







【0】README
0.1) 本文描述转自 core java volume 2, 旨在理解 java流与文件——流 的相关知识;
0.2) 输入流和输出流(InputStream 和 OutputStream传输单位是基于单字节):
- 0.2.1)输入流:可以从其中读入一个字节序列的对象,这个其中就叫做输入流,即我们可以从输入流中读入一个字节序列的对象;
- 0.2.2)输出流:可以从其中写出一个字节序列的对象,这个其中就叫做输出流,即我们可以从输出流中写出一个字节序列的对象;
- 0.2.3)抽象类 InputStream 和 OutputStream 构成了 输入输出类层次结构的基础;
0.3)引入 抽象类Reader 和 Writer(传输单位是基于两字节的Unicode码元,每次只传递一个字符,见read和write方法)
- 0.3.1)problem: 因为面向字节的流不便于处理以 Unicode 形式存储的信息;
- 0.3.2)solution:所以从抽象类 Reader 和 Writer 中继承出来了一个专门用于处理 Unicode字符的单独的类层次结构。这些类拥有的读入和写出操作都是基于两字节的 Unicode码元的, 而不是基于单字节的字符;(干货——Unicode码元==Unicode字符==两字节)
【1】读写字节
1.1)InputStream 类有一个抽象方法: abstract int read()
1.2)OutputStream类有抽象方法: abstract void write(int b)
1.3) read 和 write 方法 在执行时都将阻塞,直到字节确实被读入或写出;这意味着如果流不能被立即访问,则当前线程被阻塞;
- 1.3.1)available 方法: 可以检查当前可读入的字节数量;
- 1.3.2)close方法: 完成对流的读写后,用close 方法关闭它;且关闭一个输出流的同时还会冲刷(flush)缓冲区;
(缓冲区:所有被临时置于缓冲区中, 以便用更大的包的形式传递的字符在关闭输出流时被送出, 同时减少了访问硬盘的次数)(干货——缓冲区的定义和作用)
- 1.3.2.1)如果不关闭文件, 那么写出字节的最后一个包可能将永远也不会传递出去;
- 1.3.3)flush方法: 冲洗缓冲区的数据到流中,最后到达文件;
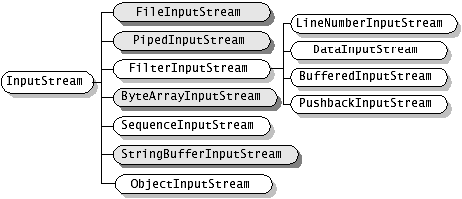
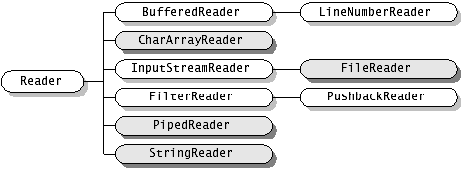
【2】完整的流家族
(图片来源: http://blog.csdn.net/hguisu/article/details/7418161)
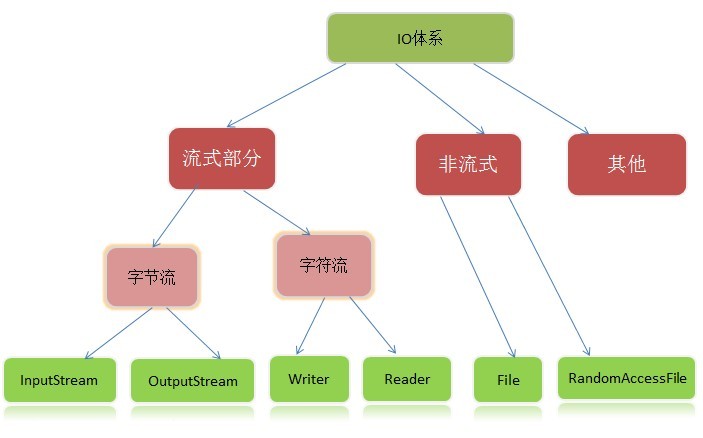
2.1)InputStream 和 OutputStream
- 2.1.1)DataInputStream 和 DataOutputStream: 可以以二进制格式读写所有的基本java类型;
- 2.1.2)ZipInputStream 和 ZipOutputStream : 以常见的ZIP 压缩格式读写文件;
 |  |
|  |  |
FileInputStream fin = new FileInputStream("a.dat");
DataInputStream din = new DataInputStream(fin);
double s = din.readDouble();PushbackInputStream pbin = new PushbackInputStream(new BufferedInputStream(new FileInputStream("a.dat")));
DataInputStream din = new DataInputStream(pbin);| 注意: (转自, http://blog.csdn.net/u010700335/article/details/40155053) 如果文件串的最后一个字符是中文,使用mark()中的长度设为file.length() 如果文件的最后一个字符串是英文或数字,则java.io.IOException: Mark invalid,使用mark()中的长度设为file.length()+1 mark用于标记当前位置;在读取一定数量的数据(小于readlimit的数据)后使用reset可以回到mark标记的位置;FileInputStream不支持mark/reset操作;BufferedInputStream支持此操作; mark(readlimit)的含义是在当前位置作一个标记,制定可以重新读取的最大字节数,也就是说你如果标记后读取的字节数大于readlimit,你就再也回不到回来的位置了;通常InputStream的read()返回-1后,说明到达文件尾,不能再读取。除非使用了mark/reset。。 |
- 3.3.3)看个荔枝: 可以通过一个 ZIP 压缩文件中通过使用下面的流序列读入数字:
ZipInputStream zin = new ZipInputStream(new FileInputStream("a.zip"));
DataInputStream din = new DataInputStream(zin);














 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









