






使用XLNet分析电影评论情感
1. 实验内容
自然语言是人类传递信息的一种载体,同时它也能表达人类交流时的一种情感。一段对话或者一句评论都能蕴含着丰富的感情色彩:比如高兴、快乐、喜欢、讨厌、忧伤等等。如图1 所示,利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。通常情况下,我们往往将情感分析任务定义为一个分类问题,即使用计算机判定给定的一段文字所表达的情感属于积极情绪,还是消极情绪。
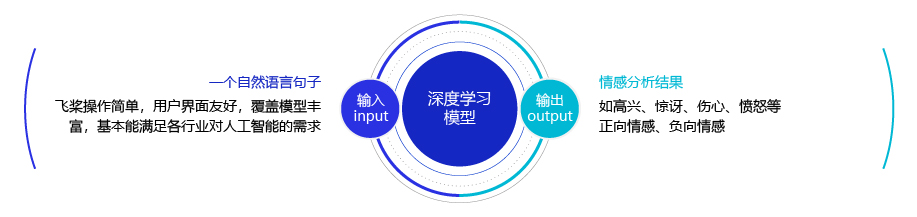
本实验将使用XLNet建模情感分析模型,使用的数据集是IMDB电影评论数据集,该任务有助于帮助消费者了解一部电影的质量,也可用于电影的推荐。下面我们来具体了解一下IMDB数据集。
IMDB是一份关于电影评论的数据集,消费者对电影进行评论时可以进行打分,满分是10分。IMDB将消费者对电影的评论按照评分的高低筛选出了积极评论和消极评论,如果评分>=7,则认为是积极评论;如果评分<=4,则认为是消极评论。所以IMDB数据集是一份关于情感分析的经典二分类数据集,其中训练集和测试集数量各为25000条。
2. 实验环境
-
PaddlePaddle 安装
本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 安装指南 进行安装 -
PaddleNLP 安装
pip install --upgrade paddlenlp -i https://pypi.org/simple -
环境依赖
Python的版本要求 3.6+
3. 实验设计
本实验将按照这样几个阶段进行:参数设置–>数据处理–>模型结构–>训练配置–>模型训练和评估
3.1 参数设置
这里我们先定义好本实验所需要的一些参数,这些参数在数据处理,模型构建,模型训练等部分均会用到,配置的超参数如下:
import re
import os
import time
import tarfile
import random
import argparse
import numpy as np
from functools import partial
import paddle
from paddle.io import Dataset
from paddle.io import DataLoader
from paddle.metric import Accuracy
from paddlenlp.datasets import MapDataset
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.transformers.xlnet.tokenizer import XLNetTokenizer
from paddlenlp.transformers.xlnet.modeling import XLNetPretrainedModel, XLNetForSequenceClassification
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
paddle.seed(args.seed)
class Config():
def __init__(self):
self.task_name = "sst-2"
self.model_name_or_path = "xlnet-base-cased"
self.output_dir = "./tmp"
self.max_seq_length = 128
self.batch_size = 32
self.learning_rate = 2e-5
self.weight_decay = 0.0
self.adam_epsilon = 1e-8
self.max_grad_norm = 1.0
self.num_train_epochs = 3
self.max_steps = -1
self.logging_steps = 100
self.save_steps=500
self.seed=43
self.device="gpu"
self.warmup_steps = 0
self.warmup_proportion = 0.1
args = Config()
3.2 数据处理
3.2.1 加载IMDB数据集
这里我们从本地文件中加载数据集,然后封装成一个paddle.io.DataSet,本实验我们将基于PaddleNLP套件进行实验,因此我们将数据进一步封装成paddlenlp.datasets.MapDataset的形式,相关代码如下:
class IMDBDataset(Dataset):
def __init__(self, is_training=True):
self.data = self.load_imdb(is_training)
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def load_imdb(self, is_training):
# 将读取的数据放到列表data_set里
data_set = []
# data_set中每个元素都是一个二元组:(句子,label),其中label=0表示消极情感,label=1表示积极情感
for label in ["pos", "neg"]:
with tarfile.open("./imdb_aclImdb_v1.tar.gz") as tarf:
path_pattern = "aclImdb/train/" + label + "/.*\.txt$" if is_training \
else "aclImdb/test/" + label + "/.*\.txt$"
path_pattern = re.compile(path_pattern)
tf = tarf.next()
while tf != None:
if bool(path_pattern.match(tf.name)):
sentence = tarf.extractfile(tf).read().decode()
sentence_label = 0 if label == 'neg' else 1
data_set.append({"sentence":sentence, "label":sentence_label})
tf = tarf.next()
return data_set
# 加载数据
trainset=IMDBDataset(is_training=True)
testset = IMDBDataset(is_training=False)
# 封装成MapDataSet的形式
train_ds = MapDataset(trainset, label_list=[0,1])
test_ds = MapDataset(testset, label_list=[0,1])
<>:19: DeprecationWarning: invalid escape sequence \.
<>:20: DeprecationWarning: invalid escape sequence \.
<>:19: DeprecationWarning: invalid escape sequence \.
<>:20: DeprecationWarning: invalid escape sequence \.
<>:19: DeprecationWarning: invalid escape sequence \.
<>:20: DeprecationWarning: invalid escape sequence \.
<ipython-input-4-d051183b01d1>:19: DeprecationWarning: invalid escape sequence \.
path_pattern = "aclImdb/train/" + label + "/.*\.txt$" if is_training \
<ipython-input-4-d051183b01d1>:20: DeprecationWarning: invalid escape sequence \.
else "aclImdb/test/" + label + "/.*\.txt$"
3.2.2 将原始数据转换模型输入形式
这里我们将加载一个XLNetTokenizer,该tokenizer负责将原始数据处理成模型输入可接收的形式,包括将原始文本转换成ID, 向原始数据中拼接CLS,SEP构造输入序列等等。
def convert_example(example,
tokenizer,
label_list,
max_seq_length=512,
is_test=False):
if not is_test:
# `label_list == None` is for regression task
label_dtype = "int64" if label_list else "float32"
# Get the label
label = example['label']
label = np.array([label], dtype=label_dtype)
# Convert raw text to feature
if (int(is_test) + len(example)) == 2:
example = tokenizer(
example['sentence'],
max_seq_len=max_seq_length,
return_attention_mask=True)
else:
example = tokenizer(
example['sentence1'],
text_pair=example['sentence2'],
max_seq_len=max_seq_length,
return_attention_mask=True)
if not is_test:
return example['input_ids'], example['token_type_ids'], example[
'attention_mask'], label
else:
return example['input_ids'], example['token_type_ids'], example[
'attention_mask']
# 定义XLNet的Tokenizer
tokenizer = XLNetTokenizer.from_pretrained(args.model_name_or_path)
trans_func = partial(
convert_example,
tokenizer = tokenizer,
label_list = train_ds.label_list,
max_seq_length= args.max_seq_length
)
# 构造train_data_loader 和 dev_data_loader
train_ds = train_ds.map(trans_func, lazy=True)
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size = args.batch_size, shuffle=True
)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id, pad_right=False), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id, pad_right=False), # token_type
Pad(axis=0, pad_val=0, pad_right=False), # attention_mask
Stack(dtype="int64" if train_ds.label_list else "float32"), # label
): fn(samples)
train_data_loader = DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=batchify_fn,
num_workers=0,
return_list=True)
dev_ds = MapDataset(testset)
dev_ds = dev_ds.map(trans_func, lazy=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=args.batch_size, shuffle=False)
dev_data_loader = DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=batchify_fn,
num_workers=0,
return_list=True)
[2021-06-15 11:11:36,717] [ INFO] - Found /home/aistudio/.paddlenlp/models/xlnet-base-cased/xlnet-base-cased-spiece.model
3.3 模型构建
这里我们通过使用PaddleNLP集成好的XLNet进行本实验,加载代码非常简单,一行代码搞定,代码如下:
num_classes = len(train_ds.label_list)
model = XLNetForSequenceClassification.from_pretrained(args.model_name_or_path, num_classes=num_classes)
[2021-06-15 11:11:47,526] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/xlnet-base-cased/xlnet-base-cased.pdparams
3.4 训练配置
接下来,我们做一些训练配置方面的工作,包括固定随机种子,设定运行环境,指定优化器等
# 固定随机种子
set_seed(args)
# 设定运行环境
paddle.set_device(args.device)
if paddle.distributed.get_world_size() > 1:
paddle.distributed.init_parallel_env()
model = paddle.DataParallel(model)
# 设定lr_scheduler
if args.max_steps > 0:
num_training_steps = args.max_steps
num_train_epochs = ceil(num_training_steps / len(train_data_loader))
else:
num_training_steps = len(train_data_loader) * args.num_train_epochs
num_train_epochs = args.num_train_epochs
warmup = args.warmup_steps if args.warmup_steps > 0 else args.warmup_proportion
lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps,
warmup)
# 制定优化器
clip = paddle.nn.ClipGradByGlobalNorm(clip_norm=args.max_grad_norm)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "layer_norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
beta1=0.9,
beta2=0.999,
epsilon=args.adam_epsilon,
parameters=model.parameters(),
grad_clip=clip,
weight_decay=args.weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
3.5 模型训练与评估
本节我们将进行模型训练与评估,训练过程中将进行评估以验证模型训练效果。其中模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data。
- 将batch data喂给model,做前向计算。
- 将前向计算结果传给损失函数,计算loss。
- loss反向回传,更新梯度。重复以上步骤。
相应代码如下:
@paddle.no_grad()
def evaluate(model, loss_fct, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, attention_mask, labels = batch
logits = model(input_ids, token_type_ids, attention_mask)
loss = loss_fct(logits, labels)
losses.append(loss.detach().numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
res = metric.accumulate()
print("eval loss: %f, acc: %s" % (np.average(losses), res))
model.train()
def train():
# 设定评估指标
metric = Accuracy()
# 定义损失函数
loss_fct = paddle.nn.loss.CrossEntropyLoss(
) if train_ds.label_list else paddle.nn.loss.MSELoss()
global_step = 0
tic_train = time.time()
model.train()
for epoch in range(num_train_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, token_type_ids, attention_mask, labels = batch
logits = model(input_ids, token_type_ids, attention_mask)
loss = loss_fct(logits, labels)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % args.logging_steps == 0:
print(
"global step %d/%d, epoch: %d, batch: %d, rank_id: %s, loss: %f, lr: %.10f, speed: %.4f step/s"
% (global_step, num_training_steps, epoch, step,
paddle.distributed.get_rank(), loss, optimizer.get_lr(),
args.logging_steps / (time.time() - tic_train)))
tic_train = time.time()
if global_step % args.save_steps == 0 or global_step == num_training_steps:
tic_eval = time.time()
evaluate(model, loss_fct, metric, dev_data_loader)
print("eval done total : %s s" % (time.time() - tic_eval))
if (not paddle.distributed.get_world_size() > 1
) or paddle.distributed.get_rank() == 0:
output_dir = os.path.join(args.output_dir, "%s_ft_model_%d"
% (args.task_name, global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Need better way to get inner model of DataParallel
model_to_save = model._layers if isinstance(
model, paddle.DataParallel) else model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
if global_step == num_training_steps:
exit(0)
tic_train += time.time() - tic_eval
train()
global step 100/2346, epoch: 0, batch: 99, rank_id: 0, loss: 0.388979, lr: 0.0000085470, speed: 1.8725 step/s
global step 200/2346, epoch: 0, batch: 199, rank_id: 0, loss: 0.251266, lr: 0.0000170940, speed: 1.8797 step/s
global step 300/2346, epoch: 0, batch: 299, rank_id: 0, loss: 0.095259, lr: 0.0000193750, speed: 1.8816 step/s
global step 400/2346, epoch: 0, batch: 399, rank_id: 0, loss: 0.417876, lr: 0.0000184280, speed: 1.8686 step/s
global step 500/2346, epoch: 0, batch: 499, rank_id: 0, loss: 0.391909, lr: 0.0000174811, speed: 1.8732 step/s
eval loss: 0.279980, acc: 0.89076
eval done total : 182.02774739265442 s
global step 600/2346, epoch: 0, batch: 599, rank_id: 0, loss: 0.277246, lr: 0.0000165341, speed: 1.8712 step/s
global step 700/2346, epoch: 0, batch: 699, rank_id: 0, loss: 0.131521, lr: 0.0000155871, speed: 1.8800 step/s
global step 800/2346, epoch: 1, batch: 17, rank_id: 0, loss: 0.316707, lr: 0.0000146402, speed: 1.8937 step/s
global step 900/2346, epoch: 1, batch: 117, rank_id: 0, loss: 0.167703, lr: 0.0000136932, speed: 1.8862 step/s
global step 1000/2346, epoch: 1, batch: 217, rank_id: 0, loss: 0.177276, lr: 0.0000127462, speed: 1.8814 step/s
eval loss: 0.272126, acc: 0.90296
eval done total : 181.41404962539673 s
global step 1100/2346, epoch: 1, batch: 317, rank_id: 0, loss: 0.159426, lr: 0.0000117992, speed: 1.8833 step/s
global step 1200/2346, epoch: 1, batch: 417, rank_id: 0, loss: 0.154938, lr: 0.0000108523, speed: 1.8759 step/s
global step 1300/2346, epoch: 1, batch: 517, rank_id: 0, loss: 0.376902, lr: 0.0000099053, speed: 1.8800 step/s
global step 1400/2346, epoch: 1, batch: 617, rank_id: 0, loss: 0.223009, lr: 0.0000089583, speed: 1.8734 step/s
global step 1500/2346, epoch: 1, batch: 717, rank_id: 0, loss: 0.184832, lr: 0.0000080114, speed: 1.8782 step/s
eval loss: 0.252491, acc: 0.9018
eval done total : 181.00143718719482 s
global step 1600/2346, epoch: 2, batch: 35, rank_id: 0, loss: 0.342831, lr: 0.0000070644, speed: 1.8901 step/s
global step 1700/2346, epoch: 2, batch: 135, rank_id: 0, loss: 0.258072, lr: 0.0000061174, speed: 1.8813 step/s
global step 1800/2346, epoch: 2, batch: 235, rank_id: 0, loss: 0.444596, lr: 0.0000051705, speed: 1.8766 step/s
global step 1900/2346, epoch: 2, batch: 335, rank_id: 0, loss: 0.182193, lr: 0.0000042235, speed: 1.8749 step/s
global step 2000/2346, epoch: 2, batch: 435, rank_id: 0, loss: 0.259044, lr: 0.0000032765, speed: 1.8762 step/s
eval loss: 0.303149, acc: 0.90508
eval done total : 182.125333070755 s
global step 2100/2346, epoch: 2, batch: 535, rank_id: 0, loss: 0.082246, lr: 0.0000023295, speed: 1.8798 step/s
global step 2200/2346, epoch: 2, batch: 635, rank_id: 0, loss: 0.210103, lr: 0.0000013826, speed: 1.8766 step/s
global step 2300/2346, epoch: 2, batch: 735, rank_id: 0, loss: 0.090656, lr: 0.0000004356, speed: 1.8810 step/s
eval loss: 0.312801, acc: 0.90624
eval done total : 180.48680448532104 s
final: acc: 0.90624
















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









