RPN网络中一个较为重要的概念,传统的检测方法中为了能够得到多尺度的检测框,需要通过建立图像金字塔的方式,对图像或者滤波器(滑动窗口)进行多尺度采样。
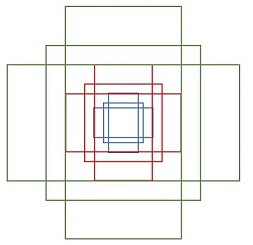
RPN网络则是使用一个 3 × 3 3 \times 3 3×3的卷积核,在最后一个特征图(conv5-3)上滑动,将卷积核中心对应位置映射回输入图像,生成3种尺度(scale) { 12 8 2 , 25 6 2 , 51 2 2 } \lbrace 128^2,256^2,512^2 \rbrace {1282,2562,5122}和3种长宽比(aspect ratio) { 1 : 1 , 1 : 2 , 2 : 1 } \lbrace 1:1, 1:2, 2:1 \rbrace {1:1,1:2,2:1}共9种Anchor,如下图所示。

左侧:锚点
中心:特征图空间单一锚点在原图中的表达
右侧:所有锚点在原图中的表达
这里的anchor实际是映射到原始输入图像上的框, 而不是特征图上的框, 对于原始数据的映射, 在确定anchor的时候, 就已经完成了.
特征图conv5-3每个位置都对应9个anchors,如果feature map的大小为 W × H W \times H W×H,则一共有 W × H × 9 W \times H \times 9 W×H×9个anchors,滑动窗口的方式保证能够关联conv5-3的全部特征空间,最后在原图上得到多尺度多长宽比的anchors。
这里的3x3滑动, 其步长是1, 这样才能确保关联所有的特征值.
RPN之后的处理
RoI Pooling
结合特征图conv5-3和proposal的信息.
-
proposal在输入图像中的坐标 [ x 1 , y 1 , x 2 , y 2 ] [x1, y1, x2, y2] [x1,y1,x2,y2]对应 M × N M \times N M×N尺度,将proposal的坐标映射到 M 16 × N 16 \dfrac{M}{16} \times \dfrac{N}{16} 16M×16N大小的conv5-3中
这里需要取整, 可以看SPP-Net中.
-
然后将Proposal在conv5-3的对应区域水平和竖直均分为7等份
-
并对每一份进行Max Pooling或Average Pooling处理,得到固定大小( 7 × 7 7 \times 7 7×7)输出的池化结果,实现固定长度输出(fixed-length output)
-
大致流程如下图所示。
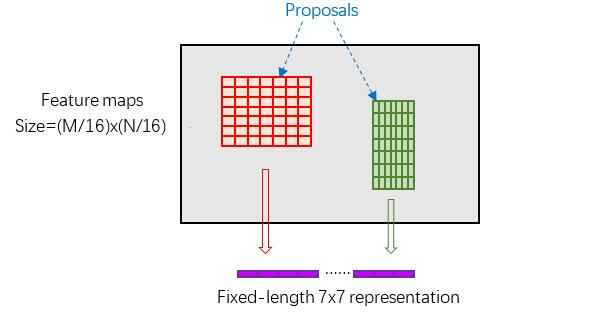
一种更简单的方法(被包括 Luminoth 版本的 Faster R-CNN 在内的目标检测实现方法所广泛使用),是用每个建议来裁剪卷积特征图,然后用插值(通常是双线性的)将每个裁剪调整为固定大小(14×14×convdepth)。裁剪之后,用 2x2 核大小的最大池化来获得每个建议最终的 7×7×convdepth 特征图。
Classification and Regression
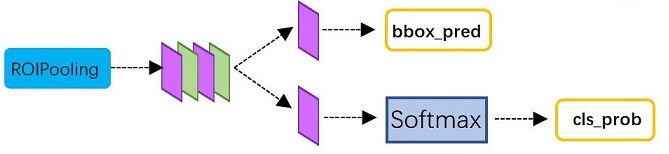
RoI Pooling层后接多个全连接层,最后为两个子连接层——分类层(cls)和回归层(reg)
Faster R-CNN 工作流的最后一步便是最后的分类回归操作。
从图像上获得卷积特征图之后,用它通过 RPN 来获得目标建议并最终为每个建议提取特征(通过 RoI Pooling),最后我们需要使用这些特征进行分类。
这个阶段有两个不同的目标:
- 将建议分到一个类中,加上一个背景类(用于删除不好的建议)
- 根据预测的类别更好地调整建议的边框
在最初的 Faster R-CNN 论文中,R-CNN 对每个建议采用特征图,将它平坦化并使用两个大小为 4096 的有 ReLU 激活函数的全连接层。
然后,它对每个不同的目标使用两种不同的全连接层:
- 一个有 N+1 个单元的全连接层,其中 N 是类的总数,另外一个是背景类。
- 一个有 4N 个单元的全连接层。我们希望有一个回归预测,因此对 N 个类别中的每一个可能的类别,我们都需要 Δcenterx、Δcentery、Δwidth、Δheight。
(训练)新架构如何训练
对于提取proposals的RPN,以及分类回归的Fast R-CNN,如何将这两个网络嵌入到同一个网络结构中,训练一个共享卷积层参数的多任务(Multi-task)网络模型?
源码中有实现**交替训练(Alternating training)和端到端训练(end-to-end)**两种方式,这里介绍交替训练的方法。
Faster R-CNN模型采用一种4步迭代的训练策略:
- 首先在ImageNet上预训练RPN,并在PASCAL VOC数据集上finetuning, 得到模型M1;
- 使用训练的RPN模型M1产生Proposal P1单独训练一个ImageNet上预训练过的Fast R-CNN模型, 进而得到模型M2;
- 用Fast R-CNN模型M2初始化RPN,且固定卷积层参数, 然后对RPN中独有的层进行finetuning(此时Fast R-CNN与RPN的特征提取器是共享的), 进而得到模型M3;
- 利用上一步训练的RPN网络模型M3,生成Proposal P2. 训练Fast R-CNN网络,用RPN网络模型M3初始化,且卷积层参数和RPN参数不变,只微调Fast R-CNN独有的网络层,得到最终模型M4
这样经过多次迭代,Fast R-CNN可以与RPN有机融合在一起,形成一个统一的网络。
总体上看,训练过程只循环了2次,但每一步训练(M1,M2,M3,M4)都迭代了多次(e.g. 80k,60k)。对于固定卷积层参数,只需将学习率(learning rate)设置为0即可。
近似联合训练策略
将RPN的2个loss和Fast R-CNN的2个loss结合在一起,然后共同训练。
注意这个过程,Fast R-CNN的loss不对RPN产生的region proposals反向传播,忽略了关于提议边界框的坐标(也是网络响应)的导数,因此是近似的(如果考虑这个反向传播,那就是非近似联合训练)。应该说,联合训练速度更快,并且可以训练出同样的性能。
在每次SGD迭代中,前向传递生成区域提议,在训练Fast R-CNN检测器将这看作是固定的、预计算的提议。反向传播像往常一样进行,其中对于共享层,组合来自RPN损失和Fast R-CNN损失的反向传播信号。这个解决方案很容易实现。
在我们的实验中,我们实验发现这个求解器产生了相当的结果,与交替训练相比,训练时间减少了大约 25 − 50 % 25-50\% 25−50%。
非近似的联合训练
如上所述,由RPN预测的边界框也是输入的函数。Fast R-CNN中的RoI池化层[2]接受卷积特征以及预测的边界框作为输入,所以理论上有效的反向传播求解器也应该包括关于边界框坐标的梯度。
在上述近似联合训练中,这些梯度被忽略。在一个非近似的联合训练解决方案中,我们需要一个关于边界框坐标可微分的RoI池化层。这是一个重要的问题,可以通过[15]中提出的“RoI扭曲”层给出解决方案,这超出了本文的范围。
我们在 RPN 和 Fast R-CNN 中有可训练的层,我们也有可以训练(微调)或不能训练的基础网络。
用加权和将四种不同的损失组合起来。这是因为相对于回归损失,我们可能希望给分类损失更大的权重,或者相比于 RPN 可能给 Fast R-CNN 损失更大的权重。
除了常规的损失之外,我们也有正则化损失,为了简洁起见,我们可以跳过这部分,但是它们在 RPN 和 Fast R-CNN 中都可以定义。我们用 L2 正则化一些层。根据正在使用哪个基础网络,以及如果它经过训练,也有可能进行正则化。
RPN的训练
训练样本
一般而言,特征图conv5-3的实际尺寸大致为 60 × 40 60 \times 40 60×40,那么一共可以生成 60 × 40 × 9 ≈ 20 k 60 \times 40 \times 9 \approx 20k 60×40×9≈20k个anchors,显然不会将所有anchors用于训练,而是筛选一定数量的正负样本。
可以看到RPN采用的是二分类,仅区分背景与物体,但是不预测物体的类别,即class-agnostic。
对于数据集中包含有人工标定ground truth的图像,考虑一张图像上所有anchors:
-
首先过滤掉超出图像边界的anchors
-
由于要同时预测坐标值,在训练时,要先将先验框(即anchor)与ground-truth box进行匹配.
- 对每个标定的ground truth,与其重叠比例IoU最大的anchor记为正样本,这样可以保证每个ground truth至少对应一个正样本anchor
- 对每个anchors,如果其与某个ground truth的重叠比例IoU大于0.7,则记为正样本(目标);如果小于0.3,则记为负样本(背景)
- 正样本anchors就这样匹配了一个ground-truth,并以这个ground-truth为回归目标。
-
再从已经得到的正负样本中随机选取256个anchors组成一个minibatch用于训练,而且正负样本的比例为1:1, 如果正样本不够,则补充一些负样本以满足256个anchors用于训练,反之亦然。(维持前景锚点和背景锚点之间的平衡比例)
对应于luminoth代码的rpn_target的实现
每个小批量数据都从包含许多正面和负面示例锚点的单张图像中产生。对所有锚点的损失函数进行优化是可能的,但是这样会偏向于负样本,因为它们是占主导地位的。所以使用上面的方式.
训练损失
由于涉及到分类和回归,所以需要定义一个多任务损失函数(Multi-task Loss Function),包括Softmax Classification Loss和Bounding Box Regression Loss,公式定义如下:
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
Σ
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
Σ
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
L(\lbrace p_i \rbrace, \lbrace t_i \rbrace)=\dfrac{1}{N_{cls}}\Sigma_i L_{cls}(p_i,p_i^{\ast}) + \lambda \dfrac{1}{N_{reg}}\Sigma_i p_i^{\ast} L_{reg}(t_i, t_i^{\ast})
L({pi},{ti})=Ncls1ΣiLcls(pi,pi∗)+λNreg1Σipi∗Lreg(ti,ti∗)
就是分类与回归损失之和. 在上式中, 相关定义如下:
-
p i p_i pi为样本分类的概率值
-
p i ∗ p_i^{\ast} pi∗为样本的标定值(label),anchor为正样本时 p i ∗ p_i^{\ast} pi∗为1,为负样本时 p i ∗ p_i^{\ast} pi∗为0
-
L c l s L_{cls} Lcls为两种类别的对数损失(log loss)
-
L r e g L_{reg} Lreg表示回归损失, 采用Smooth L1函数
-
预测框相对anchor中心位置的偏移量以及宽高的缩放量 { t } \lbrace t \rbrace {t}
-
ground truth相对anchor的偏移量和缩放量 { t ∗ } \lbrace t^{\ast} \rbrace {t∗}
-
分类层(cls)和回归层(reg)的输出分别为 { p } \lbrace p \rbrace {p}和 { t } \lbrace t \rbrace {t}
-
两项损失函数分别由 N c l s N_{cls} Ncls和 N r e g N_{reg} Nreg以及一个平衡权重 λ \lambda λ归一化。
分类损失的归一化值为minibatch的大小,即 N c l s = 256 N_{cls}=256 Ncls=256. 回归损失的归一化值为anchor位置的数量,即 N r e g ≈ 2400 N_{reg} \approx 2400 Nreg≈2400. λ \lambda λ一般取值为10,这样分类损失和回归损失差不多是等权重的。
什么时候anchor算是正样本?
如果proposal的最大IoU大于0.5则为目标(前景),标签值(label)为对应ground truth的目标分类, 标签值为1; 如果IoU小于0.5且大于0.1则为背景,标签值为0
Softmax Classification
对于RPN网络的分类层(cls),其向量维数为2k = 18(conv5-3上每个点前向映射得到 k ( k = 9 ) k(k=9) k(k=9)个anchors).
考虑整个特征图conv5-3,则输出大小为 W × H × 18 W \times H \times 18 W×H×18,正好对应conv5-3上每个点有9个anchors,而每个anchor又有两个score(fg/bg)输出.
对于单个anchor训练样本,其实是一个二分类问题。
Bounding Box Regression
RPN网络的回归层输出向量的维数为4k = 36,回归参数为每个样本的坐标[x,y,w,h],分别为box的中心位置和宽高,考虑三组参数:
- 预测框(predicted box)坐标 [ x , y , w , h ] [x,y,w,h] [x,y,w,h]
- anchor坐标 [ x a , y a , w a , h a ] [x_a,y_a,w_a,h_a] [xa,ya,wa,ha]
- ground truth坐标 [ x ∗ , y ∗ , w ∗ , h ∗ ] [x^{\ast},y^{\ast},w^{\ast},h^{\ast}] [x∗,y∗,w∗,h∗]
分别计算
-
预测框相对anchor中心位置的偏移量以及宽高的缩放量 { t } \lbrace t \rbrace {t}
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a , t w = l o g ( w / w a ) , t h = l o g ( h / h a ) t_x=(x-x_a)/w_a, t_y=(y-y_a)/h_a, t_w=log(w/w_a), t_h=log(h/h_a) tx=(x−xa)/wa, ty=(y−ya)/ha, tw=log(w/wa), th=log(h/ha)
-
ground truth相对anchor的偏移量和缩放量 { t ∗ } \lbrace t^{\ast} \rbrace {t∗}
t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = l o g ( w ∗ / w a ) , t h ∗ = l o g ( h ∗ / h a ) t_x^{\ast}=(x^{\ast}-x_a)/w_a, t_y^{\ast}=(y^{\ast}-y_a)/h_a, t_w^{\ast}=log(w^{\ast}/w_a), t_h^{\ast}=log(h^{\ast}/h_a) tx∗=(x∗−xa)/wa, ty∗=(y∗−ya)/ha, tw∗=log(w∗/wa), th∗=log(h∗/ha)
回归目标就是让 { t } \lbrace t \rbrace {t}尽可能地接近 { t ∗ } \lbrace t^{\ast} \rbrace {t∗},所以回归真正预测输出的是 { t } \lbrace t \rbrace {t},而训练样本的标定真值为 { t ∗ } \lbrace t^{\ast} \rbrace {t∗}。
得到预测输出 { t } \lbrace t \rbrace {t}后,通过上面第一式即可反推获取预测框的真实坐标( [ x , y , w , h ] [x,y,w,h] [x,y,w,h])。
在损失函数中,回归损失 L r e g = S m o o t h L 1 ( t − t ∗ ) L_{reg}=Smooth_{L1}(t-t^{\ast}) Lreg=SmoothL1(t−t∗), 采用Smooth L1函数
S m o o t h L 1 ( x ) = { 0.5 x 2 ∣ x ∣ ≤ 1 ∣ x ∣ − 0.5 o t h e r w i s e Smooth_{L1}(x)=\begin{cases} 0.5x^2 |x| \leq 1 \\ |x|-0.5 otherwise\end{cases} SmoothL1(x)={0.5x2 ∣x∣≤1∣x∣−0.5 otherwise
Smooth L1损失函数曲线如下图所示,相比于L2损失函数,L1对离群点或异常值不敏感,可控制梯度的量级使训练更易收敛。
在损失函数中, p i ∗ L r e g p_i^{\ast}L_{reg} pi∗Lreg这一项表示只有(正样本)目标anchor( p i ∗ = 1 p_i^{\ast}=1 pi∗=1)才有回归损失,其他anchor不参与计算。
这里需要注意的是,当样本bbox和ground truth比较接近时(IoU大于某一阈值),可以认为上式的坐标变换是一种线性变换,因此可将样本用于训练线性回归模型,否则当bbox与ground truth离得较远时,就是非线性问题,用线性回归建模显然不合理,会导致模型不work。
分类层(cls)和回归层(reg)的输出分别为 { p } \lbrace p \rbrace {p}和 { t } \lbrace t \rbrace {t},两项损失函数分别由 N c l s N_{cls} Ncls和 N r e g N_{reg} Nreg以及一个平衡权重 λ \lambda λ归一化。
RPN网络输出的proposal如何组织成Fast R-CNN的训练样本
RPN网络是可以单独训练的,并且单独训练出来的RPN模型给出很多region proposals。
由于先验框数量庞大,RPN预测的候选区域很多是重叠的:
- 要先进行NMS(non-maximum suppression,IoU阈值设为0.7)操作来减少候选区域的数量
- 然后按照置信度降序排列
- 选择top-N个region proposals来用于训练Fast R-CNN模型
**建议选择:**应用 NMS 后,我们保留评分最高的 N 个建议。论文中使用 N=2000,但是将这个数字降低到 50 仍然可以得到相当好的结果。但在测试时评估不同数量的提议。
-
对每个proposal,计算其与所有ground truth的重叠比例IoU
-
筛选出与每个proposal重叠比例最大的ground truth
-
如果proposal的最大IoU大于0.5则为目标(前景),标签值(label)为对应ground truth的目标分类
如果IoU小于0.5且大于0.1则为背景,标签值为0
-
从2张图像中随机选取128个proposals组成一个minibatch,前景和背景的比例为1:3
-
计算样本proposal与对应ground truth的回归参数作为标定值,并且将回归参数从(4, )拓展为(4(N+1), ),只有对应类的标定值才为非0。
同时兼顾了回归与分类
-
设定训练样本的回归权值,权值同样为4(N+1)维,且只有样本对应标签类的权值才为非0。
在源码实现中,用于训练Fast R-CNN的Proposal除了RPN网络生成的,还有图像的ground truth,这两者归并到一起,然后通过筛选组成minibatch用于迭代训练。Fast R-CNN的损失函数也与RPN类似,二分类变成了多分类,背景同样不参与回归损失计算,且只考虑proposal预测为标签类的回归损失。
(测试)新架构的测试效果
最好的Faster R-CNN模型在 2007 PASCAL VOC测试集上的mAP为78.8% ,而在2012 PASCAL VOC测试集上的mAP为75.9%。
论文中还在 COCO数据集上进行了测试。Faster R-CNN中的某个模型可以比采用selective search方法的Fast R-CNN模型快34倍。
可以看到,采用了RPN之后,无论是准确度还是速度,Faster R-CNN模型均有很大的提升。
Faster R-CNN采用RPN代替启发式region proposal的方法,这是一个重大变革,后面的two-stage方法的研究基本上都采用这种基本框架,而且和后面算法相比,Faster R-CNN在准确度仍然占据上风。















 5978
5978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









