







根据实际情况,如此题库的特征是有横向的答案ABCD也有竖的。所以解决办法:
第一步:数据预处理:横的选项全部变为竖的选项
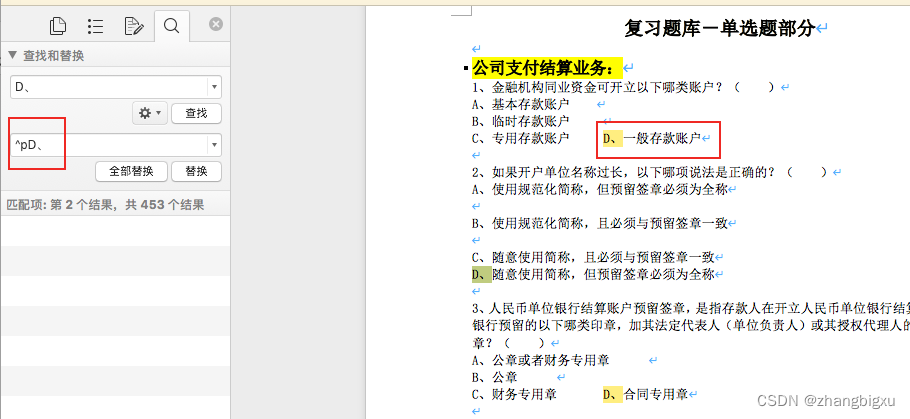
D、替换为 ^pD、就会在D选项前换行
第二步:剔除多余的空行
如下图替换操作
**

第三步:空格标识符替换为空白
第三步Python处理:也可以别的方式
# coding=utf-8
# -*- coding: UTF-8 -*-
#import xlrd
import xlwt
from docx import Document
#xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高 ,xlwt:主要对xls文件进行写操作且效率高,但是不能执行xlsx文件
#本文用的xlwt为1.3.0 python-docx是0.8.8版本 xlwt版本太高会报#错Reason: Incompatible library version: etree.cpython-37m-darwin.so requires version 12.0.0 or later,
def is_number(s):#判断是不是数字
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError, ValueError):
pass
return False
tiKu = "001.docx"# 预处理好的Word
count = 0
doc = Document(tiKu)
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('sheet1', cell_overwrite_ok=True)
for para in doc.paragraphs:
# if is_number(para.text[0])==False: #不是数字所以是标题
# sheet.write(count, 0, para.text) # 写标题
# count = count + 1
# else:#第一个字符是数字所以是题目写题目
if 'A、' in para.text:
sheet.write(count,1,para.text)
elif 'B、' in para.text:
sheet.write(count, 2, para.text)
elif 'C、' in para.text:
sheet.write(count, 3, para.text)
elif 'D、' in para.text:
sheet.write(count, 4, para.text)
count = count + 1
elif 'E、' in para.text: #对有EF答案的处理
count = count - 1
sheet.write(count, 5, para.text)
count = count + 1
elif 'F、' in para.text:
count = count - 1
sheet.write(count, 6, para.text)
count = count + 1
else:
sheet.write(count, 0, para.text) #写题干
wbk.save('001.xls') #生成的Excel题库
第四步:匹配答案:我的方法是把Word(里有答案)转为Excel再导入MySQL。使用Python模糊查询
import pymysql.cursors
import xlwt
import xlrd
import xlutils.copy
import re
#xlwt只能写入新建的Excel
import pandas as pd
from docx import Document
def mysql(chaxun,i):
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
passwd='haha',
db='tiku',
charset='utf8'
)
# if conn:
# print("连接成功!")
cursor = conn.cursor() # 获取游标
sql = "SELECT right(NAME, 9) FROM tiku2 WHERE name LIKE %s" # sql语句
cursor.execute(sql,chaxun)
result = cursor.fetchall()
if result!=():
return result[0]
else:
return '1'
if __name__ == '__main__':
compileX = re.compile(r"[a-zA-Z]")
i = 0
Workbook = xlrd.open_workbook('001.xls')
mySheet2 = Workbook.sheet_by_index(1)
wt=xlutils.copy.copy(Workbook)
sheets=wt.get_sheet(1)#读取第二个工作表
while i<441:
myCell = mySheet2.cell(i, 1) #i行1列
chaxun = myCell.value[2:-7]
a=mysql('%'+chaxun+'%',i)
if a!='1':
str = ''.join(a) # tuple转为字符串
x = compileX.findall(str) #匹配字母
sheets.write(i, 2, x)#写入
i += 1
wt.save("001.xls")
处理论述题
# coding=utf-8
# -*- coding: UTF-8 -*-
import xlwt
from docx import Document
#xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高 ,xlwt:主要对xls文件进行写操作且效率高,但是不能执行xlsx文件
#xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高 ,xlwt:主要对xls文件进行写操作且效率高,但是不能执行xlsx文件
#本文用的xlwt为1.3.0 python-docx是0.8.8版本 xlwt版本太高会报#错Reason: Incompatible library version: etree.cpython-
def is_number(s):#判断是不是数字
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError, ValueError):
pass
return False
tiKu = "运营管理岗位资格考试复习题库-论述.docx"#
count = 0
doc = Document(tiKu)
wbk = xlwt.Workbook()
k=2
sheet = wbk.add_sheet('sheet1', cell_overwrite_ok=True)
for para in doc.paragraphs:
if para.text[0]in ['1','2','3','4','5','6','7','8','9','0'] : #上一个是题干这一个是题目
count = count + 1
sheet.write(count,1,para.text)
zpx=True#是题目
k=2
else:
sheet.write(count, k, para.text)
k += 1
zpx=False#是题干
wbk.save('运营管理岗位资格考试复习题库-论述.xls')

















 8528
8528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









