










目录
map的实现方式有多种,比如哈希表、红黑树等。Golang的map底层是用哈希表实现的,在介绍Golang map的实现之前首先介绍一下哈希表的两种实现方式:
1、哈希表的两种实现方式
1.1、开放寻址法
开放寻址法,底层是一个数组,每个数组都存放一个键值对,空闲的地方就是没有放键值对的地方。首先看如何插入:key-val首先经过一个哈希函数将key值进行哈希得到一个大的数字,然后将其对数组的长度取模,这样它就落在了数组中的一个位置。如果得到的位置没有被占用,那么就直接存放在对应位置。如果已经被占用了,那么就向后寻找一个槽,直到找到空闲的槽。读取也是同样的步骤,先哈希再取模,然后去对应的槽位寻找,如果没有找到,就向后找。

1.2、拉链法
拉链法前两个步骤一样,也是先哈希再取模,然后会落到数组的一个槽中(每个槽并不存放k-v数据,它们都是指针),然后使用链表将k-v连接起来。查询的时候,获取槽位后,遍历链表来查询。

2、Go语言map源码分析
Go语言的map是用拉链法来实现的,但是与上面所说的也有所不同。
实现map的文件为runtime包下的map.go
注意: 使用的go sdk的版本为:go1.18
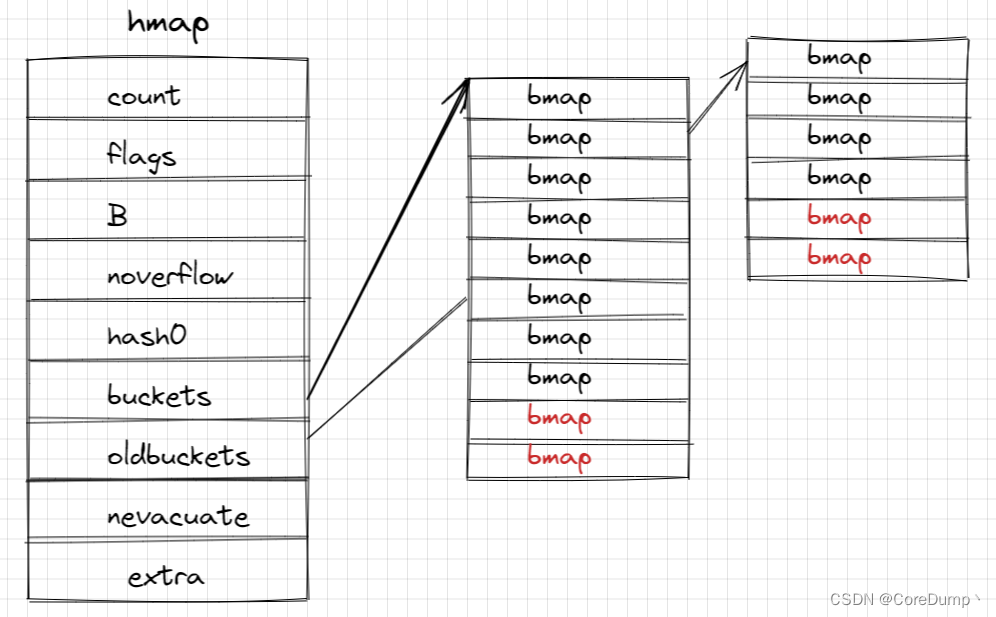
2.1 map的结构
map的底层为一个结构体,结构体如下:
// Go map 的底层结构体表示
type hmap struct {
count int // map中键值对的个数,使用len()可以获取
flags uint8
B uint8 // 哈希桶的数量的log2,比如有8个桶,那么B=3
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向哈希桶数组的指针,数量为 2^B
oldbuckets unsafe.Pointer // 扩容时指向旧桶的指针,当扩容时不为nil
nevacuate uintptr
extra *mapextra // 可选字段
}
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits // 桶数量 1 << 3 = 8
)
// Go map 的一个哈希桶,一个桶最多存放8个键值对
type bmap struct {
// tophash存放了哈希值的最高字节
tophash [bucketCnt]uint8
// 在这里有几个其它的字段没有显示出来,因为k-v的数量类型是不确定的,编译的时候才会确定
// keys: 是一个数组,大小为bucketCnt=8,存放Key
// elems: 是一个数组,大小为bucketCnt=8,存放Value
// 你可能会想到为什么不用空接口,空接口可以保存任意类型。但是空接口底层也是个结构体,中间隔了一层。因此在这里没有使用空接口。
// 注意:之所以将所有key存放在一个数组,将value存放在一个数组,而不是键值对的形式,是为了消除例如map[int64]所需的填充整数8(内存对齐)
// overflow: 是一个指针,指向溢出桶,当该桶不够用时,就会使用溢出桶
}
map结构的图表示为如下:
map的底层为hmap结构体,其中包含了很多字段,buckets是一个数组,大小是2的B次方个。数组中的每一个是一个bmap结构体的哈希桶,bmap包含了4个字段,后面三个字段在编译时才能确定。tophash、keys、elems都是大小为8的数组,它们每个元素一一对应。
tophash存放哈希值的最高字节,keys存放了键,elems存放数据。
每个桶只能存放最多8个键值对,因此当某个桶不够用时,就会使用溢出桶,溢出桶是和普通桶在一起的,都是在buckets指向的bmap数组中,(实际上,当B >= 4时,才会创建溢出桶,溢出桶的数量为 1 << (B - 4) )。overflow指向下一个溢出桶。下面为了画图方便,在B < 4时,也画了溢出桶,实际上是没有溢出桶的。
Go语言的map并没有将键值对一起存放,而是将键值分开存放。是因为如果存放在一起可能需要内存对齐,会导致空间的浪费,存放在一起会使内存更紧凑,也不会损失什么性能。

2.2 map的初始化
我们在使用map的时候的初始化方式主要有两种:一种是使用字面量初始化,一种是使用make
m1 := map[string]int{"a" : 1, "b" : 2}
m2 := make(map[string]int, 10)
接下来我们看这两种初始化方式在底层到底是怎么做的:
首先看一段代码,使用 go build -gcflags -S main.go 来生成汇编代码
// main.go
package main
import "fmt"
func main() {
m1 := map[string]int{"a": 1, "b": 2}
m2 := make(map[int]string, 10)
fmt.Println(m1, m2)
}
生成的汇编文件的一段如下:

我们可以看到,这两种初始化方式分别调用了runtime.makemap_small() 和 runtime.makemap(),但不管是字面量初始化还是make初始化,如果初始化的键值对数量比较小就会使用makemap_small,否则就使用makemap()。经过测试,当初始化的数量大于8时,也就是字面量中的键值对数量大于8或make中的第二个参数大于8,就会使用makemap()来进行初始化。
接下来我们找到这两个函数(其中省略了一些暂时不关注的内容):
// makemap_small 实现了Go map的构造
// make(map[k]v, hint) 当hint最多为bucketCnt=8时,就会使用该函数来构造map
func makemap_small() *hmap {
// 就是new了一个hmp的结构体,随机生成hash0,然后返回它的指针
h := new(hmap)
h.hash0 = fastrand()
return h
}
func makemap(t *maptype, hint int, h *hmap) *hmap {
...
// 构造hmap结构体
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// 根据传入的数据的数量来算出需要的B的大小
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 分配哈希桶的内存空间
// 如果B为0,那么将会进行延迟分配
if h.B != 0 {
var nextOverflow *bmap
/*
创建哈希桶以及一些溢出桶,假设创建了8个桶,那么只能存放 8 * 8 = 64对键值,如果再存放的话,就会溢出,因此会多创建一些溢出桶
这些溢出桶会存放在extra字段中
*/
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果有溢出桶,就初始化extra字段,保存下一个可用溢出桶的地址
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
// 保存了下一个可用的溢出桶的地址
nextOverflow *bmap
}
// 创建哈希桶数组
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
// 计算数组大小 base := 1 << b
base := bucketShift(b)
nbuckets := base
// 当b >= 4 时会创建溢出桶,溢出桶的数量为 1 << (b - 4)
if b >= 4 {
// 计算加上溢出桶后的数组大小,溢出桶跟普通桶是在一起的,溢出桶在数组尾部
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
// 创建数组
if dirtyalloc == nil {
buckets = newarray(t.bucket, int(nbuckets))
} else {
// dirtyalloc was previously generated by
// the above newarray(t.bucket, int(nbuckets))
// but may not be empty.
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
// 如果存在溢出桶,计算溢出桶的地址
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
// 返回普通桶和溢出桶的地址
return buckets, nextOverflow
}
makemap_small: 我们可以看到,它直接new了一个hmap,然后返回hmap的指针。与Go中的切片不同,切片是返回一个结构体,而map返回的是结构体的指针。
makemap: new了一个hmap的结构体,然后根据传入的数据的数量来算出需要的B的数量。然后进行哈希桶的内存分配,它还会多创建一些溢出桶,extra结构体的nextoverflow字段保存了这些溢出桶,最后返回hmap的指针。
makeBucketArray: 创建哈希桶数组,根据b来计算数组的大小,如果b>=4,还会创建一些溢出桶,溢出桶的数量为 1 << (b - 4)。计算完后,创建数组,然后返回普通桶和溢出桶的地址。
在创建map的时候,首先要确定B,假设B为3,那么桶的数量就为2^3=8,其次,如果B >= 4,也会创建一些溢出桶。然后创建mapextra类型的结构体,其中的nextoverflow保存了下一个可用的溢出桶的地址。
假设位于一号槽的桶已经用满了,那么就会使用extra字段来寻找一个新的可用的溢出桶,然后使用bmap中的overflow字段指向溢出桶来组成一个链表。
图示如下:
说明:图中普通桶的数量为8个,是不应该有溢出桶的,但是为了画图方便,就假设也有溢出桶。

map字面量赋值的两种方式
- 当元素少于25个时,转化为简单赋值:

- 元素多于25个时,转化为循环赋值:

2.3 map的访问
map的访问,首先要获取桶号,然后循环匹配该桶和溢出桶中的tophash的值,每个桶中的tophash没有保存哈希值的全部,而是保存了高八位,是为了快速遍历。匹配成功,还要验证key值是否相等,如果相等就说明找到了。
在访问map时有两种返回值:第一种,只获取值;第二种,获取值和是否查询到
val := m["a"]
val, ok := m["a"]
源码如下:
// mapaccess1 返回一个指针,这个指针不会为nil,如果key不存在,则返回该值对应的0值
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
... // 省略了相关代码
// 如果h为nil 或者数量为0,如果为nil说明map没有初始化,可能会panic
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
// 返回对应的0值
return unsafe.Pointer(&zeroVal[0])
}
// 防止map并发读写,检测到并发读写就panic
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 对key和hash0进行哈希,计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
// 计算桶掩码m,m & hash即可得到桶号
// 假设 B=3,那么 m = 1 << 3 - 1 = 0b1000 - 0b1 = 0b111, 此时 m & hash即可得到hash的后三位,即为桶号
m := bucketMask(h.B)
// 根据桶号获取bmap类型的哈希桶
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如何h.oldbuckets != nil,说明此时map正在扩容,需要判断当前要访问的key是在新桶中还是在旧桶中
if c := h.oldbuckets; c != nil {
// 如果不是等量扩容,那么桶的数量会增加一倍,因此掩码需要右移一位来查找在旧桶中的位置
// 因为扩容后,在插入或删除数据后,会驱逐一部分的数据到新桶中,一个旧桶的数据会被驱逐到两个桶中
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
// 计算旧桶的地址
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 判断数据是否被驱逐了,如果没有被驱逐,应该在旧桶中查找
// 这个函数的逻辑很简单,就是判断tophash[0]是否在大于1且小于5,因为被驱逐的桶的tophash被置为4
if !evacuated(oldb) {
b = oldb
}
}
// 计算tophash,也就是hash的高八位
top := tophash(hash)
bucketloop:
// 遍历哈希桶以及溢出桶
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 匹配tophash成功后,根据在tophash中的偏移,计算key的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 比较是否是要找的key
if t.key.equal(key, k) {
// 如果是,则计算val的地址
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
// 返回val
return e
}
}
}
// 没有找到,返回对应的0值
return unsafe.Pointer(&zeroVal[0])
}
// mapaccess2与mapaccess逻辑相同,只是多了个bool的返回值,如果没有找到就为false,否则为true
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
...
}
下面假设map没有扩容,正常查找数据,扩容的情况在后面讲解。
假设要查找的键为"a"
-
首先要计算桶号:
将a与hash0一同进行哈希运算,输出一长串哈希值。然后根据B来取二进制哈希值的后B位,得到的值即为桶号,假设B为3,那么取后三位为010b也就是2,那么桶号就是2

-
然后计算tophash
取哈希值的高八位作为tophash,16进制为0x5c

-
匹配
算出tophash后,再tophash数组中进行一一匹配,如果没有找到,则查看overflow是否为nil,不为nil则匹配溢出桶中的tophash,直到匹配成功或者到最后也找不到。如果找到了,也不一定是我们想要的,因为如果哈希碰撞的比较厉害,一个桶中的tophash可能有相等的,因此需要再进行key值的比较,如果相同,就找到了相匹配的键值对。如果key值不相同,就继续从tophash中找。

2.4 map的插入
map的插入首先要查找要插入的key是否已经存在,如果存在就更新新的value。如果不存在,就插入一条记录。
源码如下:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 如果没有初始化就直接panic
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
... // 省略了一些调试相关代码
// 防止并发写入,并发写入就panic
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
// 设置正在写入的标志
h.flags ^= hashWriting
// buckets内存空间的滞后申请,如果使用makemap_small来创建map,就会在此时申请空间
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 计算桶号
bucket := hash & bucketMask(h.B)
// 如果map正在扩容,需要额外做一些扩容的工作,后面再讲,暂时不关注
if h.growing() {
growWork(t, h, bucket)
}
// 获取key可能存在的哈希桶地址
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// 计算tophash
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
// 下面这个循环用来判断当前key是否存在,如果存在就直接修改数据,如果不存在就找一个可以存放数据的位置
bucketloop:
for {
// 首先要查询key是否已经存在
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 判断当前哈希桶是否是空的,如果是空的说明key不存在,找一个位置来存放k-v
if isEmpty(b.tophash[i]) && inserti == nil {
// 记录插入的tophash、k、v的地址
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
// 哈希桶是空的,说明不存在该key,直接调出最外层循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 匹配到了tophash,但是不一定是要找的key,因为不同的key,tophash可能相同
// 计算key在哈希桶中的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 不是要找的key,继续循环
if !t.key.equal(key, k) {
continue
}
// key已经存在,更新对应的值
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// val已经更新直接跳到done
goto done
}
// 查找溢出桶
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 判断是否需要扩容,扩容的条件是达到了最大的负载因子或者有太多的溢出桶,后面讲
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// 说明当前桶或者当前桶和溢出桶没有可用的槽位了,需要再分配一个溢出桶
newb := h.newoverflow(t, b)
// 然后获取tophash、k、v存放的地址
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 存放新的键值对
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
map的插入步骤:
- 首先根据key和hash0计算桶号以及tophash,然后在哈希桶中根据tophash查找,如果一个位置的tophash为"空"(tophash
<= 1),说明该位置以及后面都为空,没有该key。因此直接将k-v存放在此处即可。 - 如果匹配到了相同的tophash,还要对比key是否相等。key值相等,就直接修改val。
- 如果key不相等,继续查找,直到找不到,如果找不到就找一个空位用来存放数据。
- 判断是否找到了空位,如果没有找到,需要创建一个溢出桶,将数据存放入溢出桶中。
2.5 map的删除
map的删除首先要查找key值是否存在,如果存在,就删除key-val,如果val中存在指针,就需要删除,因为需要解除对该指针的引用,以便垃圾回收器回收垃圾,否则就不用删除。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
... // 省略了调试相关代码
// 防止并发写入
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
h.flags ^= hashWriting
// 计算桶号
bucket := hash & bucketMask(h.B)
// 如果map正在扩容,需要进行扩容工作,稍后介绍
if h.growing() {
growWork(t, h, bucket)
}
// 根据桶号计算哈希桶地址
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
// 计算tophash
top := tophash(hash)
// 查找要删除的key是否存在
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 如果tophash为0,说明key不存在,直接跳出循环
if b.tophash[i] == emptyRest {
break search
}
continue
}
// 找到了相匹配的tophash,还需要对比key值是否相等
// 计算key在数组中的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 对比key值,不相等就继续查找
if !t.key.equal(key, k2) {
continue
}
// 到此为止,说明已经找到了key-val
// 删除key-val
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 将对应的tophash置为1
b.tophash[i] = emptyOne
...
notLast:
h.count--
// Reset the hash seed to make it more difficult for attackers to
// repeatedly trigger hash collisions. See issue 25237.
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}
}
map的删除步骤:
前面的步骤都差不多,计算桶号、tophash,然后在哈希桶中查找tophash,找到后,再对比key值。最终,如果找到key,就删除k-v,重置对应的tophash。
2.6 map的清空
map的清空方式有两种:1、make一个新的map;2、使用for range一个一个删除
m1 = make(map[string]int)
for k := range m1 {
delete(m1, k)
}
第一种会解除上一个map的引用,然后重新创建一个map,垃圾回收器会自动回收旧的map。
第二种会被go的编译器进行优化,调用mapclear函数。

mapclear的源码如下:
就是重置了其中的一些字段,然后新建了一个bucket数组
func mapclear(t *maptype, h *hmap) {
...
if h == nil || h.count == 0 {
return
}
// 重用hmap结构体
// 重置其中的字段
h.flags ^= hashWriting
h.flags &^= sameSizeGrow
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
h.count = 0
h.hash0 = fastrand()
// Keep the mapextra allocation but clear any extra information.
if h.extra != nil {
*h.extra = mapextra{}
}
// makeBucketArray clears the memory pointed to by h.buckets
// and recovers any overflow buckets by generating them
// as if h.buckets was newly alloced.
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// If overflow buckets are created then h.extra
// will have been allocated during initial bucket creation.
h.extra.nextOverflow = nextOverflow
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
那么哪个的速度更快呢?我们可以进行一个基准测试:
package test
import (
"testing"
)
const C = 1000
func BenchmarkMapDelete1(b *testing.B) {
m := make(map[int]int, C)
for i := 0; i < b.N; i++ {
for i := 0; i < C; i++ {
m[i] = i
}
m = make(map[int]int, C)
}
}
func BenchmarkMapDelete2(b *testing.B) {
m := make(map[int]int, C)
for i := 0; i < b.N; i++ {
for i := 0; i < C; i++ {
m[i] = i
}
for k := range m {
delete(m, k)
}
}
}
C = 1000, 10000, 100000 时的测试数据如下
goos: windows
goarch: amd64
pkg: code/source_code_analyse/test
cpu: Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz
# 1000
BenchmarkMapDelete1-8 40911 29330 ns/op
BenchmarkMapDelete2-8 55832 22061 ns/op
PASS
ok code/source_code_analyse/test 3.146s
# 10000
BenchmarkMapDelete1-8 3655 302420 ns/op
BenchmarkMapDelete2-8 5011 247473 ns/op
PASS
ok code/source_code_analyse/test 2.585s
# 100000
BenchmarkMapDelete1-8 302 3923456 ns/op
BenchmarkMapDelete2-8 378 3239029 ns/op
PASS
ok code/source_code_analyse/test 3.320s
可以看到,使用for range的方式更快。
2.7 总结
- Go语言使用拉链法实现了map
- 在哈希桶中,使用长度为8的数组来存放tophash以及key和value
- 每个哈希桶超过8个数据,就会创建新的溢出桶来存放数据,溢出桶逻辑上组成一个链表
3 map的扩容
map为什么需要扩容?
首先就是当可用空间不足时就需要扩容。其次当哈希碰撞比较严重时,很多数据都会落在同一个桶中,那么就会导致越来越多的溢出桶被链接起来。这样的话,查找的时候最坏的情况就是要遍历整个链表,时间复杂度很高,效率很低。而且当删除了很多元素后,可能会导致虽然有很多溢出桶,但是桶中的元素很稀疏。
map扩容的时机:
- 达到最大的负载因子(6.5,也就是平均每个桶中k-v的数量大于6.5)
- 溢出桶的数量太多
在mapassign中会判断是否要扩容:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
// 如果达到了最大的负载因子或者有太多的溢出桶
// 或是是已经在扩容中
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
}
- map溢出桶太多时会导致严重的性能下降
- runtime.mapassign()可能会触发扩容的情况:
- 负载因子超过6.5(平均每个槽6.5个key)
- 使用了太多的溢出桶(溢出桶超过了普通桶)
map扩容的类型:
- 等量扩容:数据不多但是溢出桶太多了(整理)
- 翻倍扩容:数据太多了
等量扩容,溢出桶太多了,导致查询效率低。扩容时,桶的数量不增加。
翻倍扩容,每个桶的k-v太多了,需要增加普通桶的数量,扩容后桶的数量为原来的两倍。
3.1 map扩容的步骤
步骤1:创建新桶
- 创建一组新桶
- oldbuckets指向原有的桶数组
- buckets指向新的桶的数组
- map标记为扩容状态
如下图为翻倍扩容:
代码如下:
func hashGrow(t *maptype, h *hmap) {
// 扩容后的数量为oldbucketcnt << bigger
bigger := uint8(1)
// 如果不是超过了负载因子,那么就是等量扩容,否则就是翻倍扩容
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
// 记录旧的桶的数组
oldbuckets := h.buckets
// 创建新的桶,桶的数量为1 << (h.B+bigger)
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
... // 省略了一些不太关注的代码
// 更新其它字段
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets // oldbuckets指向旧的桶
h.buckets = newbuckets // buckets指向新创建的桶
h.nevacuate = 0
h.noverflow = 0
// 更新extra字段,使其指向新的桶的溢出桶
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
步骤2:迁移数据
- 将所有的数据从旧桶驱逐到新桶
- 采用渐进式驱逐
- 每次操作一个旧桶时(插入、删除数据),将旧桶数据驱逐到新桶
- 读取时不进行驱逐,只判断读取新桶还是旧桶
在每次插入或删除数据时,会判断map是否在扩容,如果在扩容就需要执行一些扩容的工作,也就是将旧桶中的数据驱逐到新桶,会驱逐当前要操作的桶及其溢出桶。
假设原来的桶的数量为4,那么B为2。当进行翻倍扩容后,桶的数量为8,B为3。那么这里就体现出了使用B的智慧,扩容后B为3,那么取哈希值的二进制后三位就有两种情况:010b和110b,分别是2和6。所以原来二号桶中的数据就会分布到新桶数组的2号和6号桶中。


源码为:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B) // 计算桶号 hash & (1 << h.B - 1), 假设B为3,那么就是 hash & (7) ==> hash & 111b,也就是取后三位
if h.growing() {
// 调用growWork进行扩容
growWork(t, h, bucket)
}
...
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 驱逐
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 计算要驱逐的旧桶的地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 计算增长之前的桶数
newbit := h.noldbuckets()
// 如果当前桶还没有被驱逐,就进行驱逐
if !evacuated(b) {
// x y 包含了疏散的目的地(低和高).
// 一个旧桶中的数据会被驱逐到两个桶中
var xy [2]evacDst
// x为低疏散目的地,比如在旧桶中为2,在新桶中也为2
// x.b是桶的地址 x.k是keys数组的地址 x.e是elems的地址
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 如果不是等量扩容,旧桶的数据还会被疏散到其它桶,比如旧桶为2,新桶为110b,也就是6
if !h.sameSizeGrow() {
/* y为高疏散的目的地
newbit = h.noldbuckets()
func (h *hmap) noldbuckets() uintptr {
oldB := h.B
if !h.sameSizeGrow() {
oldB--
}
return bucketShift(oldB)
}
假设扩容前B=2, 扩容后B=3, 那么newbit = 1 << (3--) = 4
oldbucket + newbit = 6
*/
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 开始疏散工作
for ; b != nil; b = b.overflow(t) {
// 要迁移的旧桶的keys数组的开始地址
k := add(unsafe.Pointer(b), dataOffset)
// 要迁移的旧桶的elems数组的开始地址
e := add(k, bucketCnt*uintptr(t.keysize))
// 循环将桶中的数据进行疏散迁移
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
// 计算hash来决定将k-v存放到x还是y中
hash := t.hasher(k2, uintptr(h.hash0))
...
if hash&newbit != 0 {
useY = 1
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 重置旧桶中对应的tophash的值, evacuatedX为2,因此如果tophash为2说明在低目的地中,为3说明在高目的地中
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 根据计算出的useY来决定将k-v放入哪个桶
dst := &xy[useY]
// 如果dst满了,需要创建一个溢出桶
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 迁移数据
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
步骤3:回收旧桶
- 所有旧桶驱逐完成后,回收oldbuckets
3.2 扩容时访问数据
在map扩容期间访问map需要确定数据是在旧桶还是在新桶中,也就是判断数据是否已经被疏散到新桶中。
在mapaccess1中:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 根据是否有oldbuckets来判断map是否正在扩容
if c := h.oldbuckets; c != nil {
// 如果是翻倍扩容,掩码要右移1来重新获取key在旧桶中的桶号
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果数据没有被驱逐,那么就去旧桶中查收数据
if !evacuated(oldb) {
b = oldb
}
}
...
}
3.3 总结
- 负载因子太大或者溢出桶太多,会触发map扩容
- ”扩容”可能并不是增加桶数,而是整理
- map扩容采用渐进式,桶被操作时才会重新分配














 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









