







 本文探讨了位运算技巧、链表与队列基础,包括用位运算swap数字、链表删除特定值、栈与队列的高级应用,如双端队列、栈转队列与BFS。此外,还涉及了归并排序、堆、排序算法、图论、最小栈等核心知识点,展示了如何在信息技术中高效处理复杂问题。
本文探讨了位运算技巧、链表与队列基础,包括用位运算swap数字、链表删除特定值、栈与队列的高级应用,如双端队列、栈转队列与BFS。此外,还涉及了归并排序、堆、排序算法、图论、最小栈等核心知识点,展示了如何在信息技术中高效处理复杂问题。
左程云算法
//更新到31课
位运算
用^来swap数字
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
03 链表结构
删除链表中给定的值注意判断是否删除头节点
栈和队列
双端队列实现队列和栈
双向链表实现双端队列
用栈实现队列
目的:先出顶部的元素改为先出底部的元素(对栈来说)
所以只要把除了顶部的元素倒到栈2中再pop出栈1剩的一个元素就行
难点:维护元素的先后顺序
初版:每次pop都先倒到栈2中,pop出栈2的首位。再把栈2的倒入栈1
缺点:每次pop都是O(N)
问题:为了保持原数组的顺序关系,每次都需要遍历数组再能得到需要的数。后面不能利用到前面的结论
思想:一个栈只接收,一个栈只弹出
维护顺序的原则:
1.push栈到pop栈要一次性倒完
2.只要pop栈里有数据,push栈就不能往pop栈里倒数据


用队列实现栈
目的:把队尾的元素弹出
操作:两个队列来回倒,一个队列只剩一个的时候再poll出
注意有个交换队列地址引用的行为

环形数组实现队列(栈简单)
设置两个指针,一个指向pop位,一个指向push位。 位置越界的判断在nextIndex里。个数越界的判断用size。就不用考虑两指针的间距
具体过程:
size++/–
设置or取出对应位置的值
nextIndex(polli)
nextIndex中堆越界进行判断

用栈实现BFS(栈转队列)
用队列实现DFS(队列转栈)
实现最小栈
04 归并排序
原理:整体是递归,左边排好序,右边再排,然后merge排左右
复杂度:merge过程中指针不后退利用了之前排序的结果
// 请把arr[L..R]排有序
// l...r N
// T(N) = 2 * T(N / 2) + O(N)
// O(N * logN)
public static void process(int[] arr, int L, int R) {
if (L == R) { // base case
return;
}
int mid = L + ((R - L) >> 1);
process(arr, L, mid);
process(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int M, int R) {
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
// 要么p1越界了,要么p2越界了
while (p1 <= M) {
help[i++] = arr[p1++];
}
while (p2 <= R) {
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {
arr[L + i] = help[i];
}
}
非递归的归并排序
public static void mergeSort22(int[] arr) {
//防止为空
if (arr == null || arr.length < 2) {
return;
}
int N = arr.length;
int mergeSize = 1;
//这里不写等于是因为mergeSize超过2/N就会停了
while (mergeSize < N) {
//每个步长都要遍历一遍数组
int LP = 0;
int RP = 0;
int mid = 0;
while (LP < N) {
//确定L,M,R的值
//M=LP+mergeSize,M<N
//这里等号转化下防止越界
if (LP > N - mergeSize) {
break;
}
mid =LP+mergeSize-1;
RP = Math.min(N - 1, mid + mergeSize);
merge(arr,LP,mid,RP);
//每次都得往前推
LP=RP+1;
}
//防止越界
if (mergeSize > N / 2) {
break;
}
mergeSize*=2;
}
}
堆
堆的heapify和heapinsert
实现最小栈:实现一个特殊的栈,在基本功能的基础上,再实现返回栈中最小元素的功能
1)pop、push、getMin操作的时间复杂度都是 O(1)。
2)设计的栈类型可以使用现成的栈结构。
加强堆
排序
堆排序
二叉树
二叉树的非递归版前中后序
二叉树的递归版前中后序
Pre序列化
//序列化成str
public static String serialByPre(Node head) {
if (head == null) {//叶子节点返回的条件
return "#!";//用#表示null
}
String res = head.value + "!";//往字符串中插入value,和分隔符
//整个流程就是打印值,向左递归。遇null返回,往右探一位再向左。再往右探,左递归。
// 直到右为null,就结束这层,返回上层。一直直到右边不为空再往右边探一个
res += serialByPre(head.left);
res += serialByPre(head.right);
return res;
}
BFS序列化
二叉树
二叉树的递归版前中后序
二叉树的非递归版前中后序
二叉树的BFS和DFS
BFS
public static void level(Node head) {
if (head == null) {
return;
}
//节点放队列里,队列是先进先出,可以保持节点从左往右遍历的顺序
Queue<Node> queue = new LinkedList<>();
queue.add(head);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.println(cur.value);
if (cur.left != null) {
queue.add(cur.left);
}
if (cur.right != null) {
queue.add(cur.right);
}
}
}
二叉树DFS的序列化和反序列化
序列化:DFS只是把sout改成操作,并且null不忽略
反序列化:前序正常,中序不能,后续队列里面顺序是左右中全压入栈顺序变成中右左方便父节点连接孩子节点
二叉树的BFS序列化和反序列化
*//序列化时需要完全按顺序复制节点,所以要加个队列
**//BFS本身就需要使用队列。
*public static Queue levelSerial(Node head) {
Queue ans = new LinkedList<>();
*//basecase
* if (head == null) {
ans.add(null);
} else {
ans.add(String.valueOf(head.value));
Queue queue = new LinkedList();
queue.add(head);
*//ans只进不出,queue就是正常的BFS
* while (!queue.isEmpty()) {
head = queue.poll(); *// head 父 子
* if (head.left != null) {
ans.add(String.valueOf(head.left.value));
queue.add(head.left);
} else {
ans.add(null);
}
if (head.right != null) {
ans.add(String.valueOf(head.right.value));
queue.add(head.right);
} else {
ans.add(null);
}
}
}
return ans;
}
public static Node buildByLevelQueue(Queue<String> levelList) {
if (levelList == null || levelList.size() == 0) {
return null;
}
Node head = generateNode(levelList.poll());
Queue<Node> queue = new LinkedList<Node>();
if (head != null) {
queue.add(head);
}
Node node = null;
while (!queue.isEmpty()) {
node = queue.poll();
node.left = generateNode(levelList.poll());
node.right = generateNode(levelList.poll());
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
return head;
}
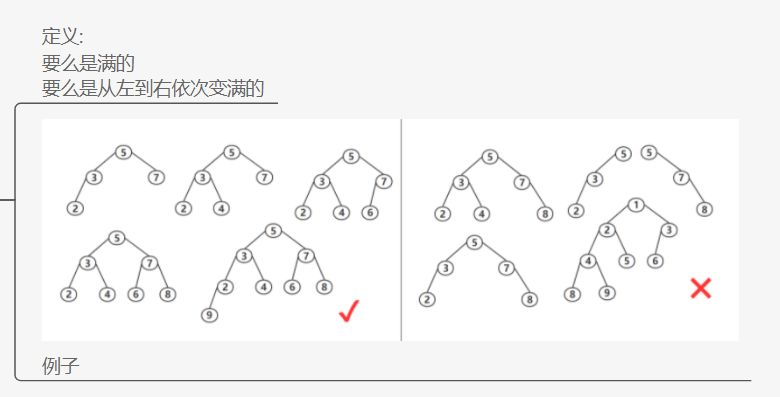
完全二叉树的定义
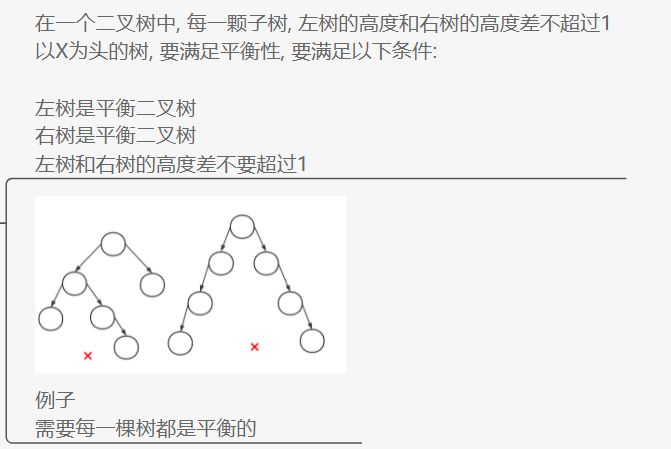
平衡二叉树
满二叉树的定义
2^L-1==N
二叉树的递归套路
1)假设以X节点为头,假设可以向X左树和X右树要任何信息
2)在上一步的假设下,讨论以X为头节点的树,得到答案的可能性(最重要)
3)列出所有可能性后,确定到底需要向左树和右树要什么样的信息
4)把左树信息和右树信息求全集,就是任何一棵子树都需要返回的信息S
5)递归函数都返回S,每一棵子树都这么要求
6)写代码,在代码中考虑如何把左树的信息和右树信息整合出整棵树的信息
Morris 二叉树遍历
原理:用左孩子的最右节点的右指针来标记cur节点是否走过
Morris的优点:空间复杂度优化为O (1)
Morris和递归遍历的区别:递归用栈来保存节点相关的信息。
流程:
到cur节点。if(没有左孩子){
则不会是通过左孩子的最右节点的右指针回到单前节点。所以一定是第一次来到当前节点
}
if (有左孩子){
则可能是第二次来到当前节点
if(左孩子的最右节点的右指针是指向当前节点)
说明当前是第二次来到cur,说明cur的左子树都遍历完了。所以cur往右孩子移。
因为题目给的树结构不能更改,所以要复原左孩子的最右节点的右指针指向null
if(左孩子的最右节点的右指针指向null)
说明当前是第一次来到cur,左子树还没遍历过。所以要遍历左子树
为了下次到cur的时候知道已经来过cur了,所以把cur的左孩子的最右节点的右指针指向cur
}
Morris遍历序:先到父节点,先左后右的遍历方式
有左孩子的树会遍历两次,没有的遍历一次
tip:根据左孩子的最右节点的右指针判断是不是第一次经过
改先序:if(没有左孩子)打印
else if(有左孩子&&第一次经过) 打印
else if(有左孩子&&不是第一次经过)
改中序:if(没有左孩子)打印
else if(有左孩子&&第一次经过)
else if(有左孩子&&不是第一次经过)打印
改后续:if(没有左孩子)
else if(有左孩子&&第一次经过)
else if(有左孩子&&不是第一次经过)逆序打印左树的右边界
问题:怎么逆序打印左树的右边界?
解决:压栈弹栈
缺点:空间复杂度不是o(1)
解决:先把链表逆序再打印,再逆序回来

public static void myMorris(Node head) {
if (head == null) {
return;
}
Node cur = head;
Node mostRight = null;
while (cur != null) {
mostRight = cur.left;
//有左树的情况
if (mostRight != null) {
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
//没有标记=》第一次来
if (mostRight.right == null) {
//System.out.print(cur.value + " ");
mostRight.right = cur;
cur = cur.left;
continue;
//有标记=》不是第一次来
} else {
//System.out.print(cur.value + " ");
mostRight.right = null;
//这里注意要先讲右指针置为null再倒序打印左树的右边界。不然会指向别处
//printEdge(cur.left);
cur = cur.right;
}
//没有左树的情况
}else if (mostRight == null){
//System.out.print(cur.value + " ");
cur = cur.right;
}
}
//因为遍历到整颗树的最右下节点就退出循环了。所以后序遍历补一个打印右边
//printEdge(head);
System.out.println();
}
Manacher 回文字符串
Manacher算法。查找最长回文字符串
问题:怎么查询最大回文字符串
解决:暴力方法。每个index位置循环往左右各指下一个比对
问题:只能查询到对称轴在某个index上的回文串。(查不到kkcc这样的回文)
解决:把每个数用#包起来(#k#k#c#c#)
问题:复杂度为O(N^2)
解决:Manacher算法 O(N)
Manacher
前置概念
回文半径,直径
回文半径数组
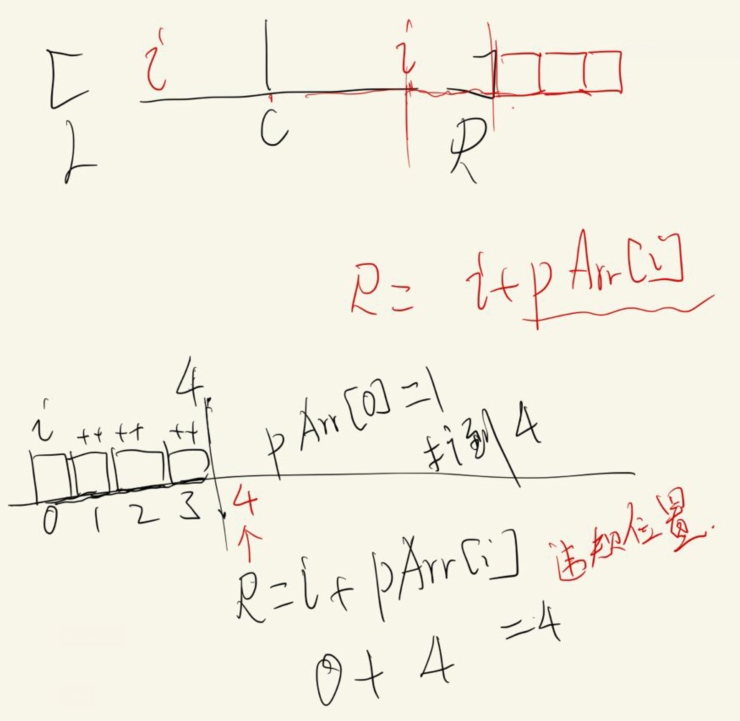
最右回文边界R
最右回文边界的中心C
流程:
来到i位置的时候两种可能
一、i在R的范围外
只能暴力验
二、i在R的范围内
i关于C的对称为j
1、如果j的回文左边界完全被C的回文左边界包围
则i=j
2、如果如果j的回文左边界超过C的左侧回文左边界
则i的回文范围到R
3、如果j的回文左边界刚好等于C的回文左边界
则i》=R,R之后的位置需要再验证

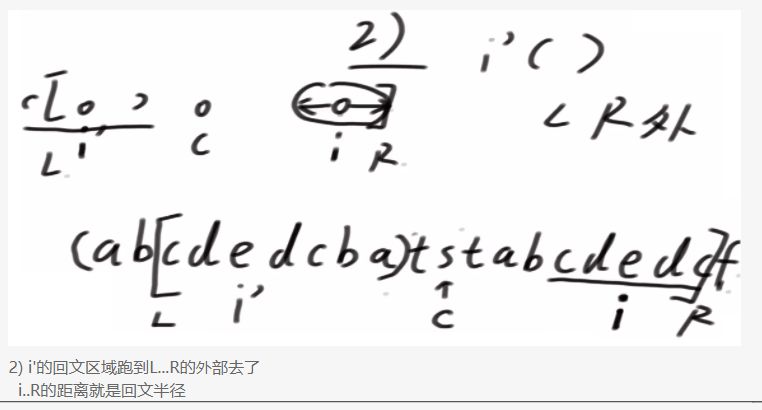

复杂度分析

代码

KMP的原理及实现
问题:求str1中的子串是否含有str2
解决:每个位置暴力遍历O(N*M)
问题:暴力方法时间复杂度高
解决:KMP算法O(N)
原理:KMP算法之前处理的信息可以为后面的处理提供参考
流程:先求辅助数组next [ ],每次对比i位置的是否相同则str1,2都往下推一位。如果不同则str2数组整体往后移next [index]位置。
问题:next [i]数组的含义?
答案:以str2中的i位置往前x位和str2首位往后数x位的字符串是相同的
问题:怎么快速的求next数组?
答案:next [i] 只依赖next [i-1],str2 [i]和 str2[next [i]+1]这三个数
str2 [i]:是i位置的字符
next [i-1]:是i-1位置和首位开始有多少位字符串是相同的
str2[next [i]+1]:是和以i-1结尾的字符串相对应的前缀字符串的结尾后一个字符串
流程:
nest [0]=-1;
nest [1]=0;
if (i位置和之前的前缀字符串后一个字符相同)
则next [i]=前位的值+1
else if( 对应字符不同&&现前缀数组中还有重复,部分还能往前跳)
跟next [ next [i] ]的下一位字符进行比较
else( 对应字符不同&& 前缀数组中已经没有重复的部分了,不能往前跳)
next [i]=0


问题:怎么证明next数组形成的复杂度
答案:i,i到cn的距离都是单调递增的。

bfprt算法
问题:无序数组中查找第k小
跟快排的区别:快排是随机选一个作为分度值的数,bfprt是讲究的选一个中位数
中位数挑选的过程:
向把数组中每五个数分成一组
每个组排序再提出中位数
一共N/5个中位数再提取出中位数。
此时的中位数一定≥3/10N的数,也一定≤3/10N的数
所以每次排序最差结果也能排除3/10N的数
双向链表 双端队列
双向链表实现双端队列
c3c3
双端链表实现双端的push和pop
双端队列 队列 栈
双端队列实现队列和栈
c3c3
图
1、由点集和边集组成
1、1点需要储存:出入度,id,edge的集合,next的集合
1、2边需要储存:from点,to点,weight
2、无向图本质上是相互的有向图
3、边上可能有权重
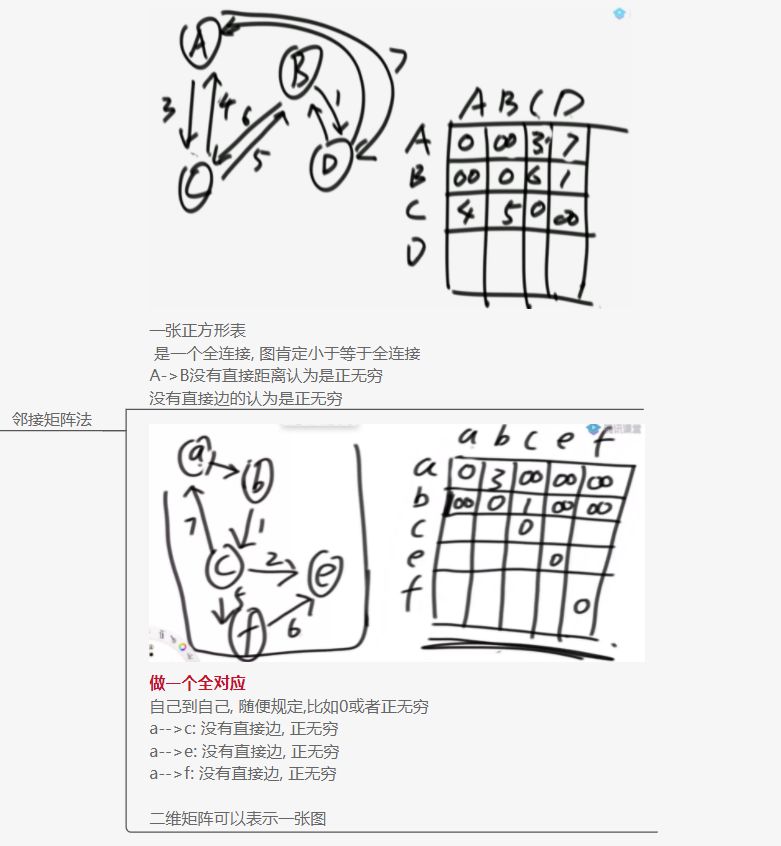
常见的图的表示方法
邻接表法
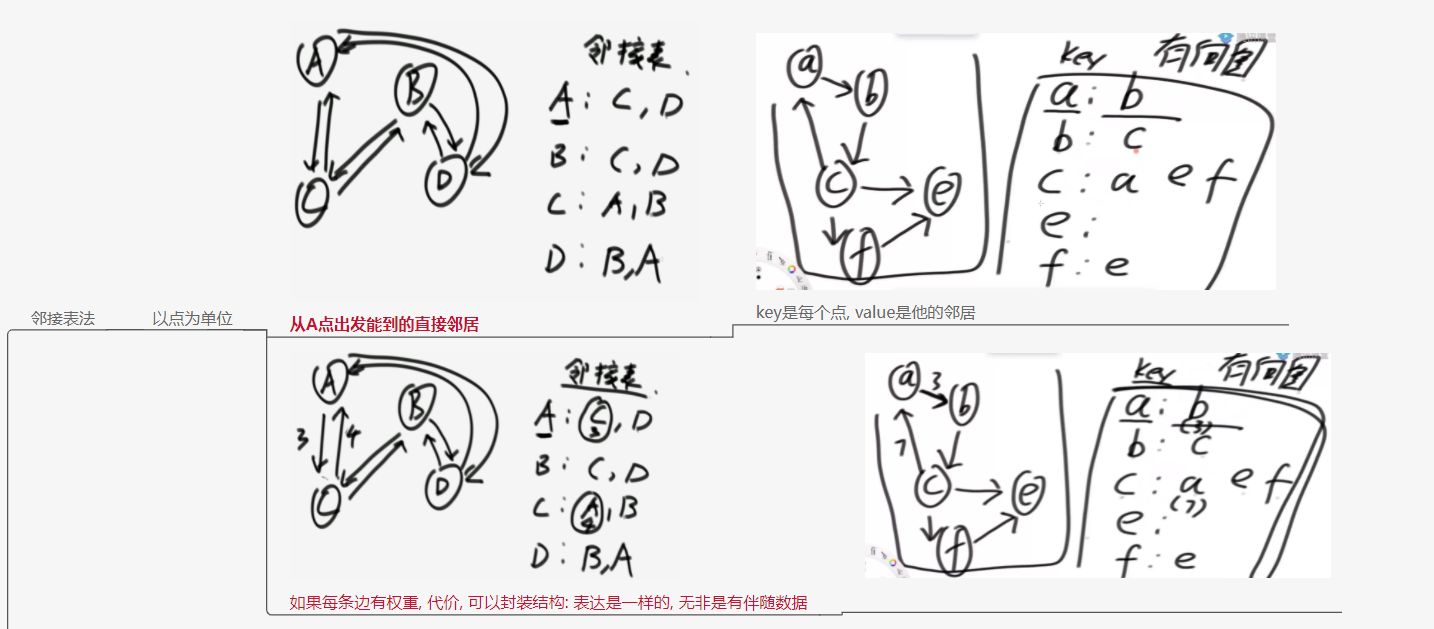
邻接矩阵法
图的统一表达结构
图有两类元素组成。点和边
点元素需要保存的信息:出入度(也是后面两集合的size),id(value),edges和nexts集合
边元素需要保存的信息:weight,from,to
图集合包含点和边集合(复杂结构用hashMap存储)
图接口转化
// matrix 所有的边
// N*3 的矩阵
// [weight, from节点上面的值,to节点上面的值]
//
// [ 5 , 0 , 7]
// [ 3 , 0, 1]
//
public static Graph createGraph(int[][] matrix) {
Graph graph = new Graph();
for (int i = 0; i < matrix.length; i++) {
// 拿到每一条边, matrix[i] =[ 3 , 0, 1]
int weight = matrix[i][0];
int from = matrix[i][1];
int to = matrix[i][2];
//如果图中没有包含from这个点
if (!graph.nodes.containsKey(from)) {
//创建点并且放入点集合中
graph.nodes.put(from, new Node(from));
}
//如果没有包含to这个点
if (!graph.nodes.containsKey(to)) {
graph.nodes.put(to, new Node(to));
}
//取出边from和to的点
Node fromNode = graph.nodes.get(from);
Node toNode = graph.nodes.get(to);
//新建边,因为每条边都是全新的所以都要新建
Edge newEdge = new Edge(weight, fromNode, toNode);
//接着修改点的信息
//出度,入度,nexts集合,edges集合
fromNode.nexts.add(toNode);
fromNode.out++;
toNode.in++;
fromNode.edges.add(newEdge);
graph.edges.add(newEdge);
}
//转换好graph后返回
return graph;
}
图的dfs
和二叉树dfs的区别:
1、一个节点可以指向多个节点
解决:用循环结构代替写死的递归指向
2、一个节点可能会被多个节点指向
问题:一个节点的中转次数不定
解决:保存整条路径
3、可能有环
解决:用hashSet去重
流程:创建set和stack
循环stack.pop
while(存在没走过的子节点)
栈中压入父和子节点,set中也加入
(压栈的时候打印next)
这里发现了就要break。不能玩成bfs
这样就可以先一条路深入,遇阻回退且不重复
图的BFS
每个节点的子节点去重后放入队列中

图的拓扑排序(编译顺序、依赖顺序)(有向无环图)
原理:先找出一批入度为0的节点(入度为0说明没有依赖其他节点)再减少该节点next列表的一个入度。循环

最小生成树Prim(用set)
图 树 并查集
原理:每次只根据当前遍历过的边挑选权重小的。逐渐拓展挑选范围,用set集合防重
解释:因为:每个节点都需要连通,然后为了连通每个节点的代价为:绕路+该节点的最小边。最小边可直接得知,因为每个节点都需要连通所以绕路成本为0
过程:遍历当前点的边加入小根堆。再取出最小的边,双端不重复就选上

Dijkstra 算法(一个点到其他所有点的最短路径)
图 路径
点A到另点B的距离为 { A到所有节点最短的边-》之后每个节点再递归处理,不重复处理节点}
问题:以什么顺序递归处理节点?
答案:从当前路径最小的节点开始遍历。
因为如果A-》B有最短路径,一定是之间各个节点之间连接的最短路径,这样从最短的开始遍历不会错过,不用回退。遍历过的节点锁起来不更改
问题:怎么获取当前路径最小的节点?
解决:hashMap里存着所有边的距离,遍历
缺点:复杂度为o(N)
解决:用堆,直接pop
问题:部分节点会找到更优路径需要更改距离,堆改值需要遍历
解决:用加强堆
问题:怎么实现锁机制
解决:用set标记
改进:一开始在点集,遍历完加入结果集
// 改进后的dijkstra算法
// 从head出发,所有head能到达的节点,生成到达每个节点的最小路径记录并返回
public static HashMap<Node, Integer> dijkstra2(Node head, int size) {
NodeHeap nodeHeap = new NodeHeap(size);
//addOrUpdateOrIgnore这方法直接把三种情况封装好了,主函数不用再判断了
nodeHeap.addOrUpdateOrIgnore(head, 0);
//结果集
HashMap<Node, Integer> result = new HashMap<>();
//循环弹出路径最短的节点然后遍历更新
while (!nodeHeap.isEmpty()) {
//先从点集合pop出,遍历完成后加入的是结果集,就不会重复。
//省了加set的参数时间
NodeRecord record = nodeHeap.pop();
Node cur = record.node;
int distance = record.distance;
//遍历更新
for (Edge edge : cur.edges) {
nodeHeap.addOrUpdateOrIgnore(edge.to, edge.weight + distance);
}
result.put(cur, distance);
}
return result;
}
堆
堆的heapify
private void heapify(int[] arr, int index, int heapSize) { //获取左孩子 int left = index * 2 + 1; //因为堆是完全二叉树所以没有左就没有孩子直接跳过 //这里用while不用if是因为可能会不断下沉 while (left < heapSize) { // 把较大孩子的下标,给largest //先判断右孩子是否超过边界 //没有超过则把两孩子中大的孩子的index赋值给largest int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left; //子树再和父节点比较 largest = arr[largest] > arr[index] ? largest : index; //如果父节点比子树大则退出循环 if (largest == index) { break; } // index和较大孩子,要互换 //如果父节点比子节点大在上一步就已经break了 //交换节点 swap(arr, largest, index); //交换坐标为下次循环做准备 index = largest; left = index * 2 + 1; }}
加强堆
堆的缺点:不能根据value删除元素只能遍历
解决:引入反向索引表,记录每个kv的对应关系
难点:每次堆中元素位置发生变化都需要同时操作两张表(数组和hashMap)
操作的注意点:
pop():/push():增删反向索引表
remove():先获取要删除的obj和堆末尾的元素的index和obj。
先在堆中断链末尾元素,再判断obj和原末尾。相同则不处理,
重新设置双表的值
数组(堆):不同则把原末尾元素放被删除的元素在数组中的位置。
覆盖反向索引表内的信息
再resign()整理堆
resign():对一个位置分别执行heapinsert()和heapify()
swag():先获取两元素在两表中的值,再覆盖
public class HeapGreater<T> { private ArrayList<T> heap; private HashMap<T, Integer> indexMap; private int heapSize; private Comparator<? super T> comp; public HeapGreater(Comparator<T> c) { //这是堆结构 heap = new ArrayList<>(); //这是反向索引表 indexMap = new HashMap<>(); heapSize = 0; //比较器 comp = c; } public boolean isEmpty() { return heapSize == 0; } public int size() { return heapSize; } //直接在反向索引表中查询 public boolean contains(T obj) { return indexMap.containsKey(obj); } public T peek() { return heap.get(0); } public void push(T obj) { //分别在堆中和反向索引表中加入obj,后再进行堆化 heap.add(obj); //反向索引表 indexMap.put(obj, heapSize); heapInsert(heapSize++); } public T pop() { //把首位移到最后,再在两表中删除末尾的数 //因为现在是首位是乱的所以调用heapify T ans = heap.get(0); swap(0, heapSize - 1); indexMap.remove(ans); //这里用的是动态数组所以不是减少limit来删除,而是要调用remove方法删除 heap.remove(--heapSize); heapify(0); return ans; } public void remove(T obj) { //先分情况obj是不是最后一个数 //是的话在两表中删除就行了 //不是的话要和末位在两表中先交换再删除 //先获取需要heap末尾的元素 T replace = heap.get(heapSize - 1); //根据反向索引表获取需要删除的元素的下标 int index = indexMap.get(obj); //先在反向索引表中删除对应的元素 indexMap.remove(obj); //再在堆中删除末尾元素,并且断连 heap.remove(--heapSize); //如果需要删除的元素不是末尾元素,则需要重新设置堆和map中的值,并且堆化 if (obj != replace) { heap.set(index, replace); indexMap.put(replace, index); resign(replace); } } //调整obj位置的值 public void resign(T obj) { heapInsert(indexMap.get(obj)); heapify(indexMap.get(obj)); } // 请返回堆上的所有元素 public List<T> getAllElements() { List<T> ans = new ArrayList<>(); for (T c : heap) { ans.add(c); } return ans; } private void heapInsert(int index) { while (comp.compare(heap.get(index), heap.get((index - 1) / 2)) < 0) { swap(index, (index - 1) / 2); index = (index - 1) / 2; } } private void heapify(int index) { int left = index * 2 + 1; while (left < heapSize) { int best = left + 1 < heapSize && comp.compare(heap.get(left + 1), heap.get(left)) < 0 ? (left + 1) : left; best = comp.compare(heap.get(best), heap.get(index)) < 0 ? best : index; if (best == index) { break; } swap(best, index); //往后推 index = best; left = index * 2 + 1; } } private void swap(int i, int j) { //swap这里注意两表都得修改 T o1 = heap.get(i); T o2 = heap.get(j); heap.set(i, o2); heap.set(j, o1); indexMap.put(o2, i); indexMap.put(o1, j); }}
堆的heapinsert
private void heapInsert(int[] arr, int index) { //如果子树比父节点大的话 //这里包含了0边界 while (arr[index] > arr[(index - 1) / 2]) { swap(arr, index, (index - 1) / 2); //然后再转到父位置 index = (index - 1) / 2; }}
并查集
并查集特点
特点:查询为O(1),合并为O(n)
1)每个节点都有一条往上指的指针
2)节点a往上找到的头节点,叫做a所在集合的代表节点
3)查询x和y是否属于同一个集合,就是看看找到的代表节点是不是一个
4)把x和y各自所在集合的所有点合并成一个集合,只需要小集合的代表点挂在大集合的代表点的下方即可
原理:查询时以头结点是否相同为依据判断是否是一个集合
合并时把小的集合的头节点的父亲设置为大的集合的头节点
和查询两条链表的区别:差并集利用hashMap查询的时间为o(1)的特性把链表扁平化了。每次只要查有限个就能查询到头节点。
和在hashMap中储存v:组号的区别:如果合并组则所有该组的元素对应的kv都得改。但是并查集只需要修改头节点的“指向”就行。
这里的结构类似于所有kv中一端指向组号的k,只要更改组号的v就可以合并。但是这样就不能在查询时获得本组的其他元素,无法做到扁平化。查并集在此基础上用链表的形式可以获得路径过长的元素扁平化处理,以免复杂度增长到o(n)
例题:真实用户的数量,朋友圈,岛问题1/2,
static class MyUnionFind { //并查集需要一个father private int[] father; //还需要个路径数组 private int[] path; //和一个size数组用来判断谁依附谁 private int[] size; //还需要记录头节点(集合数目)//todo 为什么? private int sizeGather; public MyUnionFind(int N) { father = new int[N]; path = new int[N]; size = new int[N]; sizeGather = N; for (int i = 0; i < N; i++) { father[i] = i; size[i] = 1; } } public int find(int node) { int i=0; //遍历寻找头节点 while (father[node] != node) { path[i++] = node; node = father[node]; } //把路径上的节点的头节点设置为“最终的”头节点 for (i--; i>=0;i--) { father[path[i]]=node; } return node; } public int getSizeGather() { return sizeGather; } //合并两个节点所属的集合 public void union(int nodeA,int nodeB) { //先判断节点是不是一个集合 int findA = find(nodeA); int findB = find(nodeB); if ( findA == findB) return; int maxNode = size[findA] >= size[findB] ? findA :findB; int minNode = size[findA] < size[findB] ? findA : findB; father[minNode] = maxNode; size[maxNode] += size[minNode]; size[minNode]=0; sizeGather--; } }
排序
归并排序
原理:先进行任务拆分,左边调黑盒排序,右边也调黑盒排序。(注意中间端点不能相交)。左右都排完序调用merge
merge:左右数组各有个指针,再新建个数组。比大小复制到新数组,最后再把剩余的复制到新数组。新数组覆盖老数组的相应位置
整体是递归,左边排好序,右边再排,然后merge排左右
复杂度:merge过程中指针不后退利用了之前排序的结果

非递归的归并排序
不用建栈模拟递归。而使“宽度拆分”
因为原结构是数组所以可以在第一层就看到所有元素。可以不断调整操作的覆盖范围。如果是链表结果就不能调整操作元素的范围。
过程:每次循环都增加覆盖范围,用这个范围遍历整个数组。每次都只merge覆盖范围内的两段数组
特点:用步长(范围)替换了递归取L和R
快排
basecase:左右指针碰撞
随机一个位置的数和最后互换,拿最后的数和数组其他位置的数组对比,利用左右指针的移动划分大,小区。接着递归处理0L指针,Rlen-1的两区间
(非递归版本就是手动压栈,在函数中用while循环pop栈,本来调用递归的地方push栈)
桶排序(基数排序)
特点:对原数据的格式有要求(要求区分的种类要少,比如数字以0~9为区分度)
原理:按某位的大小依次放桶里(要求稳定性)之后再按桶的顺序倒出,位往左移一位。因为数字高位的权重比低位高阶,所以低位先排序再排高位,整体区间的低位会被打乱,高位排序后不会。
原理:桶排序
有分治的思想,每次遍历桶与桶之间只关注当前位的数,同一个桶内只关心保持原数组中的先后顺序
public static void countSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int[] bucket = new int[max + 1];
for (int i = 0; i < arr.length; i++) {
bucket[arr[i]]++;
}
int i = 0;
for (int j = 0; j < bucket.length; j++) {
while (bucket[j]-- > 0) {
arr[i++] = j;
}
}
} 特殊化:基数排序
private static int[] raduxSort2(int[] arr, int left, int right, int digit) { final int num = 10; int[] help = new int[right - left + 1]; //这是出入桶的次数,也是本次排大小的数位 //basecase:从第一位开始比较,比到最高位 for (int d = 1; d <= digit; d++) { int[] count = new int[num]; //这是每次遍历算某位数出现的次数,为了下文能处理后推算出该放置的index for (int i = 0; i < arr.length; i++) { int dNum = getNumByDigit(arr[i], d); count[dNum]++; } //遍历处理count数组,原本数组储存的是某位数出现的次数,现在变成某位的数该放置的index for (int i = 1; i < count.length; i++) { count[i] += count[i - 1]; } //把arr放入help1的相应位置 for (int i = arr.length-1; i >= 0; i--) { int dNum = getNumByDigit(arr[i], d); count[dNum]--; help[count[dNum]] = arr[i]; } //把help再倒回arr for (int i = 0; i < arr.length; i++) { arr[i] = help[i]; } } return arr;}
排序算法的稳定性
环形数组实现队列(实现栈简单)
设置两个指针,一个指向pop位,一个指向push位。 指针移动封装到nextIndex里。
nextIndex还包括位置越界的判断。个数越界的判断用size。(废弃两个指针一追一赶的思路。转为两指针各自往前不会退,size超了就是出错)
具体过程:
size++/–
设置or取出对应位置的值
栈
实现最小栈
:实现一个特殊的栈,在基本功能的基础上,再实现返回栈中最小元素的功能
1)pop、push、getMin操作的时间复杂度都是 O(1)。
2)设计的栈类型可以使用现成的栈结构。
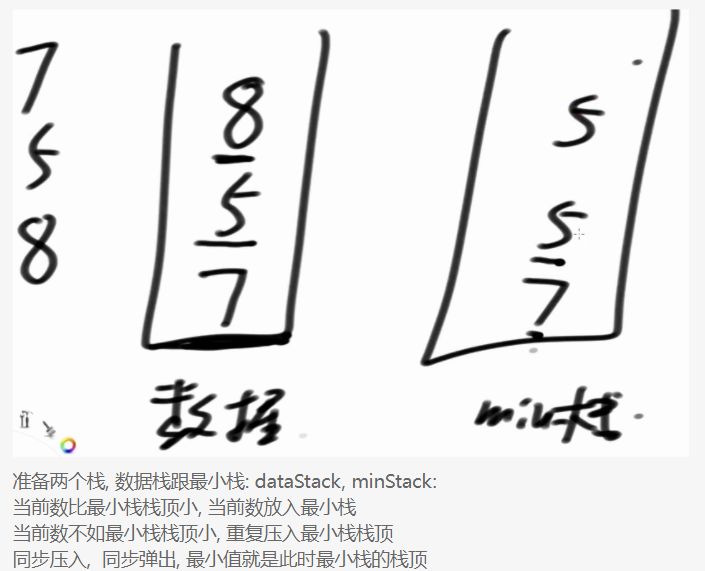
单调栈
目的:以o(N)的复杂度获得数组中最靠近且比index小的数
过程:每个数和栈顶的数进行比较(栈底到栈顶由小到大),如果该数比栈顶的数大则直接push,小则pop出栈顶元素处理完再压入index位置的数
处理:pop出的数在表中记录现在栈顶的数为左小,index位置的数为右小。
遍历完数组再处理栈中的数
问题:数组中有相同的数怎么处理?
解决:在栈中每个数以数组的形式储存。如果index的数跟栈顶的一样则加入数组尾部。如果index小于栈顶,则弹出整个数组。后面记录左右小的位置的时候都取数组的末尾(需要取首位的情况都是值为-1)
问题:为什么不用链表储存,而是用数组
答案:因为要频繁的取最后一个数,链表要遍历,慢
无重复值版
public static int[][] getNearLessNoRepeat(int[] arr) { //先建栈和返回的数组 int[][] res = new int[arr.length][2]; // 这里可用下标对上所以不用多额外一列来储存下标 Stack<Integer> stack = new Stack<>(); // 当遍历到i位置的数,arr[i] for (int index = 0; index < arr.length; index++) { //判断要不要弹出 //栈中储存的是下标 //arr[stack.peek()]要取出栈中对应的真实的数来进行比较 while (!stack.isEmpty() && arr[stack.peek()] > arr[index]) { //先弹出栈顶元素,再塞左右数据 int j = stack.pop(); int leftLessIndex = stack.isEmpty() ? -1 : stack.peek(); res[j][0] = leftLessIndex; res[j][1] = index; } //压入最新的数据 stack.push(index); } //遍历完数组再弹栈 while (!stack.isEmpty()) { int j = stack.pop(); int leftLessIndex = stack.isEmpty() ? -1 : stack.peek(); res[j][0] = leftLessIndex; res[j][1] = -1; } return res;}
有重复值,链表版
public static int[][] getNearLess(int[] arr) { int[][] res = new int[arr.length][2]; //这里栈储存的是链表头节点 Stack<List<Integer>> stack = new Stack<>(); for (int index = 0; index < arr.length; index++) { // index -> arr[index] 进栈 //stack中是链表 //stack.peek()出链表 //stack.peek().get(0)才是int //下个位置的值比栈顶的小 while (!stack.isEmpty() && arr[stack.peek().get(0)] > arr[index]) { List<Integer> popIs = stack.pop(); int leftLessIndex = stack.isEmpty() ? -1 : stack.peek().get(stack.peek().size() - 1); //遍历整个链表设置返回信息 //链表是int相同所以被串起来,但是每个的index不同 for (Integer popi : popIs) { res[popi][0] = leftLessIndex; res[popi][1] = index; } //这里不压栈,后面判断的时候再压 //因为可能不止弹一次栈,但只会压一次栈 } //当堆顶的链表和下一个位置的int相同的时候 if (!stack.isEmpty() && arr[stack.peek().get(0)] == arr[index]) { stack.peek().add(Integer.valueOf(index)); //差别就是等于时只要连上就行,大于时要新建链表再放入 } else {//新值比栈顶大时 //新建个链表 ArrayList<Integer> list = new ArrayList<>(); //把index加入链表 list.add(index); //压栈 stack.push(list); } } //遍历完数组后栈不为空 while (!stack.isEmpty()) { List<Integer> popIs = stack.pop(); int leftLessIndex = stack.isEmpty() ? -1 : stack.peek().get(stack.peek().size() - 1); //一条链表加的值都是一样的 for (Integer popi : popIs) { res[popi][0] = leftLessIndex; res[popi][1] = -1; } } return res;}
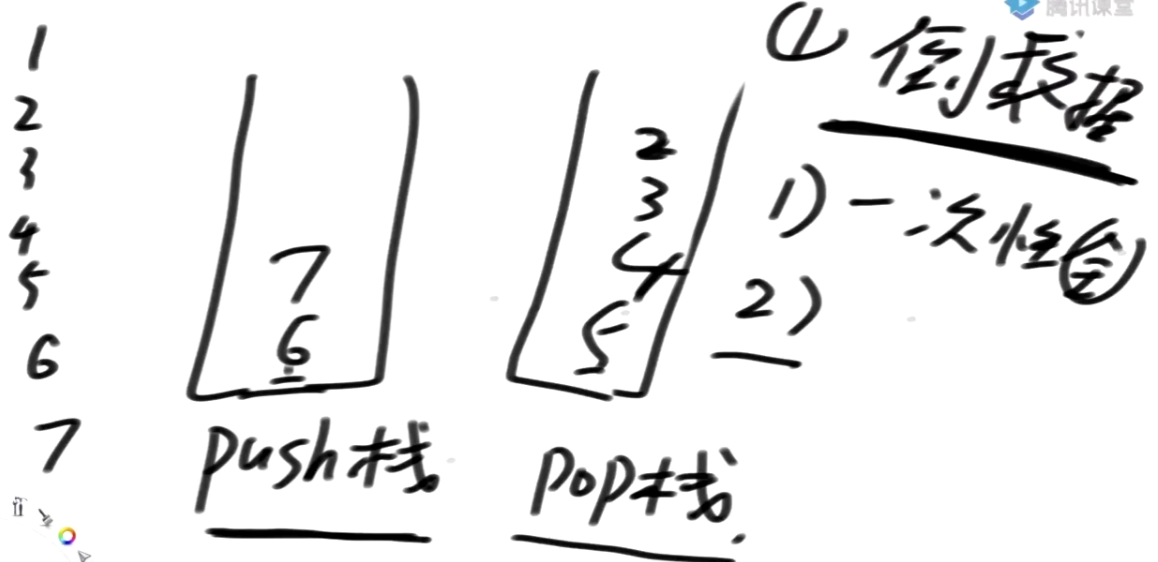
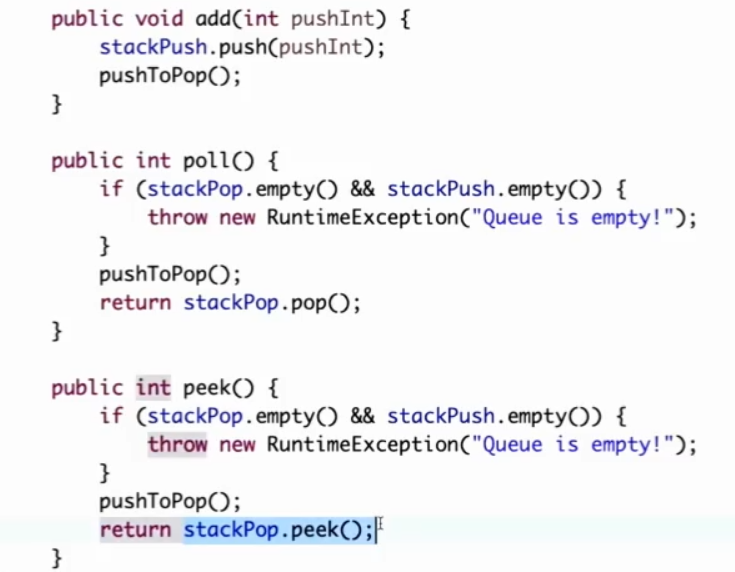
用栈实现队列
栈 队列
目的:先出顶部的元素改为先出底部的元素(对栈来说)
所以只要把除了顶部的元素倒到栈2中再pop出栈1剩的一个元素就行
难点:维护元素的先后顺序
初版:每次pop都先倒到栈2中,pop出栈2的首位。再把栈2的倒入栈1
缺点:每次pop都是O(N)
问题:为了保持原数组的顺序关系,每次都需要遍历数组再能得到需要的数。后面不能利用到前面的结论
思想:一个栈只接收,一个栈只弹出
维护顺序的原则:
1.push栈到pop栈要一次性倒完
2.只要pop栈里有数据,push栈就不能往pop栈里倒数据


用栈实现BFS(栈转队列)
用队列实现DFS(队列转栈)
栈 队列
树
前缀树
s前缀树节点有26条路,路径为字母,节点上储存pass和end
操作分为更改节点属性和寻址
寻址:判断某个节点的路径列表包不包含下个路径的序号。判空之后的操作各不同
CRUD对应不同的更改节点属性pass和end
java删除时只要断开指向就行,JVM会回收
1)单个字符串中,字符从前到后的加到一棵多叉树上 2)字符放在路上,节点上有专属的数据项(常见的是pass和end值) 3)所有样本都这样添加,如果没有路就新建,如有路就复用 4)沿途节点的pass值增加1,每个字符串结束时来到的节点end值增加1
前缀树的功能
1)void insert(String str) 添加某个字符串,可以重复添加,每次算1个2)int search(String str) 查询某个字符串在结构中还有几个3) void delete(String str) 删掉某个字符串,可以重复删除,每次算1个4)int prefixNumber(String str) 查询有多少个字符串,是以str做前缀的
public static class Trie1 { private Node1 root; public Trie1() { root = new Node1(); } public void insert(String word) { //判断字符是否有效 if (word == null) { return; } //把string改成数组后面好拆分 char[] str = word.toCharArray(); //获取树的根节点 Node1 node = root; //沿途的pass++ node.pass++; //对应通路的编号 int path = 0; for (int i = 0; i < str.length; i++) { // 从左往右遍历字符 path = str[i] - 'a'; // 由字符,对应成走向哪条路 if (node.nexts[path] == null) { node.nexts[path] = new Node1(); } node = node.nexts[path]; node.pass++; } node.end++; } public void delete(String word) { if (search(word) != 0) { char[] chs = word.toCharArray(); Node1 node = root; node.pass--; int path = 0; for (int i = 0; i < chs.length; i++) { path = chs[i] - 'a'; if (--node.nexts[path].pass == 0) { node.nexts[path] = null; return; } node = node.nexts[path]; } node.end--; } } // word这个单词之前加入过几次 public int search(String word) { if (word == null) { return 0; } char[] chs = word.toCharArray(); Node1 node = root; int index = 0; for (int i = 0; i < chs.length; i++) { index = chs[i] - 'a'; if (node.nexts[index] == null) { return 0; } node = node.nexts[index]; } return node.end; } // 所有加入的字符串中,有几个是以pre这个字符串作为前缀的 public int prefixNumber(String pre) { if (pre == null) { return 0; } char[] chs = pre.toCharArray(); Node1 node = root; int index = 0; for (int i = 0; i < chs.length; i++) { index = chs[i] - 'a'; if (node.nexts[index] == null) { return 0; } node = node.nexts[index]; } return node.pass; }}
滑动窗口
滑动窗口求范围内的最大/小值
问题:求窗口范围内的最大值
解决:每个窗口都遍历
缺点:复杂度高
解决:滑动窗口
双端队列的根本含义:如果让窗口依次缩小,哪些位置会成为窗口内的最大值
队列头大尾小
流程:到index位置时和队列尾部比较。如果比尾部小则直接加入队列,大则弹出队尾元素,直到比队尾小时再加入队尾
队头为index位置的答案
if ( 队头元素超过窗口左边界)
弹出队头
public static int[] getMaxWindow(int[] arr, int w) { if (arr == null || w < 1 || arr.length < w) { return null; } //双端队列储存窗口范围内的最大值 LinkedList<Integer> qmax = new LinkedList<Integer>(); //结果数组 int[] res = new int[arr.length - w + 1]; //res结果数组的指针 int index = 0; for (int R = 0; R < arr.length; R++) { while (!qmax.isEmpty() && arr[qmax.peekLast()] <= arr[R]) { qmax.pollLast(); } //双端队列储存的是index不是值信息 qmax.addLast(R); //根据R指针和窗口长度判断队列中最左边(最大)的数是否出队列 if (qmax.peekFirst() == R - w) { qmax.pollFirst(); } //原数组后续不足窗口范围个数的时候 if (R >= w - 1) { res[index++] = arr[qmax.peekFirst()]; } } return res;}
线段树
线段树
主要是三个操作,范围累加,范围查询,范围更新。(递归版)
暴力遍历都需要O( N),但是线段树只要logN
配置:(数组小标从1开始方便下标的转化),(存放树结构的数组长度为4N)
特点:
1、用了树状结构,由大到小的颗粒度处理大幅减少了处理的操作次数。
数组的颗粒度是不变且最小的
2、生成线段树的时候算L~R的累加和只使用 Lmid+midL这两个数。不是通过遍历累加所以整体做到N的复杂度。(但是这样用二分法累加不像遍历累加可以控制细致的控制左右边界,而且只有大量重复操作时有前置结果可以利用)
3、范围累加时使用懒加载。减少树形结构的下沉层数(只减少常数时间)
4、因为更新的优先级大于累加,所以每次操作需要注意优先级。而且需要而外增加标志位来标识update数组某位的有效性
函数
一、build() 先构建累加和树O(N)
二、query()查询
三、add()累加
四、query()更新
五、pushDown()父节点向左右子节点分发父节点的懒加载和更新任务
六、pushUp() 父节点统计左右子节点的sum值
build()
思路:递归函数,index位置上的lr的sum数等于lm+m~r的sum值
basecase:l==r时 sum的值等于对应arr的值
// 在初始化阶段,先把sum数组,填好// 在arr[l~r]范围上,去build,1~N,// rt : 这个范围在sum中的下标public void build(int l, int r, int rt) { if (l == r) { sum[rt] = arr[l]; return; } int mid = (l + r) >> 1; build(l, mid, rt << 1); build(mid + 1, r, rt << 1 | 1); pushUp(rt);}
//to do
蓄水池算法
目的:针对一个流输入持续随机挑选出其中的k个
原理:第i个数有 k/i的概率被选中。如果被选中则从池中弹出一个数,每个数有1/k的概念被弹出

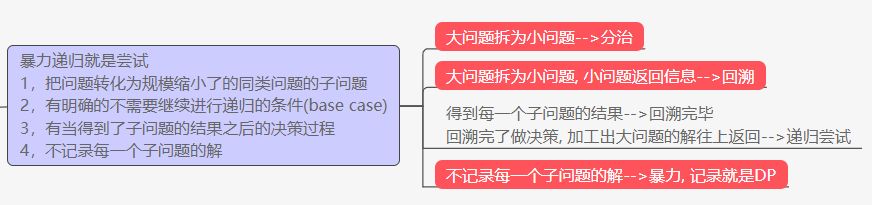
递归
递归的思路


逆序栈,使用递归不额外申请空间
思路:创建一个函数popFromBottom()弹出栈底元素。
在主函数递归popFromBottom()获取栈底元素,栈为空后再push之前获取的栈底元素。
popFromBottom():弹出栈底元素。
原理:每层都移除当前栈顶元素并且返回下层的返回值,再把当前栈顶push回去。
basecase,pop后为空就返回pop值(原栈底)
主函数是从下到上取元素,所以push回去的时候元素变为倒序
删除链表中给定的值注意判断是否删除头节点
链表
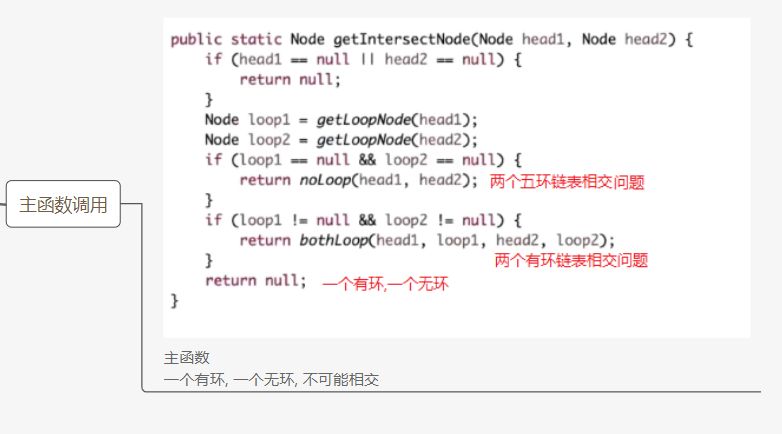
判断链表有无环(找出链表的入环节点)
无环链表怎么判断时候相交(以及相交节点)
各自遍历并且记录步数。如果最后一个节点相同则长链表先走差值的步数,然后再同时走会相遇

两个有or无环链表找第一个相遇节点
四种情况

先拿到各自的入环节点if(两节点相同)则是入环前就相交用无环链表的解法(可能在入环节点相交)
else(两节点不同)。有两种可能,共环和不共环
其中不共环肯定不相交。共环时一个节点遍历一圈如果先遇到另一个则是共环,先遇到自己说明不共环
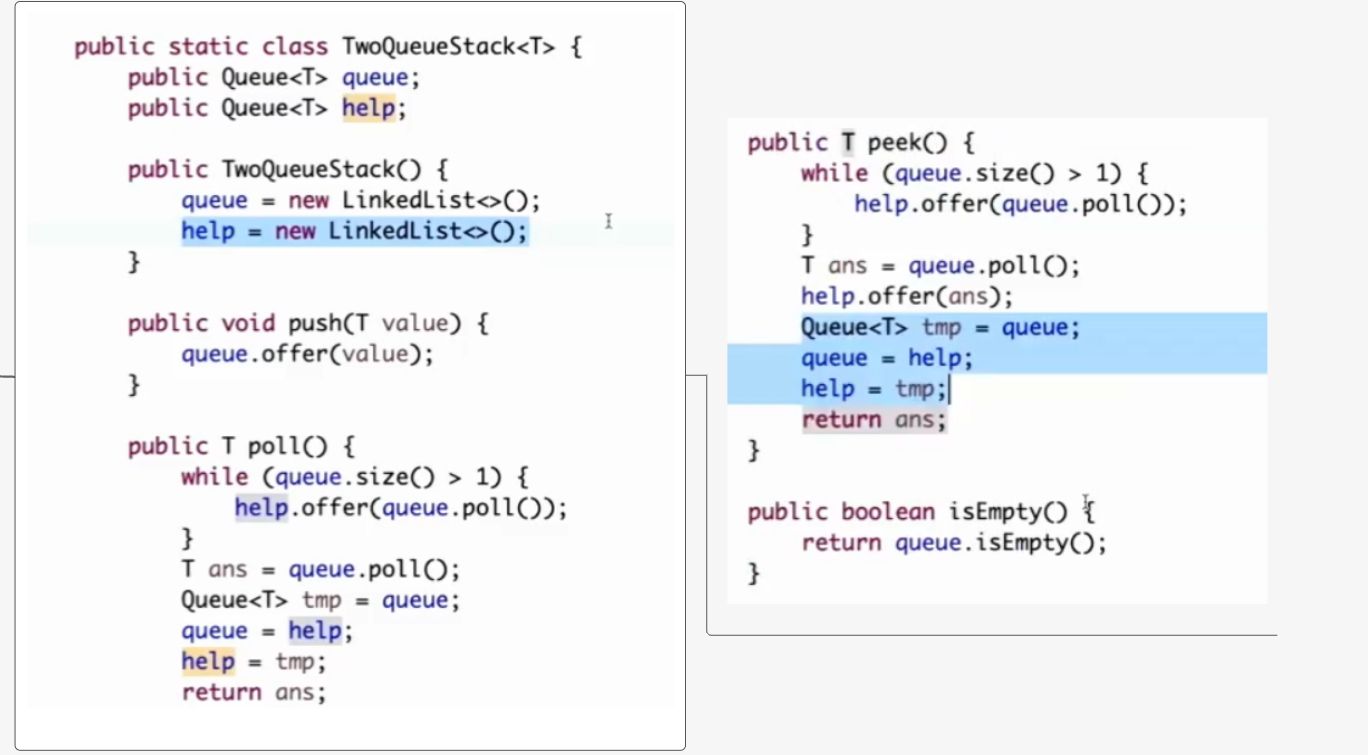
队列
用队列实现栈(简单)
目的:把队尾的元素弹出 操作:两个队列来回倒,一个队列只剩一个的时候再poll出 注意有个交换队列地址引用的行为

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









