







1.智能指针
1、shared_ptr
- 原理:shared_ptr是基于引用计数的智能指针,用于管理动态分配的对象。无论 std::shared_ptr 存储在堆区还是栈区,它所指向的内存块始终存储在堆区。这是因为 std::shared_ptr 是用于管理动态分配的内存的智能指针,它需要存储在堆区,以便进行引用计数和自动释放内存
- 使用场景:适用于多个智能指针需要共享同一块内存的情况。例如在多个对象之间共享某个资源。
2、 unique_ptr
- 原理:unique_ptr是独占式智能指针,意味着他独占拥有所管理的对象,当其生命周期结束时,对象会自动销毁。
- 使用场景:适用于不需要多个指针共享同一内存的情况,即单一所有权。通常用于动态分配的对象
或文件句柄。
3、weak_ptr
- 原理:weak_ptr是一种弱指针,他不增加引用计数。它通常用于协助shared_ptr,以避免循环引用问题。
- 使用场景:适用于协助解决shared_ptr的循环引用问题,其中多个shared_ptr互相引用,会导致内存泄漏。
4、auto_ptr (已废弃)
- 原理:std::auto_ptr是C++98标准引入的智能指针,用于独占地管理对象。但由于其存在潜在的问题,已在C++11中被废弃。
- 使用场景:在C++98标准中,可用于独占性地管理动态分配的对象。不推荐在现代C++中使用。
2.栈和堆的区别
1、分配方式:
栈:栈是一种自动分配和释放内存的数据结构,它遵循"后进先出"(LIFO)原则。当你声明一个局部变量时,该变量存储在栈上。函数的参数和局部变量也存储在栈上。栈的分配和释放是自动的,由编译器管理。
堆:堆是一种手动分配和释放内存的数据结构。在堆上分配内存需要使用new或malloc等函数,释放内存则需要使用delete或free。堆上的内存不会自动释放,必须手动管理。
2、存储内容:
栈:栈主要存储局部变量、函数参数和函数调用的上下文。它的存储生命周期通常是有限的,当超出其作用域时,内存会自动释放。
堆:堆主要用于存储动态分配的对象和数据结构。它的存储生命周期没有那么明确,需要手动释放。
3、生命周期:
栈:栈上的变量生命周期与其作用域(通常是一个函数的执行)相对应。一旦超出作用域,栈上的变量将自动销毁。
堆:堆上的内存生命周期由程序员控制。在程序员显式释放内存之前,内存将一直存在。
4、分配速度:
栈:由于栈上的内存分配和释放是自动管理的,通常比堆更快。
堆:堆上的内存分配和释放需要较多的开销,通常比较慢。
5、大小限制:
栈:栈的大小通常受到限制,因为它由操作系统管理,可以很小,通常在几MB以内。
堆:堆的大小可以较大,受到系统资源的限制,通常比栈要大得多。
6、数据访问:
栈:栈上的数据访问速度较快,因为它是线性存储,访问局部变量通常只需要一次寻址操作。
堆:堆上的数据访问速度较慢,因为它是散乱存储,需要进行额外的寻址操作。
3.c++和c的不同
- C是面向过程的语言,而C++是面向对象的语言。
- C和C++动态管理内存的方法不一样,C是使用malloc/free函数,而C++除此之外还使用new/delete关键字。
- C++的类是C里没有的,但是C中的struct是可以在C++中正常使用的,并且C++对struct进行了进一步的扩展,使得struct在C++中可以和class有一样的作用。而唯一和class不同的地方在于struct成员默认访问修饰符是public,而class默认的是private。
- C++支持重载,而C语言不支持。
- C++有引用,C没有。
4.用const的目的
- 防止修改变量的值:将变量声明为 const 后,编译器会确保该变量的值在初始化后不能被修改。这有助于在程序中创建更加稳定和可维护的代码。
const int maxAttempts = 3;
// maxAttempts = 4; // 错误,无法修改常量
- 指定函数参数为只读:在函数定义中,使用 const 可以指定某个参数是只读的,防止在函数内部修改参数的值。
void printMessage(const std::string& message) {
// message += "!"; // 错误,无法修改只读参数
std::cout << message << std::endl;
}
- 确保成员函数不修改对象状态:在成员函数声明和定义中使用 const 关键字,可以确保该成员函数不会修改调用对象的状态。这种方法被称为常量成员函数。
class MyClass {
public:
void modifyState(); // 普通成员函数
void queryState() const; // 常量成员函数,不修改对象状态
};
- 指针常量或常量指针
指针常量(const 在 * 前面):只能修改指针指向,不能修改指针指向的值。
const int *p = a;
常量指针(const 在 * 后面):只能修改指针指向的值,不能修改指针指向。
int *p const = a;
5.重载和重写的区别
- 重载
定义:在同一个作用域内,允许存在多个同名的函数,但是这些函数的参数列表必须不同(包括参数的个数、类型、顺序等)。需要注意的是,与返回值无关。
目的:通过相同的函数名来处理不同类型的参数,提高代码的灵活性。 - 重写
定义:在派生类中重新实现(覆盖)其基类的虚函数。发生在继承关系中,子类重新定义基类的虚函数,实现子类自己的版本。
目的:支持多态性,允许基类的指针或引用在运行时指向派生类对象,并调用相应的派生类函数。
总结:
重载是指在同一作用域中定义多个同名函数,通过参数列表的不同来区分;
重写是指派生类重新实现(覆盖)其基类的虚函数,以支持多态性
6.定义指针时要注意的问题
- 初始化:指针在定义时最好立即初始化,可以为其赋予 nullptr(C++11 及以上)或 NULL,或者指向有效的内存地址。未初始化的指针具有不确定的值。
- 悬空指针:当指针指向的内存被释放后,如果不将指针置为 nullptr,该指针就成了悬空指针。使用悬空指针可能导致未定义行为。
int* ptr = new int; delete ptr; // ptr 现在是悬空指针 - 野指针:指针指向未知的内存地址,可能是未初始化的指针或者指向已释放的内存。使用野指针可能导致程序崩溃或不可预测的行为。
- 空指针解引用:尝试解引用空指针会导致未定义行为。在解引用指针之前,应该确保指针不为 nullptr。
- 指针的生命周期:指针在超出其作用域后不再有效,但如果指针指向的是动态分配的内存,需要手动释放以防止内存泄漏。
- 空指针与野指针:空指针(nullptr)表示指针不指向任何有效的内存地址,而野指针是指指针的值是一个不确定的地址。合理使用空指针,并尽量避免野指针。
7.c++内存分配
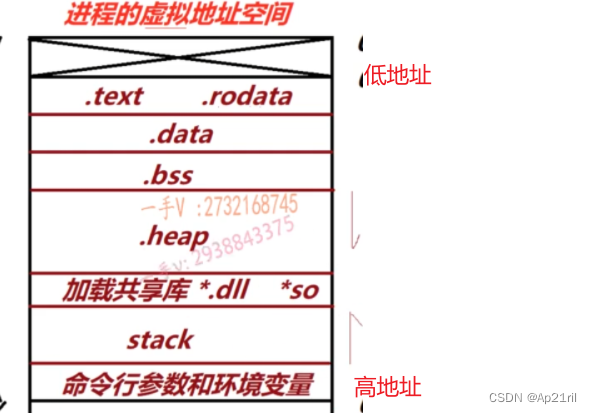
.text (代码段)存储指令
.rodata(只读数据段):存储只读数据
.data:存放初始化且初始化不为0的数据
.bss:存放未初始化且初始化为0的数据,其实在程序运行的时候,未初始化的数据会被内核初始化为0。
堆内存:程序运行后调用new malloc才会有堆内存,
加载共享库:当前程序在运行过程中会加载共享库。
栈内存:函数运行或产生线程时,每个线程独有的,栈内存。
#include<iostream>
using namespace std;
int data1 = 10; // .data
int data2 = 0; // .bss
int data3; // .bss
static int data4 = 11; // .data
static int data5 = 0; // .bss
static int data6; // .bss
int main()
{
int a = 12; //.text
int b = 0; //.text
int c; //.text
static int e = 13; // .data
static int f = 0; // .bss
static int g; // .bss
return 0;
}
8.new/delete和malloc/free的联系及区别
- 类型安全性
- new 和 delete:是C++运算符,可以确保类型安全。new 分配内存时会调用构造函数初始化对象,delete 会自动调用析构函数进行清理。
- malloc 和 free:是C标准库函数,不涉及构造和析构函数,需要手动调用构造和析构函数,可能导致类型安全问题。
- 内存块大小
- new:根据对象类型自动计算所需内存大小,不需要手动指定。
- malloc:需要手动指定要分配的内存块的大小。
- 返回类型
- new:返回指向已构造对象的指针。
- malloc:返回void*类型的指针,需要手动进行类型转换。
- new失败是通过异常来判断,malloc失败是通过与nullptr比较来实现。
- 开辟内存
- malloc只负责开辟内存,不负责初始化;new不仅负责开辟内存也负责初始化。
- new在开辟内存的时候是指定内存的,不需要进行内存强转;malloc是按字节分配的,需要进行类型强转,返回的是void*;
- 构造和析构
- new:会调用类的构造函数来初始化分配的内存。在释放内存时,会自动调用析构函数进行清理。
- delete:会调用类的析构函数来进行清理,然后释放内存。
- malloc:不会调用构造和析构函数,分配的内存块中的内容是未定义的。需要手动调用构造函数和析构函数。
- free:只会释放内存,不会调用析构函数。
- free只需要传入内存的起始地址就可以释放内存;delete在释放内存时,需要注意是单个元素还是数组元素
- 重载和重写
- new:可以通过重载自定义内存分配和释放操作符,实现更复杂的内存管理。
- delete:也可以通过重载自定义释放操作符。
- malloc 和 free:不能像 new 和 delete 一样进行重载。
9.c++是类型安全的语言吗(面试官提到了动态联编和静态联编)
C++ 是一种相对而言更加类型安全的编程语言。类型安全是指在编译时和运行时,程序对数据类型的使用都是合法的,不会发生未定义行为。C++ 在设计上考虑了类型安全,并提供了一些机制来减少类型相关的错误。
- 静态联编(Static Binding):在编译阶段,编译器将函数调用与具体的函数实现关联起来,这被称为静态联编。C++ 是静态类型语言,因此大部分的联编工作在编译时完成。这有助于在编译期发现一些类型相关的错误,提高了类型安全性。
- 动态联编(Dynamic Binding):在运行时,通过虚函数和多态性实现动态联编。C++ 支持运行时多态,允许在父类的指针或引用上调用子类的虚函数。这种机制在一定程度上提高了灵活性,但也引入了动态联编的概念。
- 强类型:C++ 是一种强类型的语言,即在编译时对类型的检查比较严格,不同类型之间的操作需要进行明确的类型转换。
- 静态类型检查:C++ 是一种静态类型检查语言,这意味着变量的类型在编译时就已经确定,不会发生隐式的类型转换错误。
- 面向对象的封装:C++ 支持面向对象编程,通过类的封装特性可以将数据和操作封装在一起,防止未授权的访问和修改。
- 模板和泛型编程:C++ 提供了模板和泛型编程的支持,允许程序员编写与类型无关的代码,提高了代码的通用性和类型安全性。
10.main函数前会有其他函数语句被执行吗
在标准的 C++ 程序中,main函数是程序的入口点,程序从main函数开始执行。在main函数执行之前,不会有其他普通函数被自动调用。然而,有一些特殊情况可能导致main函数执行前调用其他函数或执行其他代码。
- 全局对象的构造:在 C++ 中,全局变量和静态变量的构造函数会在main函数执行之前调用。这意味着如果你有全局对象,它们的构造函数将在main函数执行前执行。
#include <iostream>
class GlobalObject {
public:
GlobalObject() {
std::cout << "GlobalObject constructed!" << std::endl;
}
};
GlobalObject globalVar; // 全局变量,构造函数会在 main 函数执行前调用
int main() {
std::cout << "Inside main function!" << std::endl;
return 0;
}
例子中,GlobalObject 类的构造函数会在 main 函数执行前被调用。
11.虚函数实现
- 虚函数表(vtable):对于每个包含虚函数的类,编译器会在该类的对象中添加一个指向虚函数表的指针。虚函数表是一个数组,其中存储了类的虚函数的地址。每个类有一个对应的虚函数表。
- 虚函数指针(vptr):对象中的虚函数指针指向虚函数表。在对象的构造过程中,虚函数指针被设置为指向类的虚函数表。
- 动态绑定:当通过基类指针或引用调用虚函数时,实际调用的是对象的实际类型的虚函数。这种调用方式被称为动态绑定。编译器通过虚函数指针找到对象的虚函数表,然后在表中查找对应虚函数的地址。
12.tls握手
- 客户端向服务端发起第一次握手请求,告诉服务端客户端所支持的SSL的指定版本、加密算法及密钥长度等信息。
- 服务端将自己的公钥发给数字证书认证机构,数字证书认证机构利用自己的私钥对服务器的公钥进行数字签名,并给服务器颁发公钥证书。
- 服务端将证书发给客户端。
- 客服端利用数字认证机构的公钥,向数字证书认证机构验证公钥证书上的数字签名,确认服务器公开密钥的真实性。
- 客户端使用服务端的公开密钥加密自己生成的对称密钥,发给服务端。
- 服务端收到后利用私钥解密信息,获得客户端发来的对称密钥。
- 通信双方可用对称密钥来加密解密信息。
13.手撕算法冒泡排序
#include<iostream>
#include<vector>
using namespace std;
void bubbleSort(vector<int>& nums)
{
int n = nums.size();
for (int i = 0; i < n - 1; i++)
{
bool flag = false;
for (int j = 0; j < n - i - 1; j++)
{
if (nums[j] > nums[j + 1])
{
int tmp = nums[j];
nums[j] = nums[j+1];
nums[j + 1] = tmp;
flag = true;
}
}
if (!flag) return;
}
}
int main()
{
vector<int> nums = { 64, 34, 25, 12, 22, 11, 90 };
for (int i = 0; i < nums.size(); i++)
{
cout<< nums[i] << " ";
}
cout << endl;
bubbleSort(nums);
for (int i = 0; i < nums.size(); i++)
{
cout<< nums[i] << " ";
}
return 0;
}
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











