







05-计算机指令:让我们试试用纸带编程
在软硬件接口中,CPU帮我们做了什么事?
-
从硬件的角度来看,CPU就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各 种各样的处理逻辑。
-
从软件工程师的角度来讲,CPU就是一个执行各种计算机指令的逻辑机器。
计算机指令(Instruction Code), CPU支持的语言,就是计算机指令 集,英文叫Instruction Set。
从编译到汇编,代码怎么变成机器码?
我们需要把整个程序翻译成一个汇编语言的程序,这个过程我们一般叫编译成汇编代码。 针对汇编代码,我们可以再用汇编器翻译成机器码
汇编语言(ASM,Assembly Language),编译(Compile),汇编器(Assembler),机器码(Machine Code)
解析指令和机器码
常见的指令分为五大类。
- 第一类是算术类指令。我们的加减乘除,在CPU层面,都会变成一条条算术类指令。
- 第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。
- 第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。
- 第四类是条件分支类指令。日常我们写的“if/else”,其实都是条件分支类指令。
- 第五类是无条件跳转指令。写一些大一点的程序,我们常常需要写一些函数或者方法。在调用函数的时 候,其实就是发起了一个无条件跳转指令


MIPS的指令是一个32位的整数,高6位叫操作码(Opcode),也就是代表这条指令具体是一条什么样的指 令,剩下的26位有三种格式,分别是R、I和J。
我以一个简单的加法算术指令add $t0, $s1, $s2,为例
对应的MIPS指令里opcode是0,rs代表第一个寄存器s1的地址是17,rt代表第二个寄存器s2的地址是18,rd 代表目标的临时寄存器t0的地址,是8。因为不是位移操作,所以位移量是0。

总结延伸
06-指令跳转:原来if…else就是goto
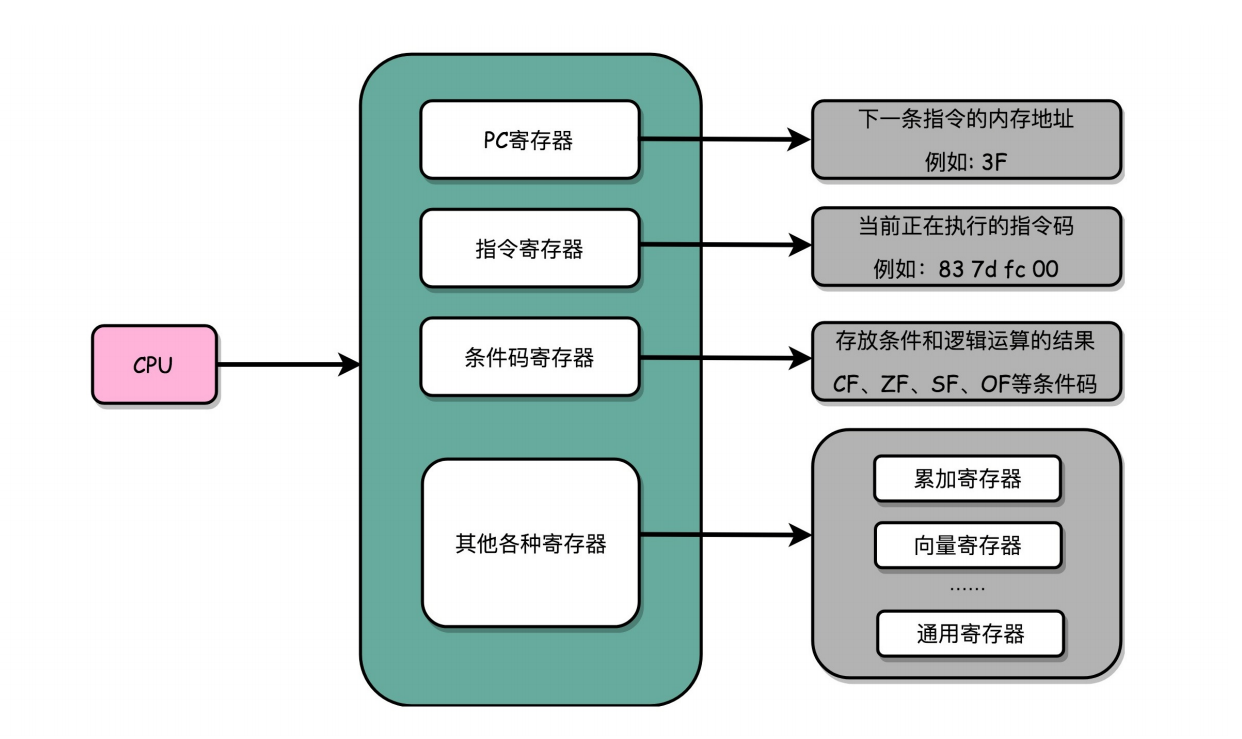
CPU是如何执行指令的?
逻辑上,我们可以认为,CPU其实就是由一 堆寄存器组成的。而寄存器就是CPU内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单 电路。

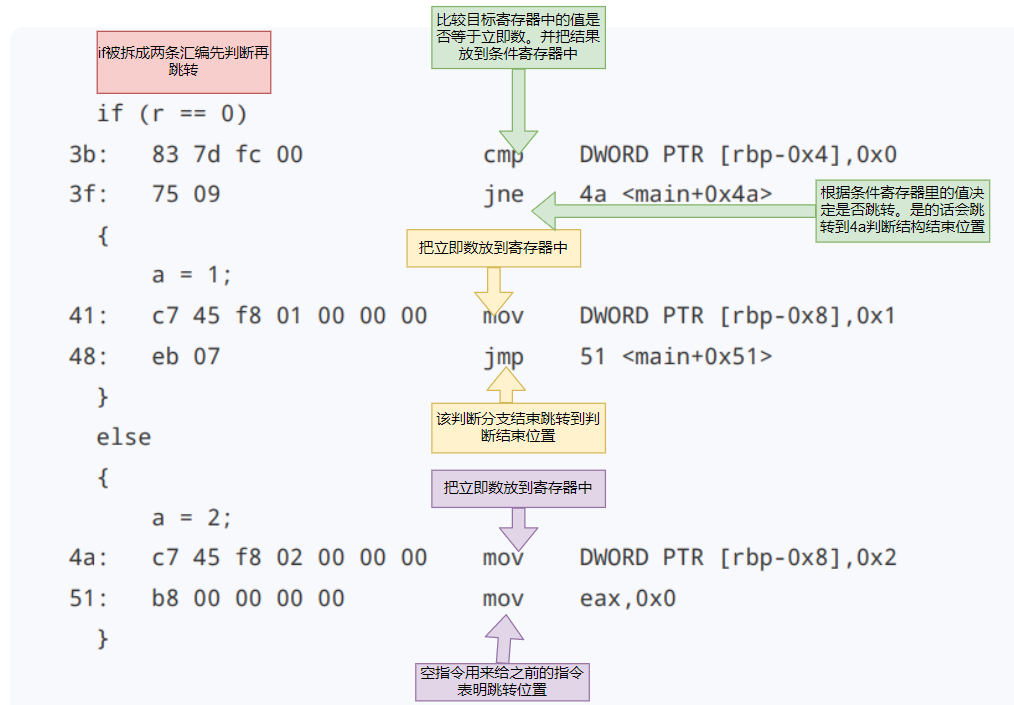
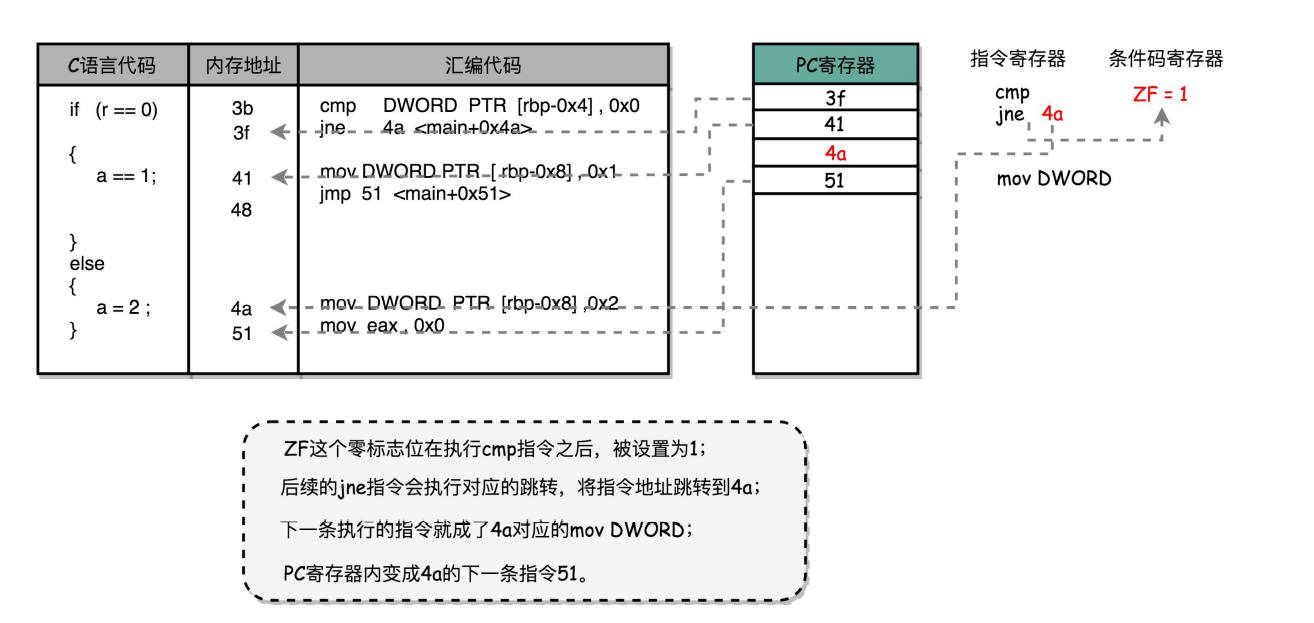
从if…else来看程序的执行和跳转
// test.c
#include <time.h>
#include <stdlib.h>
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
}
如何通过if…else和goto来实现循环?
int main()
{
int a = 0;
for (int i = 0; i < 3; i++)
{
a += i;
}
}

循环结构本质上是条件判断+跳转。for是先初始化计步器后跳转到循环体,循环体结尾有判断+跳转。dowhile则不需要先跳转到循环体这一步
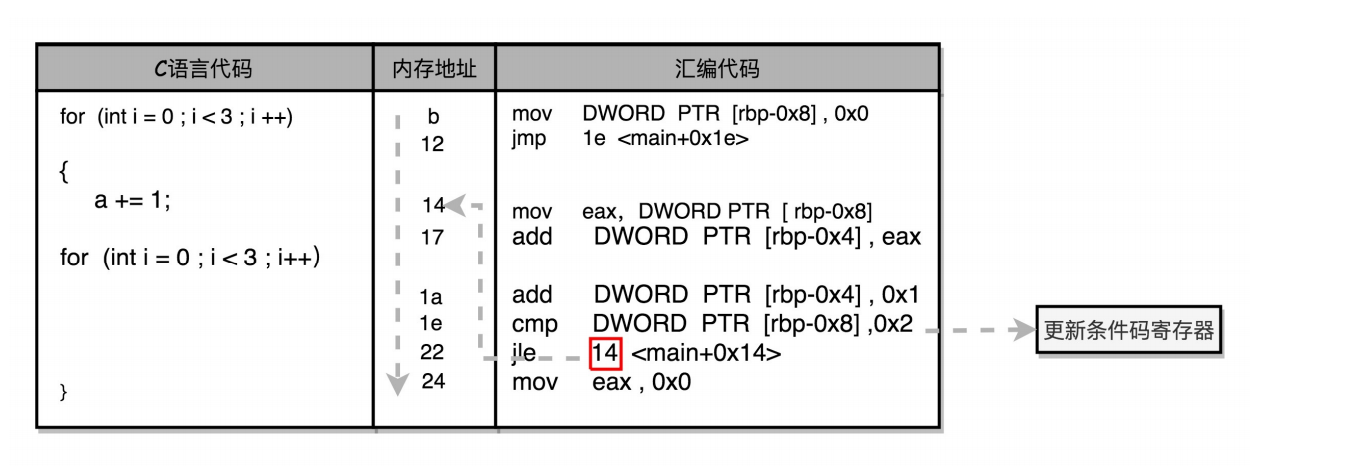
实际在机器指令层面,无论是if…else… 也好,还是for/while也好,都是用和goto相同的跳转到特定指令位置的方式来实现的。
总结延伸
除了简单 地通过PC寄存器自增的方式顺序执行外,条件码寄存器会记录下当前执行指令的条件判断状态,然后通过 跳转指令读取对应的条件码,修改PC寄存器内的下一条指令的地址,最终实现if…else以及for/while这样的 程序控制流程。
想要在硬件层面实现这个goto语句,首先要有个通用寄存器保存跳转地址,还要根据条件码寄存器来判断是否跳转,最后修改PC的值
07-函数调用:为什么会发生stackoverflow?
为什么我们需要程序栈?
// function_example.c
#include <stdio.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x, y);
}
函数add,接收两个参数a和b,返回值是a+b。main函数里则定义了两个变 量x和y,然后通过调用这个add函数,来计算u=x+y,最后把u的数值打印出来。

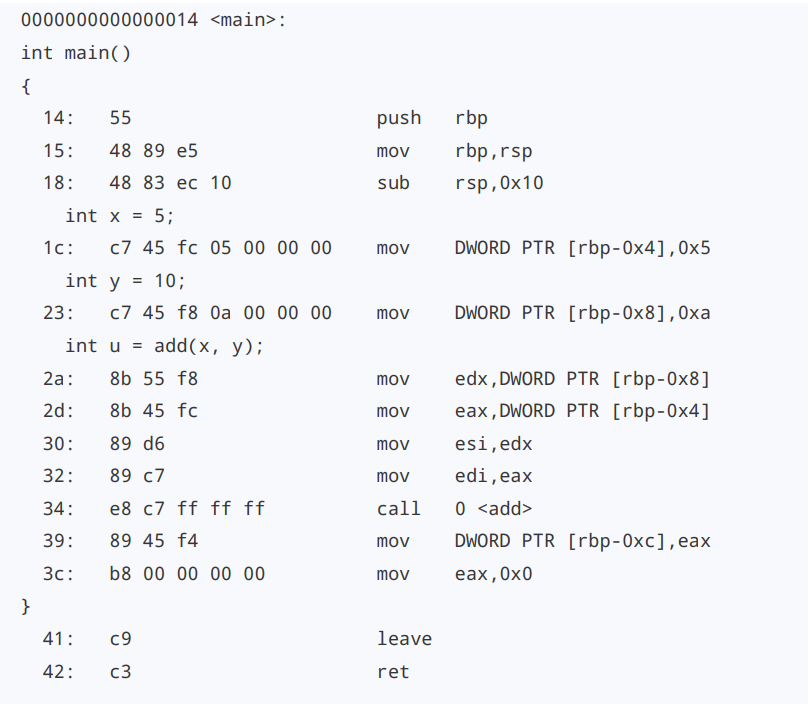
add函数编译之后,代码先执行了一条push指令和一条mov指令;在函数执 行结束的时候,又执行了一条pop和一条ret指令。这四条指令的执行,其实就是在进行我们接下来要讲压栈 (Push)和出栈(Pop)操作。
函数调用的跳转,在对应函数的指令执行完了之后,还要再回到函数调用的地方,继续 执行call之后的指令 。跟jump不同
- 问题:怎么实现一个可以从断点继续的函数的调用呢?
- 解决:直接写死jump到断点的地址
- 问题:可能会造成函数相互调用死循环,而且函数调用是直接写死的
- 解决:在寄存器中记录每个原函数的地址再根据寄存器的内容跳转
- 问题:多层函数调用寄存器不够放
- 解决:原函数的地址放在内存中
- 解决:通过压栈和出栈的操作在栈中储存函数的地址

压栈有函数调用完成后的返回地址,以及原函数的上下文。整个函数A所占用的所有内存空间,就是函数A的栈帧(Stack Frame)。

A函数执行时先将之前的rbp(栈帧指针)压入栈中,再将rsp(栈顶指针)放入rbp中。如果A函数再调用B函数,B函数会把A函数的rbp(值为A的rsp)压入栈
如何构造一个stack overflow?
如果函数调用层数太多,我们往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,这就是stack overflow。
如何利用函数内联进行性能优化?
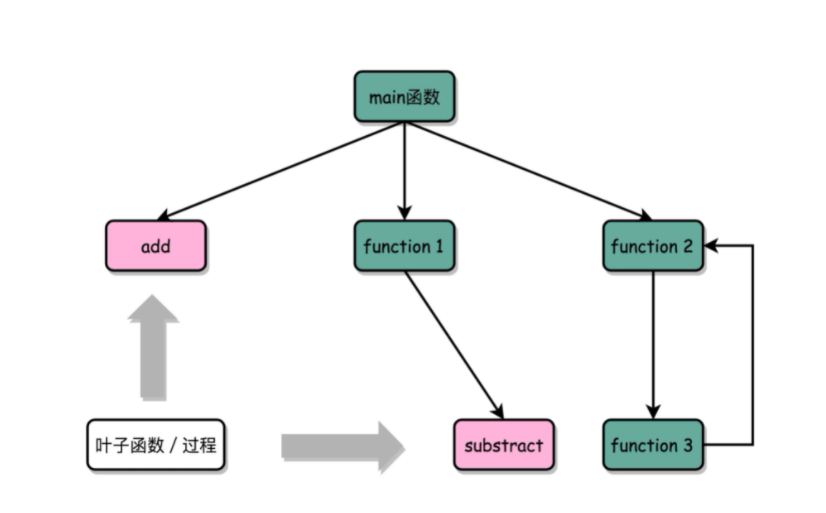
- 函数内联(Inline):如果被调用的函数里,没有再调用其他函数。那把被调用的函数产生的指令,直接插入cell指令的位置。
- 优点:CPU 需要执行的指令数变少了,根据地址跳转的过程不需要了,减少了切换上下文带来的开销
- 缺点: 我们把可以复用的程序指令在调用它的地方完全展开了。函数被多次调用,就会展开多次,程序占用的空间变大。
这样没有调用其他函数,只会被调用的函数,我们一般称之为叶子函数(或叶子过程)。
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
srand(time(NULL));
int x = rand() % 5
int y = rand() % 10;
int u = add(x, y)
printf("u = %d\n", u)
}
在调用 u = add(x, y) 的时候,直接替换成了一个 add 指令。
return a+b;
4c: 01 de add esi,ebx
总结延伸
通过加入了程序栈,我们可以在指令跳转的过程中,记忆断点位置能够实现更加丰富和灵活的指令执行流程。这个也为我们提供了“函数”这样一个抽象,使得我们可以复用代码和指令
08 | ELF和静态链接:为什么程序无法同时在Linux和Windows下运行?
编译、链接和装载:拆解程序执行
“C语言代码-汇编代码-机器码” 这个过程,是由两部分组成的。
第一个部分由编译、汇编,链接三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。
第二部分,我们通过装载器把可执行文件装载到内存中。CPU从内存中读取指令和数据,来开始真正执行程序。
编译(Compile)、汇编(Assemble)以及链接(Link)装载器(Loader)装载(Load)

ELF格式和链接:理解链接过程
程序最终是通过装载器变成指令和数据的,所以其实我们生成的可执行代码也并不仅仅是一条条的指令。


在Linux下,可执行文件和目标文件都使用ELF文件格式
ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式

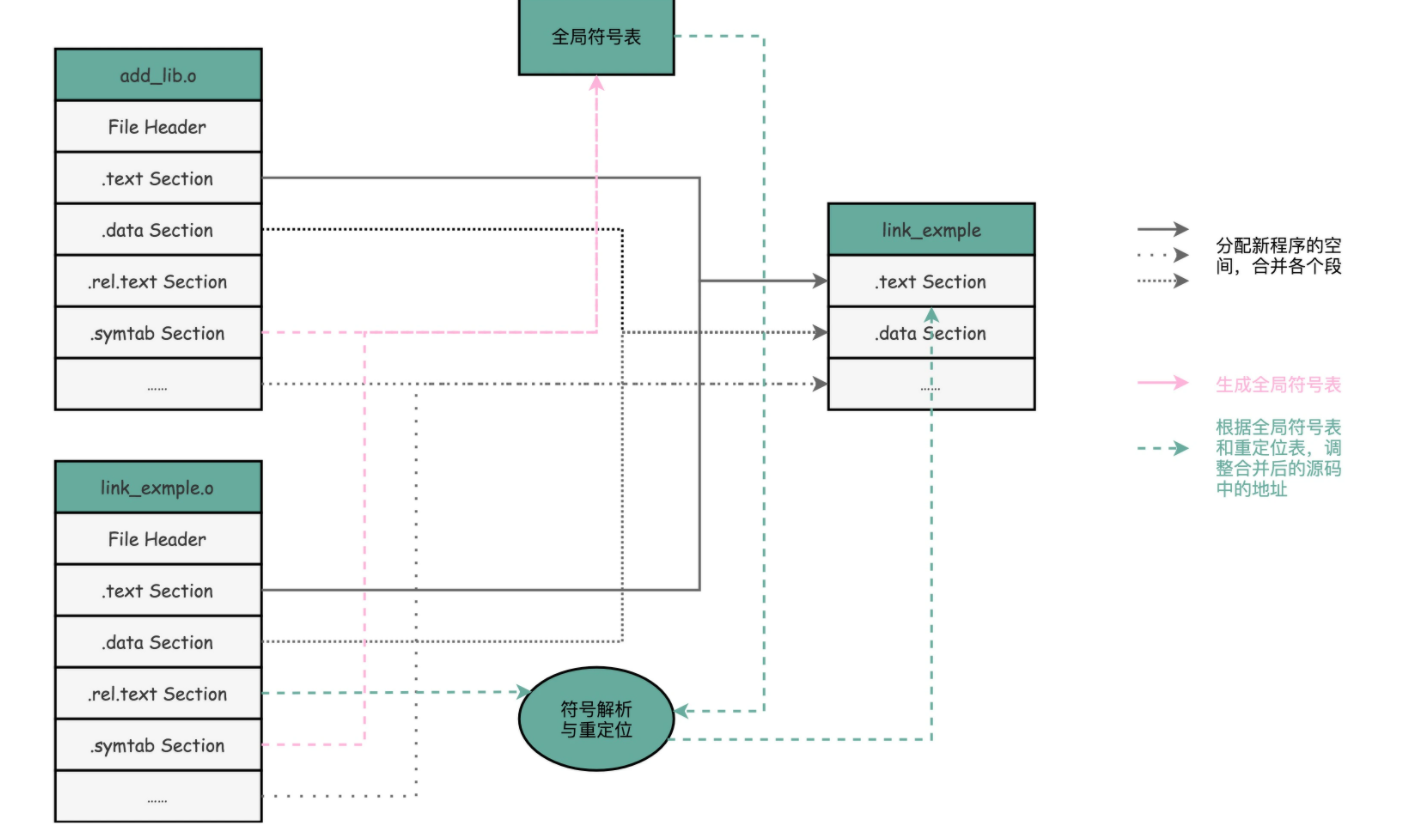
大部分程序还有这么一些Section:
- 首先是.text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;
- 接着是.data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;
- 然后就是.rel.text Secion,叫作重定位表(Relocation Table)。重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。比如上面的 link_example.o 里面,我们在main函数里面调用了 add 和 printf 这两个函数,但是在链接发生之前,我们并不知道该跳转到哪里,这些信息就会存储在重定位表里;
- 最后是.symtab Section,叫作符号表(Symbol Table)。符号表保留了当前文件里面定义的函数名称和对应地址的地址簿。
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
连接器会整合各个符号表
在链接器把程序变成可执行文件之后,要装载器去执行程序就容易多了。装载器不再需要考虑地址跳转的问题
总结延伸
为什么同样一个程序,在Linux下可以执行而在Windows下不能执行了。 其中一个非常重要的原因就是,两个操作系统下可执行文件的格式不一样。
09 | 程序装载:“640K内存”真的不够用么?
程序装载面临的挑战
装载器需要满足两个要求。
- 第一,可执行程序加载后占用的内存空间应该是连续的
- 第二,我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。
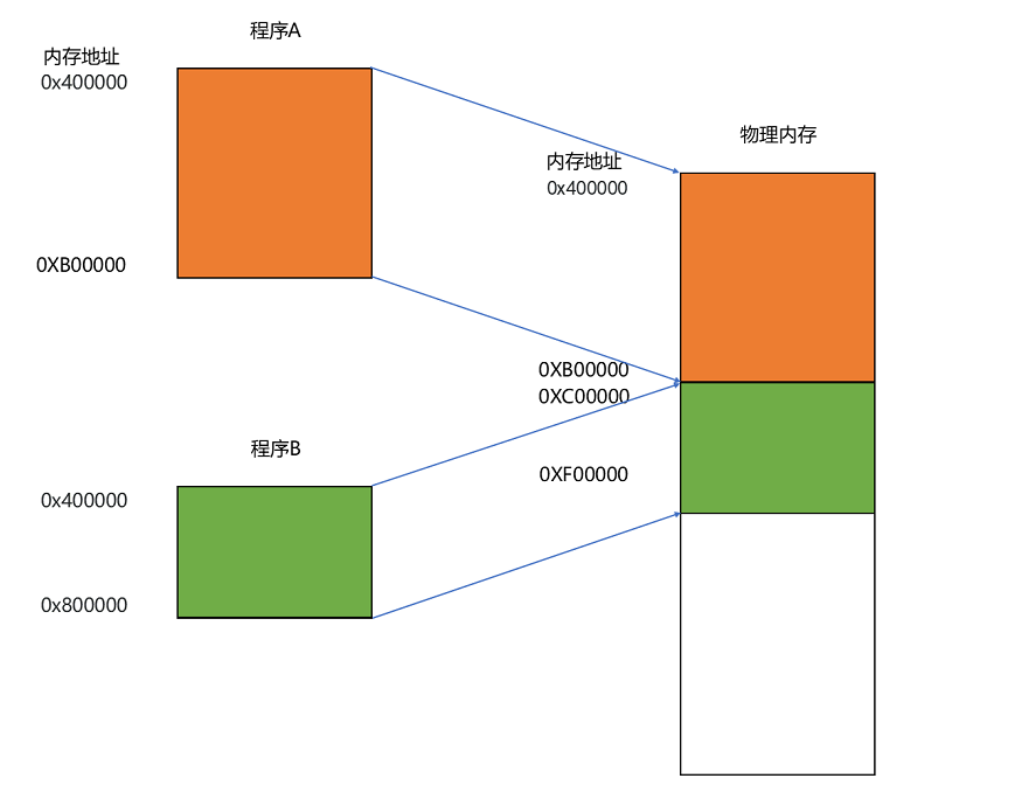
虚拟内存地址(Virtual Memory Address)物理内存地址(Physical Memory Address)。
内存分段
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。
-
问题:产生外部碎片(Memory Fragmentation)的问题。
-
解决:内存交换。 先把内存移到硬盘再整合回内存
- 问题:硬盘速度慢,即使程序比较大也不能拆分只能整个交换所以会“卡”
内存碎片(Memory Fragmentation)内存交换(Memory Swapping)
内存分页
分页是把整个物理内存空间切成一段段固定尺寸的大小**。
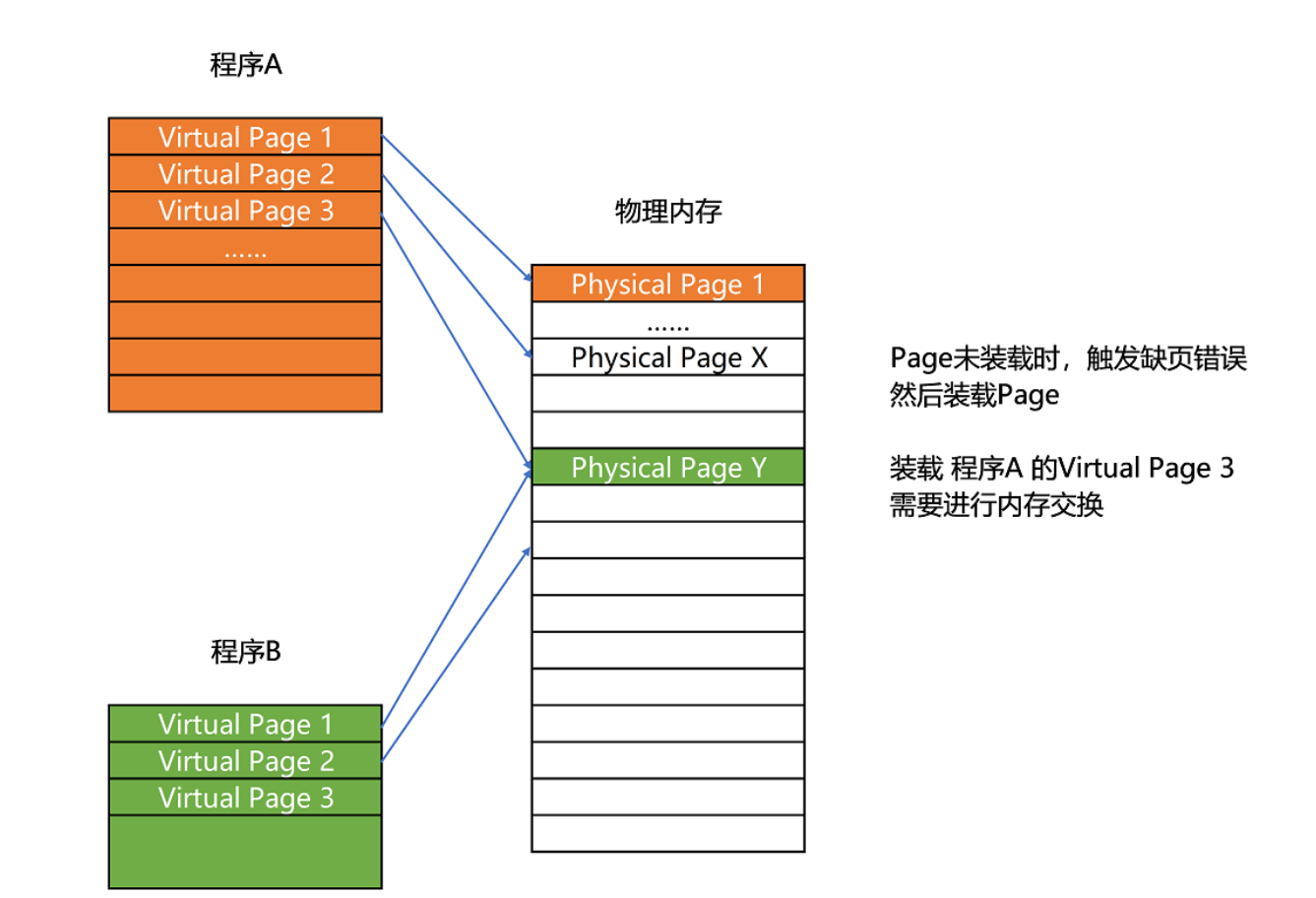
- 原理:物理内存先分成页再分配给程序
- 优点:不会有外部碎片(但还是会存在内部碎片)
- 内存交换时一次性交付少量页面速度块
- 程序可以部分装入内存
通过引入虚拟内存、页映射和内存交换,我们的程序本身,就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
10 | 动态链接:程序内部的“共享单车”
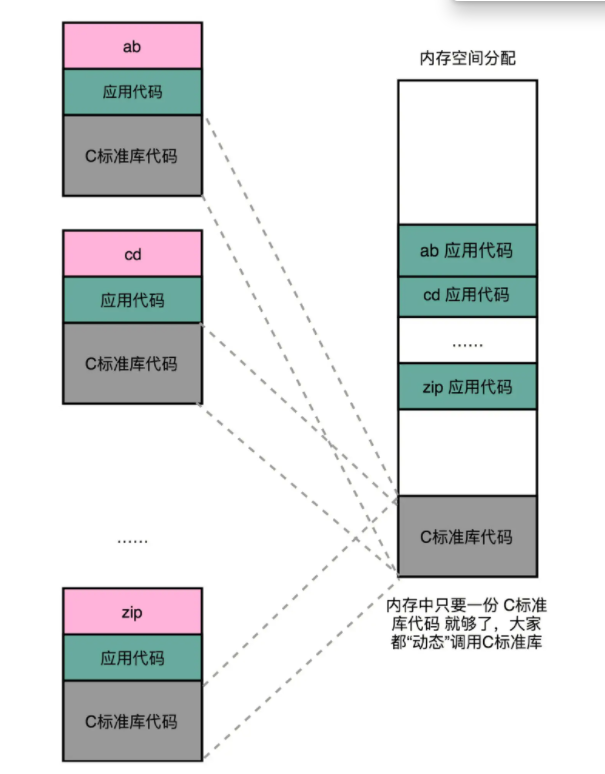
程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。这个链接的方式,让我们在写代码的时候做到了“复用”。 这是静态复用
链接可以分动、静,共享运行省内存
动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
地址无关很重要,相对地址解烦恼
我们编译出来的共享库文件的指令代码,是地址无关码(Position-Independent Code)。这段代码,无论加载在哪个内存地址,都能够正常执行
于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的(基址不同)。
- 问题:每个程序都使用各自的页表,虚拟内存,以及对应物理内存的基址。共享库的物理地址是固定的,而且需要被公共访问
- 问题:我们要怎么样才能做到,动态共享库编译出来的代码指令,都是地址无关码呢?
- 解决:动态代码库内部的变量和函数调用都很容易解决,我们只需要使用相对地址(Relative Address)就好了。给共享库预留一段连续的虚拟内存地址中的,程序再什么位置都能指向共享库。
PLT和GOT,动态链接的解决方案
首先,lib.h 定义了动态链接库的一个函数 show_me_the_money。
// lib.h
#ifndef LIB_H
#define LIB_H
void show_me_the_money(int money);
#endif
lib.c包含了lib.h的实际实现
// lib.c
#include <stdio.h>
void show_me_the_money(int money)
{
printf("Show me USD %d from lib.c \n", money);
}
然后,show_me_poor.c 调用了 lib 里面的函数。
// show_me_poor.c
#include "lib.h"
int main()
{
int money = 5;
show_me_the_money(money);
}
最后,我们把 lib.c 编译成了一个动态链接库,也就是 .so 文件。
$ gcc lib.c -fPIC -shared -o lib.so
$ gcc -o show_me_poor show_me_poor.c ./lib.so
在编译的过程中,我们指定了一个 -fPIC 的参数。这个参数其实就是Position Independent Code的意思,也就是我们要把这个编译成一个地址无关代码。
我们再通过gcc编译show_me_poor 动态链接了lib.so的可执行文件。
$ objdump -d -M intel -S show_me_poor
们把show_me_poor这个文件通过objdump出来看一下。
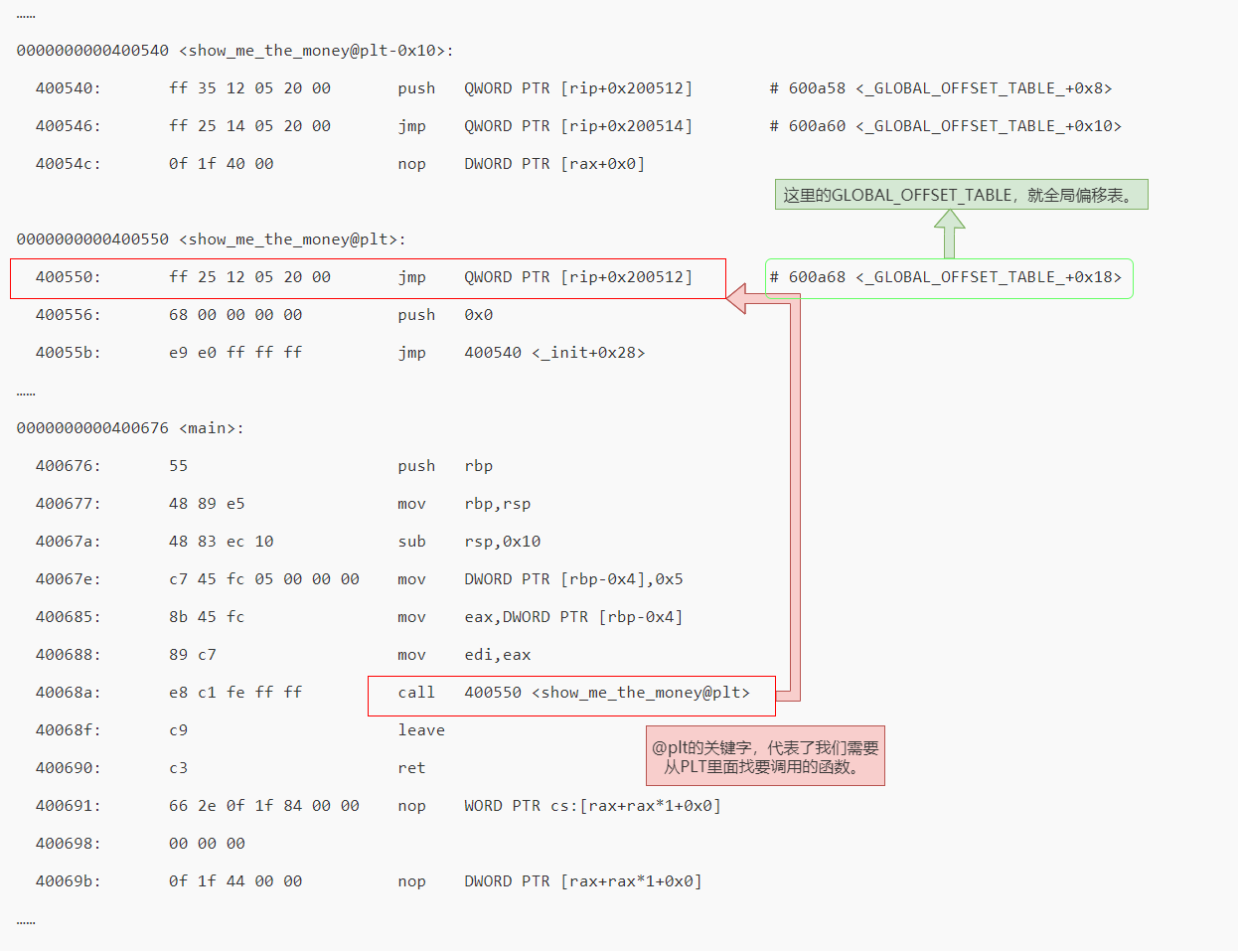

在动态链接对应的共享库,我们在共享库的data section里面,保存了一张全局偏移表(GOT,Global Offset Table)。**虽然共享库的代码部分的物理内存是共享的,但是数据部分是各个动态链接它的应用程序里面各加载一份的。**所有需要引用当前共享库外部的地址的指令,都会查询GOT,来找到当前运行程序的虚拟内存里的对应位置。而GOT表里的数据,则是在我们加载一个个共享库的时候写进去的。
不同的进程,调用同样的lib.so,各自GOT里面指向最终加载的动态链接库里面的虚拟内存地址是不同的。
这样,虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库,但是不需要去修改动态库里面的代码所使用的地址,而是各个程序各自维护好自己的GOT,能够找到对应的动态库就好了。
我们的GOT表位于共享库自己的数据段里。GOT表在内存里和对应的代码段位置之间的偏移量,始终是确定的。这样,我们的共享库就是地址无关的代码,对应的各个程序只需要在物理内存里面加载同一份代码。而我们又要通过各个可执行程序在加载时,生成的各不相同的GOT表,来找到它需要调用到的外部变量和函数的地址。
这是一个典型的、不修改代码,而是通过修改“地址数据”来进行关联的办法。
总结延伸
这一讲,我们终于在静态链接和程序装载之后,利用动态链接把我们的内存利用到了极致。同样功能的代码生成的共享库,我们只要在内存里面保留一份就好了。这样,我们不仅能够做到代码在开发阶段的复用,也能做到代码在运行阶段的复用。















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









