






 该文详细介绍了在Windows10环境下部署AUTOMATIC1111的stable-diffusion-webui的步骤,包括Python和git的安装,模型和必要文件的准备,以及webui-user.bat的配置和运行。同时,文章还提供了模型下载链接和可视化界面的中文设置方法。
该文详细介绍了在Windows10环境下部署AUTOMATIC1111的stable-diffusion-webui的步骤,包括Python和git的安装,模型和必要文件的准备,以及webui-user.bat的配置和运行。同时,文章还提供了模型下载链接和可视化界面的中文设置方法。
Windows10 AUTOMATIC1111 / stable-diffusion-webui 本地部署
文章目录
前言
非常简单的前言,这就是一个简单介绍部署流程的文章。如有不全敬请谅解。
下面根据网上的资料对部分名词简要介绍一下:
stable diffusion是一个基于潜在扩散模型(Latent Diffusion Models)的一个 文本到图像(text to image)生成模型,能够根据任意文本输入生成高质量、高分辨率、高逼真的图像。
AUTOMATIC1111 的 stable-diffusion-webui,则是一个基于stable diffusion,可以便捷部署的离线框架,其实就是封装了UI以及一些功能,让我们能通过可视化界面而不是通过命令行参数使用SD进行绘画创作。
使用stable-diffusion-webui需要我们先行下载已经训练过的模型,根据使用的模型将生成使用模型的风格的图片。模型的下载方式将在接下来进行介绍。
下面将详细介绍部署stable-diffusion-webui的具体流程。
一、前期准备
在开始部署前,我们可以先准备好一些需要的东西。
1.Python
请注意,为保证准确性,Python版本至少为3.10.6,点击这里直接下载
想使用更高版本的Python也可以去官网下载
2.git
在后续的部署过程中会使用到git,点击这里直接下载
3.stable-diffusion-webui存储库
这个分两种情况,你可以使用git直接将库导到本地,也可以去github上自行下载仓库,
使用git的方式将在接下来的流程中介绍,这里介绍直接下载的情况。点击这里进入github网页
点击下图所示的Code / Download ZIP即可,你也可以点击这里直接下载

4.模型
stable-diffusion-webui需要有已经训练过的模型才能进行使用,下面提供一些模型的下载地址:
- 框架本体提供的模型sd-v1-4
- waifu-diffusion-v1-3 适合二次元画风
- Inkpunk Diffusion_v2 墨水朋克画风
另外下面是两个常用的下载模型的网站,可以直接去搜模型下载
huggingfacel
civitai
VAE文件,会让图像更加拟人点击这里下载
此外一些我使用过的模型和一些”优质“模型我会放在文末。
Anything-v4.5 擅长漫画
chilloutmix 真人效果
CounterfeitV25_25 动漫风格
dreamlike 高质量动漫艺术
5.必须文件
注意,这一步可以先跳过!!!
stable-diffusion-webui本体在第一次运行webui-user.bat时需要下载一些必须文件,这一步有可能会因为网络问题出现错误,如果不嫌麻烦可以先行直接把这些文件下载安装。下面提供各依赖文件的下载:
下面是python包
以上这些文件的操作步骤请点击这里跳转
当然,这些我也会放在文末的资源整合中
二、部署步骤
1.安装Python
安装Python没什么好说的吧,记得勾选上Add Python 3.10 to PATH就行

2.安装git
这个也没什么好说的吧,打开.exe然后一路next->就行
3.stable-diffusion-webui存储库
首先,为了防止你使用的时候空间不足,综合考虑下,至少需要空余空间为15G的盘来存放文件,然后新建一个文件夹用于存放文件并重命名。
如果你之前已经在github下载了stable-diffusion-webui-master.zip,那就解压到新建的文件夹中。

如果使用git,则需要打开cmd,用cd命令进入到对应文件夹中,然后使用git将库拉到本地

git命令如下:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4.修改webui-user.bat文件
首先我们打开本地的stable-diffusion-webui文件夹,找到webui-user.bat文件,右键点击编辑,下面是我的内容,可以参考修改。
@echo off
set PYTHON=C:\Users\Administrator\AppData\Local\Programs\Python\Python310\python.exe
set GIT=
set VENV_DIR=venv
set COMMANDLINE_ARGS=
git pull
start http://localhost:7860/
call webui.bat
需要注意的是,在set PYTHON=后方填写你安装的python的路径,如果忘了的话,可以在快捷方式单击右键点击属性查看

如果GPU VRAM小于4GB的话可以set COMMANDLINE_ARGS=--medvram --opt-split-attentio
电脑RAM小于8GB的话可以set COMMANDLINE_ARGS=--lowvram --opt-split-attention
除此之外,git pull命令用于从远程获取代码并合并本地的版本(但不建议频繁更新),start http://localhost:7860/是直接打开网页(可视化界面),如果没有刷新出来不用着急,等bat运行完毕后刷新即可出现界面。
5.放置模型及相关文件
将下载下来的模型放置在相应的位置,注意,把下载下来的.ckpt文件和.safetensors文件放置在下图所示的Stable-diffusion文件夹下:
如果是Lora请记得放在下图的Lora文件夹下。(Lora一般大小为几十-几百M),注意,首次部署可能没有lora文件夹,暂时不用管。
VAE文件请放在下图中的VAE文件夹下

6.运行webui-user.bat
注意!!!这一步可能会出现很多问题,这里会对常见问题进行说明,其余问题将在文末进行更新总结。
双击运行webui-user.bat。
注意它可能会报错,提示你升级pip版本,你只需要cd到对应目录,然后运行一下命令python.exe -m pip install --upgrade pip升级一下pip就行。
注意!!!由于它会自己使用git下载文件,但还是很有可能出现即使科学上网仍然下载不下来的情况
这时候有以下几种方法:
-
使用GitHub Proxy,
打开launch.py文件,把def prepare_environment():下所有https://github.com/前添加https://ghproxy.com/


-
使用开发者边车,
访问github下载点击前往网页,然后把代理服务,系统代理,Git.exe打开,以及应用里面的pip加速改为aliyun镜像




-
添加镜像
-
直接在科学上网软件处打开cmd去运行webui-user.bat
-
直接下载所需要的各种文件,这一步请前往文件下载
操作步骤:
下载完成之后,请新建一个文件夹并命名为:repositories,用于放置5个依赖文件

然后把5个依赖文件压缩包全部解压,去掉-main或-master后缀,按照图中命名,放在repositories文件夹下

文件下载列出的3个python包非常容易报错,所以建议自行安装。下载后,解压到stable-diffusion-webui\venv\Scripts目录下,venv是在编辑.bat的时候的set VENV_DIR=venv,所以这里根据你的命名修改。
CLIP和open_clip的方法如下:
打开cmd,cd到stable-diffusion-webui\venv\Scripts\open_clip-main或者CLIP-main下。
使用G:\\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install安装。
GFPGAN的方法如下:
打开cmd,cd到stable-diffusion-webui\venv\Scripts\GFPGAN-master下。
使用命令G:\\stable-diffusion-webui\venv\Scripts\python.exe -m pip install basicsr facexlib安装GFPGAN的依赖。
再使用G:\\stable-diffusion-webui\venv\Scripts\python.exe -m pip install -r requirements.txt安装GFPGAN的依赖。
使用G:\\stable-diffusion-webui\venv\Scripts\python.exe setup.py develop安装GFPGAN。
上面提供的5个选项请根据自身情况选择,可以先科学上网然后双击点开webui-user.bat文件试一试,出现报错再去根据相应文件进行对应的下载安装。
最后双击webui-user.bat,如果最后控制台出现下面的提示时说明成功,最后刷新网页,成功进入ui界面
To create a public link, set `share=True` in `launch()`.
三、可视化界面操作简介
这里只简单介绍一下一些相应设置以及基本操作,具体如何才能画出符合自己预期的图片就需要各位自行摸索了。
1.更改中文
点击Extensions,选择Install from URL,然后把链接粘贴过去,最后点击Install,等待应用成功。链接如下
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN

安装完成之后重启webui,点击Settings -> Reload UI

然后勾选上中文拓展,再点击Apply and restart UI

再点击Settings -> User interface,滑动到最底在Localization下拉框中选择zh_CN。


最后回到最上方,点击Apply settings,再点击Reload UI,即可切换成中文。

2.页面简要介绍
下面再简单介绍下界面,其实切换成中文后大多的都应该懂了。提示词使用英文,用逗号进行分隔,比如
a girl,undercut hair,young
反面提示词为你不希望它生成的,比如:
bad hands,missing fingers,bad body,
采样方法中,推荐采用Euler A,DPM2 A ,DDIM
采样迭代次数中,迭代不一定越多越好,根据具体采样方法以及具体需求自行决定。实际使用时往往需要根据画布大小和目标是否复杂来综合考虑。对于512*512那样的标准画布与无强烈细化要求的简单场景,使用Euler A / DDIM等中步数要求算法的迭代次数通常推荐30或以上,40或以下。
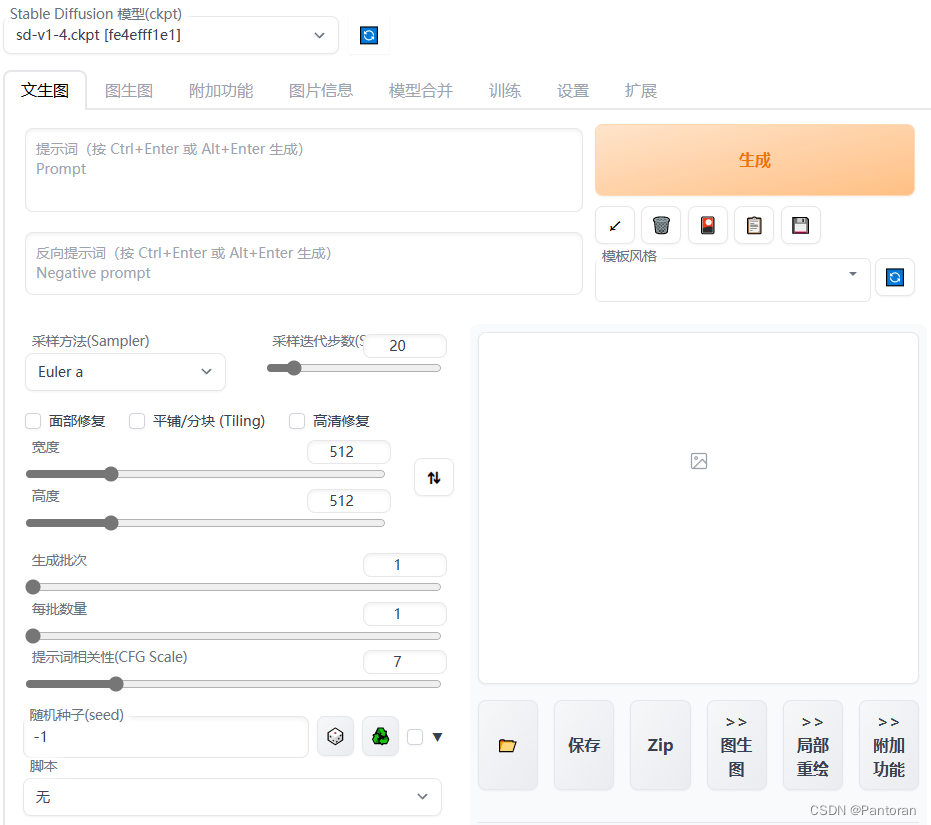
3.通用提示词
正面:((masterpiece)), (((best quality))), ((ultra-detailed)), ((illustration)), ((disheveled hair))
负面:longbody, lowres, bad anatomy, bad hands, missing fingers, pubic hair,extra digit,fewer digits, cropped, worst quality, low quality
文末
目前绝大多数的需要的文件已经提供下载方式,我自行打包了一份文件用于内部交流使用,目前由于特殊原因不提供下载地址,如有需要请联系我。

















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









