







OCR方向的工程师,一定有在关注PaddleOCR这个项目,其主要推荐的PP-OCR算法更是被国内外企业开发者广泛应用。短短几年时间,PP-OCR累计Star数量已超过32.2k,频频登上GitHub Trending和Paperswithcode日榜月榜第一,称它为OCR方向目前最火的repo绝对不为过。
PaddleOCR主打的PP-OCR系列模型,在去年五月份推出了v3。最近,飞桨AI套件团队针对PP-OCRv3进行了全方位的改进,重磅推出了PP-OCRv4!👏👏👏
从效果上看,速度可比情况下,v4相比v3在多种场景下的精度均有大幅提升:
- 中文场景,相对于PP-OCRv3中文模型提升超4%。
- 英文数字场景,相比于PP-OCRv3英文模型提升6%。
- 多语言场景,优化80个语种识别效果,平均准确率提升超8%。
PP-OCRv4模型目前已随PaddleOCR 2.7版本正式发布,欢迎大家持续关注PaddleOCR~~~
GitHub项目地址
https://github.com/PaddlePaddle/PaddleOCR
PP-OCRv4效果速览
让我们拿结果说话,多图预警!!!
PP-OCRv4效果速览

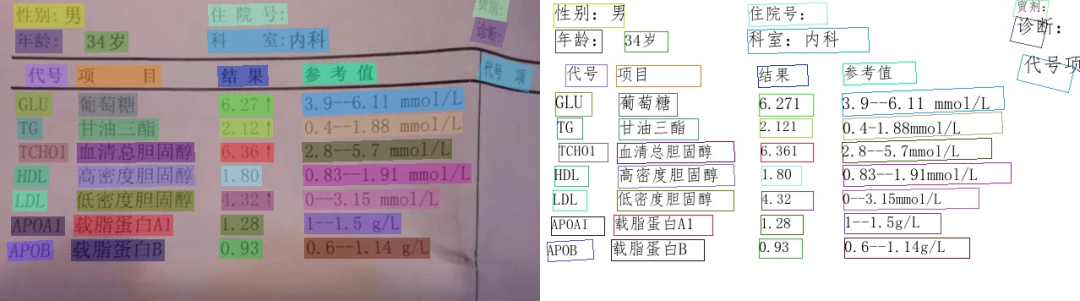

英文场景


多语言场景


下面上定量评测结果!
PP-OCRv4在速度可比情况下,中文场景端到端Hmean指标相比于PP-OCRv3提升4.25%,效果大幅提升。具体指标如下表所示:
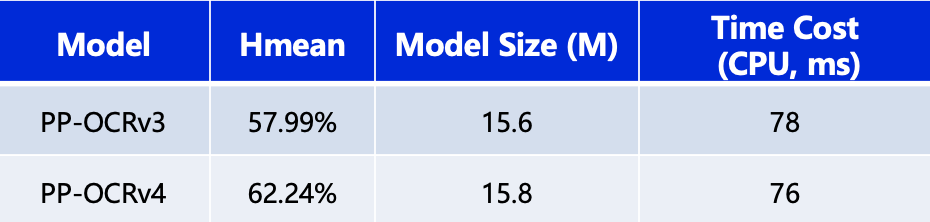
测试环境:CPU型号为Intel Gold 6148,CPU预测时使用OpenVINO。
除了更新中文模型,本次升级也优化了英文数字模型,在自有评估集上文本识别准确率提升6%,如下表所示:

同时,也对已支持的80余种语言识别模型进行了升级更新,在有评估集的四种语系识别准确率平均提升5%以上,如下表所示:

在飞桨AI套件中使用PP-OCRv4
为了方便大家在线体验效果,并且快速上手PP-OCRv4模型的训练调优和部署,PP-OCRv4目前已上线飞桨AI套件PaddleX!
在线体验推理效果
https://aistudio.baidu.com/projectdetail/6611435
创建自己的PP-OCRv4
https://aistudio.baidu.com/modelsdetail?modelId=286
PaddleX是一站式、全流程、高效率的飞桨AI套件,具备飞桨生态优质模型和产业方案。PaddleX的使命是助力AI技术快速落地,愿景是使人人成为AI Developer。
PaddleX支持10+任务能力,包括图像分类、目标检测、图像分割、3D、OCR和时序预测等;内置36 种飞桨生态特色模型,包括PP-ChatOCR、PP-OCRv4、RT-DETR、PP-YOLOE、PP-ShiTu、PP-LiteSeg、PP-TS等。
PaddleX提供“工具箱”和“开发者”两种开发模式,同时支持云端和本地端。工具箱模式可以无代码调优关键超参,开发者模式可以低代码进行单模型训压推和多模型串联推理。
PaddleX未来还将支持联创开发,收益共享!欢迎广大个人开发者和企业开发者参与进来,共创繁荣的AI技术生态!
目前PaddleX正在快速迭代,欢迎大家试用和指正!
PP-OCRv4十大关键技术点深入解读
PP-OCRv4整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。PP-OCRv4系统框图如下所示:

从算法改进思路上看,分别针对检测和识别模型,进行了共10个方面的改进:
检测模块
- PP-LCNetV3:精度更高的骨干网络
- PFHead:并行head分支融合结构
- DSR: 训练中动态增加shrink ratio
- CML:添加Student和Teacher网络输出的KL div loss
识别模块
- SVTR_LCNetV3:精度更高的骨干网络
- Lite-Neck:精简的Neck结构
- GTC-NRTR:稳定的Attention指导分支
- Multi-Scale:多尺度训练策略
- DF: 数据挖掘方案
- DKD :DKD蒸馏策略
敲黑板了,下面让我们对这10个技术点进行一一解读。
检测优化
PP-OCRv4检测模型在PP-OCRv3检测模型的基础上,在网络结构,训练策略,蒸馏策略三个方面做了优化。首先,PP-OCRv4检测模型使用PP-LCNetV3替换MobileNetv3,并提出并行分支融合的PFhead结构;其次,训练时动态调整shrink ratio的比例;最后,PP-OCRv4对CML的蒸馏loss进行优化,进一步提升文字检测效果。
消融实验如下:
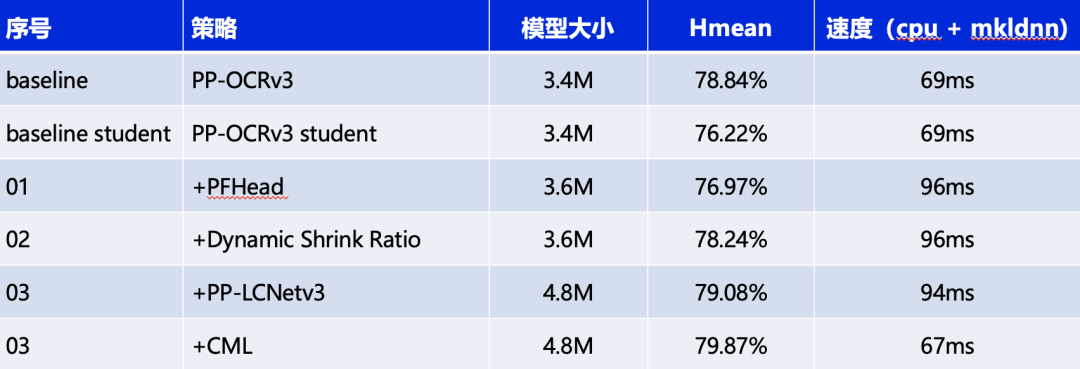
测试环境:Intel Gold 6148 CPU,预测引擎使用OpenVINO。
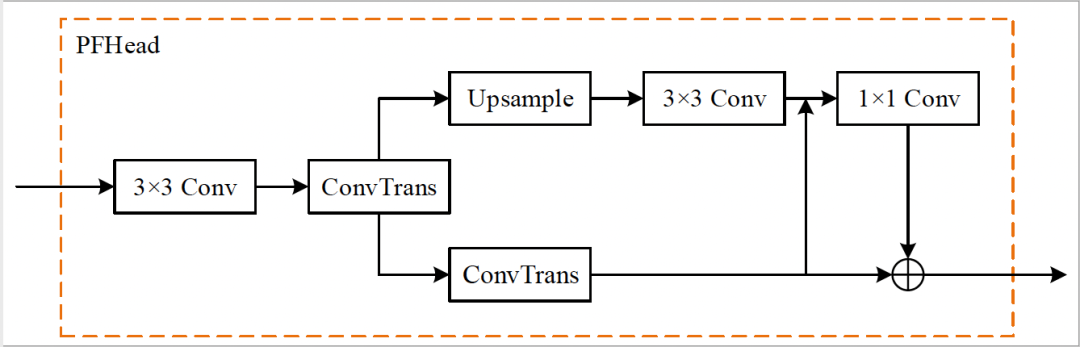
PFhead:多分支融合Head结构
PFhead结构如下图所示,PFHead在经过第一个转置卷积后,分别进行上采样和转置卷积,上采样的输出通过3x3卷积得到输出结果,然后和转置卷积的分支的结果级联并经过1x1卷积层,最后1x1卷积的结果和转置卷积的结果相加得到最后输出的概率图。PP-OCRv4学生检测模型使用PFhead,Hmean从76.22%增加到76.97%。
DSR:收缩比例动态调整策略
动态shrink ratio(dynamic shrink ratio): 在训练中,shrink ratio由固定值调整为动态变化,随着训练epoch的增加,shrink ratio从0.4线性增加到0.6。该策略在PP-OCRv4学生检测模型上,Hmean从76.97%提升到78.24%。
PP-LCNetV3:精度更高的骨干网络
PP-LCNetV3系列模型是PP-LCNet系列模型的延续,覆盖了更大的精度范围,能够适应不同下游任务的需要。PP-LCNetV3系列模型从多个方面进行了优化,提出了可学习仿射变换模块,对重参数化策略、激活函数进行了改进,同时调整了网络深度与宽度。最终,PP-LCNetV3系列模型能够在性能与效率之间达到最佳的平衡,在不同精度范围内取得极致的推理速度。使用PP-LCNetV3替换MobileNetv3 backbone,PP-OCRv4学生检测模型hmean从78.24%提升到79.08%。
CML:融合KD的互学习策略
PP-OCRv4检测模型对PP-OCRv3中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了优化。如下图所示,在计算Student Model和Teacher Model的distill Loss时,额外添加KL div loss,让两者输出的response maps分布接近,由此进一步提升Student网络的精度,检测Hmean从79.08%增加到79.56%,端到端指标从61.31%增加到61.87%。
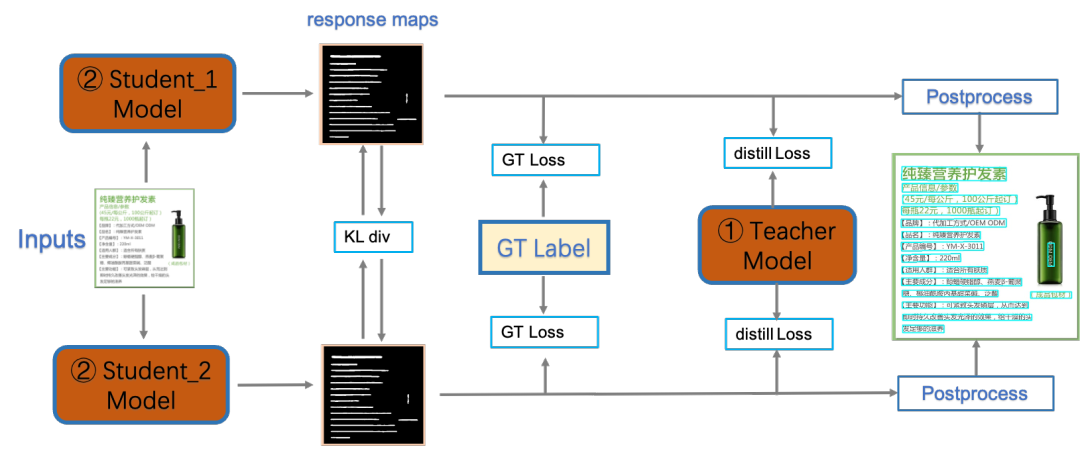
识别优化
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。直接将PP-OCRv2的识别模型,替换成SVTR_Tiny,识别准确率从74.8%提升到80.1%(+5.3%),但是预测速度慢了将近11倍,CPU上预测一条文本行,将近100ms。因此,如下图所示,PP-OCRv3采用如下6个优化策略进行识别模型加速。

基于上述策略,PP-OCRv4识别模型相比PP-OCRv3,在速度可比的情况下,精度进一步提升4%。具体消融实验如下所示:

注:测试速度时,输入图片尺寸均为(3,48,320)。在实际预测时,图像为变长输入,速度会有所变化。测试环境:Intel Gold 6148 CPU,预测时使用OpenVINO预测引擎。
DF:数据挖掘方案
DF(Data Filter) 是一种简单有效的数据挖掘方案。核心思想是利用已有模型预测训练数据,通过置信度和预测结果等信息,对全量数据进行筛选。具体的:首先使用少量数据快速训练得到一个低精度模型,使用该低精度模型对千万级的数据进行预测,去除置信度大于0.95的样本,该部分被认为是对提升模型精度无效的冗余数据。其次使用PP-OCRv3作为高精度模型,对剩余数据进行预测,去除置信度小于0.15的样本,该部分被认为是难以识别或质量很差的样本。使用该策略,千万级别训练数据被精简至百万级,显著提升模型训练效率,模型训练时间从2周减少到5天,同时精度提升至72.7%(+1.2%)。

PP-LCNetV3:精度更优的骨干网络
PP-LCNetV3系列模型是PP-LCNet系列模型的延续,覆盖了更大的精度范围,能够适应不同下游任务的需要。PP-LCNetV3系列模型从多个方面进行了优化,提出了可学习仿射变换模块,对重参数化策略、激活函数进行了改进,同时调整了网络深度与宽度。最终,PP-LCNetV3系列模型能够在性能与效率之间达到最佳的平衡,在不同精度范围内取得极致的推理速度。
Lite-Neck:精简参数的Neck结构
Lite-Neck整体结构沿用PP-OCRv3版本,在参数上稍作精简,识别模型整体的模型大小可从12M降低到8.5M,而精度不变;在CTCHead中,将Neck输出特征的维度从64提升到120,此时模型大小从8.5M提升到9.6M,精度提升0.5%。
GTC-NRTR:Attention指导CTC训练策略
GTC(Guided Training of CTC),是在PP-OCRv3中使用过的策略,融合多种文本特征的表达,可有效提升文本识别精度。在PP-OCRv4中使用训练更稳定的Transformer模型NRTR作为指导,相比SAR基于循环神经网络的结构,NRTR基于Transformer实现解码过程泛化能力更强,能有效指导CTC分支学习。解决简单场景下快速过拟合的问题。模型大小不变,识别精度提升至73.21%(+0.5%)。

Multi-Scale:多尺度训练策略
动态尺度训练策略,是在训练过程中随机resize输入图片的高度,以增大模型的鲁棒性。在训练过程中随机选择(32,48,64)三种高度进行resize,实验证明在测试集上评估精度不掉,在端到端串联推理时,指标可以提升0.5%。

DKD:蒸馏策略
识别模型的蒸馏包含两个部分,NRTRhead蒸馏和CTCHead蒸馏;
对于NRTR head,使用了DKD loss蒸馏,使学生模型NRTR head输出的logits与教师NRTR head接近。最终NRTR head的loss是学生与教师间的DKD loss和与ground truth的cross entropy loss的加权和,用于监督学生模型的backbone训练。通过实验,我们发现加入DKD loss后,计算与ground truth的cross entropy loss时去除label smoothing可以进一步提高精度,因此我们在这里使用的是不带label smoothing的cross entropy loss。
对于CTCHead,由于CTC的输出中存在Blank位,即使教师模型和学生模型的预测结果一样,二者输出的logits分布也会存在差异,影响教师模型向学生模型的知识传递。PP-OCRv4识别模型蒸馏策略中,将CTC输出logits沿着文本长度维度计算均值,将多字符识别问题转换为多字符分类问题,用于监督CTC Head的训练。使用该策略融合NRTRhead DKD蒸馏策略,指标从0.7377提升到0.7545。
在AI Studio在线体验PP-OCRv4的推理效果
https://aistudio.baidu.com/projectdetail/6611435
飞桨AI套件PaddleX中的PP-OCRv4
https://aistudio.baidu.com/modelsdetail?modelId=286
PaddleOCR项目地址
https://github.com/PaddlePaddle/PaddleOCR
















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









