







MySQL数据库所支持的SQL语句主要包含以下几个部分。
(1)数据定义语言(DDL)
(2)数据操纵语言(DML)
(3)数据控制语言(DCL)
首先,需要指明的是,sql语句默认不区分大小写(除非更换字符集的校对规则),不过习惯对所有sql关键字使用大写,而对所有列和表的名称使用小写,这样的书写方式可使代码易于阅读和调试。(此处因为懒,都小写了)
一、数据库的创建与使用
create database mysql_test;//创建一个名叫mysql_test的数据库
if not exists //mysql不允许同一系统中两个数据库使用相同的名字,加上这句可以避免错误产生,只是给出错误提示。
create database if not exists mysql_test;//只有在不存在时才创建,存在时会警告,不会报错,不加if not exists则会报错
use mysql_test;//指定mysql_test为当前数据库,只有这样才能对mysql_test数据库进行操作
alter database mysql_test character set =utf8;//修改数据库编码(character_set_database)格式
等价于:set character_set_database = utf8;
alter database mysql_test// [ˈɔltɚ]
default character set gb2312//[ˈkærəktɚ]
default collate gb2312_chinese_ci;//[kəˈleɪt]修改已有数据库mysql_test的默认字符集和核对规则
在mysql5.1之后的版本中,alter database命令增加了upgrade data directory name从句,用于使用mysql5.1版本的编码规则更新5.1之前版本数据库的目录名称,以提高文件系统的安全性。如下:
alter database ‘#mysql50#a-b-c’ upgrade data directory name;// upgrade [ˈʌpˌɡred]提升。在mysql5.5版本中修改mysql5.0版本下创建的数据库名’a-b-c’所对应的目录名称。
drop database mysql_test;//永久删除整个test数据库
drop database if exists mysql_test;//避免test不存在时发生错误
show databases;//查看用户权限范围内的所有数据库(mysql安装后,系统会自动地创建名为information_schema [ˈskimə]和mysql两个数据库,所以每次查看都会有这两个数据库。有些默认的还有test和performance_schema,即有四个默认数据库)
show create database mysql_test;//展示数据库test的创建命令和编码形式
show engines;//查看系统中可用的数据库引擎和默认引擎
show warnings;//查看警告信息
select database();//显示当前打开的数据库,注意没有s
select version();//查看当前mysql版本
select now();//查看当前系统时间
二、创建表和使用表
创建一个表的命令如下:
create table customers(
id int not null unsigned auto_increment ,
username varchar(20),
age tinyint unsigned,//unsigned [ʌn’saɪnd]表示无符号位,即不能为负数
salary float(8,2) unsigned//[ˈsæləri]薪水,有效位数为8位,精度为2,即8位数,2位小数
);
复制表,使用like关键字创建一份表的拷贝,表的列名,数据类型,空指引,索引都将被复制,但表内容不会复制,因此创建的是一个空表。如果想复制表的内容可以使用as(select_statement)关键字,但索引和完整性约束不会被复制,select_statement表示一个select语句表达式,例如可以是一个select 语句。
create table mysql_test.customers_copy
like mysql_test.customers;//复制了一个空表
create table mysql_test.customers_copy2
as (select * from mysql_customers);//复制customers表中的所有内容
drop table customers_copy;//删除表
show tables;//查看当前数据库的所有表
show tables from mysql_test;//查看mysql_test这个数据库中的所有表
show create table customers;//显示数据表创建时的命令,可以用来查看外键等
show columns from customers;// [‘kɒləm]查看数据表的结构(有哪些列及列属性定义)
desc customers;//作用与上面的一样,查看数据表的结构
show indexes from customers[\G] // 查看customers表的key和索引,\G表示以网格的形式显示
三、表的更新
1.添加删除列
添加列:alter table customers add 列名 数据类型 (+ after xx , 将会添加新列到指定列xx 的后面);
举例:alter table customers add password varchar(30) after username;
另外:alter table customers add truename varchar(20) first; 会将新列添加到最前面。
删除列:alter table tb_name drop列名,drop列名,drop列名…;
举例:alter table users drop password; //删除一个列
alter table users drop age,drop truename;//同时删除多个列
2.修改列定义、列名称:modify,change:
alter table 表名 modify 列名 数据类型 [其他属性];
modify子句只会修改指定列的数据类型,而不会干涉它的列名。此外还可以通过first或after关键字修改指定列在表中的位置。注意:使用时要严格按照上面的格式,即如果只是改变位置也要加上数据类型,否则会出错。
举例:alter table users2 modify id smallint unsigned first;
alter table表名 change 列名 新列名 数据类型 [其他属性]
change则可以同时修改列的名称和数据类型。注意:使用时要严格按照上面的格式,即如果只是修改列名称时也要加上数据类型,否则会出错。
举例:alter table users2 change pid p_id smallint unsigned not null;
3.表重命名的两种方法:rename to和rename …to…
alter table 表名 rename [to|as] 新表名
举例:alter table customers
rename to customers_copy;
此外也可以 rename table 表名 to 新表名;
举例:rename table customers_copy to customers;
4.修改表中指定列的默认值
将数据库mysql_test中表customers的cust_city列的默认值修改为’Beijing’
alter table mysql_test.customers
alter cust_city set default ‘Beijing’;
四、表数据的基本操作
1.插入
插入方法一:
insert [into] 表名 values(abc,123),(dfad,321);//可以插入多条数据, 逗号分割
insert mysql_test.customers values(901,’张三’,’F’,’北京市’,’朝阳区’);插入所有字段的值
插入方法二:
在表名后明确给出列表清单,其优点是即使表的结构发生改变,这条insert语句仍可以正确执行。
insert tb1(username,salary) values(‘John’,4500.69);插入某些字段的值
插入方法三:
insert的set使用方法,该方法一次只能插入一条记录,但可以使用子查询。
举例:insert users set username=’Ben’,password=’123’;
插入方法四:
insert select ,此种方法可将查找到的结果赋值给数据表
举例:insert test(username) select username from user1 where age>=30;//从user1中查找出年龄大于等于30的username,然后插入到test的username中
插入方法五:
如果在表中存在与待插入数据相同的primary key或unique key 的数据行时,则insert语句无法插入此行,这时就可以用replace语句来实现,它会将冲突的旧记录删除,从而保证新记录正常插入。
举例:replace customers(cust_id,cust_name,cust_sex,cust_address,cust_contact)
values(901,’王五’,’M’,’广州市’,’越秀区’);//这条记录会替换原来的记录
2.更新UPDATE
举例:update users set age=age+1; //整张表发生改变
update users set age=age+id,sex=0; //多个字段用逗号隔开。
update users set sex=1 where id%2=0; //id为偶数的sex值设为1。求余为0即偶数
update tbl1,tbl2 set tbl1.name=’李明’,tbl2.name=’张亮’ where tbl1.id=tbl2.id;//在表tbl1中id值与表tbl2中id值 相同时,将表tbl1中name列的值修改为“李明”,将tbl2中name列的值修改为“张亮”
3.删除记录(单表删除)
1.删除一个表中的数据
delete from tbl_name [ where condition]
举例:delete from customers where cust_name=’王五’;//注意delete与from之间没有*号
删除某条记录后,再插入一条新的记录,自动编号不会补到删除记录的编号上,而是基于原有记录最大编号继续增加(如原来最大的编号是10,delete之后插入的新数据的编号为11)。就算把数据全都清空了,计数器也不是重新从0开始,而是在原来的基础上继续增加。
2.删除多个表中的数据
举例:delete tbl1,tbl2 from tbl1,tbl2,tbl3 where tbl1.id=tbl2.id and tbl2.id=tbl3.id;//删除的是tbl1,tbl2中的对应的行,from之前
delete from tbl1,tbl2 using tbl1,tbl2,tbl3 where tbl1.id=tbl2.id and tbl2.id=tbl3.id;//删除的是tbl1,tbl2中的对应的行,from之后,using之前
3.删除表中所有的数据,可以使用truecate语句,而且执行速度会比delete更快。这是因为,truecate操作的实际过程是先删除原来的表,再重新创建一个表,而不是逐行删除表的数据,因此使用的系统和事务日志资源也会比较少。注意:truecate清空数据后,auto_increment计数器会从0开始。
举例:truecate customers;//truecate只是清空数据,剩下空表。而drop table customers;是删除表,包括结构
4.查询
(1)列的选择与指定
select cust_name,cust_sex,cust_address from mysql_test.customers;//选择指定的列
select cust_name,cust_address as 地址,cust_contact from mysql_test.customers;//将结果集中cust_address用别名”地址“代替,因为别名没空格,所以引号可有可无
select cust_name,cust_address as ‘地 址’,cust_contact from mysql_test.customers;//当别名中含有空格时,必须用单引号括起来
另外,列别名不允许出现在where子句中,因为sql语句的执行是有顺序的,执行where子句时, as ‘别名’语句还没执行,即别名不存在
在对表进行查询时,若希望得到对某些列的查询分析结果,而不是由查询得到的原始具体数据,则可以在select语句中替换这些列,其中需要用到case表达式。举例:
select cust_name,
case
when cust_sex=’M’ then’男’
else ‘女’//如果cust_sex的值为M,则显示输出”男“,否则 为”女“
end as 性别//同时可以将cust_sex列用别名”性别“代替,end as 语句必须要加才能正确运行,即使列名不改变也要加,即end as cust_sex
from mysql_test.customers;
此外,查询还可以指定为对应列参与计算的表达式(如:select cust_id+100…)、聚合函数(如:select count(*) from mysql_test.customers)。聚合函数是mysql中一类系统内置函数,常用于对一组值进行计算,返回单个值。如:
avg()//求平均值
round(avg(goods_price),2) //保留两位有效数字
(2)from子句与连接表
如果在from子句中指定了表别名,那么它所在的select 语句中其他子句都 必须使用表别名来代替原始的表名,因为from子句是select语句中最先被执行的,有关select语句执行顺序的详细说明,可参考博客:http://blog.csdn.net/paranoidyang/article/details/65449830
01.交叉连接,又称笛卡儿积(cross join)
使用关键字cross join连接两张表,用于实现 一张表的每 一行与另一张表的每一行笛卡儿积,返回两张表的每一行相乘的所有可能的搭配结果。
举例:select * from tbl1 crosss join tbl2;
select * from tbl1,tbl2;//cross join可以用逗号代替
02.内连接**(inner join)
由于是系统默认的连接方式,所以在from子句中可以省略关键字inner,而只用join连接。使用内连接后,from子句中的on子句可以用来设置连接表的条件,而其他不属于连接表的条件则可以在select 语句中的where子句中进行指定。
1)相等连接
on子句的连接条件中使用运算符”=“,通常这样的条件会包含一个主键和一个外键。
2)不等连接
on子句的连接条件中使用除运算符”=“之外的比较运算符。
3)自连接
需要为表指定两个不同的别名,且对所有查询列的引用均必须使用表别名限定,否则select操作会失败。
03.自然连接**
04.外连接
内连接是在交叉连接的结果集上返回满足条件的记录 ;而外连接则是首先将连接的两张表分为基表和参考表,然后再以基表为依据返回满足和不满足条件的记录。外连接可以在表中没有匹配记录的情况下仍返回记录。
1)左外连接
又称为左连接,在from子句使用关键字left outer join(outer可以省略),用于接收该关键字左边表(基表)的所有行,并用这些行与该关键字右边表(参考表)中的行进行匹配,即返回的是左表的全部以及右表中符合条件的。
2)右外连接
又称为右连接,在from子句使用关键字right outer join(outer可以省略),右外连接以右表为基表,即返回的是右表的全部以及左表中符合条件的。
(3)where子句
比较运算符(=、<>、!=、<、<=、>、>=、<=>)
前面七种比较运算符,当两个表达式均不为空值(null)时,比较运算返回true或false;只要有一个空值,则返回unknown。
而<=>有点类似于=,不同之处在于对空值的处理:当两个表达式相等或都为空值,返回true;若有一个空值或者非空不等时,则为false,不会出现unknown的情况。
举例:select * from mysql_test.customers where cust_sex=’M’;
字符串匹配(like+通配符)
百分号(%)
* 百分号可代表任意多个字符
* 不能匹配空值null
* 尾空格可能会干扰通配符的匹配,所以一般可以在搜索模式的最后附加一个%。
举例:
show variables like ‘char%’;
select cust_id,cust_name from mysql_test.customers where cust_name like ‘杨%’;
下划线(_):匹配单个字符
注意:当要匹配的字符串中含有与通配符(%或_)相同的字符时,可以用关键字escape和一个指定的转义字符,来临时改变与通配符相同字符的作用和意义。
举例:select cust_address from mysql_test.customers where cust_address like ‘%#_%’ escape ‘#’;//将#号后面的下划线转义
文本匹配(regexp+正则表达式)
使用正则表达式进行文本串的匹配比较,以满足定义一些复杂过滤条件的要求。
举例:select distinct cust_address from mysql_test.customers where cust_address regexp ‘市’;//只要有市这个字的就会被匹配,而上面的字符串匹配必须加上通配符才能实现这种效果,单单写like ‘市’是匹配不了的,返回的是空。
如果想在使用正则表达式进行文本匹配时区分大小写,则可在关键字regexp之后再加上关键字binary。
如果想进行选择性匹配,则可以使用分隔符”|“,类似于select 语句中的or子句。
举例:select distinct cust_address from mysql_test.customers where cust_address regexp ‘北京|武|广’;//cust_address中带有北京,武,广这几个中文字符的都会被匹配
select cust_name from mysql_test.customers where cust_id regexp [3-8];//匹配在3-8范围内的cust_id,此外还有[a-g]等
正则表达式语言是一些具有特定含义的特殊字符构成的,当要查找匹配含有这些特殊字符的字符串时,也需要使用转义的方法,不过这里不是用escape,而是在这些特殊字符前面使用”\“作前导即可。如正则表达式中如果出现”\-“是指查找字符”-“。
另外,注意的是,”\“也可用来引用空白元字符(即含有特殊含义的字符),例如,”\f“表示换页,”\r“表示回车等。
为更加方便地查找,可以将经常使用的数字、字符等定义成一个预定义的字符集(也称字符类),然后在下面正则表达式中直接使用。例如,”[:upper:]“表示任意大写字母,相当于”[A-Z]“。
select cust_name from mysql_test.customers where cust_name regexp ‘[丽]{2}’;//匹配名字中重复出现两个“丽”的客户,有关重复匹配的还有很多,可以自己再去了解,这里就不再赘述
select * from mysql_test.customers where cust_id regexp ‘^[8-9]’;//匹配以数字8或9开关的cust_id,关于使用定位符匹配的还有其他的,自行了解
select * from mysql_test.customers where cust_id between 901 and 912;//查询cust_id在901~912之间的10个客户信息(包括901和912),not between…and 则不包括两端的值
select * from mysql_test.customers where cust_id in (903,906,908);//查询cust_id为这三个值 的客户信息
select cust_name from mysql_test.customers where cust_contact is null;//查询没有填写客户联系方式的客户
all,some和any:
all用于指定表达式需要与子查询结果集中的每个值比较,some和any是同义词,表示表达式只要与子查询结果集中的某个值满足比较关系时,就返回true,否则返回false。
(4)group by与order by
group by
使用having 语句在group by后面追加条件以过滤分组。
having后面可以跟聚合函数或者某个字段(如果是某个字段则需保证这个字段出现在前面的SELECT语句当中)。
注意:where子句用来过滤数据行,且后面不可以跟聚合函数。having子句主要用于过滤分组。
举例:select cust_name,cust_address
from mysql_test.customers
group by cust_address,cust_name
having count(*) <=3;//列出相同地址中客户人数少于3的所有客户姓名及其对应地址。
select * from users group by 1;(这里的1表示查询的第一个字段,这里查询所有字段信息,第一个字段就是id,所以会按照id字段进行分组)
order by
使用order by 子句将结果集中的数据按一定顺序进行排列,asc 升序排列,desc 降序排列。示例:
select cust_name,cust_sex from mysql_test.customers
order by cust_age asc,cust__id desc//先按年龄的升序(默认顺序)排列,然后有相同年龄的则将其id按降序排列
注意:当对空值进行排序时,order by 子句会将空值做为最小值来对待。
(5)limit
limit限制select语句返回的行数(在PHP分页技术中会用到这个子句)
如:select * from mysql_test.customers limit 2; //结果只显示排序最前面的两条记录。
此例等价于 : select * from mysql_test.customers limit 0,2;
如果想返回结果显示第五、第六条记录,则可以:
select * from mysql_test.customers limit 4,2; //从4+1行开始取2行,即第五,第六条记录,是从0数起的
其中limit 4,2 等价于limit 2 offset 4。
select * from mysql_test.customers order by id desc limit 2; //倒序后仍然显示第一、第二条记录,说明与id号是无关的,是从上到下显示表记录的
(6)union语句(并查询或联合查询)
两种基本情形:
*在单条查询中,需要从不同的表中返回相似结构的数据。
*对单个表执行多条查询时 需要以单条查询的结果集返回。
举例:select cust_id,cust_name from mysql_test.customers
where cust_sex=’F’
union
select cust_id,cust_name from mysql_test.customers
where cust_address=’北京市’;
使用union 语句进行联合查询与在单条select 语句中使用多个where子句的执行结果是相同的。所以此例等价于:
select cust_id ,cust_name form mysql_test.customers where cust_sex=’F’ or cust_address=’北京市’;
注意:union all是union语句中的一种,它可以完成where子句完成不了的工作,它可以让每个条件的匹配行在最终查询结果集中全部出现 ,并允许返回重复的数据行。
五、注意事项
1、set names gbk;//当命令行出现乱码时,设置gbk编码格式即可正常显示中文。
关于mysql命令行中文乱码详解请移步博客:http://blog.csdn.net/paranoidyang/article/details/57128346
2、关于空值
空值(null)通常用于表示未知、不可用或将在以后添加的数据,不能与数字0和字符类型的空字符混为一谈。任意两个空值不相等。
3、\s 可以查看当前数据库的一些基本信息,如数据库名称,版本,用户,字符编码等,注意:不用加分号
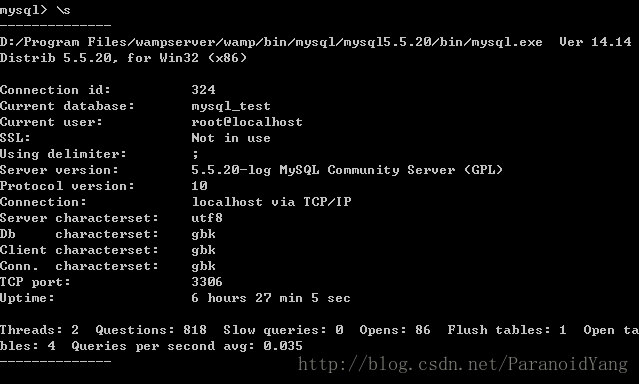
4、show variables like ‘char%’//查看数据库编码
5、使用 MySQL 时,有时输入命令时不小心输错了,却发现怎么也无法退出错误状态。那么,怎样才能取消错误的命令呢?
(1)可能少写了分号;
(2)可能输入了一个引号之后按了回车。因为引号是成对的,如果只有一个引号,就会一直无法退出命令,此时只要再输入一个对应的引号,再输入分号结束即可。















 8781
8781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









