






系列文章目录
文章目录
前言
暑期学习
一、匿名内部类
匿名对象:没有名字的对象,调用方法的使用,仅仅是调用一次的时候
注意:调用多次的时候,使用匿名对象不合适那么,为什么还会存在匿名对象呢?匿名对象在调用完毕之后,由于栈内存中没有引用指向它,那么调用完后,就是一个垃圾空间,可以被垃圾回收器回收。
匿名内部类:它的本质是一个 带具体实现的 父类或者父接口的 匿名的 子类对象。
匿名内部类的创建方法:
public class Run1{
public void test(){
new Run(){
public void run() {
System.out.println("can run");
}
public int getSpeed() {
return 3;
}
}.run();
}
}
原文链接:https://blog.csdn.net/qq_44823756/article/details/120402324
二、Lambda表达式写法
第一种写法:有参数无返回值
public static void main(String[] args) {
// 1.采用匿名内部类方式 接口代替实现类对象
MyInterface my = new MyInterface() {
@Override
public void sum(int a, int b) {//实例方法(非static修饰)
// 没有返回值就直接进行输出
System.out.println(a + b);
}
MyInterface my1 = ( a, b) -> System.out.println(a + b);
第二种写法:有参数有返回值
public static void main(String[] args) {
// 1.采用匿名内部类方式
MyInterface my1 = new MyInterface() {
@Override
public int sum(int a, int b) {
return a+b;
}
};
// 2.采用lambda表达式:简化版
MyInterface my2 =(a,b) -> a+b;
第三种写法:无参无返回值测试类
// 1.采用匿名内部类方式
MyInterface my = new MyInterface() {
// 重写抽象父类中的抽象方法
@Override
public void speaking() {
System.out.println("每个人从小就要学说话");
}
};
// 2.采用lambda表达式 简化版
MyInterface my1 = ()-> System.out.println("每个人从小就要动作")
原文链接:[https://blog.csdn.net/m0_64210833/article/details/123697495]
三、函数式接口
生产型接口Supplier
接口仅包含一个无参的方法:T get() 。用来获取一个泛型参数指定类型的对象数据。由于这是一个函数式接口,这也就意味着对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象数据。
获取一个字符串返回值:
public class Demo01Supplier {
public static void main(String[] args) {
//调用getString方法,方法的参数Supplier是一个函数式接口,
//所以可以传递Lambda表达式
String s = getString(()->{
//生产一个字符串,并返回
return "zjq666";
});
System.out.println(s);
//优化Lambda表达式
String s2 = getString(()->"zjq666");
System.out.println(s2);
}
//定义一个方法,方法的参数传递Supplier<T>接口,
//泛型执行String,get方法就会返回一个String
public static String getString(Supplier<String> sup){
return sup.get();
}
}
输出如下:
zjq666
zjq666
消费型接口Consumer
接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型决定。Consumer 接口中包含抽象方法void accept(T t) ,意为消费一个指定泛型的数据。
public class Demo01Consumer {
/**
定义一个方法
方法的参数传递一个字符串的姓名
方法的参数传递Consumer接口,泛型使用String
可以使用Consumer接口消费字符串的姓名
*/
public static void method(String name, Consumer<String> con){
con.accept(name);
}
public static void main(String[] args) {
//调用method方法,传递字符串姓名,方法的另一个参数是Consumer接口,是一个函数式接口,所以可以传递Lambda表达式
method("zjq666",(String name)->{
//对传递的字符串进行消费
//消费方式:直接输出字符串
//System.out.println(name);
//消费方式:把字符串进行反转输出
String reName = new StringBuffer(name).reverse().toString();
System.out.println(reName);
});
}
}
判断型接口Predicate
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用java.util.function.Predicate 接口。
Predicate接口中包含一个抽象方法:
boolean test(T t):用来对指定数据类型数据进行判断的方法
结果:
符合条件,返回true
不符合条件,返回false
public class Demo01Predicate {
/**
定义一个方法
参数传递一个String类型的字符串
传递一个Predicate接口,泛型使用String
使用Predicate中的方法test对字符串进行判断,并把判断的结果返回
*/
public static boolean checkString(String s, Predicate<String> pre){
return pre.test(s);
}
public static void main(String[] args) {
//定义一个字符串
String s = "abcdef";
//调用checkString方法对字符串进行校验,参数传递字符串和Lambda表达式
/**boolean b = checkString(s,(String str)->{
//对参数传递的字符串进行判断,判断字符串的长度是否大于5,并把判断的结果返回
return str.length()>5;
});*/
//优化Lambda表达式
boolean b = checkString(s,str->str.length()>5);
System.out.println(b);
}
}
类型转换接口Function
接口用来根据一个类型的数据得到另一个类型的数据,
前者称为前置条件,后者称为后置条件。
Function接口中最主要的抽象方法为:R apply(T t),根据类型T的参数获取类型R的结果。
使用的场景例如:将String类型转换为Integer类型。
public class Demo01Function {
/**
定义一个方法
方法的参数传递一个字符串类型的整数
方法的参数传递一个Function接口,泛型使用<String,Integer>
使用Function接口中的方法apply,把字符串类型的整数,转换为Integer类型的整数
*/
public static void change(String s, Function<String,Integer> fun){
//Integer in = fun.apply(s);
int in = fun.apply(s);//自动拆箱 Integer->int
System.out.println(in);
}
public static void main(String[] args) {
//定义一个字符串类型的整数
String s = "1234";
//调用change方法,传递字符串类型的整数,和Lambda表达式
change(s,(String str)->{
//把字符串类型的整数,转换为Integer类型的整数返回
return Integer.parseInt(str);
});
//优化Lambda
change(s,str->Integer.parseInt(str));
}
}
原文链接:https://blog.csdn.net/qq_35427589/article/details/124497496
四、Stream流
1、转换成流
数组转换成流:
String [] players = Arrays.asList("z","j","x");
Stream.of(players).filter().map();
集合转换成流:
List<String> players=Arrays.asList("z","j","x");
//过滤以x开头,并转换成大写的字符串
players.stream().filter(s->s.startWith("x")).map(String::toUpperCase)
文件转换成流:
Stream<String> stringStream = Files.lines(Paths.get("file.txt"));
2、基于filter()实现数据过滤
该方法会接收一个返回boolean的函数作为参数,终返回一个包括所有符合条件元素的流。
案例:获取所有年龄20岁以下的学生
public class FilterDemo {
public static void main(String[] args) {
//获取所有年龄20岁以下的学生
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
students.stream().filter(student -> student.getAge()<20);
}
}
3、基于distinct实现数据去重
public class DistinctDemo {
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
integers.stream().distinct().collect(Collectors.toList());
}
}
在distinct()内部是基于LinkedHashSet对流中数据进行去重,并终返回一个新的流。
4、基于limit()实现数据截取
该方法会返回一个不超过给定长度的流
案例:获取数组的前五位
public class LimitDemo {
public static void main(String[] args) {
//获取数组的前五位
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
integers.stream().limit(5);
}
}
5、基于skip()实现数据跳过
案例:从集合第三个开始截取5个数据
public class LimitDemo {
public static void main(String[] args) {
//从集合第三个开始截取5个数据
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
List<Integer> collect = integers.stream().skip(3).limit(5).collect(Collectors.toList());
collect.forEach(integer -> System.out.print(integer+" "));
}
}
结果:4 4 5 5 6
案例:先从集合中截取5个元素,然后取后3个
public class LimitDemo {
public static void main(String[] args) {
//先从集合中截取5个元素,然后取后3个
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
List<Integer> collect = integers.stream().limit(5).skip(2).collect(Collectors.toList());
collect.forEach(integer -> System.out.print(integer+" "));
}
}
结果:3 4 4
6、映射
在对集合进行操作的时候,我们经常会从某些对象中选择性的提取某些元素的值,就像编写sql一样,指定获取表 中特定的数据列
#指定获取特定列 SELECT name FROM student
在Stream API中也提供了类似的方法,map()。它接收一个函数作为方法参数,这个函数会被应用到集合中每一个 元素上,并终将其映射为一个新的元素。 案例:获取所有学生的姓名,并形成一个新的集合
public class MapDemo {
public static void main(String[] args) {
//获取所有学生的姓名,并形成一个新的集合
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
List<String> collect = students.stream().map(Student::getName).collect(Collectors.toList());
collect.forEach(s -> System.out.print(s + " "));
}
}
结果:张三 李四 王五 赵六
7、基于anyMatch()判断条件至少匹配一个元素
anyMatch()主要用于判断流中是否至少存在一个符合条件的元素,它会返回一个boolean值,并且对于它的操作, 一般叫做短路求值
案例:判断集合中是否有年龄小于20的学生
public class AnyMatchDemo {
public static void main(String[] args) {
//判断集合中是否有年龄小于20的学生
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1,19,"张三","M",true));
students.add(new Student(1,18,"李四","M",false));
students.add(new Student(1,21,"王五","F",true));
students.add(new Student(1,20,"赵六","F",false));
if(students.stream().anyMatch(student -> student.getAge() < 20)){
System.out.println("集合中有年龄小于20的学生");
}else {
System.out.println("集合中没有年龄小于20的学生");
}
}
}
根据上述例子可以看到,当流中只要有一个符合条件的元素,则会立刻中止后续的操作,立即返回一个布尔值,无需遍历整个流
8、基于allMatch()判断条件是否匹配所有元素
allMatch()的工作原理与anyMatch()类似,但是anyMatch执行时,只要流中有一个元素符合条件就会返回true, 而allMatch会判断流中是否所有条件都符合条件,全部符合才会返回true
9、collect
Stream 流提供了一个 collect() 方法,可以收集流中的数据到【集合】或者【数组】中去。
10、concat
Stream流中常用的方法_concat:用于把流组合到一起
如果有两个流,希望合并成为一个流,则可以使用 Stream 接口的静态方法 concat :
五、Entry
Entry: 键值对 对象。
在Map类设计是,提供了一个嵌套接口(static修饰的接口):Entry。Entry将键值对的对应关系封装成了对象,即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
Entry为什么是静态的?
Entry是Map接口中提供的一个静态内部嵌套接口,修饰为静态可以通过类名调用。
Map集合遍历键值对的方式:
Set<Map.Entry<K,V>> entrySet();
//返回此映射中包含的映射关系的Set视图
该方法返回值是Set集合,里面装的是Entry接口类型,即将映射关系装入Set集合。
实现步骤:
1,调用Map集合中的entrySet()方法,将集合中的映射关系对象存储到Set集合中
2,迭代Set集合
3,获取Set集合的元素,是映射关系的对象
4,通过映射关系对象的方法,getKey()和getValue(),获取键值对
六、SQL语句增删改查
Select语句
1、select 语句
功能:SELECT 语句用于从数据库中选取数据,选取结果被存储在一个结果表中,称为结果集。
语法:可以用以下语句选择特定列名,或用*代替表示所有列。
SELECT column_name,column_name
FROM table_name;
2、 Select distinct 语句
功能:在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。distinct 关键词用于返回唯一不同的值。
语法:
SELECT DISTINCT column_name,column_name
FROM table_name;
3 、Select … where 语句
功能:SELECT语句用于从数据库中选取数据,WHERE子句用于提取那些满足指定条件的记录。而指定条件需要用到各种运算符。
语法:
SELECT column_name,column_name
FROM table_name
WHERE column_name operator value;
4 、Select … order by 语句
功能:SELECT语句用于从数据库中选取数据,用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列。默认为升序排列,如果要对某元素按降序排列则在对应关键字后添加参数DESC。
语法:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
5 、Select … group by 语句
功能:SELECT语句用于从数据库中选取数据, GROUP BY 语句用来对相同的数据进行分组。
语法:
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
6、 SELECT TOP 子句
功能:SELECT TOP 子句用于规定要返回的记录的数目。SELECT TOP 子句对于拥有数千条记录的大型表来说,是非常有用的。
注意:并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
7 、Select … join 语句
功能:JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
类型:
INNER JOIN:如果表中有至少一个匹配,则返回行;
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行;
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行;
FULL JOIN:只要其中一个表中存在匹配,则返回行。
https://blog.csdn.net/m0_64378913/article/details/123521016
insert into 语句
功能:用于向表中插入新记录,可以插入一行也可以同时插入多行。
语法:INSERT INTO 语句可以有两种编写形式。
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
update 语句
功能:用于更新表中已存在的记录。
语法:
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
注意:WHERE 子句规定哪条记录或者哪些记录需要更新。如果您省略了 WHERE 子句,所有的记录都将被更新!
delete 语句
功能:用于删除表中的行。
语法:
DELETE FROM table_name
WHERE some_column=some_value;
七、网络编程
1、通信协议
八、JAVA异常
1、什么是异常
在程序运行过程中出现的错误,称为异常。异常就是程序运行过程中出现了不正常现象导致程序的中断。在Java中,把各种异常现象进行了抽象形成了异常类。
2、异常的分类
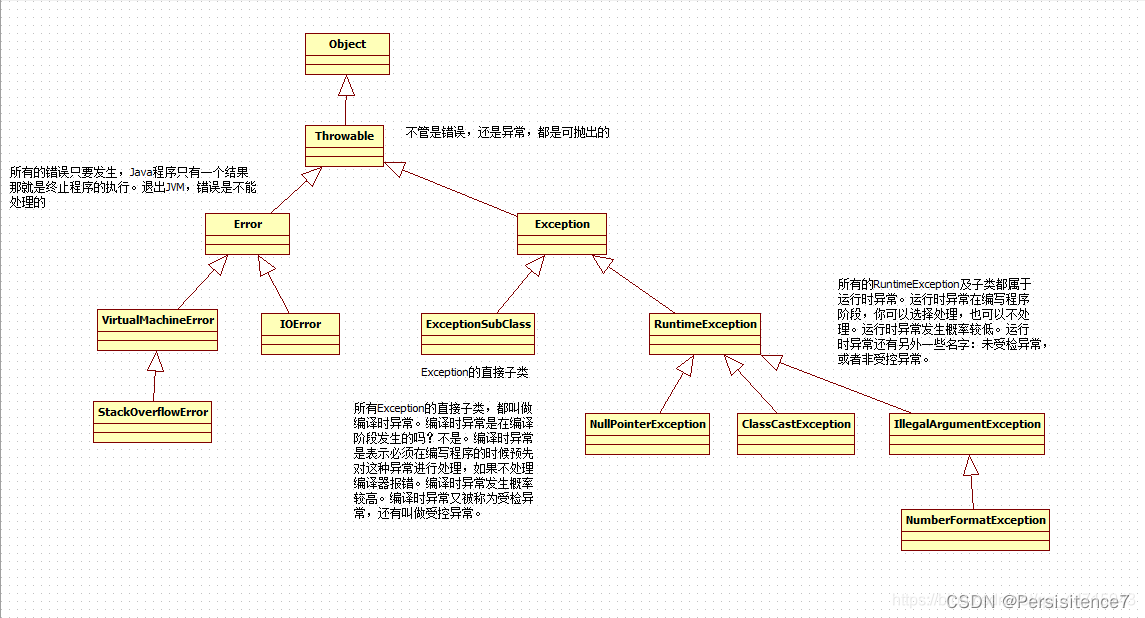
错误
如果应用程序出现了Error,那么将无法恢复,只能重新启动应用程序,最典型的Error的异常是:OutOfMemoryError
受控异常
这种异常属于一般性异常,出现了这种异常必须显示的处理,不显示处理java程序将无法编译通过。编译器强制普通异常必须try…catch处理,或用throws声明继续抛给上层调用方法处理,所以普通异常也称为checked异常。
非受控异常
非受控异常也即是运行时异常(RuntimeException),这种系统异常可以处理也可以不处理,所以编译器不强制用try…catch处理或用throws声明,所以系统异常也称为unchecked异常。
此种异常可以不用显示的处理,例如被0除异常,java没有要求我们一定要处理, 当出现这种异常时,肯定是程序员的问题,也就是说,健壮的程序一般不会出现这种系统异常。
3、异常的处理
异常捕获处理详细说明:
private static void testException2() {
try {
//1、对可能产生异常的代码进行检视
//2、如果try代码块的某条语句产生了异常, 就立即跳转到catch子句执行, try代码块后面的代码不再执行
//3、try代码块可能会有多个受检异常需要预处理, 可以通过多个catch子句分别捕获
} catch (异常类型1 e1) {
//捕获异常类型1的异常, 进行处理
//在开发阶段, 一般的处理方式要么获得异常信息, 要么打印异常栈跟踪信息(e1.printStackTrace())
//在部署后, 如果有异常, 一般把异常信息打印到日志文件中, 如:logger.error(e1.getMessage());
} catch (异常类型2 e1) {
//捕获异常类型2的异常, 进行处理
//如果捕获的异常类型有继承关系, 应该先捕获子异常再捕获父异常
//如果没有继承关系, catch子句没有先后顺序
} finally {
//不管是否产生了异常, finally子句总是会执行
//一般情况下, 会在finally子句中释放系统资源
}
}
【代码示例】
private static void testException3() {
int i1 = 100;
int i2 = 0;
//try里是可能出现异常的代码
try {
//当出现被0除异常时,程序流程会执行到“catch(ArithmeticException arithmeticException)”语句,这里是运行是异常,编译可以通过
//被0除表达式以下的语句永远不会执行
int i3 = i1 / i2;
//永远不会执行
System.out.println(i3);
//采用catch可以拦截异常
//arithmeticException代表了一个ArithmeticException类型的局部变量
//采用arithmeticException主要是来接收java异常体系给我们new的ArithmeticException对象
//采用arithmeticException可以拿到更详细的异常信息
} catch (ArithmeticException arithmeticException) {
System.out.println("被0除了");
arithmeticException.printStackTrace();
}
}
4、异常的捕获顺序
异常的捕获:一般按照由小到大的顺序,也就是先截获子异常,再截获父异常
以上代码分析:
将IOException放到前面,会出现编译问题,因为IOException是FileNotFoundException的父类,所以截获了IOException异常后,IOException的子异常都不会执行到,所以再次截获FileNotFoundException没有任何意义
异常的截获一般按照由小到大的顺序,也就是先截获子异常,再截获父异常。
5、正确的捕获方式:
try {
FileInputStream fis = new FileInputStream("test.txt");
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
这里只是为了说明捕获顺序,实际中,关闭流资源fis.close()是在finally语句块中处理的。
6、throw和throws
在定义方法时,如果方法体中有受检(编译时)异常需要预处理,可以捕获处理,也可以抛出处理。
处理异常时,使用throws抛出处理:
谁调用这个方法,谁负责处理该异常
在定义方法时,把异常抛出就是为了提醒方法的使用者,有异常需要预处理
在处理异常时,是选择捕获处理还是抛出处理
一般情况下,在调用其他方法时,如果被调用的方法有受检(编译时)异常需要预处理,选择捕获处理,因为你调用了方法, 你负责处理该异常。
在定义方法时,如果方法体中有受检异常需要预处理,可以选择捕获 ,也可以选择抛出处理。如果方法体中通过throw语句抛出了一个异常对象,所在的方法应该使用throws声明该异常。

throw
throw 语句用在方法体内,表示抛出异常,由方法体内的语句处理。
throw是具体向外抛出异常的动作,所以它抛出的是一个异常实例,执行throw一定是抛出了某种异常。
throw一般用于抛出自定义异常。
throws
throws语句是用在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理。
throws主要是声明这个方法会抛出某种类型的异常,让它的使用者要知道需要捕获的异常的类型。
throws表示出现异常的一种可能性,并不一定会发生这种异常。
7、获取异常对象的具体信息
getMessage()和printStackTrace()
如何取得异常对象的具体信息,常用的方法主要有两种:
获取异常描述信息
使用异常对象的getMessage()方法,通常用于打印日志时
取得异常的堆栈信息
使用异常对象的printStackTrace()方法,比较适合于程序调试阶段
8、自定义异常

骤
第一步:编写一个类继承 Exception 或者 RuntimeException.
第二步:提供两个 构造方法,一个无参数的,一个带有String参数的。
//栈操作异常:自定义异常!
public class StackOperationException extends Exception{ // 编译时异常!
public MyStackOperationException(){
}
public MyStackOperationException(String s){
super(s);
}
}
多线程
进程
进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
线程
线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
进程和线程的关系
线程是进程的一部分
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程
进程和线程的区别
理解它们的差别,我从资源使用的角度出发。(所谓的资源就是计算机里的中央处理器,内存,文件,网络等等)
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
开销方面:每个进程都有独立的代码和数据空间(程序上下文),进程之间切换开销大;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配:系统为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









