







来自cvpr2020关于语义分割任务的文章
Cars Can’t Fly up in the Sky: Improving Urban-Scene Segmentation via Height-driven Attention Networks
文章标题比较风趣幽默、
也简明扼要点出中心,会引人入胜
文章核心:在城市场景中,垂直区域的物体有着显著的差异,就像汽车不可能飞在天空中一样。

作者运用这个这个特征来提高城市场景中网络的一致性精度:即MIOU
1、MIOU定义
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值和预测值。在每个类上计算IoU,之后平均。计算公式如下: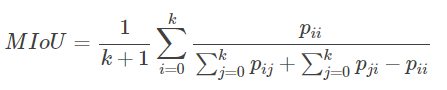
i表示真实值,j表示预测值 ,p_{ij}pij 表示将i预测为j 。

2、直观理解
为:计算两圆交集(橙色部分)与两圆并集(红色+橙色+黄色)之间的比例,理想情况下两圆重合,比例为1的实现
3、MIOU实现
(1)先求混淆矩阵
(2)再求mIOU
混淆矩阵的每一行再加上每一列,最后减去对角线上的值
import numpy as np
class IOUMetric:
“”"
Class to calculate mean-iou using fast_hist method
“”"
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
# 找出标签中需要计算的类别,去掉了背景
mask = (label_true >= 0) & (label_true < self.num_classes)
# # np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
# 输入:预测值和真实值
# 语义分割的任务是为每个像素点分配一个label
def ev aluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
assert len(lp.flatten()) == len(lt.flatten())
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
# miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iou)
# -----------------其他指标------------------------------
# mean acc
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.nanmean(np.diag(self.hist) / self.hist.sum(axis=1))
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()
return acc, acc_cls, iou, miou, fwavacc
垂直位置上的城市场景数据集的类别分布
所以,如果能够识别任一像素所处的这个图像的部分,就有助于语义分割的像素集的分类
新型的高度注意力驱动网络HAnet,作为城市场景语义分割的通用附加模块:在给定一个输入的特征图的情况下,HAnet将提取代表每一个部分的高度上下维信息,然后从高度上下维信息中预测每一个水平部分的特征或类别。
这个网络主要就是提取高度上下维信息,,还有使用上下维计算高度驱动的注意力权重,以表示每一行的特征或者类的重要性。


作者在原文中说道,提出一种轻量级的模块:HAnet,可以很好地添加到各种现有模块中。并且通过实验证明模块的高效性和广泛适用性。
将HAnet添加到ResNet—101,在计算资源资源增加很少的情况下,在Cityspace上取得了最新的最优成绩
最后,作者通过可视化各个通道的注意力权重来阐明可靠性
cityspace数据集
CityScape数据集
介绍
Cityscapes是关于城市街道场景的语义理解图片数据集。它主要包含来自50个不同城市的街道场景,拥有5000张在城市环境中驾驶场景的高质量像素级注释图像(其中 2975 for train,500 for val,1525 for test, 共有19个类别);此外,它还有20000张粗糙标注的图像(gt coarse)。

数据集结构

cityspace介绍源
HAnet高度注意力网络的结构

具体说明参考
link
然后运用到RESNE101T网络里
RESNET
link
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深。
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式。identity mapping和residual mapping
1.identity mapping
如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
2.esidual mapping
抄近道

又分为两种设计:分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目。

最后,解决一个问题:channel合并问题
1.他们的channel个数一致,所以采用计算方式:
y=F(x)+x
2,。他们的channel个数不同,所以采用计算方式:
y=F(x)+Wx
即,做一个卷积,让他们的通道数相同















 3195
3195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









