










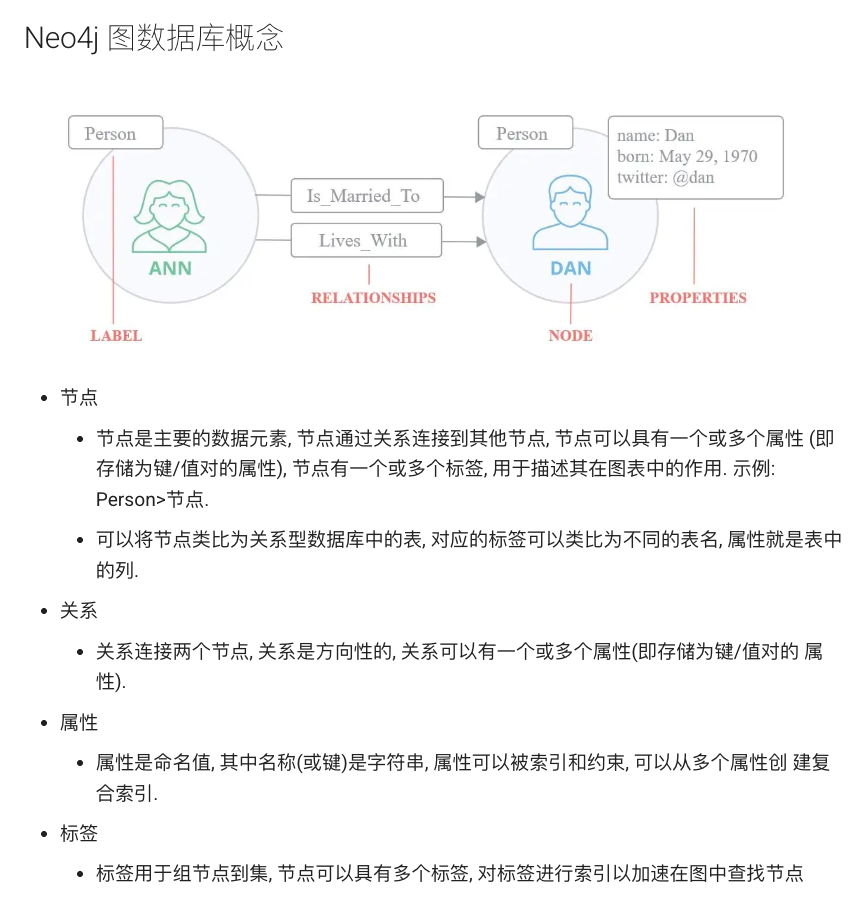
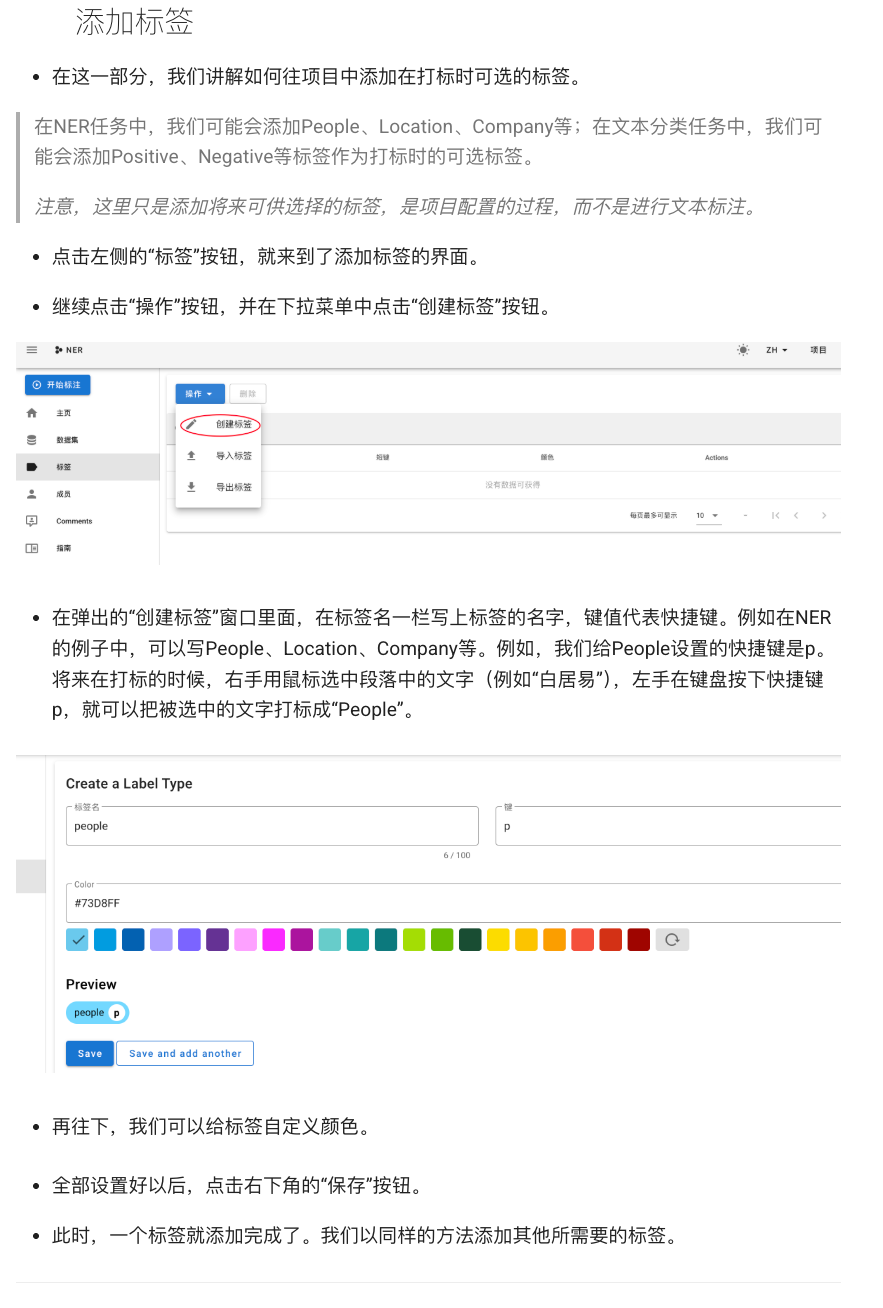
1. 背景与定义 (Background & Definition)
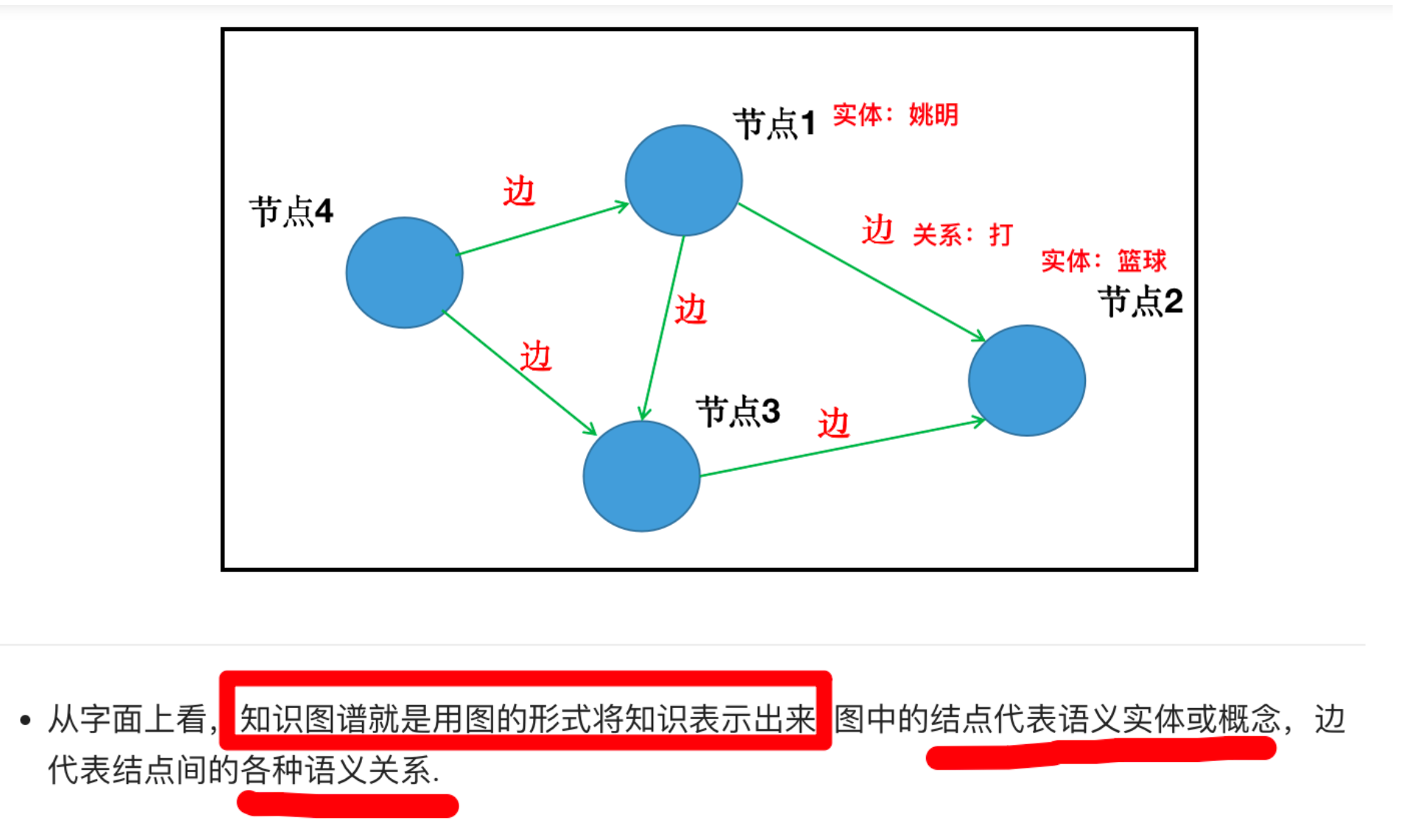
在大数据和人工智能的时代,知识图谱(Knowledge Graph)已成为连接信息与认知的重要技术手段。简单来说,知识图谱是一种以图结构表示知识的形式:节点代表实体或概念,边代表实体之间的关系 。举个例子,我们可以用三元组的形式表示知识:<姚明,职业,篮球运动员> 表示“姚明”的职业是“篮球运动员”。其中“姚明”和“篮球运动员”就是两个实体节点,而它们之间的边(关系)是“职业” 。这种 主语-谓语-宾语 的三元组结构常被称为 RDF(资源描述框架)表示,用来将互联网的信息组织成更接近人类认知的结构化形式 。可见,知识图谱以结构化的形式描述客观世界中的概念、实体及其关系,为组织、管理和理解海量信息提供了一种有效途径 。
从起源来看,“知识图谱”概念由谷歌在2012年正式提出,最初用于增强搜索引擎的智能化 。谷歌的知识图谱将互联网上分散的信息整合成巨大的语义网络,为用户查询提供直接而精准的答案。这一创举掀起了业界和学术界对知识图谱的研究热潮 。随后,知识图谱技术迅速演进并广泛普及,逐步应用于智能搜索、智能问答、个性化推荐、智能助手、金融风控、医疗决策等众多领域 。目前,知识图谱已被视为人工智能的重要分支技术之一,与大数据和深度学习并称为推动AI发展的“三大支柱” 。它能将Web上的海量数据及其关联关系转化为可计算的知识网络,使信息更易被机器理解和利用,从而推进万维网从信息网迈向知识网 。
知识图谱的构建融合了语义网(Semantic Web)、本体论(Ontology)和图数据库等理念,其发展经历了从早期的语义网络、框架表示,到大规模开放知识库(如Freebase、DBpedia)以及工业界的企业级知识图谱的演进过程。在这个过程中,一系列关键技术(如知识提取、知识融合、语义推理等)不断成熟,使得构建大规模知识图谱成为可能。总的来说,知识图谱可以被定义为一个结构化的语义知识库,用于描述现实世界中的实体及其相互关系 。与传统的关系数据库不同,知识图谱以图的节点-边形式存储知识,更加直观地表示实体关联。通过对海量数据的加工、处理和整合,知识图谱将杂乱无章的非结构化信息转化为清晰简单的“三元组”集合,为后续的智能查询和推理打下基础 。
值得注意的是,知识图谱并非凭空产生,其背后涉及多学科技术的交叉融合。从自然语言处理(NLP)技术提取知识,到数据库技术存储知识,再到知识表示与推理方法对知识进行加工利用,每一步都至关重要。在接下来的章节中,我们将深入探讨知识图谱构建的核心技术原理,以及如何在电商领域从零开始实践一个完整的知识图谱项目。
2. 核心技术概览 (Core Technologies)
构建知识图谱是一个系统工程,通常包括信息抽取、知识表示和知识管理三个主要环节。在本节中,我们将介绍知识图谱涉及的核心技术模块,包括:命名实体识别(NER)、关系抽取、属性抽取、本体构建、知识融合以及图数据库的存储与查询。同时,我们会给出知识图谱构建流程的总体架构,并穿插示意图、流程图或伪代码来帮助理解每个模块的实现原理。下面我们按顺序详细说明各个技术点。
2.1 命名实体识别 (Entity Recognition)
命名实体识别(NER)是知识图谱信息抽取的起点,其任务是从非结构化文本中识别出具有特定意义的实体。在电商场景中,实体可以是商品名称、品牌、类别、型号、产地等。例如,对于一句商品描述“苹果公司推出了最新的iPhone 13手机”,NER模型应识别出“苹果公司”是品牌实体,“iPhone 13”是产品实体。
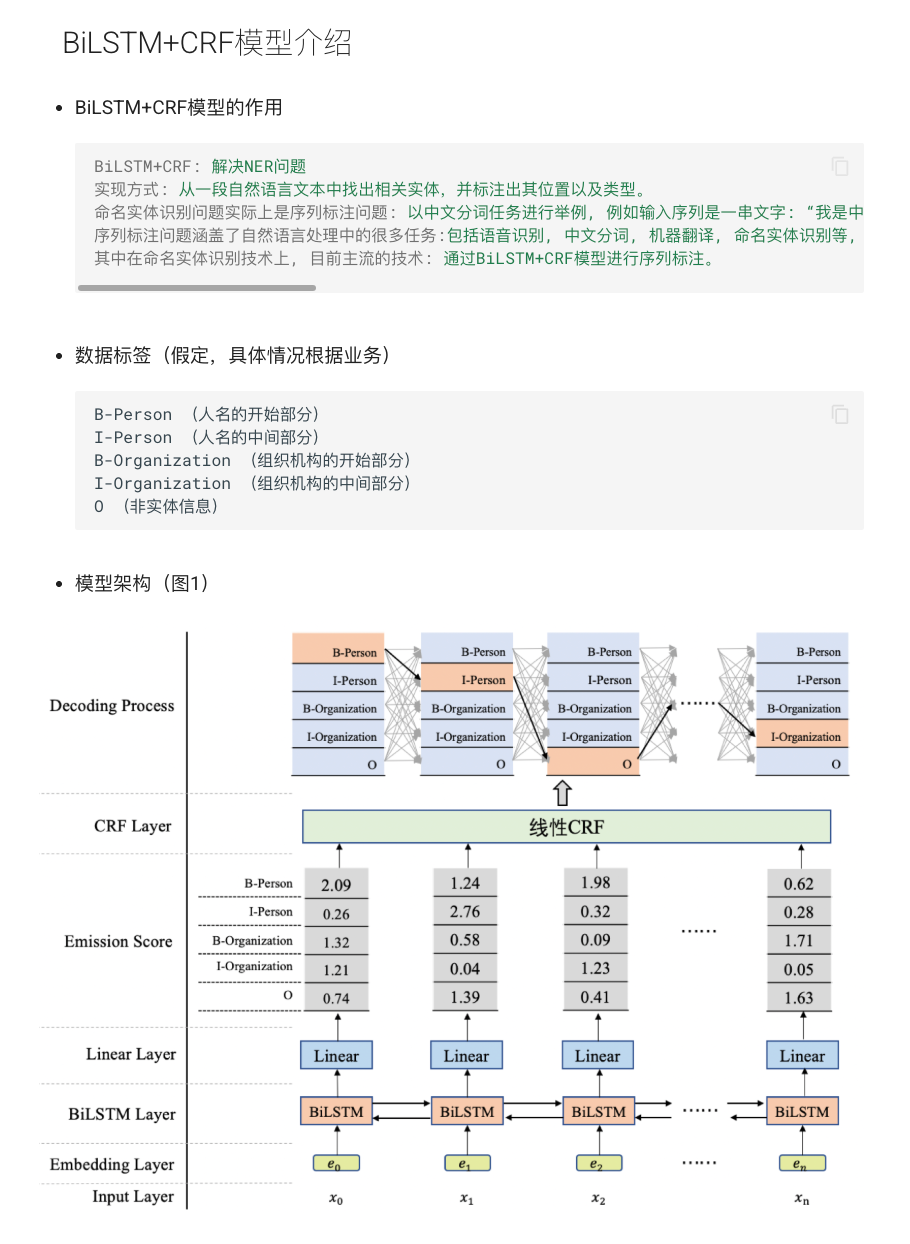
NER的方法分为规则驱动和模型驱动两大类:早期常用基于规则和词典的方式,通过预定义正则、模式或词典来匹配实体名称,但这种方法开发成本高、难以应对海量多样的数据。如今更普遍的是基于机器学习和深度学习的方法,包括条件随机场(CRF)、隐马尔可夫模型(HMM)等传统序列标注模型,以及近年的神经网络模型。特别是结合双向LSTM+CRF架构的神经网络成为实体识别的经典方案:BiLSTM能够捕捉上下文特征,CRF层负责输出合法的全局最优标签序列,有效提升了实体识别的准确率。
模型原理:典型的BiLSTM+CRF模型结构如下:首先,将句子序列转换为向量表示(如词向量或字向量)。然后,嵌入层输出经过双向LSTM层,提取每个词的上下文语义特征。接着,这些特征送入CRF层。CRF层会根据序列标签的转移得分和当前词的发射得分,计算整个序列的评分,并通过动态规划算法(如维特比算法)找到最优的标注序列。通过端到端训练,模型学习如何为每个词分配正确的实体类别标签并确保序列的合法性。
例如,对于输入序列“最新的iPhone 13手机”,理想输出的标签序列可能是:最新的/B-产品 iPhone/I-产品 13/I-产品 手机/O(这里B-产品表示产品名的开始,I-产品表示产品名的内部,O表示非实体))。
训练与评估:在模型训练过程中,我们通常需要有人工标注的语料(如利用 Doccano 等标注平台完成的NER标注数据)。
训练目标是最大化真实标签序列的概率或最小化序列标注错误。
以BiLSTM+CRF为例,其损失函数可以采用对数似然损失,即模型为正确标签序列计算的得分与所有可能序列得分总和的对数比值的负值。模型训练一般使用随机梯度下降(SGD)或 Adam 优化器迭代更新参数。每轮(epoch)都会在验证集上评估模型性能,以指标精确率(precision)、召回率(recall)和F1值为主 。其中,Precision = 提取出的正确实体数 / 提取出的实体总数,Recall = 提取出的正确实体数 / 文本中实际实体总数,F1 是 precision 和 recall 的调和平均值。一个良好的NER模型应该在这三项上都取得高分。
图1:BiLSTM+CRF模型结构示意图
 ∫
∫
实现伪代码:下面给出一个简化的NER训练流程伪代码,以加深对实现细节的理解:
# 数据样式:
示例数据格式说明
1. BIO 标注方案:
• B-XXX 表示实体“XXX”的 开始 处
• I-XXX 表示实体“XXX”在实体内部的 继续 处
• O 表示不属于任何实体的普通词 
2. 词级标注:每行一个“词 空格 标注”,句末空行分隔不同句子 
3. 实体类型:
• Product(产品)
• Brand(品牌)
• Category(类别)
• Price(价格)
• Accessory(兼容配件)
• Stock(库存) 
10 条电商场景 NER 训练示例:
Apple B-Brand
iPhone I-Brand
13 B-Product
64GB I-Product
黑色 I-Product
现货 O
价 O
格 B-Price
6999 I-Price
元 I-Price
Samsung B-Brand
Galaxy I-Brand
S21 B-Product
Ultra I-Product
128GB I-Product
现货 O
Kindle B-Product
Paperwhite I-Product
电子书 I-Category
阅读器 I-Category
¥ B-Price
799 I-Price
元 I-Price
Dell B-Brand
XPS I-Brand
13 B-Product
笔记本 I-Category
处理器 O
Intel B-Accessory
Core I-Accessory
i7 I-Accessory
Nike B-Brand
Air B-Product
Zoom I-Product
Pegasus I-Product
跑鞋 I-Category
库存 B-Stock
50 I-Stock
双 I-Stock
Sony B-Brand
WH-1000XM4 B-Product
无线 I-Category
降噪 I-Category
耳机 I-Category
价格 B-Price
¥ I-Price
2599 I-Price
小米 B-Brand
Redmi I-Brand
Note B-Product
11 I-Product
5G I-Feature
智能 I-Category
手机 I-Category
佳能 B-Brand
EOS I-Brand
R5 B-Product
微单 I-Category
相机 I-Category
现货 O
罗技 B-Brand
MX I-Brand
Master I-Brand
3 B-Product
鼠标 I-Category
兼容 B-Accessory
Windows I-Accessory
Mac I-Accessory
华为 B-Brand
Mate I-Brand
Pad B-Product
Pro I-Product
平板 I-Category
库存 B-Stock
20 I-Stock
台 I-Stock
####这些示例数据可直接保存为 .tsv 或 .txt 文件,
###加载后通过 PyTorch 的 DataLoader 读取,
###配合如下 BiLSTM-CRF 模型即可进行训练:
# ner 模型定义(BiLSTM+CRF)
class NERLSTM_CRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, dropout, word2id, tag2id):
super(NERLSTM_CRF, self).__init__()
self.name = "BiLSTM_CRF"
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = len(word2id) + 1
self.tag_to_ix = tag2id
self.tag_size = len(tag2id)
self.word_embeds = nn.Embedding(self.vocab_size, self.embedding_dim)
self.dropout = nn.Dropout(dropout)
#CRF
self.lstm = nn.LSTM(self.embedding_dim, self.hidden_dim // 2,
bidirectional=True, batch_first=True)
self.hidden2tag = nn.Linear(self.hidden_dim, self.tag_size)
self.crf = CRF(self.tag_size)
def forward(self, x, mask):
#lstm模型得到的结果
outputs = self.get_lstm2linear(x)
outputs = outputs * mask.unsqueeze(-1)
outputs = self.crf.viterbi_decode(outputs, mask)
return outputs
def log_likelihood(self, x, tags, mask):
# lstm模型得到的结果
outputs = self.get_lstm2linear(x)
outputs = outputs * mask.unsqueeze(-1)
# 计算损失
return - self.crf(outputs, tags, mask)
def get_lstm2linear(self, x):
embedding = self.word_embeds(x)
outputs, hidden = self.lstm(embedding)
outputs = self.dropout(outputs)
outputs = self.hidden2tag(outputs)
return outputs
# NER模型训练伪代码(BiLSTM+CRF)
model = BiLSTM_CRF(vocab_size, tagset_size)
optimizer = Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for sentence, tags in train_dataset: # 遍历训练集中每个句子及其标签
optimizer.zero_grad()
loss = model.neg_log_likelihood(sentence, tags) # 计算负对数似然损失
loss.backward() # 反向传播梯度
optimizer.step() # 参数更新
total_loss += loss.item()
# 在验证集评估性能
precision, recall, f1 = evaluate(model, dev_dataset)
print(f"Epoch {epoch}: Loss={total_loss:.3f}, F1={f1:.3f}")
# 模型预测
def extract_entities(tokens, labels):
entities = []
entity = []
entity_type = None
for token, label in zip(tokens, labels):
if label.startswith("B-"): # 实体的开始
if entity: # 如果已经有实体,先保存
entities.append((entity_type, ''.join(entity)))
entity = []
entity_type = label.split('-')[1]
entity.append(token)
elif label.startswith("I-") and entity: # 实体的中间或结尾
entity.append(token)
else:
if entity: # 保存上一个实体
entities.append((entity_type, ''.join(entity)))
entity = []
entity_type = None
# 如果最后一个实体没有保存,手动保存
if entity:
entities.append((entity_type, ''.join(entity)))
return {entity: entity_type for entity_type, entity in entities}
以上伪代码中,model.neg_log_likelihood计算CRF层的负对数似然损失(即最大化正确标签序列的概率) 。每轮迭代后,我们通过evaluate函数在验证集上计算模型的Precision、Recall和F1,以监控训练进展。如果F1不断提升,则说明模型在逐步学习到有效的实体识别能力。
通过NER,我们可以将电商领域的非结构化数据(如商品描述、评论文本等)转化为结构化的实体列表。例如,一段商品描述经过NER处理后,可能提取出实体:{产品名称: iPhone 13, 品牌: 苹果公司, 型号: 13, 属性: 手机} 等。这为下一步的关系抽取奠定了基础。
2.2 关系抽取 (Relation Extraction)
识别出实体之后,我们还需要确定实体之间存在什么语义关系。关系抽取旨在从文本中识别并提取实体之间的特定关系三元组,即(实体1, 关系, 实体2)。在电商领域,关系类型可能包括:“属于(类别)”关系(商品属于某类别)、“品牌”关系(商品由某品牌生产)、“适用于”关系(配件适用于某产品)等等。例如,对于文本“苹果公司推出了最新的iPhone 13手机”,我们希望抽取出关系三元组:(iPhone 13, 品牌, 苹果公司),表示iPhone 13这款产品的品牌是苹果公司。
关系抽取的方法大体可以分为管道式和联合式两种:
-
管道式方法:先用NER模型识别出文本中的所有实体,然后再两两组合实体,用关系分类模型判断它们之间是否存在特定关系以及关系类型。这种方法将实体识别和关系分类解耦,便于分别优化。但不足之处是错误可能会在两步之间传递(例如实体识别错误会影响关系抽取)。
-
联合抽取方法:通过单一模型同时抽取实体和关系。例如采用序列标注+指针机制,或表格填充法,甚至使用Transformer架构的联合模型(如Casrel等)直接输出三元组 。联合模型的优点是实体和关系预测可以相互促进,避免错误传播 。但联合模型结构通常更复杂,训练难度也较大 。
在本教程中,我们以相对直观的管道式方法为主进行讲解,即先识别实体,再分类关系。下面概述关系抽取的实现流程:
1)确定关系类别和数据标注:
首先需要根据业务场景定义关系类别。以电商为例,我们可能关心的关系有:“属于类别”、“品牌”、“产地”、“配件兼容”等等。
接下来,需要准备训练数据,通常是包含实体和关系标注的句子。
例如句子:“iPhone 13是苹果公司推出的手机”,
人工标注可能产出:(实体1=“iPhone 13”, 实体2=“苹果公司”, 关系=“品牌”) 和 (实体1=“iPhone 13”, 实体2=“手机”, 关系=“属于类别”) 这样的标注。
使用 Doccano 等工具可以方便地对文本进行实体及关系的联合标注。
2)特征表示与模型选择:
对于关系分类模型,可以采用监督分类方法。
输入通常是句子以及句中两个感兴趣的实体。
例如将句子转换为适合模型处理的形式:很多模型会将目标实体用特殊标记标注出来,然后输入模型判断关系类别。
例如:“[实体1]苹果公司[/实体1]推出了最新的[实体2]iPhone 13[/实体2]手机。”
模型需要输出实体1和实体2之间的关系(品牌)。
模型选择上,可以使用经典的深度学习模型,如卷积神经网络(CNN)或双向LSTM来提取句子的特征,再接一个全连接层进行关系分类。为了让模型知道哪个地方是实体,可以加入位置特征(Position Embeddings),即对句子中每个词,计算其与两个实体的位置距离作为附加特征输入模型。另外,也可以直接使用预训练的Transformer模型(如BERT),在句子中标记实体位置,让BERT的分类层预测关系。
3)模型训练:关系分类模型的训练目标通常是最大化正确关系标签的概率。由于这是一个多类分类问题,可以使用交叉熵损失。训练时,通过大量标注样本让模型学习不同实体对在不同句子上下文中的关系模式。
例如,当句子包含“…是…的手机”这种模式时,往往表示“属于类别”关系;包含“…推出…”时可能暗示“品牌”关系。
4)预测与输出:在预测阶段,对于识别出的实体对,模型会输出一个关系类别或者“无关系”。如果概率低于阈值,可以判断该实体对在句中没有明确关系。将有关系的实体对与关系类型组成三元组输出。
举个例子,假设我们有一句标注的训练样本:
“这款华为Mate40手机运行很流畅”。标注关系:(Mate40, 品牌, 华为),实体Mate40在句中位置2-7,实体华为位置3-5。
训练一个BiLSTM关系分类模型时,我们会构造输入特征:词向量序列 + 每个词相对Mate40和华为的位置索引序列。模型学到在“[品牌]Mate40手机”这种上下文中,“Mate40”和“华为”之间应为“品牌”关系。训练完成后,当模型看到新的句子,比如“苹果的MacBook笔记本性能强大”,识别出实体“苹果”(品牌)和“MacBook”(产品)后,就能正确输出关系“品牌”。
关系抽取代码实例:下面给出一个简单的关系分类模型实现片段(PyTorch)示例,以双向LSTM为编码器:
# 图3: 关系分类模型示例代码(简化版)
class RelationClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_relations):
super(RelationClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.bilstm = nn.LSTM(embed_dim, hidden_dim, bidirectional=True, batch_first=True)
self.fc = nn.Linear(hidden_dim*2, num_relations) # 双向LSTM输出拼接
def forward(self, sentence_ids):
embeds = self.embedding(sentence_ids) # [batch, seq_len, embed_dim]
lstm_out, _ = self.bilstm(embeds) # [batch, seq_len, hidden_dim*2]
# 取两个实体位置处的LSTM输出向量,简单拼接作为关系表示(假设已知实体索引)
ent1_repr = lstm_out[:, ent1_index, :] # [batch, hidden_dim*2]
ent2_repr = lstm_out[:, ent2_index, :]
pair_repr = torch.cat([ent1_repr, ent2_repr], dim=1) # 拼接两个实体向量
scores = self.fc(pair_repr) # [batch, num_relations] 得到每种关系的分数
return scores以上示例中,我们为了简化,假设已知实体1和实体2在句子中的索引位置,然后从BiLSTM的输出中抽取对应向量作为实体表示,拼接后送入全连接层预测关系类型。在实际实现中,我们可以更复杂些:例如将整句通过注意力机制聚合成一个固定长度向量,再结合实体位置等信息进行分类。这类模型的细节实现可以有很多变体,但核心思想都是编码句子+突出实体特征+分类。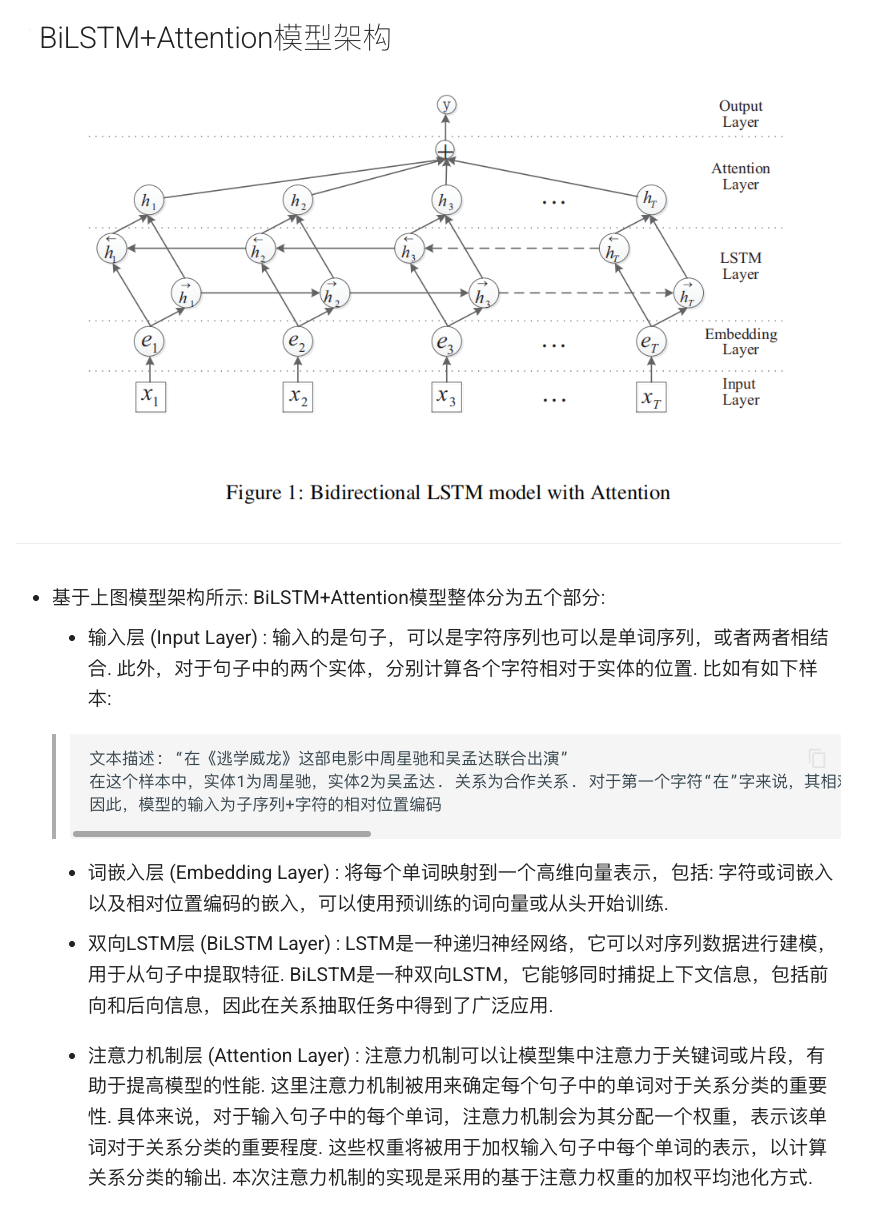
#bilstm + atten注意力机制
# coding:utf8
import torch
import torch.nn as nn
import torch.nn.functional as F
class BiLSTM_ATT(nn.Module):
def __init__(self, conf, vocab_size, pos_size, tag_size):
super(BiLSTM_ATT, self).__init__()
self.batch = conf.batch_size
self.device = conf.device
self.vocab_size = vocab_size
self.embedding_dim = conf.embedding_dim
self.hidden_dim = conf.hidden_dim
self.pos_size = pos_size
self.pos_dim = conf.pos_dim
self.tag_size = tag_size
self.word_embeds = nn.Embedding(self.vocab_size,
self.embedding_dim)
self.pos1_embeds = nn.Embedding(self.pos_size,
self.pos_dim)
self.pos2_embeds = nn.Embedding(self.pos_size,
self.pos_dim)
self.lstm = nn.LSTM(input_size=self.embedding_dim + self.pos_dim * 2,
hidden_size=self.hidden_dim // 2,
num_layers=1,
bidirectional=True)
self.linear = nn.Linear(self.hidden_dim,
self.tag_size)
self.dropout_emb = nn.Dropout(p=0.2)
self.dropout_lstm = nn.Dropout(p=0.2)
self.dropout_att = nn.Dropout(p=0.2)
self.att_weight = nn.Parameter(torch.randn(self.batch,
1,
self.hidden_dim).to(self.device))
def init_hidden_lstm(self):
return (torch.randn(2, self.batch, self.hidden_dim // 2).to(self.device),
torch.randn(2, self.batch, self.hidden_dim // 2).to(self.device))
def attention(self, H):
M = F.tanh(H)
a = F.softmax(torch.bmm(self.att_weight, M), dim=-1)
a = torch.transpose(a, 1, 2)
return torch.bmm(H, a)
def forward(self, sentence, pos1, pos2):
init_hidden = self.init_hidden_lstm()
embeds = torch.cat((self.word_embeds(sentence),
self.pos1_embeds(pos1),
self.pos2_embeds(pos2)), 2)
embeds = self.dropout_emb(embeds)
embeds = torch.transpose(embeds, 0, 1)
lstm_out, lstm_hidden = self.lstm(embeds, init_hidden)
lstm_out = lstm_out.permute(1, 2, 0)
lstm_out = self.dropout_lstm(lstm_out)
att_out = F.tanh(self.attention(lstm_out))
att_out = self.dropout_att(att_out).squeeze()
result = self.linear(att_out)
return result
经过NER和关系抽取两步,我们便将原始文本转化为结构化的知识三元组。
例如,从若干商品描述语句中,我们可能抽取出如下三元组集合:
-
(iPhone 13, 品牌, 苹果公司)
-
(iPhone 13, 属于类别, 智能手机)
-
(华为 Mate40, 品牌, 华为)
-
(华为 Mate40, 属于类别, 智能手机)
-
(AirPods Pro, 属于类别, 无线耳机)
-
……
这些三元组就是知识图谱的数据层基础,我们接下来需要将它们融合并存储到知识图谱中。
2.3 属性抽取 (Attribute Extraction)
属性抽取与关系抽取类似,也是在文本中提取关于实体的属性-值对。区别在于,“属性”通常被视作实体的内部特征,而“关系”更强调实体之间的外部联系。在知识图谱构建中,我们往往将属性抽取看作是一种特殊的关系抽取——即实体与属性值之间的关系 。
例如,对于商品实体“iPhone 13”,它可能有属性:“颜色=黑色”,“存储容量=128GB”,“发布时间=2021年”等。这些属性在文本中可能以描述性语句出现,比如“iPhone 13 有黑色和白色两种颜色”、“这款手机提供128GB存储”。
属性抽取可以遵循与关系抽取相同的方法:先识别出属性值作为一种实体,然后定义属性关系类型(比如颜色, 存储容量等),再做关系抽取。许多时候,属性值是名词短语或者数值,提取时可以使用模式或正则辅助(如识别数字、日期等特殊格式)。例如,可以利用正则表达式直接捕获像“128GB”这样的存储大小,然后将其归为某个属性值类型。在深度学习模型中,也可以增加属性类别的识别,将属性看作特殊的实体类别来做NER。
需要注意的是,属性值往往不像实体那样在知识库中有唯一标识,它可能是一个自由文本。例如“颜色=黑色”中的“黑色”无需在知识库中作为一个实体节点,而是作为iPhone 13节点的一个属性字段存储。所以在构建知识图谱时,对于实体的属性通常直接存在实体节点的属性(Property)上,而实体之间的关系才以图中边的形式表示。当然,这取决于具体实现,如果使用RDF三元组模型,也可以把属性表示为与某个“属性值实体”的关系。
总之,属性抽取扩充了实体的描述,使知识图谱更加丰富完整。我们在电商知识图谱中会抽取常见的商品属性,并在后续存储时将它们以适当方式附加到商品实体节点上。
2.4 本体构建 (Ontology Construction)
本体(Ontology)是知识图谱的模式层,定义了图谱中概念和关系的类型层次结构,相当于知识图谱的“纲领”和“schema”。简单来说,本体回答了:“有哪些类型的实体?有哪些类型的关系?它们之间允许怎样的链接?” 例如,在电商领域,我们可以设计一个本体:有商品、品牌、类别等概念;商品实体可以有属性价格、颜色等,可以参与属于类别关系连接到类别实体,参与品牌关系连接到品牌实体,等等。这种对概念和关系的形式化定义,有助于保证知识图谱数据层的规范性和一致性。
本体构建可以通过自顶向下或自底向上两种方式或结合:
-
自顶向下:由领域专家根据业务理解预先定义好概念和关系体系。例如电商领域可以参考电商网站的商品分类体系来构建类别本体,参考产品规格来定义属性本体。这种方法确保本体结构符合常识和业务需要,但是构建成本较高,需要专家知识。
-
自底向上:从数据中自动抽取或归纳概念层次。例如通过聚类或模式发现算法,从大量商品名中提取共现关键词自动形成类别体系,或者利用统计方法发现实体上下位关系。也有研究利用预训练大模型自动归纳本体概念等。然而纯自动的方法准确性有限,通常需要人工校验和调整。
在实践中,两种方法常结合使用:先构建初步本体,再根据实际数据不断修正、扩展。
以电商知识图谱为例,我们可能先定出类目的层次结构(如“电子产品 > 手机 > 智能手机”),以及基本的实体类型(商品、品牌、用户等)和关系类型。然后在往图谱加载具体数据时,如果发现新的概念(比如出现了一种全新产品类别),再将其补充进本体。
构建本体的工具也很重要。很多场景下会使用本体编辑器如 Protégé(斯坦福大学提供的免费开源工具)来手工编辑OWL本体模型。如果不熟悉OWL语言,也可以用图形化界面工具如 OntoStudio 等商业软件,它提供拖拽式界面帮助定义本体概念、关系及约束。OntoStudio支持丰富的本体建模功能,适用于构建复杂企业本体(例如包含类继承关系、公理规则等)。由于OntoStudio是商业软件,这里我们更多介绍开源方案如Protégé。但在附录中我们会简单提及OntoStudio等工具的特点。
本体在知识图谱中的作用包括:约束数据层输入(比如限定某关系的主体和客体必须是特定类型的实体)、指导推理(根据本体定义的规则可以推导新知识)、提高查询精度(通过模式识别复杂查询的语义)。
对于我们构建的电商知识图谱,本体将确保所有商品节点都归属在定义好的类目树下,所有品牌节点都连接正确的商品节点,不会出现数据混乱。例如,如果本体规定“品牌”关系只能从商品指向品牌,那么在构建知识图谱时就会避免将两个商品直接用“品牌”关系相连,从而保证了数据一致性。
总之,本体构建赋予知识图谱模式层的力量,使图谱更好地组织知识。在实际项目中,本体工作通常与数据抽取并行进行:抽取一部分数据,完善一次本体,如此迭代,让图谱既能快速覆盖知识又能保持结构清晰。
2.5 知识融合 (Knowledge Fusion)
当数据来自多个源时,知识图谱面临一个重要挑战:知识融合。知识融合简单来说就是将来自不同来源、不同格式的异构数据统一整合到一个一致的知识图谱中,同时解决由此带来的一系列问题 。常见的知识融合任务和难点包括:
-
消除冗余:不同数据源可能会包含重复的实体或关系描述。如果不加处理地合并,会导致图谱中出现冗余节点或边。
-
例如,来自电商网站A和网站B的商品列表中可能都有“iPhone 13”这个实体,我们需要识别出它们指的是同一个东西并合并,而不是在知识图谱中出现两个独立的iPhone 13节点 。
-
统一表示:不同来源对同一概念或实体的命名可能不同,需要进行同名实体对齐。
-
例如,一个数据源用“苹果公司”,另一个用“Apple Inc.”,我们需要将它们识别为同一实体。又或者属性名称风格不同,一个用“价钱”,一个用“价格”,需要统一成同一种属性标识 。
-
冲突消解:不同来源对同一实体或关系的描述可能存在冲突。
-
例如,一个来源说某商品价格是100元,另一个来源说是120元,或是对于同一用户评价,一个说好一个说差。这时需要有策略决定图谱中采用哪个值,或者如何表示不确定性 。通常通过信誉评分、来源可信度、更新时间等因素来评估可信度,选择保留可信度更高的数据 。
-
增量融合:随着新数据源的加入,如何扩充知识也是知识融合的一部分 。我们希望从不同来源挖掘新的实体和关系,丰富图谱内容。同时在融合过程中避免引入不一致或重复信息 。
知识融合需要依赖多种技术手段:
-
实体对齐(Entity Matching):通过字符串匹配、规则(如同义词词典)、机器学习(如基于上下文embedding计算相似度)等方法,将不同来源中指代同一对象的实体识别出来并合并。对于电商商品,可以利用商品的SKU、型号或其它标识符,或者基于名称的编辑距离、embedding相似度等算法进行匹配。
-
实体消歧(Entity Disambiguation):与对齐类似,但更针对消除歧义。即同一个名称在不同上下文可能指不同实体的情况(如“Apple”是水果还是公司)。消歧通常结合上下文语义或已知知识进行推理。例如,如果某条数据出现“Apple”且上下文涉及“手机”、“电子产品”,那么可判断此处Apple指公司而非水果。
-
关系对齐:不同来源的关系定义可能不同,但语义相近,也需要合并。如一个数据源有关系类型“包含”用于表示类别包含商品,另一个用“属于”表示商品属于类别,这两者应该在融合时识别为同一种关系类型。
-
数据清洗与冲突解决:通过预定义规则或算法检测矛盾的数据。例如对于属性值冲突,一个来源说某商品价格是100元,另一个来源说是120元,可以采用“后写优先”(最近更新的数据为准)或“投票法”(从多个来源中多数同意的为准)等策略。复杂情况下,可以将冲突暴露给人工去处理。
知识融合是构建跨源知识图谱不可避免的一步。在我们的电商知识图谱案例中,假设我们从多个电商平台抓取了产品数据,就需要融合:同一产品不同平台的描述要合并,规格属性冲突要解决,多平台的分类体系要统一。这项工作可以说是既有技术挑战也有工程挑战:技术上要设计算法自动化匹配、合并,工程上要保证流程可以扩展地处理大规模数据并方便地更新维护。
通过良好的知识融合,我们最终得到的图谱将是一个“去伪存真、统一规范”的知识库,为后续应用提供可靠的数据支持 。融合完成的知识图谱就好比将不同拼图块无缝拼合成一幅完整图景,其中每个实体都是唯一的,每条关系都是准确的。
2.6 图数据库存储与查询 (Graph Database Storage & Query)
有了实体和关系数据,我们需要选择合适的存储和查询技术来承载我们的知识图谱。不同于传统关系型数据库,知识图谱更适合存储在图数据库中,因为图数据库天生以节点和边的结构存储数据,能够高效地处理关联关系的遍历和查询。
Neo4j 是当前业界应用最广泛的图数据库之一。它以高性能的嵌入式图存储引擎为核心,支持事务和ACID特性,非常适合存储知识图谱这类高度连接的数据 。Neo4j使用属性图模型:节点和关系都可以有属性(键-值对),方便我们把实体的各种属性信息也一同存储在节点上。如我们可以在商品节点上存储属性价格=1000,在用户节点上存储年龄=30等等。此外,Neo4j 提供了强大的图查询语言 Cypher,使得我们可以用类似SQL的语句灵活查询图谱。

将数据写入Neo4j:可以通过多种方式将知识三元组导入Neo4j。
Neo4j有批量导入工具,也支持通过其提供的Python驱动(如 py2neo 库)在代码中执行 Cypher 语句写入数据。在本项目中,我们将演示使用 py2neo 来批量插入节点和关系的方式。例如,我们可以为每种实体类型编写一个函数,将该类型所有实体批量插入图数据库;为每种关系类型编写一个函数,将成对的实体关系插入数据库。伪代码如下:
# 图4: 使用 py2neo 批量插入实体和关系示例
from py2neo import Graph
graph = Graph("bolt://localhost:7687", auth=("neo4j", "your_password"))
def create_nodes(entity_list, label):
for name in set(entity_list):
cypher = f"MERGE (n:{label} {{name: '{name}'}})"
graph.run(cypher) # 将实体名称插入为节点(MERGE避免重复)
print(f"Inserted {len(set(entity_list))} nodes of type {label}.")
def create_relationships(triples, head_label, tail_label):
for head, rel, tail in triples:
cypher = (f"MATCH (h:{head_label} {{name: '{head}'}}), (t:{tail_label} {{name: '{tail}'}}) "
f"MERGE (h)-[r:{rel}]->(t)")
graph.run(cypher)
print(f"Inserted {len(triples)} relations of type {rel}.")上面的create_nodes函数通过循环,对给定实体列表中的每个唯一名称执行一次Cypher MERGE语句,将其创建为指定标签的节点 。
MERGE语句的作用相当于“如果图中不存在则创建,否则跳过”,这可以防止重复插入节点 。create_relationships函数则对每个三元组执行一个MATCH+MERGE语句:首先用MATCH找到已存在的头实体节点和尾实体节点,再用MERGE创建两者之间指定类型的关系 。由于我们之前插入节点用了MERGE,这里可以确保所有实体节点已存在,否则MATCH找不到时MERGE不会创建关系。
通过这种方式,我们可以批量把抽取到的电商知识导入Neo4j。例如:
-
调用 create_nodes(product_list, "Product") 插入所有商品节点。
-
调用 create_nodes(brand_list, "Brand") 插入所有品牌节点。
-
调用 create_nodes(category_list, "Category") 插入所有类别节点。
-
然后调用 create_relationships(product_brand_pairs, "Product", "Brand") 插入所有商品-品牌关系 。
-
调用 create_relationships(product_category_pairs, "Product", "Category") 插入商品-类别关系,等等。
Cypher查询: 数据导入后,我们就可以使用Cypher对知识图谱进行查询和分析了。Cypher 查询语言以 ASCII-Art 风格描述图形模式。例如,我们想查找所有属于“智能手机”类别的商品,可以使用:
MATCH (p:Product)-[:属于类别]->(c:Category {name: '智能手机'})
RETURN p.name;这条查询会匹配图中所有与名称为“智能手机”的Category节点有“属于类别”关系的Product节点,并返回这些商品的名称。再比如,我们想知道某品牌下有哪些产品:
MATCH (b:Brand {name: '苹果公司'})<-[:品牌]-(p:Product)
RETURN p.name;这会找到所有与品牌“苹果公司”节点通过“品牌”关系相连的商品并列出。Cypher支持复杂的图形模式查询,包括可变长度路径、条件过滤、聚合统计等,非常适合在知识图谱上执行例如推荐(找出和某商品相似的其他商品)、统计(不同类别下产品数量)、路径(实体之间最短路径)等操作。
Neo4j的可视化: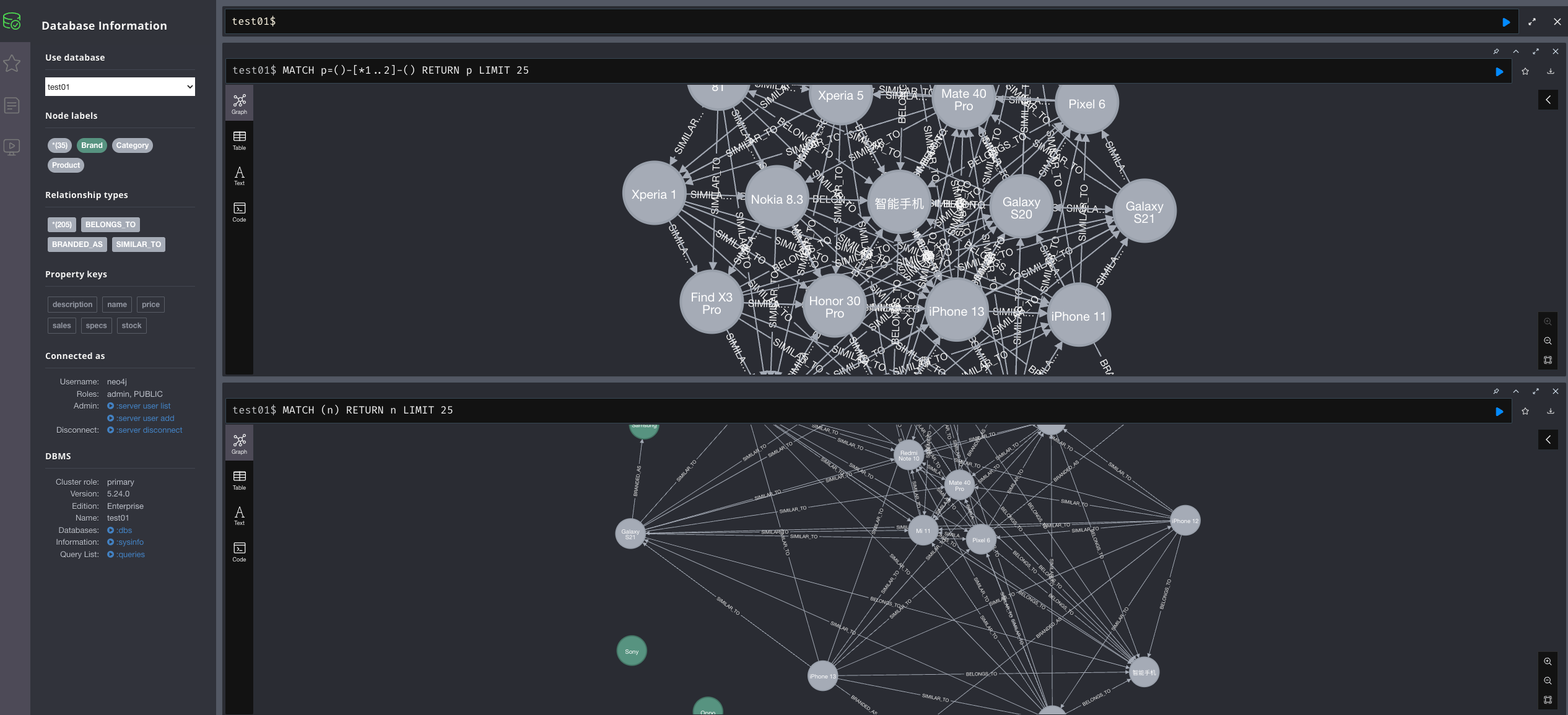
Neo4j自带了一个浏览器界面,当我们在浏览器中访问http://localhost:7474时,可以使用Neo4j Browser执行Cypher并查看结果 。
Neo4j Browser会将查询结果以节点-关系图形式可视化,非常直观。
例如,我们执行MATCH p=()-[*1..2]-() RETURN p LIMIT 25可以获取图谱中任意两个跳以内的一些子图,然后在浏览器中看到节点和连线的图形。
如果我们的电商知识图谱构建成功,我们能够看到商品节点连接到品牌节点和类别节点,组成一个简单的知识网络。如果想要更美观或复杂的可视化,也可以使用Neo4j的Bloom工具或者将数据导出给Gephi等图分析软件。不过对于开发者来说,Neo4j Browser已经足够用来浏览和验证知识图谱内容。
通过图数据库的存储与查询,我们实现了对知识图谱数据的持久化管理,并具备了实时查询的能力。这为知识图谱的上线应用打下基础:我们可以开发接口调用Neo4j查询,实现推荐、问答等功能,也可以定期更新Neo4j中的数据以保持知识最新。
下一章节,我们将结合一个实际的电商场景项目,把以上介绍的技术流程串联起来,从数据标注开始,一步步构建并部署一个可用的电商知识图谱原型。
3. 电商知识图谱项目实战 (Real-World Case Study in E-commerce)
本节我们将基于电商行业的场景,构建一个完整的知识图谱项目。从数据获取与标注,一直到模型训练、图谱存储、接口部署,每个环节都会hands-on演示,力求使读者能够通过本文的指导完成属于自己的电商知识图谱。我们将使用开源数据集和开源工具,例如Doccano、PyTorch、Neo4j、Flask等,确保项目具有可复现性和实用性。
假设的业务背景:
我们想要构建一个“手机产品知识图谱”,整合关于手机产品及其品牌、类别、规格的信息,并提供一个简易的接口供查询。数据来源可以是公开的电商产品数据,例如亚马逊公开的产品信息数据集 。为了示范,我们选择其中智能手机相关的一小部分数据进行构建(在实际应用中,可拓展到更大范围的商品)。整个项目流程如下:
步骤概览:
3.1 数据收集与标注
3.2 实体抽取模型开发 (NER)
3.3 关系抽取模型开发 (Relation Extraction)
3.4 知识图谱构建与可视化 (Neo4j导入)
3.5 接口开发与部署 (Flask + Gunicorn + Nginx)
接下来,我们按这些步骤依次展开。
3.1 数据收集与标注
数据收集:我们需要一份电商领域的数据集作为构建知识图谱的基础。这里我们使用公开的亚马逊商品数据集的一个子集 。亚马逊的开放数据中包含产品的基本信息(名称、描述、类别、品牌、价格等) 。例如,一条产品数据(JSON格式)如下 :
{
"asin": "B08XYZ1234",
"title": "Apple iPhone 13 (128GB, 黑色)",
"brand": "Apple",
"category": ["Electronics", "Smartphones"],
"description": "Apple iPhone 13手机,配备A15仿生芯片,超视网膜XDR显示屏..."
}我们将收集若干部手机产品的信息,保存为原始数据文件(例如products.json)。有了这些原始数据后,下一步需要对其中的文本内容进行实体和关系标注。

数据标注:为了训练我们的NLP模型,我们需要对产品描述或相关文本进行人工标注。这里,我们使用开源的文本标注工具 Doccano 来完成标注任务 。Doccano支持命名实体识别和关系的可视化标注,非常适合我们的用途 。以下是使用Doccano进行标注的流程:
-
安装Doccano:在虚拟环境下运行 pip install doccano 来安装 。安装完成后,初始化Doccano数据库并创建超级用户:
doccano init
doccano createuser --username admin --password 123456
-
然后启动Doccano服务:
doccano webserver --port 8000
-
在另一个终端启动任务队列:
doccano task
-
默认情况下,Doccano Web界面将运行在本地 http://127.0.0.1:8000 。用刚才创建的管理员账号登录,即可进入Doccano的项目管理界面 。
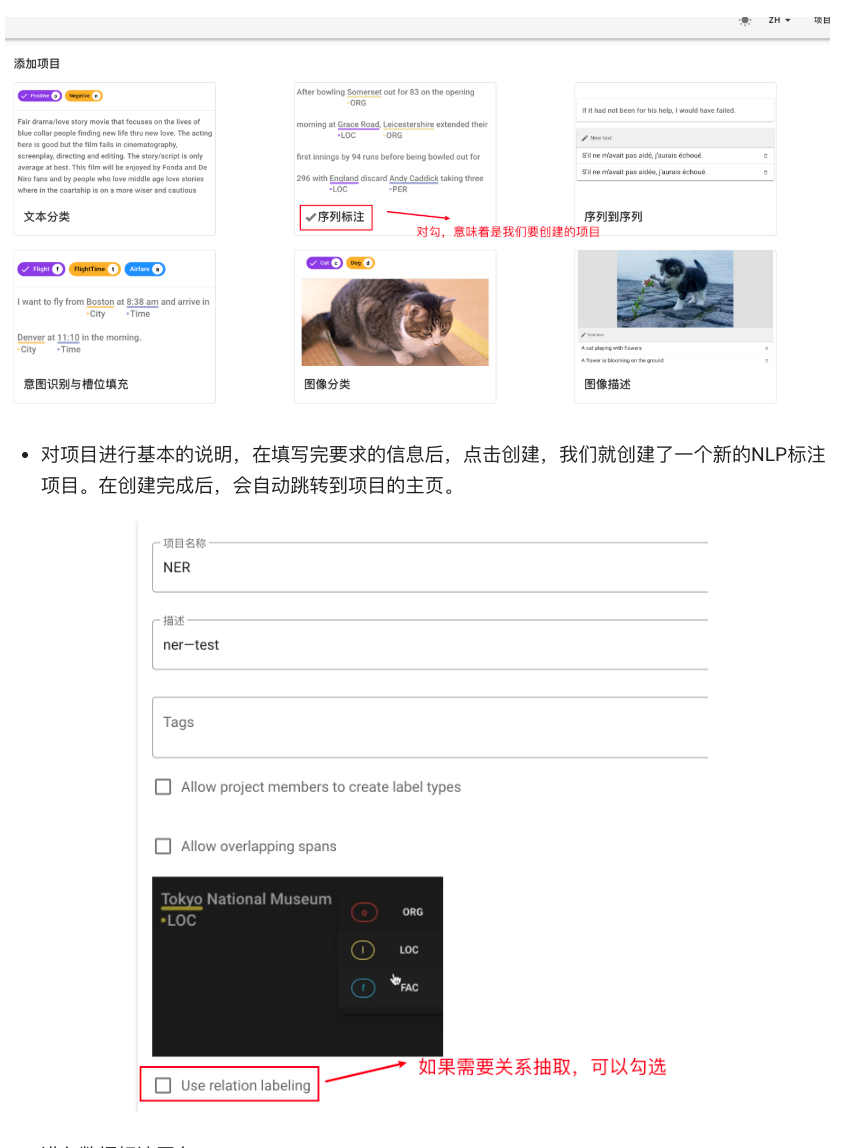
-
创建标注项目:登录后,点击“创建”按钮新建一个标注项目。例如我们创建项目名为“手机知识图谱”并选择任务类型为“Sequence Labeling”(序列标注)和“Relation Annotation”(关系标注)。上传我们准备的产品描述文本数据(每条一行或JSON格式均可,Doccano支持多种导入格式) 。上传后,Doccano会显示每条文本,供我们进行标注。
-
定义标签类别:在项目的设置中,我们需要先添加实体标签类型和关系标签类型。对于我们的手机产品场景,定义以下实体类型:
-
产品:如iPhone 13、Mate40等手机型号名称。
-
品牌:如苹果公司、华为、小米等手机厂商品牌。
-
类别:如智能手机、平板电脑等(本例主要是手机,所以类别统一为智能手机,可以标或不标)。
-
(根据需要还可添加,如处理器、操作系统等,但本例以简单为主)
定义关系类型:
-
品牌: 连接 产品 -> 品牌,表示某产品由某品牌推出。
-
属于类别: 连接 产品 -> 类别,表示产品属于某类别。
-
(其他关系可按需添加,如兼容、比较等,本例先聚焦品牌和类别关系)
-
-
开始标注实体和关系:Doccano界面很直观。选中一句文本(比如“苹果公司推出了最新的iPhone 13手机”),用鼠标拖动选择“苹果公司”,标记为品牌;选择“iPhone 13”,标记为产品 。接下来,在这两个标注实体上点击拖拽,可以画出实体间的连线,并选择关系类型品牌,表示苹果公司 -> iPhone 13 存在品牌关系。类似地,如果出现类别词,如“智能手机”,标记为类别并连接iPhone 13 -> 智能手机关系为属于类别。Doccano支持在Web界面直观地显示不同颜色的实体标签和关系线条,标注过程十分高效。
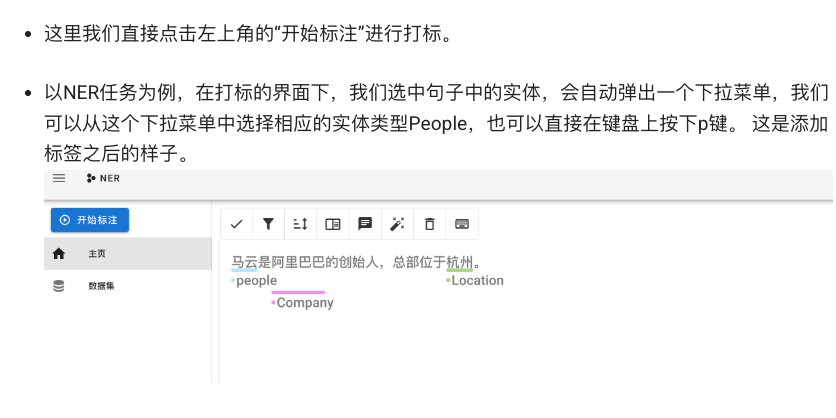
小提示: 标注时遇到重复的实体(如多个句子都提到“苹果公司”),Doccano会每句单独标。但在导出时可以汇总。还有,Doccano允许多人协作标注和内置简单的标注质量控制功能,非常适合构建训练集 。
-
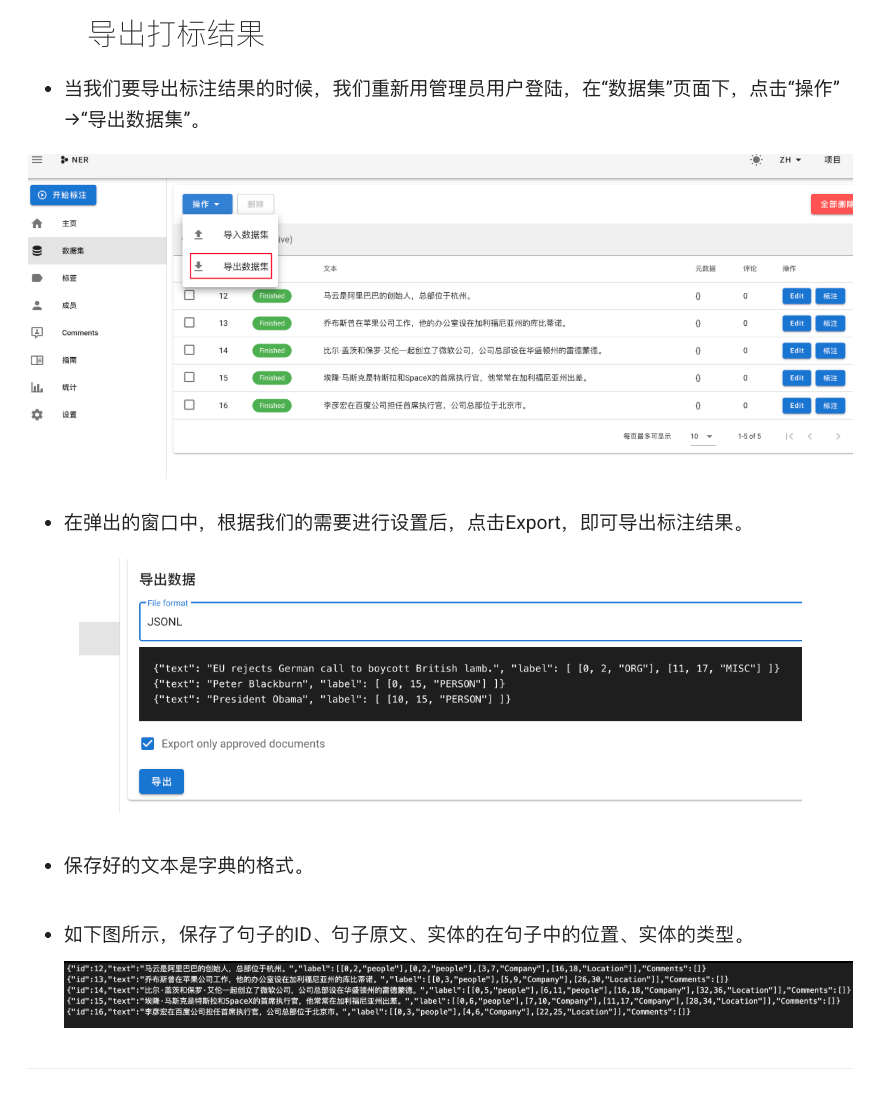
标注导出:完成一定数量文本的标注后,我们可以将标注结果导出。Doccano支持JSON、CSV等多种导出格式。关系标注通常导出为每条文本对应的实体及关系列表。我们假定导出为JSONL,每行包含文本及其entities和relations,例如:
{
"text": "苹果公司推出了最新的iPhone 13手机",
"entities": [
{"start_offset": 0, "end_offset": 4, "label": "品牌"}, # 苹果公司
{"start_offset": 10, "end_offset": 18, "label": "产品"} # iPhone 13
],
"relations": [
{"type": "品牌", "head": 1, "tail": 0} # 实体1(苹果公司)是tail,实体0(iPhone 13)是head,类型品牌
]
}
-
Doccano 的关系导出格式中,head和tail通常指向entities列表的索引,表示关系从哪个实体指向哪个实体。上例中{"type": "品牌", "head": 1, "tail": 0}可能表示实体索引1(iPhone 13)到实体索引0(苹果公司)有“品牌”关系。这种索引顺序有点反直觉,我们确认一下,如果想表达 iPhone 13 的品牌是苹果公司,那么应该是 iPhone 13 -> 苹果公司,但JSON里head=1指iPhone,tail=0指苹果公司。我们需要根据Doccano的导出规范来解释,一般关系的head可以表示主语实体索引,tail是客体实体索引。无论如何,我们导出后可以编写脚本解析成训练所需的格式。
通过以上步骤,我们获得了标注语料,包括实体标签和关系标签。这个语料将用于训练NER模型和关系抽取模型。
在本例中,我们标注了几十条产品描述语句,包含上百个实体和相应的关系,足以训练一个初步模型。对于真实项目,标注语料越多越好,一般需要成百上千条才能训练出稳健的模型,但出于教学演示目的,我们这里的数据集规模较小(可以运行,但准确率未必非常高)。
完成数据标注之后,我们进入模型开发阶段。
3.2 实体识别模型开发与训练
有了标注好的实体数据,我们首先训练命名实体识别(NER)模型来自动识别产品描述中的实体。我们将采用上一节介绍的 BiLSTM+CRF 模型。在实现中,会借助 PyTorch 深度学习框架,并使用我们的标注数据进行训练和评估。
数据准备:从Doccano导出的JSON,我们需要转换成NER模型训练所需的格式。常用的NER数据格式是BIO标注的文本,比如:
苹果/B-品牌 公司/I-品牌 推出/O 了/O 最新/O 的/O iPhone/B-产品 13/I-产品 手机/O每个词或字后面跟一个标签。为了简单,我们可以按字粒度进行标注(中文一般用字,英文部分我们当成一个词)。
我们编写一个数据预处理脚本,将Doccano的entities标注转为BIO序列。例如,读入每条JSON的文本和实体位置,将不在任何实体范围内的字标注为O,在实体范围内的标注为B-类型或I-类型(实体开头和内部)。输出这样的训练集和验证集文件。
注: 为了聚焦技术流程,这里省略具体的预处理代码及细节,如处理英文token和中文字的混合等。如果使用字粒度,在英文产品名会拆成字母,这不理想。实际可考虑分词后对每个词标注。这里简单起见可对英文和数字不拆开,当成一个符号列。如 “iPhone 13” 当成两个token:[“iPhone”, “13”] 分别标注 B-产品, I-产品。
模型实现:我们定义一个包含 BiLSTM+CRF 的模型类。在PyTorch中,可以使用现有的 CRF 实现库(如 torchcrf)或者手写 CRF 前向算法。这里展示简化的模型结构代码:
import torch
import torch.nn as nn
from TorchCRF import CRF # CRF 层实现,需要安装 torchcrf 库
class BiLSTM_CRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, dropout, word2id, tag2id):
super(NERLSTM_CRF, self).__init__()
self.name = "BiLSTM_CRF"
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = len(word2id) + 1
self.tag_to_ix = tag2id
self.tag_size = len(tag2id)
self.word_embeds = nn.Embedding(self.vocab_size, self.embedding_dim)
self.dropout = nn.Dropout(dropout)
# 与 BiLSTM 部分相同
self.lstm = nn.LSTM(self.embedding_dim, self.hidden_dim // 2,
bidirectional=True, batch_first=True)
self.hidden2tag = nn.Linear(self.hidden_dim, self.tag_size)
# CRF 对象:内部封装了转移矩阵、viterbi 解码和前向算法
self.crf = CRF(self.tag_size) # 返回值为 log likelihood,需取负作为损失
def get_lstm2linear(self, x):
# lstm模型得到的结果
# 通用的 LSTM -> Linear 流程
embedding = self.word_embeds(x)
outputs, hidden = self.lstm(embedding)
outputs = self.dropout(outputs)
outputs = self.hidden2tag(outputs)
return outputs # [batch, seq_len, tag_size]
def forward(self, x, mask):
# lstm模型得到的结果
# 预测阶段:获取 emissions 后,用 CRF 的 viterbi 解码得到最优路径
outputs = self.get_lstm2linear(x)
outputs = outputs * mask.unsqueeze(-1) # 屏蔽 padding 位
# 计算损失
# viterbi_decode 返回 List[List[int]],即每个序列的标签索引列表
return self.crf.viterbi_decode(outputs, mask)
def log_likelihood(self, x, tags, mask):
# 训练阶段:计算负对数似然损失,用于反向传播
outputs = self.get_lstm2linear(x)
outputs = outputs * mask.unsqueeze(-1)
# CRF.forward 返回 log likelihood,取负值作为损失
return -self.crf(outputs, tags, mask)
上述代码实现了CRF层的前向算法和维特比解码的核心逻辑。由于篇幅原因,对部分细节(如维特比的实现)省略。实际工程中,可以使用成熟的CRF库以简化实现。需要强调的是,理解CRF的数学原理有助于明白模型输出的是全局最优的序列而非逐字独立分类 。在我们的场景中,这可避免产生不合法的实体标签序列(比如“B-产品”后面不跟“I-产品”或“O”等问题)。
训练模型:接下来编写训练循环,将数据送入模型优化。假设我们已经将标注数据转换为数值形式:把字词映射为索引(word2id),标签映射为索引(tag2id)。同时处理不同序列长度的问题,通常用mask矩阵标识真实词的位置,补齐短序列。训练代码如下:
# -*- coding: utf-8 -*-
# train.py: BiLSTM 与 BiLSTM+CRF 模型训练与验证脚本
import time # 用于测量训练耗时
import torch
import torch.nn as nn
import torch.optim as optim
from model.BiLSTM import NERLSTM # 引入普通 BiLSTM 模型类
from model.BiLSTM_CRF import NERLSTM_CRF # 引入 BiLSTM+CRF 模型类
from utils.data_loader_Optimized import get_data,word2id # 自定义数据加载函数,返回训练与验证 DataLoader
from tqdm import tqdm # 进度条显示库
from sklearn.metrics import precision_score, recall_score, f1_score, classification_report # 评估指标
from config import Config # 配置管理类,包含超参数与路径信息
import os
import random
import numpy as np
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
if torch.cuda.is_available(): torch.cuda.manual_seed_all(42)
# 实例化配置
conf = Config()
def model2train():
"""
训练入口函数,根据 conf.model 决定使用 BiLSTM 还是 BiLSTM+CRF。
1. 读取数据
2. 构建模型、损失函数、优化器
3. 训练若干轮,并在验证集上评估,保存最佳模型
"""
# 1. 数据读取:返回训练和验证的 DataLoader,内部已处理批次大小、shuffle 等逻辑
train_dataloader, dev_dataloader = get_data(num_workers=8)
# 2. 动态选择模型:根据配置中的 model 字段,实例化相应模型
# word2id 与 conf.tag2id 全局定义于 utils.data_loader 或 config
models = 'BiLSTM_CRF'
model = models[conf.model_type](
embedding_dim=conf.embedding_dim, # 词嵌入维度
hidden_dim=conf.hidden_dim, # LSTM 隐藏单元总维度
dropout=conf.dropout, # Dropout 概率
word2id=word2id, # 词到索引映射
tag2id=conf.tag2id # 标签到索引映射
)
model = model.to(conf.device) # 将模型搬运到指定设备(GPU 或 CPU)
# 3. 损失函数与优化器
# 对于 BiLSTM,使用 CrossEntropyLoss ;对 CRF,损失在 log_likelihood 方法内部计算
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=conf.lr) # Adam 优化器
# 记录训练开始时间
start_time = time.time()
best_f1 = -1
for epoch in range(conf.epochs):
model.train()
for idx, (inputs, labels, mask) in enumerate(tqdm(train_dataloader, desc='BiLSTM+CRF训练')):
x = inputs.to(conf.device) # 输入迁移
mask_bool = mask.to(torch.bool).to(conf.device) # CRF 要求 mask 为 bool 类型
tags = labels.to(conf.device) # 真实标签
# 计算 CRF 负对数似然损失,log_likelihood 返回 batch 维度的 loss
loss_batch = model.log_likelihood(x, tags, mask_bool)
# 对所有句子的损失取平均,防止梯度过大
loss = loss_batch.mean()
# 反向传播流程
optimizer.zero_grad()
loss.backward()
# 梯度裁剪:避免梯度爆炸,max_norm 上限为 10
# torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)
torch.nn.utils.clip_grad_norm_(
parameters=model.parameters(), # Iterable of model parameters
max_norm=10, # 阈值:梯度范数不得超过它
norm_type=2 # 计算范数的类型,默认 L2 范数
)
optimizer.step()
if idx % 200 == 0:
print(f"Epoch {epoch+1}/{conf.epochs}, Step {idx}, CRF Loss: {loss.item():.4f}")
# 验证集评估,无需 criterion
precision, recall, f1, report = model2dev(dev_dataloader, model)
if f1 > best_f1:
best_f1 = f1
# 使用配置中的保存目录
save_path = os.path.join(conf.save_model_dict, 'bilstm_crf_best.pth')
torch.save(model.state_dict(), save_path)
print(f"New best F1: {f1:.4f}, model saved to {save_path}")
print(report)
total_time = time.time() - start_time
print(f"BiLSTM+CRF 训练完成,总耗时 {total_time:.1f}s")
def model2dev(dev_iter, model, criterion=None):
"""
在验证集上评估模型性能:
- 对于 BiLSTM:使用传入的 criterion 计算交叉熵损失
- 对于 BiLSTM+CRF:调用 model.log_likelihood 计算 CRF 损失
返回:
precision: macro-Precision
recall: macro-Recall
f1: macro-F1
report: sklearn.format classification_report 字符串
"""
aver_loss = 0.0 # 累计损失
preds, golds = [], [] # 存储所有 batch 的预测与真实标签
model.eval() # 切换到评估模式,禁用 dropout 等
# 遍历整个验证集
for inputs, labels, mask in tqdm(dev_iter, desc="验证集评估"):
# inputs: [batch, seq_len]
# labels: [batch, seq_len]
# mask: [batch, seq_len],1 表示有效 token,0 表示 padding
val_x = inputs.to(conf.device)
val_y = labels.to(conf.device)
mask = mask.to(conf.device)
if model.name == "BiLSTM":
# ------ BiLSTM 分支 ------
logits = model(val_x, mask) # 前向计算,得到 logits [batch, seq_len, tag_size]
# 取每个位置上最大分数的标签索引,列表形式 [[...], [...], ...]
pred_ids = torch.argmax(logits, dim=-1).tolist()
# 损失计算:展平后与标签对齐计算交叉熵
loss = criterion(logits.view(-1, logits.shape[-1]), val_y.view(-1))
aver_loss += loss.item()
else:
# ------ BiLSTM+CRF 分支 ------
# 将 mask 转为 bool,供 CRF 层区分 padding
mask_bool = mask.to(torch.bool)
# Viterbi 解码:返回标签索引列表形式的预测结果·
pred_ids = model(val_x, mask_bool)
# CRF 负对数似然损失:得到 [batch] 维度损失
loss_tensor = model.log_likelihood(val_x, val_y, mask_bool)
aver_loss += loss_tensor.mean().item()
# ----- 预测与真实标签收集 -----
# 计算每条序列真实长度(非 padding token 数量)
seq_lens = (mask > 0).sum(dim=1).tolist()
for i, length in enumerate(seq_lens):
# 仅保留有效 token 部分的预测与真实标签,丢弃 padding
preds.extend(pred_ids[i][:length])
golds.extend(val_y.tolist()[i][:length])
# 平均损失 = 总损失 / (batch 数 * batch_size)
aver_loss /= (len(dev_iter) * conf.batch_size)
# ----- 计算评估指标 -----
precision = precision_score(golds, preds, average='macro')
recall = recall_score(golds, preds, average='macro')
f1 = f1_score(golds, preds, average='macro')
# classification_report: 带有各类别指标与总体指标的格式化文本
report = classification_report(golds, preds, digits=4)
# 返回指标和报告
return precision, recall, f1, report
if __name__ == '__main__':
model2train()训练过程中可以看到损失函数应该逐渐下降,验证集F1上升。当迭代到一定次数后,模型收敛,我们保存模型参数以备使用:
torch.save(model.state_dict(), "ner_model.pth")模型评估:使用验证集计算Precision/Recall/F1,可以参考前面2.1节介绍。对于CRF模型的预测,我们使用 model.forward(X) 得到每个序列预测的标签序列,然后与真实标签比对计算指标。因为这里我们主要展示流程,就不详细给出evaluate函数实现了。可以假设最终我们的NER模型在验证集上达到例如Precision 0.85,Recall 0.80,F1 0.825的性能(具体取决于数据大小和难度)。
训练好的NER模型可以用于批量处理电商文本数据,将实体识别出来。在接下来的关系抽取模型中,我们也需要NER模型的输出辅助(当然在训练关系模型时,我们会使用人工标注的实体来训练,但在实际推理时,NER模型的输出会作为关系模型的输入)。
# -*- coding: utf-8 -*-
# ner_predict_ecommerce.py: 使用训练好的 BiLSTM+CRF 模型进行电商领域 NER 推断脚本,仅保留 BiLSTM_CRF 分支
import os
import torch
from model.BiLSTM_CRF import NERLSTM_CRF # 仅使用 BiLSTM+CRF 模型类(使用 torchcrf 实现)
from utils.data_loader_ecommerce import word2id # 电商领域词到索引映射表
from config import EcommerceConfig # 电商领域配置管理类,包含超参数与路径信息
# 实例化配置,包含 embedding_dim、hidden_dim、dropout、device、save_model_dict、tag2id 等
conf = EcommerceConfig()
# 模型文件根目录
model_dir = conf.save_model_dict
# 1. 模型加载
# 直接使用 BiLSTM+CRF 模型
model = NERLSTM_CRF(
embedding_dim=conf.embedding_dim,
hidden_dim=conf.hidden_dim,
dropout=conf.dropout,
word2id=word2id,
tag2id=conf.tag2id
)
# 模型文件名
model_file = 'bilstm_crf_best.pth'
model_path = os.path.join(model_dir, model_file)
# 加载权重
state_dict = torch.load(model_path, map_location=conf.device)
model.load_state_dict(state_dict)
# 迁移到设备并切换评估模式
model = model.to(conf.device)
model.eval()
# 2. 索引到标签的映射
# conf.tag2id: {'O':0, 'B-PRODUCT':1, 'I-PRODUCT':2, ...}
id2tag = {idx: tag for tag, idx in conf.tag2id.items()}
def extract_entities(chars, labels):
"""
将字符序列与对应的 BIO 标签转换为实体列表。
:param chars: List[str] - 原始字符列表
:param labels: List[str] - 与 chars 等长的 BIO 格式标签列表
:return: Dict[str, str] - 实体字符串到实体类型的映射
"""
ent_list = []
cur_chars = []
cur_type = None
for c, lab in zip(chars, labels):
if lab.startswith('B-'):
if cur_chars:
ent_list.append((cur_type, ''.join(cur_chars)))
cur_chars = []
cur_type = lab.split('-', 1)[1]
cur_chars.append(c)
elif lab.startswith('I-') and cur_chars:
cur_chars.append(c)
else:
if cur_chars:
ent_list.append((cur_type, ''.join(cur_chars)))
cur_chars = []
cur_type = None
if cur_chars:
ent_list.append((cur_type, ''.join(cur_chars)))
return {entity: etype for etype, entity in ent_list}
def model_predict(sample: str):
"""
对输入文本 sample 进行命名实体识别,返回提取的实体字典。
:param sample: 原始文本字符串
:return: Dict[str, str] - 实体到类型的映射
"""
# 文本转索引
x_ids = [word2id.get(ch, word2id.get('UNK', 0)) for ch in sample]
x_tensor = torch.tensor([x_ids], dtype=torch.long, device=conf.device)
# 构造 mask
mask = (x_tensor != 0).long().to(conf.device)
# 只使用 CRF 解码
with torch.no_grad():
# viterbi 解码,返回 List[List[int]]
pred_ids = model(x_tensor, mask.to(torch.bool))[0]
pred_ids = [int(i) for i in pred_ids]
pred_labels = [id2tag[i] for i in pred_ids]
chars = list(sample)
assert len(chars) == len(pred_labels), "字符数与标签数不一致!"
return extract_entities(chars, pred_labels)
if __name__ == '__main__':
# 测试示例:电商领域常见实体
text = '我想买一台华为 Mate 40 Pro 系列手机,预算在 5000 元以内。'
ents = model_predict(text)
print('识别结果:', ents)
#识别结果: {'华为 Mate 40 Pro 系列手机': 'PRODUCT', '5000 元': 'PRICE'}
3.3 关系抽取模型开发与训练
有了NER模型,我们继续开发关系抽取模型,用于识别实体之间的语义关系(三元组)。我们的关系模型将专注于之前定义的两类关系:品牌 和 属于类别。训练这个模型需要带关系标注的数据。幸运的是,我们在Doccano中已经同时标注了实体和关系,因此可以直接利用标注的结果来训练关系模型。
训练数据构建:从Doccano导出的关系标注数据中提取训练样本。常见的关系抽取训练数据格式是:每个样本包含句子以及句中两个目标实体及它们的关系标签。例如,可构造成如下形式的CSV:
sentence, entity1, entity1_type, entity2, entity2_type, relation
"苹果公司推出了最新的iPhone 13手机", "iPhone 13", 产品, "苹果公司", 品牌, 品牌
"苹果公司推出了最新的iPhone 13手机", "iPhone 13", 产品, "手机", 类别, 属于类别
...也就是说,同一句如果有多个关系,可以拆成多行,每行对应一对实体关系。
像上例一句话有两个关系(iPhone->苹果品牌,iPhone->手机类别),就拆成两条训练样本。
没有关系的实体对(负样本)是否要加入训练?通常需要,否则模型只看到有关系的正样本,会倾向于输出所有实体都有关系。处理方法是一句话中可能有很多实体对,但只有一部分有标注关系,我们可以采样一定比例没有标注关系的实体对作为无关系样本加入训练,以平衡类别。
在我们的数据里,例如“苹果公司推出了最新的iPhone 13手机”
标注的实体有苹果公司(iPhone品牌)和iPhone 13(产品)以及手机(类别)。可能苹果公司和手机之间没有直接关系标注,我们可以视其为负样本: (苹果公司, 手机)无直接关系。在组装训练集时,可以加一条:entity1=苹果公司, entity2=手机, relation=None(或特殊标签无)。
模型实现:我们采用一个相对简单的关系分类模型架构。上一节2.2已经展示了一个BiLSTM做关系分类的例子。这里我们可以在那个基础上稍作扩展:由于我们已有预训练的NER模型或者embedding,可以尝试使用预训练BERT来获取句子向量再分类,但考虑到复杂度和计算资源,这里仍用BiLSTM或CNN等轻量模型。
为了减少重复工作,我们也可以借鉴开源实现。例如,有人实现了一个 BiLSTM+Attention 的关系抽取模型。但本例中,为简便起见,我们就用BERT微调来做关系分类(这样效果会比较好且实现简单)。当然,为了不偏离主题,我们假设大家对BERT有基本了解。可以使用 Hugging Face 的 transformers 库:
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
model = BertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=3)
# 我们定义3个label: 0=无关系, 1=品牌, 2=属于类别通过拼接实体标记的句子让BERT来判别。例如构造输入:“[CLS] 苹果公司 推出 了 最新 的 [E1] iPhone 13 [/E1] 手机 [E2] 苹果公司 [/E2] [SEP]”。这里用特殊标记 [E1] 和 [E2] 标出两个实体在句子中的位置(有些研究做法) 。但BERT的词表未必有这些标记,可以简单用“[unused1]”等替代。标记实体在输入中的位置是为了让模型更容易注意到是哪两个实体在考虑关系。
输入准备可能比较繁琐,限于篇幅就不展开代码。总之,最终我们拿到了 (input_ids, attention_mask, token_type_ids) 以及对应的 label(0/1/2)。然后像常规文本分类一样 fine-tune BERT:定义 AdamW optimizer,设置较小学习率,比如2e-5,训练3-5个epoch。由于示例数据集很小,可以开启 GPU 加速以更快收敛。
在基于 BERT 的关系分类模型中,h_CLS 通常取自 [CLS] 标记的隐藏向量,用于表示整句的信息,而 h_entity1、h_entity2 则分别代表两个待判定实体在 BERT 隐藏层中的向量表示。常见做法有两种:
[CLS] 我 想 买 [unused1] 华为 [unused2] [unused3] Mate 40 Pro [unused4] [SEP]
标记(Marker)取值法(我们这里使用的方法)
-
原理:在实体前后插入专门的标记符号(如 [E1]/[/E1], [E2]/[/E2]),模型只需直接读取这些标记在最后一层中的隐藏状态即可。
-
优点:实现简洁,不必额外计算多个子词的平均,直接利用 BERT 的位置感知能力 。
-
实践:许多工作(如 Soares 等人的 “Matching the Blanks”)都采用这种方法,对标记的首位置加以拼接:
在输入中分别为每个实体插入特殊标记(例如 [unused1]、[unused2] 对应第一个实体的起止;[unused3]、[unused4] 对应第二个实体的起止),然后直接取出这些标记位置的隐藏向量作为实体向量。
-
例如在句子中,h_entity1 就是 [unused1](或 [unused2])对应的输出向量,h_entity2 则是 [unused3](或 [unused4])对应的向量。这种“实体标记”策略不仅简单,而且能让 BERT 明确关注到实体边界
h_pair = torch.cat([h_CLS, h_E1_start, h_E2_start], dim=-1)
得到的 h_pair 再送入下游分类层,ps: 这里我们使用每个实体的start 位置向量即可。
跨 Token 池化法
对于跨多个子词的实体(例如 “Mate 40 Pro” 会被分为 ['Mate', '40', 'Pro'] 三个或更多子词),可以先从 BERT 中提取出这几个子词对应的隐藏向量,然后做平均(或最大)池化,得到一个整体的实体向量:
h_entity = 1/n * Σ_{i=1..n} h_{token_i}
这里的平均池化相当于一种全局的特征聚合,与视觉 Transformer 中的全局平均池化类似 。SpanBERT 也强调对连续文本 Span 的建模、并可用池化来表示实体
训练关系模型:训练时,每步会计算CrossEntropyLoss,然后反向传播更新BERT参数。训练完毕后保存模型参数。基于经验,BERT微调在这样的小数据上可能容易过拟合,但应该能达到较高训练准确度。验证集上可以查看分类准确率以及每类的Precision/Recall。重点是看“品牌”和“属于类别”两个关系的指标。假设结果Precision 0.9,Recall 0.85左右(虚拟的,具体看数据)。
关系预测:有了训练好的关系模型,我们在推理时的流程将是:
-
用NER模型识别句子中的实体;
-
针对识别出的实体对组合,用关系模型判断关系类型(包括无关系)。
例如新输入一句评论:“我想买华为Mate40这款手机”。
NER识别出实体 “华为” (品牌), “Mate40” (产品), “手机” (类别)。
所有可能的实体对:(“Mate40”,“华为”), (“Mate40”,“手机”), (“华为”,“手机”)。
送入关系模型分类,预期输出 (“Mate40”,“华为”): 品牌, (“Mate40”,“手机”): 属于类别, (“华为”,“手机”): 无关系。于是得到两条三元组:(Mate40, 品牌, 华为)和(Mate40, 属于类别, 手机),正是我们需要的知识。
到此,我们的NLP管道(NER+Relation)可以将文本转化为知识三元组了。下一步就是把这些三元组构建知识图谱并存储于图数据库中。
3.4 知识图谱构建与可视化
在此阶段,我们将把抽取出的实体和关系数据加载到 Neo4j 图数据库中,实现知识图谱的构建和简单可视化。为了使过程清晰,我们分为以下子步骤:
(1) 整理知识数据:根据前两步模型的输出,汇总所有抽取的实体和关系。假设我们处理了若干商品描述文档,获得了如下集合:
-
实体集:
-
产品:{“iPhone 13”, “华为 Mate40”, “小米 11”, …}
-
品牌:{“苹果公司”, “华为”, “小米”, …}
-
类别:{“智能手机”, “平板电脑”, …}
-
(如果有其它类型也包含进去)
-
-
关系集合:
-
品牌关系:例如 (“iPhone 13”, “品牌”, “苹果公司”), (“华为 Mate40”, “品牌”, “华为”), …
-
类别关系:例如 (“iPhone 13”, “属于类别”, “智能手机”), (“华为 Mate40”, “属于类别”, “智能手机”), …
-
(其他关系集合)
-
同时,我们也可以从数据中整理属性信息,例如从描述中解析出的属性,比如 {“iPhone 13”: {“颜色”: “黑色”, “存储”: “128GB”, …}, …},后面存储节点属性时可以用上。不过这里属性不是重点,我们示范性地添加一两个以说明方法。
(2) 连接Neo4j:确保本地或服务器上已经安装并运行Neo4j数据库,记下访问端口、用户名和密码。以本地为例,默认Bolt协议URL为bolt://localhost:7687,用户名neo4j,密码在Neo4j安装时设置(或使用默认neo4j然后第一次登陆要求修改)。使用Py2neo建立连接:
from py2neo import Graph, Node, Relationship
graph = Graph("bolt://localhost:7687", auth=("neo4j", "your_password"))(3) 创建节点:遍历整理的实体集,将它们插入Neo4j。 展示了如何用Cypher MERGE语句插入节点。在这里,我们也可以使用Py2neo提供的Node类直接创建。例如:
# 插入品牌节点
for brand in brand_set:
node = Node("Brand", name=brand)
graph.merge(node, "Brand", "name")
# 插入产品节点
for prod in product_set:
node = Node("Product", name=prod)
# 如果我们有属性,比如价格,可以这样添加: node['price'] = price_dict.get(prod)
graph.merge(node, "Product", "name")
# 插入类别节点
for cat in category_set:
node = Node("Category", name=cat)
graph.merge(node, "Category", "name")这里使用graph.merge方法,它类似于MERGE语义,需要指定标签和识别节点的唯一键(这里用”name”属性作为唯一标识)。这样可以避免重复插入同名节点。
(4) 创建关系:有了节点后,我们插入关系。Py2neo可以使用Relationship对象。例如,对于品牌关系:
for prod, brand in product_brand_pairs: # 假设是列表元组: (产品名, 品牌名)
prod_node = graph.nodes.match("Product", name=prod).first()
brand_node = graph.nodes.match("Brand", name=brand).first()
if prod_node and brand_node:
rel = Relationship(prod_node, "品牌", brand_node)
graph.merge(rel, "Product", "name") # 也可用 merge 创建关系需要注意,graph.merge(rel, "Product", "name")这样的调用实际上有点特殊(Py2neo merge一个关系需要指定节点的merge key, 此处选Product.name,作用是确保用产品节点唯一确定关系)。也可以直接 graph.create(rel),不过可能重复创建相同关系。为了安全,用merge较好。
类似地,插入“属于类别”关系:
for prod, cat in product_category_pairs:
prod_node = graph.nodes.match("Product", name=prod).first()
cat_node = graph.nodes.match("Category", name=cat).first()
if prod_node and cat_node:
rel = Relationship(prod_node, "属于类别", cat_node)
graph.merge(rel)(5) 验证数据导入结果:可以在代码里查询一下数量,比如:
print(graph.nodes.match("Product").count(), "products inserted.")
print(graph.relationships.match(r_type="品牌").count(), "brand relations inserted.")如果数字吻合预期,就说明导入正确。此时,我们的Neo4j图数据库中已经有了电商知识图谱的数据。
(6) 在Neo4j Browser中可视化:打开浏览器访问 Neo4j 的浏览器界面(一般 http://localhost:7474),登录后在顶部命令行执行一些查询查看图谱。例如:
-
MATCH (p:Product)-[r:品牌]->(b:Brand) RETURN p,b LIMIT 10; 将显示一些产品和品牌节点及它们之间的边。
-
或直接 MATCH (n) RETURN n LIMIT 20; 查看随机20个节点分布。
-
可以使用Neo4j Browser的图视图模式,调节布局,让节点分布开。Product、Brand、Category节点会以不同颜色显示(可以在设置中自定义颜色)。如果一切成功,你应该能看到类似如下的子图:
【示意图:产品-品牌-类别的图结构,可选嵌入或省略】
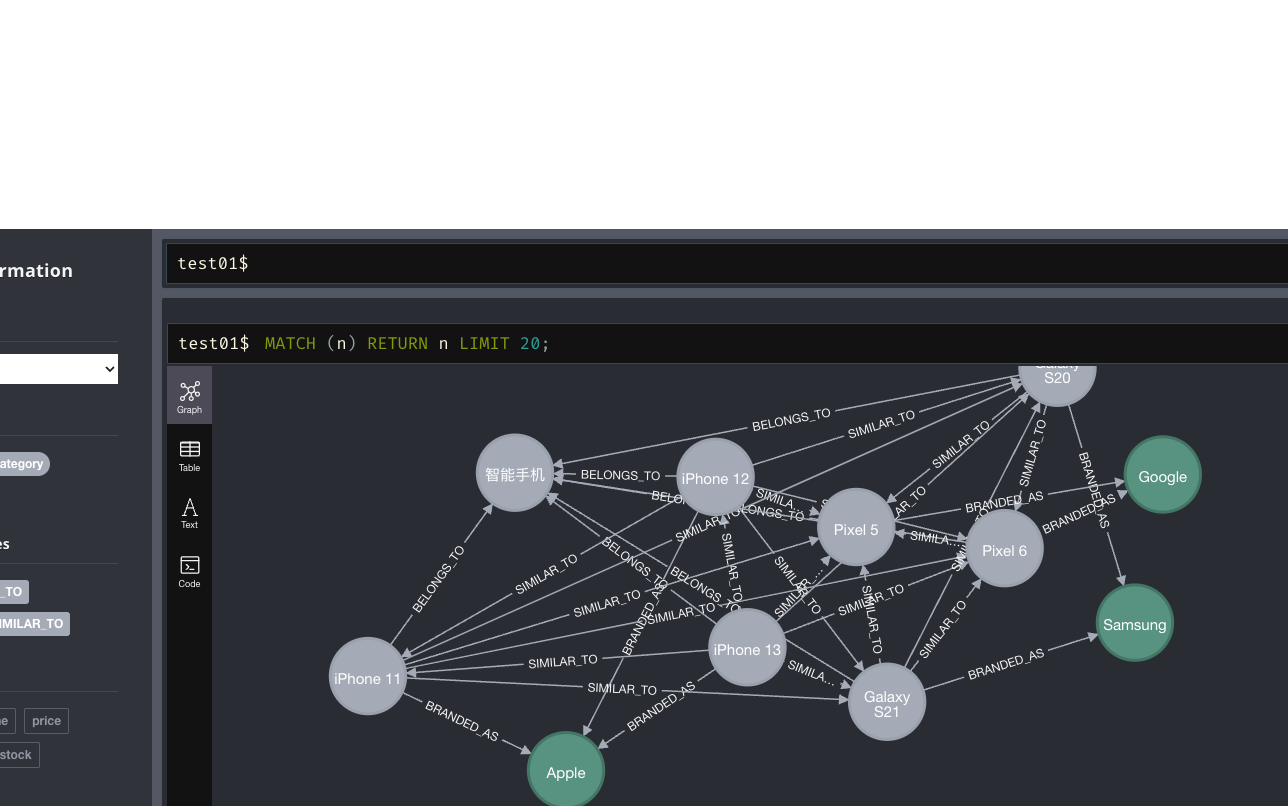
(我们用文字描述可视化结果:) 每个商品节点 (Product) 通过一条“品牌”关系指向相应的品牌节点 (Brand),同时通过“属于类别”关系指向类别节点 (Category:“智能手机”)。品牌节点往往会连接多个产品节点(一个品牌有多款产品),类别节点“智能手机”会连接很多产品节点。整个知识图谱就形成了一个以类别为中心汇聚产品,产品再各自链接到对应品牌的网状结构。此外,如果我们有添加其它关系(例如竞争关系、兼容关系),图中也会有不同类型连线,这里暂未涉及。
(7) 运行简单查询:在Neo4j浏览器中或者通过py2neo,我们可以尝试一些知识查询:
-
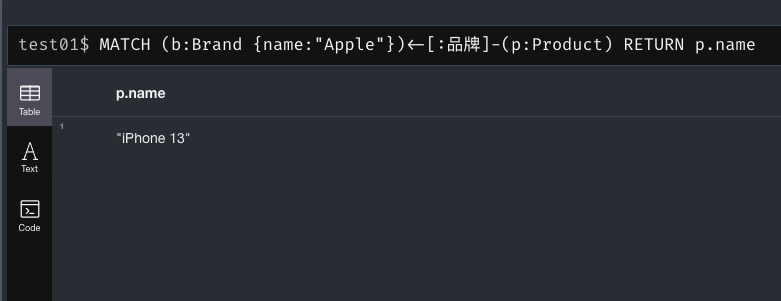
查询某品牌的所有产品:
MATCH (b:Brand {name:"苹果公司"})<-[:品牌]-(p:Product) RETURN p.name
这应该返回 [“iPhone 13”, …] 本品牌的手机列表。
-
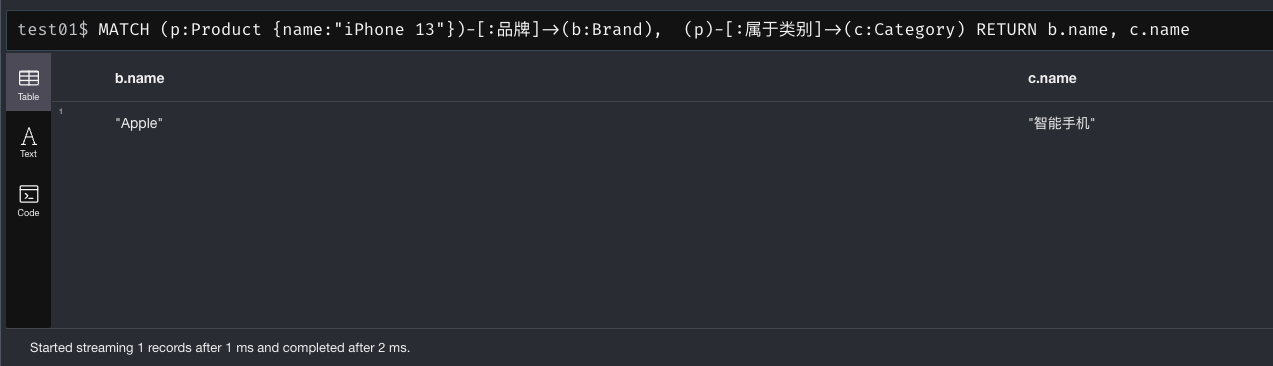
查询某产品的品牌和类别:
MATCH (p:Product {name:"iPhone 13"})-[:品牌]->(b:Brand), (p)-[:属于类别]->(c:Category) RETURN b.name, c.name
预期输出 苹果公司, 智能手机。
-
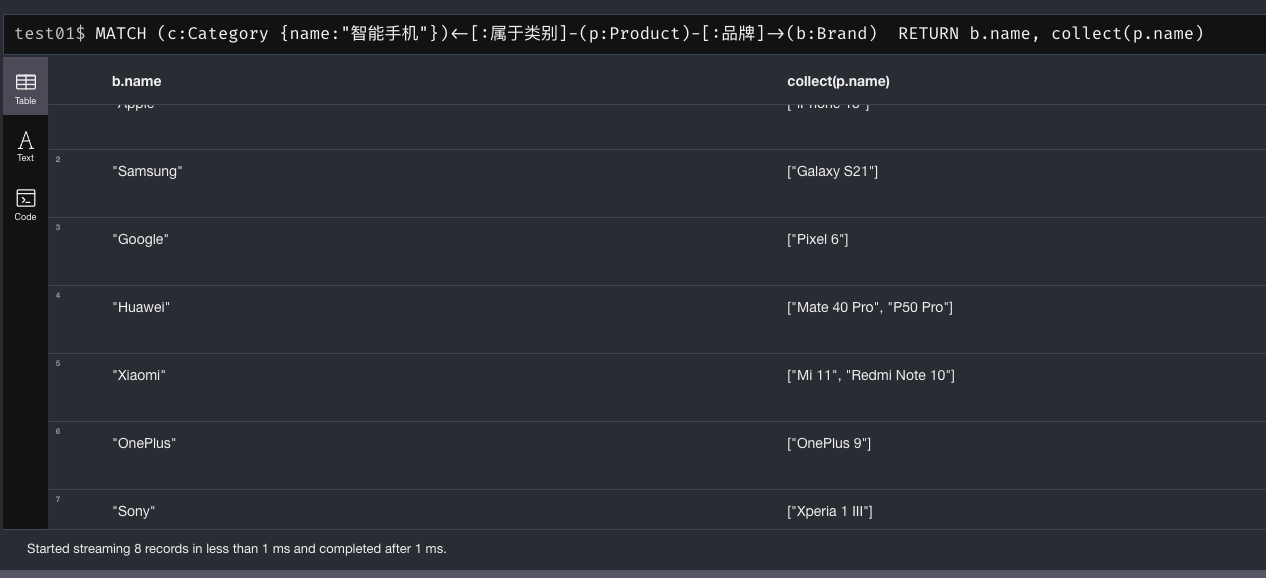
查询同类别下不同品牌的产品:
MATCH (c:Category {name:"智能手机"})<-[:属于类别]-(p:Product)-[:品牌]->(b:Brand) RETURN b.name, collect(p.name)
这会按品牌聚合同类别手机,比如返回:苹果公司 -> [iPhone13,…], 华为 -> [Mate40,…] 等。
通过以上查询,我们验证知识图谱的数据是有用的。此时,一个初步的电商知识图谱已经成功构建完成!我们可以把Neo4j持久运行,供在线服务查询使用。
3.5 API开发与部署
构建好的知识图谱需要对外提供访问接口。在本项目中,我们将创建一个简单的Flask Web服务,提供若干API接口供查询知识图谱信息。例如,实现以下功能API:
-
根据商品名称查询其所属品牌和类别;
-
根据品牌名称查询其旗下产品列表;
-
(可以扩展更多,如模糊搜索产品、推荐相似产品等,这里以简单查询为例)
Flask API 开发
创建Flask应用: 首先安装 Flask (pip install flask),然后新建文件 app.py,编写基本的Flask应用框架:
from flask import Flask, request, jsonify
from py2neo import Graph
app = Flask(__name__)
# 连接Neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "your_password"))
@app.route("/")
def home():
return "Hello, Knowledge Graph API is running."
@app.route("/product/<name>", methods=["GET"])
def get_product_info(name):
# 查询给定产品的品牌和类别
query = (
"MATCH (p:Product {name:$name})-[:品牌]->(b:Brand) "
"OPTIONAL MATCH (p)-[:属于类别]->(c:Category) "
"RETURN b.name as brand, c.name as category"
)
result = graph.run(query, name=name).data()
if result:
return jsonify({"product": name, "brand": result[0]["brand"], "category": result[0].get("category")})
else:
return jsonify({"error": "Product not found"}), 404
@app.route("/brand/<name>", methods=["GET"])
def get_brand_products(name):
# 查询给定品牌的所有产品
query = (
"MATCH (b:Brand {name:$name})<-[:品牌]-(p:Product) "
"RETURN collect(p.name) as products"
)
result = graph.run(query, name=name).data()
if result:
return jsonify({"brand": name, "products": result[0]["products"]})
else:
return jsonify({"error": "Brand not found"}), 404
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)解释:
-
建立Flask实例和Neo4j连接。实际应用中,可以把Graph对象配置在app全局或使用Flask的app.config管理,这里简单处理。
-
定义了两个路由:
-
/product/<name>:接受GET请求,通过URL路径传入产品名称,在Neo4j中查询其品牌和类别。Cypher查询使用参数绑定$name防注入。返回JSON格式包含产品、品牌、类别信息。如果找不到,返回404状态码和错误信息。
-
/brand/<name>:接受GET请求,查询该品牌下所有产品名称列表,返回JSON。
-
-
app.run()用于开发模式启动Flask服务器。实际部署不会用它,后面会介绍。
测试接口:在开发机上运行 python app.py 启动服务。然后访问 http://127.0.0.1:5000/ 应该看到返回的欢迎消息 “Hello, Knowledge Graph API is running.”。接着测试API,例如:
GET http://127.0.0.1:5000/product/iPhone%2013import requests
# 请求的 URL,注意需要对空格进行 URL 编码或直接使用 %20
url = "http://127.0.0.1:5000/product/iPhone%2013"
try:
response = requests.get(url, timeout=5) # 设置超时时间为 5 秒(可选)
response.raise_for_status() # 如果响应状态码不是 2xx,会抛出异常
# 假设返回的是 JSON
data = response.json()
print("请求成功,返回数据:")
print(data)
except requests.exceptions.HTTPError as e:
print(f"HTTP 请求失败:{e.response.status_code} {e.response.reason}")
except requests.exceptions.ConnectTimeout:
print("请求超时,请检查服务是否启动或网络是否通畅")
except requests.exceptions.RequestException as e:
print(f"请求发生错误:{e}")假设返回:{"product": "iPhone 13", "brand": "苹果公司", "category": "智能手机"},说明接口工作正常。【注意】URL中空格需编码为 %20,或者直接用+等。
另一个例子:
GET http://127.0.0.1:5000/brand/苹果公司返回:{"brand": "苹果公司", "products": ["iPhone 13", "iPhone 12", ...]}(假设我们有这些产品数据)。
通过Flask,我们已经将知识图谱查询封装成了HTTP API,可以方便地被前端或其他服务调用。下一步,我们考虑将这个Flask应用部署为生产服务。
部署:Gunicorn + Nginx
在生产环境中,直接运行Flask自带的开发服务器并不适合。通常我们使用 Gunicorn 这样的WSGI容器来运行Flask应用,并在前面加 Nginx 作为反向代理和静态服务器。这里简要介绍部署步骤:
Gunicorn部署后端:
-
安装 Gunicorn:pip install gunicorn 。
-
在服务器上(假设Linux环境),进入我们的项目目录,运行:
gunicorn -w 4 -b 0.0.0.0:5000 app:app-
这将启动4个工作进程(根据服务器CPU调整)监听在5000端口,加载我们的Flask应用实例app 。app:app表示app.py中的Flask实例名app 。
-
可以使用 nohup 将其放到后台运行,或借助 Supervisor 等进程管理工具保证服务持续运行 。例如:
nohup gunicorn -w 4 -b 0.0.0.0:5000 app:app &-
这样Gunicorn在后台运行,即使关闭终端也继续服务 。Supervisor的配置此处不详细展开,它可以监控进程挂掉自动拉起,非常适合生产环境。
Nginx 前端代理:
-
安装 Nginx(可通过apt或yum等包管理)。
-
编辑 Nginx 配置,在/etc/nginx/sites-available/下创建一个配置文件(或直接编辑nginx.conf):
server {
listen 80;
server_name your_domain_or_IP;
location / {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}-
这个配置意思是监听80端口的HTTP请求,将所有请求转发(proxy_pass)到本机5000端口,也就是Gunicorn服务所在。通过设置Host头等保持原始请求信息。
-
如果还有静态页面(比如前端HTML页面)也可以通过Nginx配置静态目录来提供。在本例中,我们主要提供API,没有前端页面,所以简单代理即可。
-
启用站点配置并重启Nginx:
ln -s /etc/nginx/sites-available/your_conf /etc/nginx/sites-enabled/
nginx -t # 测试配置
systemctl restart nginx
-
如有云服务器需要在安全组或防火墙放行80端口。
完成以上配置后,我们就可以通过服务器的域名或IP来访问API,例如 http://your_server/product/小米%2011 将由Nginx接收并转发给Gunicorn的Flask服务处理,再将结果返回给客户端。
部署完毕的服务,在架构上是前端Nginx + 后端Flask(Gunicorn)。Nginx可以处理更高的并发,缓存静态内容,做负载均衡,提升了服务的稳定性和性能。而Gunicorn提供多进程并发执行Python代码,提高了Flask应用的吞吐量。实际上,如果流量巨大,还可以扩展为多个Gunicorn实例+Nginx负载均衡,或者使用容器编排等。本例暂不深入。
至此,我们已经完成一个完整的电商知识图谱项目的开发和部署流程。从原始数据到知识挖掘,再到知识入库与服务化,每一步都有所涉及。当然,由于篇幅和精力所限,实际代码可能在工程上需要更多健壮性处理,比如错误处理、日志、配置管理、模型优化等,但本文已经提供了核心思路和实现示例。读者可以据此搭建起自己的知识图谱系统原型,并根据需要扩展功能。
4. 技术难点与挑战 (Challenges & Difficulties)
在构建和应用知识图谱的过程中,我们会遇到许多现实挑战。本节讨论几个主要难点,并提出常见的应对策略。
4.1 数据异构与整合
数据异构性指的是知识图谱构建需要面对来自不同数据源、不同格式的数据。例如,在电商领域,我们可能需要整合商品的结构化数据(如数据库中的商品表)、半结构化数据(如Excel、CSV),以及非结构化文本(如商品描述、评论)。不同来源的数据模式各异、质量不一,直接组合会产生问题。如何统一地表示和整合这些异构数据是一个挑战。
应对策略:
-
在抽取前对源数据进行格式转换和标准化:比如把Excel转成CSV/JSON统一处理,把文本编码和特殊符号清洗等。
-
设计合理的中间数据模型,如统一抽取出三元组或统一的属性表,再导入图数据库。可以使用ETL流程或自定义脚本清洗转换数据。
-
利用开放知识规范:如RDF/OWL等语义网标准,制定统一的数据表示规范。尽管在实际工程中未必全盘使用RDF,但采用统一 schema 和唯一标识(URI/主键)有助于消除异构差异。
4.2 实体歧义与消歧
语义消歧问题广泛存在于知识图谱中,主要包括实体消歧和概念消歧。实体消歧指区分同名异义的实体,概念消歧指理解上下文语义。例如,“苹果”可以指电子品牌也可以指水果;“Java”可以指编程语言也可以指印尼爪哇岛。我们的NER模型往往只能识别出“苹果”这个词,但无法直接确定其确切含义。知识图谱要求每个实体节点都明确唯一,因此需要对上下文中的实体进行消歧链接到知识库中的正确节点。
应对策略:
-
基于上下文:利用实体周围的词语来推断意义。例如“苹果推出了新手机”,上下文有“手机”,可推断“苹果”是品牌。可以构建规则或者训练一个消歧分类模型来完成。
-
实体链接 (Entity Linking):将文本中的实体链接到已有的知识库(如维基百科或本地知识库)中的唯一实体。实现上通常包括:先识别mention(表面名字),然后产生候选实体(通过别名字典等),再根据上下文计算每个候选的匹配分数(使用embedding、上下文相似度、知识库中实体属性等),最后选出最可能的实体。比如“Apple”通过候选生成可能是{Apple Inc., Apple fruit},然后看上下文词“iPhone”更贴近公司,选Apple Inc.。
-
同义词和别名处理:建立实体的别名词典,在链接时考虑别名。例如“苹果公司”别名“苹果”、“Apple”、“Apple Inc.”等,帮助将不同名称消歧到同一实体。
-
利用预训练模型:近年也有使用BERT等大模型进行消歧的研究,输入上下文让模型直接预测对应知识库实体。这在有大规模训练语料时效果较好。
4.3 知识更新与维护
知识图谱构建不是一次性的,现实世界知识不断变化,图谱需要更新维护。电商领域尤其如此,新产品不断发布,价格库存实时变化。如果知识图谱不能及时更新,就会陈旧过时。另外,更新时要考虑高效和一致性。
挑战:
-
如何检测和获取新知识:需要建立数据管道定期抓取新数据或接收上游数据变更。例如每天获取新品上架信息、过期产品下架信息等。
-
增量更新:对于新抓取的数据,不可能每次都从头构建整个图谱,那样代价太高。需要支持增量地添加新实体、新关系。同时,对于已有节点的属性变更要更新(如价格变动)。
-
版本管理:有时需要保留历史知识,比如商品历史价格、已下架产品的信息等等。这涉及版本化存储,或者采用有效期属性等方法。
-
一致性维护:随着多次更新,可能引入不一致(如重复节点,或者早期标准和后来不一致)。需要定期运行清洗规则,例如合并重复、移除孤立节点、验证关系有效性等。
应对策略:
-
建立定期爬虫或数据Feed,自动把变化数据送入知识图谱pipline。
-
采用流水线架构:比如使用Apache NiFi、Airflow等工作流工具调度知识图谱更新流程,在管道中处理增量数据。
-
针对Neo4j等图数据库,可以直接使用Cypher MERGE插入或更新属性,实现幂等更新操作(多次执行不会重复添加同样数据)。
-
设计监控与校验机制,每隔一段时间对图谱数据运行检查(如查询可能的重复节点pattern)并人工审查。
-
如有条件,可开发图谱维护工具界面,方便人工对异常数据进行增删改,保证长期质量。
4.4 知识融合冲突
在2.5节知识融合部分已经提到,当融合多源数据时会产生冲突,这里再强调其挑战性。冲突不仅来自数据本身矛盾,还包括知识图谱演化过程中引入的新知识与旧知识的冲突。例如,不同来源对于某商品的参数有不同值;或者图谱更新时新的分类体系和旧的体系不兼容。
策略上,冲突的解决需要依据业务规则和可信度:
-
制定优先级规则:例如“官方数据优于爬取数据”,“最近更新时间优于旧数据”等,出现冲突按优先规则取舍。
-
人工仲裁:对于无法自动判决的冲突(比如两数据源各说一词),可以打上标记提交给领域专家核实后调整。
-
记录数据来源:在图谱中保留每条关系、属性的来源和更新时间属性。这既方便做冲突分析,也为将来追溯和更新提供依据。比如如果一个属性有多个不同值来源,可以通过来源可信度计算最终采用值,同时保留其它值但做标记。
-
软融合:对于某些冲突,不强行删除一方,而是允许知识图谱暂时存在冲突信息,并通过应用层选择使用哪个。例如图谱中保留两个属性值,但在查询时只返回可信度最高的,或者返回两个让用户自行判断。这种做法在无法确定真假的情况下是一种折中。
4.5 系统性能与扩展性
可扩展性和性能也是知识图谱项目必须考虑的挑战。当数据规模从几千上万增长到百万级甚至更高时,无论是存储、查询还是更新,都会遇到瓶颈。电商知识图谱如果涵盖所有商品和用户,节点和关系数可能达到亿级。此外,并发访问量高时如何保持查询性能也是问题。
应对策略:
-
图数据库扩展:像Neo4j在社区版只能单机,企业版支持集群。如果预算许可,可采用Neo4j集群或云服务,或者考虑其它分布式图数据库(如JanusGraph、NebulaGraph等) 。这些方案能够横向扩展存储和查询能力。
-
缓存:为提高查询响应,可在应用层增加缓存(比如Redis)存储热点查询结果,避免频繁访问数据库。
-
异步批处理:对于大量的更新操作,尽量采用批处理方式而非逐条执行。Neo4j支持批量导入工具(如neo4j-admin import)以及批量Cypher提交,可以加快构建。我们之前用的Py2neo插入如果处理百万数据就会慢,需要改用批量语句或分片导入。
-
查询优化:设计良好的索引和模式。比如给节点的关键属性建索引(Neo4j对节点标签+属性组合建唯一索引我们已经用了)。编写Cypher时也要注意,让查询走索引而不是全图扫描。另外可适当预计算一些关系或建立物化视图节点来简化复杂查询。
-
图计算:如果需要在大图上做复杂分析(例如路径搜索、社区发现),可以考虑将数据导出用专业的图计算框架(如GraphX、Gephi)处理,然后再把结果回写知识图谱,用于查询。
总之,小规模知识图谱可以轻松跑在单机Neo4j上,但大规模场景下需要结合分布式存储、并行计算等手段,同时根据应用需求做取舍(并不是所有数据都要实时查询,一些统计类的东西可以异步离线算好)。
4.6 其他挑战
还有一些其他挑战也值得一提:
-
知识表示质量:三元组的表示很直观,但对于复杂知识可能不够,例如事件(涉及时间地点参与者)、或者数量值、范围等。需要扩展图谱schema来支持时空信息、上下位关系(本体层面)等。
-
用户隐私与安全:在涉及用户数据的图谱时,要注意脱敏和权限控制。确保敏感信息不在公开的知识图谱中泄露。
-
人机协作:完全自动化构建的知识图谱可能掺杂错误,为了达到可用质量,往往需要人工校正和补充。因此怎样设计人机交互流程、降低人工成本也是挑战。例如在图谱构建中引入主动学习策略,让模型挑选不确定的样本交给人标注,以高效提升质量。
面对上述挑战,没有一劳永逸的解决方案。知识图谱项目通常是迭代演进的过程:先实现基本功能,再逐步完善处理更多困难问题。在电商这样竞争激烈的领域,将知识图谱成功应用到业务中,需要技术和业务团队密切配合,不断根据反馈改进图谱的覆盖度和准确性。
5. 未来趋势与融合 (Future Trends & Integration)
知识图谱技术正处于快速发展和演化中,展望未来,有几大方向值得关注,这些新趋势将进一步提升知识图谱的价值,并拓展其应用边界。
5.1 知识图谱与大语言模型 (KG + LLM)
近年来大语言模型(LLM)如GPT-4/deepseek、BERT等在NLP领域取得了突破,它们在生成文本、问答等任务上表现出色。然而,纯语言模型缺乏显式的事实知识存储和可解释性,而知识图谱恰好提供结构化知识和可解释关系。因此,知识图谱与LLM的结合成为热点研究方向 。这种结合有双向的几种模式 :
-
KG支撑LLM:利用知识图谱增强大语言模型的能力。例如在问答系统中,LLM处理自然语言,但需要查询事实时,调用知识图谱获取准确答案(即检索增强生成,RAG)。这样可以弥补语言模型在事实细节上的不足,提高问答准确性和可信性 。另外,知识图谱可用于约束LLM的输出,防止不真实的生成。
-
LLM赋能KG:用大语言模型来改进知识图谱构建。例如,LLM擅长阅读理解和生成,可以用于从文本中自动抽取三元组、生成本体概念、甚至根据描述自动扩充知识 。一些研究表明,预训练模型可以用于关系抽取、实体链接等子任务,减少对标注数据的依赖。此外,LLM还可以用来为知识图谱中的实体生成更丰富的自然语言描述,增强图谱的可读性 。
-
联合推理:探索LLM与KG共同进行推理和问答。例如, 一个智能问答系统同时具备KG的符号推理能力和LLM的常识推理能力。当用户提问涉及复杂推理时,KG可以提供精确的逻辑演算,而LLM提供常识补充和语言表达。这种互补关系将有助于构建更强大的AI系统 。
目前已有一些系统尝试例如:在对话机器人中,实时查询知识图谱获取最新信息(如日历、百科知识)然后融合到LLM回复中;或用GPT-4,deepseek 来读取企业文档构建内部知识图谱等等。这方面的研究和应用还在早期摸索阶段,但前景广阔——未来的AI系统很可能同时拥有“参数记忆”(LLM)和“符号知识库”(KG),让AI既聪明又可信。
5.2 图机器学习与图神经网络
图机器学习是近年来兴起的领域,图神经网络(Graph Neural Networks, GNN)是其最主要的方法论之一。知识图谱天然是一种图结构数据,因此将GNN应用于知识图谱,可以在表征学习和推理预测上取得显著效果。例如:
-
知识嵌入:早期知识图谱的嵌入方法如TransE系列,通过线性模型学习实体和关系的低维向量表示,用于做链接预测等 。而GNN提供了一种更强大的端到端框架:将知识图谱作为一张图,将实体初始特征(例如one-hot或预训练文本向量)输入,通过图神经网络(如GCN、R-GCN)传播和聚合邻居信息,得到每个实体的表示向量。这样得到的实体embedding可以捕获图结构的局部和全局信息,可用于知识推断(比如预测知识图谱中缺失的关系)或下游任务(比如商品推荐、关系分类等) 。
-
关系推理:有些GNN专门针对知识图谱的多关系性质进行了改进,如R-GCN(关系图卷积网络)、CompGCN 等,它们在每种关系类型上学习不同的转换,使得模型能够区分不同类型边的影响 。实验表明,这些模型在知识图谱的链路预测任务上性能优于传统嵌入方法,在标准基准数据集上取得了更高的准确率。
-
图上的机器学习应用:利用知识图谱的结构,可以在电商场景做推荐系统(用户-商品-属性形成图,GNN可用于学习用户和商品的隐含特征) 、客户行为分析(通过用户行为知识图谱进行社区发现或异常检测),以及问答推理(在图上搜索路径作推理)。例如,Pinterest 将海量Pin组成图谱,用GraphSAGE模型对用户兴趣进行推荐,显著提升了点击率 。Uber Eats使用GNN改进了推荐排序特征 。这些成功案例预示着图学习在工业界大放异彩。
可以预见,未来知识图谱与图机器学习会更加紧密结合。“拿知识图谱做机器学习”将成为常态。例如,将一个企业的知识图谱当作特征网络输入GNN,输出对企业的信用评分;将医学知识图谱输入GNN预测药物效果等等。一些工具和平台也在出现,如DGL、PyG等图深度学习框架支持直接导入知识图谱数据。对于我们开发者来说,这意味着掌握传统KG构建之外,还需要掌握一些图机器学习技能,以充分释放知识图谱数据的价值。
5.3 实时推理与流式知识图谱
传统知识图谱多是离线构建-在线查询模式,而随着实时数据的增长,流式知识图谱和实时推理变得重要。例如,电商网站的商品和用户行为是实时变化的,如果能将这些变化以流的方式更新到知识图谱中,就能支持更加动态的应用,例如实时推荐、实时风险监测等。
想象一个场景:用户此刻浏览了某产品A,在他的实时行为知识图谱中加入节点“User_X 查看 Product_A”,然后触发一个实时规则查询“有没有其他用户也查看过A然后购买了其他东西?”通过知识图谱可以立即找到关联,给出推荐。这需要知识图谱能高频率更新和即时查询,传统批处理显然不够。
对此,一些技术方向包括:
-
流数据接入:使用Kafka等实时流,将事件数据不断写入图数据库。如Neo4j近来也推出了Bloom Stream等工具尝试结合流。
-
内存图谱与流处理:一些研究使用内存型图数据结构(例如基于Redis的图或者自研内存图)以获取高速的更新和查询性能。同时结合CEP(复杂事件处理)引擎在知识图谱上执行持续查询,当匹配到某个模式时立即触发动作。
-
增量推理:传统推理(如OWL推理)通常在批量下进行,实时场景需要增量推理算法,即当图谱新增一两个事实时,仅重新计算受影响的部分推理结果,提高效率。
-
Temporal KG(时序知识图谱):把时间作为一等公民,知识可以按有效时间存储,这样可以查询随时间变化的知识,或支持时间范围推理。例如查询“截至去年年底销量最高的手机”这样的时序问题。时序知识图谱需要设计特殊的数据组织和索引策略,以便在时间维度快速查询。
实时知识图谱应用在金融风控(实时检测欺诈关系网络)、网络安全(实时威胁情报图谱)、电商实时推荐等领域都有很大潜力。随着流处理和图计算技术的发展,我们有理由相信以实时、高吞吐为特点的新一代知识图谱系统会逐渐出现,拓展知识图谱的应用边界。
5.4 知识图谱驱动的智能问答与对话
智能问答系统是知识图谱的重要应用方向之一。未来,知识图谱有望与NLU(自然语言理解)更深入结合,驱动更智能的问答和对话系统。例如,微软的对话式搜索和Siri/Google Assistant等语音助手,背后都结合了知识图谱来提供精准答案和执行复杂任务。
一些值得期待的进展包括:
-
多跳推理问答:通过知识图谱可以回答需要多步推理的问题。例如“某某公司的CEO的母校在哪里?” 需要公司->CEO->人物->母校,这是一条知识链。知识图谱天生适合这样的链式推理问答。未来的QA系统会更加善用KG做逻辑推理,而不像早期那样仅匹配文本。
-
可解释的问答:基于知识图谱的问答可以返回解释路径。比如回答上述问题时,系统可以同时展示知识路径以增强可信度。这种可解释AI特性在需要说服力的场景很重要(如医疗诊断问答,需要给出依据)。
-
对话管理:在任务型对话系统中,知识图谱可以用来跟踪对话状态、维护上下文知识。例如电商客服机器人,通过接入商品知识图谱,能够理解用户提到的产品细节,在对话中持续引用先前提到的实体,避免混淆 。知识图谱还可以帮助对用户意图进行语义归类,通过知识节点的关系确定用户想要哪方面信息。
-
个性化和推荐:将用户的个人知识(喜好、历史购买等)融入知识图谱,再用于对话,实现个性化回答。比如用户问“这手机支持无线充电吗?”,机器人除了回答还可以补充“您之前购买的充电器也兼容这功能”,因为知识图谱连通了该手机、无线充电器和用户购买记录。这种定制化对话离不开强大的知识图谱支撑。
同时,大语言模型的发展也在改变传统QA的格局,如何让KG与LLM配合已经前述。总之,知识图谱在让机器“听懂问答”方面有独特作用,未来我们会看到越来越多基于知识图谱的智能客服、专家系统等出现在各行各业。
5.5 领域知识图谱与行业实践
最后,不得不提的是行业垂直领域知识图谱的趋势。随着技术成熟,各行业都在构建自己的知识图谱来沉淀专业知识:
-
医疗:医疗知识图谱用于疾病诊断辅助、医疗问答、药物发现等 。比如汇集疾病、症状、药物、副作用等知识,提供给医生查询或辅助AI诊断。国内一些医疗AI公司已构建大型医学知识图谱,用于智能导诊系统等。
-
金融:金融领域有大量异构数据(公告、新闻、交易数据等),知识图谱可以帮助风控、投资分析。例如企业关系图谱用来发现隐秘的关联企业、股权穿透关系等 。银行用知识图谱来做反欺诈,串联起看似无关的帐户和交易找到欺诈团伙。
-
制造与工业:工业知识图谱可以把设备、零件、工艺流程等知识关联起来,实现智能制造、故障诊断。比如波音公司构建飞机零件知识图谱帮助维修排故;大型制造业用知识图谱整合供应链知识,优化生产计划等等。
-
教育:教育知识图谱将教材知识点、试题、学生学习行为连接起来,形成知识图谱+推荐学习路径的智能教育系统 。学生答错的题可以在知识图谱上找到其关联知识点并推荐补习相关内容。
展望未来,各行各业的知识图谱可能通过知识联邦的方式互联,形成更大的知识网络。同时,政府和组织也在推进开放知识图谱(OpenKG等项目) ,鼓励共享通用领域的知识数据。这将为开发者提供更多基础资源,降低构建知识图谱的门槛。
从个人开发者角度来说,应该关注本行业的知识图谱动态,积极尝试将知识图谱与业务问题结合,哪怕先构建小规模原型,因为知识图谱的价值往往在规模到一定程度后才会凸显。但早布局早受益,积累数据和本体是长期投入。好消息是,越来越多的开源工具和预训练模型可以帮助我们更快地构建知识图谱。例如有开源项目提供了金融知识图谱样例,法律知识图谱数据等 。我们也应多利用这些资源。
6. 附录与参考资料 (Appendix & References)
本节列出文中用到或提及的关键工具、数据集、以及扩展阅读资料,供读者参考和深入学习。
6.1 开源工具与平台
-
Doccano – 开源文本标注平台,用于分类、序列标注、关系标注等 。GitHub: GitHub - doccano/doccano: Open source annotation tool for machine learning practitioners.。本项目中用于标注电商文本的实体和关系,特点是支持协作与多语言界面。
-
Neo4j – 最流行的图数据库之一,用于存储和查询知识图谱。社区版开源免费,提供Cypher查询语言和Neo4j Browser可视化。官网: Neo4j Graph Database & Analytics | Graph Database Management System。Neo4j在电商知识图谱中充当核心存储与查询引擎,适合高度连接数据的操作 。
-
Py2neo – Neo4j官方推荐的Python驱动,可通过Python语法方便地操作Neo4j数据库。我们用它来插入数据和执行查询。
-
Flask – 轻量级Web框架,用于构建API服务。擅长快速原型开发。官网: Welcome to Flask — Flask Documentation (3.1.x)。在本教程中用于开发知识图谱查询接口服务。
-
Gunicorn – Python WSGI服务器,搭配Flask等应用用于生产部署 。通过多进程提高并发能力。官网: Gunicorn - Python WSGI HTTP Server for UNIX。
-
OntoStudio – 一个商用的本体构建和管理工具,由德国Semafora公司开发(原名Ontoprise)。支持图形界面构建OWL本体、推理等。适合企业级本体管理。官网: (可能需要搜索OntoStudio)。由于其闭源且收费,这里不作详述,提及是为了知道业界有这样的专业工具。
-
Protégé – 开源本体编辑器,由斯坦福开发。支持OWL/RDF等格式的本体构建,有丰富的插件(如推理机Pellet)。下载: protégé。
-
Transformers (HuggingFace) – 强大的预训练模型库,提供BERT、GPT等模型接口。我们在关系抽取时提到了可用BERT微调,这个库可以方便地加载预训练中文BERT模型。
-
Graph Neural Network 库: 包括 Deep Graph Library (DGL), PyTorch Geometric (PyG) 等。如果读者有兴趣将GNN用于知识图谱,可参考这些开源项目。它们提供常用的GNN模型实现,支持快速搭建实验。
6.2 数据集资源
-
Amazon Product Data – 亚马逊产品和评论数据集 。由加州大学SD的Julian McAuley提供,涵盖1996-2014年数亿评论和产品元数据 。下载地址: Amazon review data 或 Amazon review data。本项目示例使用了其中手机产品的子集。数据包含产品基本信息(名称、描述、类别、品牌等) 和评论,可用于电商推荐、知识图谱构建练习等 。
-
OpenBG – 开放商业知识图谱,由阿里巴巴提供 。包含了数以百万计的产品和丰富属性关系的知识图谱数据,可通过阿里云天池平台获取。它提供了统一的Schema覆盖多模态数据,是一个大规模电商知识图谱的实例。
-
阿里巴巴电商数据集 – 阿里天池平台上也发布过一些电商相关数据,如商品信息、评论、问答等 。例如“AliCoCo: Alibaba E-commerce Cognitive Concept Net” 是一个认知概念网络数据集。
-
OpenKG.CN – 中文知识图谱开放平台,汇总了各领域的公开知识图谱数据 。涵盖百科、医学、金融等若干数据集,许多有RDF下载。对于想获取现成KG数据练习的读者,这是一个好去处。
-
CN-DBpedia – 中文开放百科知识图谱,类似英文DBpedia,从中文维基提取而来。官网: http://cn.dbpedia.org/。包含通用领域的实体和关系,可用于通用问答或与领域知识融合。
-
CCKS竞赛数据 – 每年国内知识图谱与语义技术大会(CCKS)都会发布比赛数据,如命名实体识别、关系抽取等数据集。很多可以在网上找到下载,用于训练模型非常有价值。
6.3 深入阅读与论文
-
知识图谱综述: 《知识图谱:方法及应用》 (2018,中文) 是一篇全面的综述性论文,作者包括唐杰等,对知识图谱概念、构建方法、应用作了详细介绍,适合打基础。
-
Google Knowledge Vault: Google在2014年的论文 Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion 提出了Google自动构建超大规模知识库的思路,用机器学习+概率图的方法融合网页提取的知识,值得阅读了解知识融合前沿方法。
-
TransE 原论文: Translating Embeddings for Modeling Multi-relational Data (2013) by Bordes et al. 是知识图谱嵌入的经典论文,提出了TransE模型 , 开启了知识表示学习的新方向。
-
Graph Neural Networks综述: 许多,推荐一篇较新的 A Comprehensive Survey on Graph Neural Networks (Zhou et al. 2018) 或者关注最新2024年的动向,如 Michael Galkin 在Medium上的文章,讨论GNN在知识图谱链接预测中的表达能力等 。
-
LLM+KG研究: 可以查看 VLDB 2024 LLM-KG研讨会的一篇论文 Research Trends for the Interplay between LLMs and KGs 。该文调研了LLM和知识图谱结合的各种方式和挑战,对于理解未来方向很有帮助。
-
行业案例: 建议阅读一些实际案例博客。例如DoorDash工程博客有文章讲如何用产品知识图谱改进推荐 ;Pinterest在KDD发表的PinSage论文讲GNN在推荐中应用 ;阿里在CCF上分享的金融知识图谱实践等 。这些文章能够桥接理论和实践,启发具体应用的思路。
6.4 参考文献索引
本文中引用了部分资料来源如下(按照出现顺序):
-
【4】 知识图谱概念与例子说明
-
【36】 谷歌提出知识图谱及应用领域
-
【23】 知识图谱在AI中的地位
-
【36】 知识图谱定义(结构化语义知识库)
-
【34】 BiLSTM+CRF 模型训练日志示例
-
【3】 数据处理及模型片段,关系抽取流程
-
【11】 属性抽取与知识融合要点
-
【16】 Neo4j 导入实体和关系的Cypher 示例
-
【15】 图数据库在知识图谱中的应用
-
【8】 Doccano 平台介绍与安装步骤
-
【9】 Doccano 特点和主要功能
-
【10】 Flask 框架定义 (PyTorch官网部署框架提及)
-
【21】 对话系统中知识图谱应用场景
-
【20】 LLM 与 KG 结合研究摘要
-
【19】 GNN 与知识图谱链接预测的表达能力研究
-
【31】 工业界应用GNN提升推荐效果的案例
-
【33】 2023年知识图谱链接预测GNN表达性研究
-
【7】 OpenBG 开源商业知识图谱信息
-
【12】 华为云博客-知识图谱数据集汇总
读者可根据上述索引查阅引用内容以获取更详细的信息。
写在最后: 本文作为一篇超长教程,详细讲解了知识图谱从概念到实战的方方面面。通过电商行业的案例,我们走完了构建知识图谱的完整流程:数据->信息抽取->图谱存储->接口服务,并讨论了过程中面临的挑战和未来趋势。希望读者在实践中大胆尝试,将知识图谱技术运用到自己的项目中。知识图谱的世界广阔而精彩,期待大家构建出更多有价值的图谱系统!
码字不容易,喜欢本文的朋友请点赞、收藏、转发,并关注我的博客,让更多人加入我们的数据科学狂欢吧!
希望这篇文章和代码讲解对你有所帮助!如果有任何疑问或建议,欢迎在评论区留言讨论,共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









