






基本步骤
创建工程
scrapy startproject 工程名
创建爬虫文件
scrapy genspider 爬虫文件名 www.xxx.com
或者
scrapy genspider -t crawl spiderName www.xxx.com
设置配置文件
显示指定类型的日志文件:
LOG_LEVEL = 'ERROR'
不必遵守robots协议:
ROBOTSTXT_OBEY = FALSE
启动管道/下载器
启动爬虫
scrapy crawl spiderName
△scrapy框架简介
1.什么是框架
框架就是一个集成了很多功能并且具有很强通用性的一个项目模板
2.如何学习框架
专门学习框架封装的各种功能的详细用法
3.什么是scrapy
爬虫中封装好的一个明星框架
功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式…
△scrapy的基本使用
1.环境安装
安装以下模块:wheel, twisted,pywin32,scrapy(均可用pip安装)
2.创建工程
进入工程文件夹:
scrapy startproject 工程名
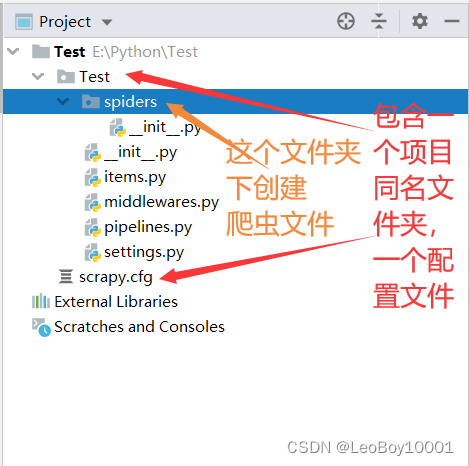
spiders目录:此目录下创建爬虫文件
items.py:实例化对象所用的类,需要自己添加属性
middlewares.py:下载器,可以截获请求和响应
pipelines.py:专门用来处理item类型的对象(数据存储)
setting.py:当前工程对应的配置文件
3.在spiders目录下创建爬虫文件
·进入工程路径
·创建起始url:
scrapy genspider 爬虫文件名 www.xxx.com
4.执行工程
scrapy crawl 爬虫文件名
5.变量说明

name: 脚本文件的唯一表示,不同的爬虫文件对应不同的值
allowed_domains: 允许的域名:用来限定start_urls列表中哪些url会被访问(通常注释掉)
start_urls: 起始的url列表,该列表中的url会被scrapy自动的发送请求
def parse(self,response):用来解析数据的函数,response参数表示的就是请求成功后对应的响应对象
6.Settings设置
显示指定类型的日志文件:
LOG_LEVEL = ‘ERROR’
不必遵守robots协议:
ROBOTSTXT_OBEY = FALSE
7.数据解析 parse()方法
response.xpath( ) 返回的是列表,但是列表元素一定是Selector类型的对象
.extract( ) 可以将Selector对象中data参数存储的字符串提取出来
.extract_first( ) 可以提取第一个元素,仅在确定列表中只有一个元素时使用
8.scrapy中持久化存储
1.基于终端指令(不用)
scrapy crawl spiderName -o ./fileName.csv
-
要求:只可以将parse方法的返回值存储到本地的文本文件中
-
注意:持久化存储对应的文本文件的类型只能是(json, jsonlines, js, csv, xml, marshal, pickle)
-
优点:简介高效便捷
-
缺点:局限性比较强(数据只可以保存在指定后缀的文本文件中)
2.基于管道
编码流程:
- 数据解析
- 在item类中定义相关的属性
- 将解析的数据封装存储到item类型的对象
- 将item类型的对象提交给管道进行持久化存储的操作:yield item
- 在管道类的process_item中要将接收到的item对象存储的数据进行持久化存储操作
fp = None
# 重写父类的一个方法:该方法只在爬虫的时候被调用一次
def open_spider(self, spider):
self.fp = open('fileName', 'w', encoding='utf-8')
# 该方法专门用来持久化存储
# item:传过来的封装好的数据
# 每传过来一个item就被调用一次
def process_item(self, item, spider):
self.fp.write()
return item # 将会传给下一个即将被执行的管道类
# 结束爬虫后调用一次
def close_spider(self, spider):
self.fp.close()
import pymysql
class mysqlPipeline(object):
conn = None
cursor = None
# 重写父类的一个方法:该方法只在爬虫的时候被调用一次
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root',passwd='root', db='dbName',charset='utf8')
# 该方法专门用来持久化存储
# item:传过来的封装好的数据
# 每传过来一个item就被调用一次
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('sql')
# 如果没有执行异常就提交事务
self.conn.commit()
except Exception as e:
print(e)
# 出现异常进行事务回滚
self.conn.rollback()
return item
# 结束爬虫后调用一次
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
-
在配置文件中开启管道(默认管道关闭)
ITEM_PIPELINES = { 'job_51.pipelines.Job51Pipeline': 300, # 300表示的是优先级,数值越小优先级越高 }
好处:通用性强
注意:
- 管道文件中的一个管道类对应的是将数据存储到一种平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接收
- process_item中的return item表示将item传递给下一个即将被执行的管道类
△基于Spider的全站数据爬取
全站数据爬取就是将某网站某版块下的全部页码对应的页面进行爬取
实现方式:
手动请求发送: yield scrapy.Request(url, callback,) callback:用于数据解析
-
def start_requests(self): urls = [ ] for url in urls: yield scrapy.Request(url=url, callback=self.parse, dont_filter=True) -
def parse(self, response): # 爬取父页面的页面信息 # 找到子页面 跳转到子页面的信息获取 yield scrapy.Request(detail_url, self.parse_stock, dont_filter=True) # 获取下一页地址 if nextPageURL: url = nextPageURL.extract_first('') # 发送下一页请求并调用parse()函数继续解析 yield scrapy.Request(url, self.parse, dont_filter=True)
△scrapy五大核心组件
调度器
- 过滤器:将引擎提交的请求对象去重
- 队列:存放过滤后的请求对象
- 将请求对象发送给引擎
管道
- 接收引擎发来的封装数据进行永久性存储数据
引擎
引擎主要作用数据流处理;引擎可以触发事务
- 将Spider传来的请求对象发送给调度器
- 将调度器传来的请求对象发送给下载器
- 将下载器传来的response对象传给Spider
- 接收封装好的数据发送给管道
下载器
- 负责去互联网当中进行数据下载
- 将response传给引擎
Spider
爬虫类
- 产生url,自动请求发送
- 进行数据解析
- 将请求对象传给引擎
- 接收引擎发来的response对象
- 将解析好的封装数据发送给引擎
△请求传参
使用场景:爬取数据不在同一张页面中(深度爬取)
在一个parse方法传参到另一个parse方法时,添加meta={‘item’: item}参数
yield scrapy.Request(url, self.parse_Subpage, dont_filter=True, meta={'item': item})
接收参数的函数,调用参数:
item = response.meta['item']
△图片数据爬取之ImagesPipeline
基于scrap爬取字符串类型的数据与图片类型的数据的区别:
- 字符串:只需要基于xpath进行解析且提交给管道进行持久化存储
- 图片:xpath只能解析出图片src属性值。单独对图片的地址发起请求获取图片二进制类型的数据
ImagesPipeline:
-
只需要将img的src属性进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制数据,并进行持久化存储
-
使用流程:
-
解析图片地址
-
将存储src属性的item提交给管道类
-
新建自定义管道类(重写父类中的三个方法)
-
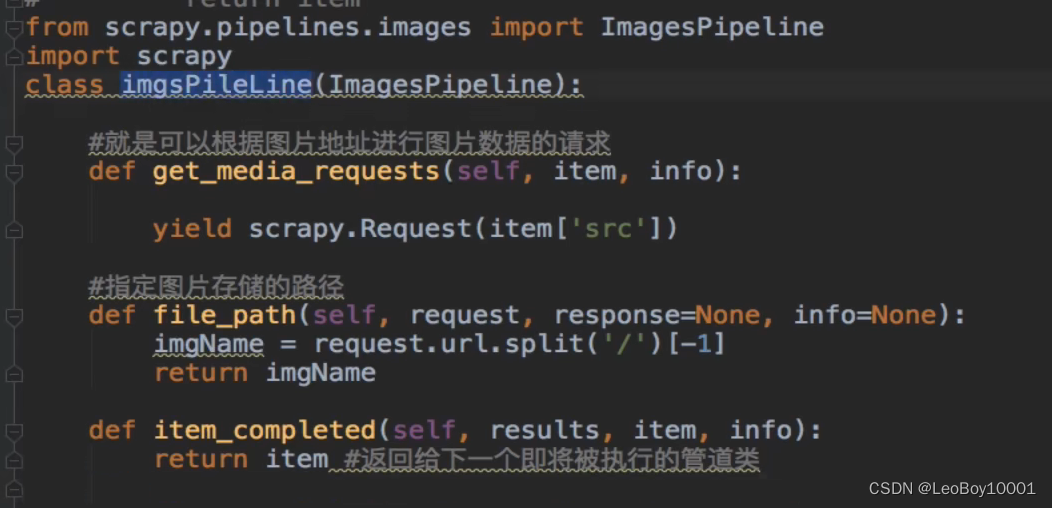
-
设置配置文件 指定图片存储路径
IMAGES_STORE = './images' -
开启管道类
△中间件
下载中间件(DownloaderMiddleware):
- 位置:引擎与下载器之间
- 作用:批量拦截到整个工程中所有的请求和相应
- 拦截请求:
- UA伪装:process_request()
- 代理ip:process_exception()
- 拦截响应:
- 篡改响应数据,响应对象
middlewares.py
拦截请求:
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) ',
]
# 拦截请求
def process_request(self, request, spider):
# UA伪装
request.headers['User-Agent'] = random.choice(self.user_agent_list)
return None
# 拦截所有的响应
def process_response(self, request, response, spider):
return response
# 设置代理ip池
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# 拦截发生异常的请求
def process_exception(self, request, exception, spider):
if request.url.split(':')[0] == 'http':
# 设置代理ip
request.meta['procxy'] = 'http://' + random.choice(self.PROXY_http)
else:
# 设置代理ip
request.meta['procxy'] = 'https://' + random.choice(self.PROXY_https)
# 将修正之后的请求对象进行重新请求发送
return request
-
配置文件中打开下载中间件
DOWNLOADER_MIDDLEWARES = { 'bossSpider.middlewares.BossspiderDownloaderMiddleware': 543, }
拦截响应:
主要解决网页中动态加载出来的数据
爬虫文件中用selenium实例浏览器对象(在构造函数中)
from selenium import webdriver
# 实例化一个浏览器对象
def __int__(self):
self.bro = webdriver.Chrome(executable_path='驱动地址')
-
首先在爬虫文件的parse函数中将需要动态加载的数据的url封装到model_urls列表中
-
将model_urls列表yield给解析动态页面的parse函数(首先由中间件重新封装新的response对象,再发送封装好的response对象给parse函数)
-
在配置文件中启动下载中间件
-
在解析动态加载数据的parse函数中解析数据
-
最终将封装好的数据yield item
# 拦截所有的响应 def process_response(self, request, response, spider): # 参数spider表示爬虫对象 # 获取爬虫文件中实例的浏览器对象 bro = spider.bro # 挑选出指定的响应对象进行篡改 # 通过url来指定request # 通过request指定response if request.url in spider.model_urls: # response #需要动态加载数据的响应对象 # 针对定位到的这些response进行篡改 # 实例化一个新的response(符合需求:包含动态加载出来的数据),替换旧的response from scrapy.http import HtmlResponse bro.get(request.url) # 对需要动态加载数据的页面发送请求 sleep(2) page_text = bro.page_source # 包含了动态加载的数据 # 如何动态获取需要加载的数据? # 基于selenium便捷的获取动态加载数据(在爬虫文件的构造方法中创建启动浏览器的对象bro) new_response = HtmlResponse(url=request.url,body= page_text,encoding='utf-8',request) return new_response else: # response #其他页面对应的响应对象 return response # 返回旧的响应对象 -
在爬虫文件中重写方法关闭浏览器closed()
def closed(slef, spider): slef.bro.quit()
CrawlSpider
是一个类,Spider的一个子类,专门用于全站数据爬取
全站数据爬取的方式:
- 基于Spider:手动请求
- 基于CrawlSpider:
CrawlSpider的使用:
-
创建一个工程
-
cd xxx
-
创建爬虫文件(CrawlSpider):scrapy genspider -t crawl spiderName www.xxx.com
链接提取器:LinkExtractor(allow=r’Items/')
- 提取指定的规则提取符合条件的链接
- allow:指定的规则 (正则)
- 可以自动去重
规则解析器:Rule(LinkExtractor(allow=r’Items/'), callback=‘parse_item’, follow=True)
-
作用:将链接提取器提取到的链接进行指定规则(callback)的解析
-
callback:指定数据提取的函数
-
follow=True:将链接提取器提取到的链接继续作用到链接提取器(全站爬取)
er
是一个类,Spider的一个子类,专门用于全站数据爬取
全站数据爬取的方式:
- 基于Spider:手动请求
- 基于CrawlSpider:
CrawlSpider的使用:
-
创建一个工程
-
cd xxx
-
创建爬虫文件(CrawlSpider):scrapy genspider -t crawl spiderName www.xxx.com
链接提取器:LinkExtractor(allow=r’Items/')
- 提取指定的规则提取符合条件的链接
- allow:指定的规则 (正则)
- 可以自动去重
规则解析器:Rule(LinkExtractor(allow=r’Items/'), callback=‘parse_item’, follow=True)
-
作用:将链接提取器提取到的链接进行指定规则(callback)的解析
-
callback:指定数据提取的函数
-
follow=True:将链接提取器提取到的链接继续作用到链接提取器(全站爬取)
















 1648
1648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











