







一、索引的基本概念
数据库中文件系统的索引类似于书的目录,如果希望了解一本书的某个主题,可以通过目录中的该主题的关键词找到对应的页数,然后读取这些页,获取信息。数据库中的索引的工作原理是根据索引,查找相应记录所在的磁盘块,然后取出磁盘块,得到相应的记录。
总的来说,数据库的索引有两种基本类型:
1.
顺序索引。基于值的顺序排序(b+树也属于这个范畴)
2.
散列索引。将值平均分布到散列桶中。一个值所属的散列桶是根据散列函数来确定的。
关于索引,要清楚的相关概念:
1.
搜索码。用于在文件中查找记录的属性或者属性集。如果以个文件上有多个索引,那么它就有多个搜索码。一个文件可以有多个索引,分别基于不同的搜索码。
2.
聚集索引。如果包含记录的文件按照某个搜索码指定的顺序排列,那么该搜索码对应的索引称为聚集索引。聚集索引的搜索码常常是主码。
3.
非聚集索引。如果搜索码指定的顺序和文件中记录的物理顺序不同的,我们就将该索引称为非聚集索引。
二、B+树
索引顺序组织的文件最大的缺点在于,随着文件的增大,索引查找性能和数据顺序扫描性能都会下降,我们可以重组文件结构,但是我们不希望频繁地重组文件结构。
1、B+树的结构

B+树的结构可以由上图得到。可以将这个结构拆分成三个部分:叶节点,内部节点和根节点。
叶节点的结构如下图:

一般来说,每个节点用一个磁盘块来存储。叶节点有n-1个搜索码,有n个指针。指针Pi指向Ki对应的数据库中表的一条记录,Pn用于串接叶节点,形成一个链表结构。叶节点内部的搜索码是按照大小线性排序的。叶节点之间的搜索码大小也有个线性顺序。
叶节点包含值的个数最少为(n - 1)/2向上取整。
内部节点的结构和叶节点相同,但是有它自己的特点:
1、 Pi指向的子树,该子树包含的搜索码值小于Ki, 且大于等于Ki-1;
2、 Pm指向的子树所含的搜索码值大于等于Km-1的那一部分
3、 P1指向的子树小于K1的那一部分
4、 每个节点最多n个指针,最少n/2个指针向上取整。
根节点的指针数可以小于n/2向上取整,但是除非整棵树只有一个节点,否则根节点必须至少包含两个指针。
2、B+树的查询
假设在上一节的图中我们要查找Kim这个人,可以分三步进行:
1、 从根节点出发,查找最小的i是搜索码值Ki大于等于Kim, 在这个图里就是找到根节点的Mozart。因为Mozart前的指针指向的子树搜索码值小于Mozart,所以定位到Mozart左边的指针,到达内部节点。
2、 通过根节点的指针到达内部节点之后,该节点的所有搜索码都小于Kim,所以取最后的指针,到达叶节点。
3、在叶节点中搜索,找到了Kim,然后到对应的磁盘块上获取记录。
搜索码重复的情况:如果要查找所有叫Kim的人, 那应该找到第一个Kim的记录,然后在叶节点中依次向后检索得到所有相同搜索码的记录。
查找特定区间的情况:如果要查找工资区间在(5000,7000)之间的所有人,需要找到第一条工资5000的记录,然后再叶节点中依次检索,直到记录大于7000。
关于
B+树的插入和删除,会导致节点的分裂或者合并,这里就不多介绍了。
3、B+树的查询代价
B+树的查询路径长度可以用以下公式来表示:

其中n代表每个节点最多可以容纳的指针数,N代表搜索码的个数。一般来说,一个节点的大小就等于一个磁盘块的大小,通常为4KB, 假设搜索码值共有100万个,那么在n大约为100的情况下(也就是一个节点最多有100个指针99个搜索码),需要访问

3、散列文件组织和散列索引
1、基本概念
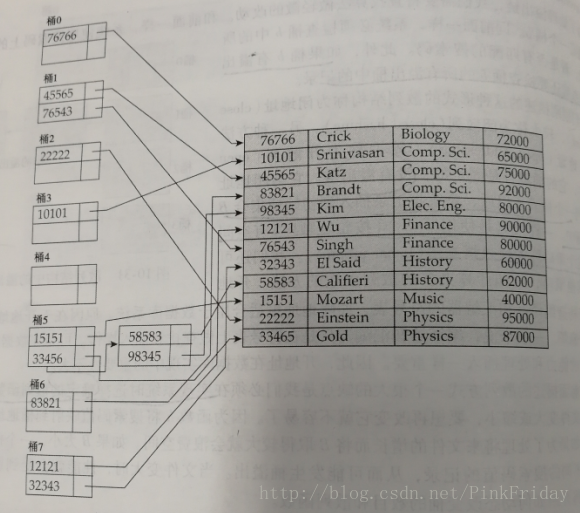
桶:能够存储一条或者多条记录的一个存储单位,通常一个桶就是一个磁盘块。
散列函数:令K表示所有搜索码的集合,B表示所有桶地址的集合,散列函数就是一个从K到B的函数,将每个搜索码映射到它所对应的桶之中。散列函数应该满足均匀性和随机性。
- 均匀性:散列函数从所有的搜索码值集合中为每个桶分配同样数量的搜索码值
- 随机性:不管搜索码值实际如何分布,每个桶应分配到的搜索码值数应该几乎相同。假设搜索码值是一个收入区间(1000元,9000元),我们将它分配4个区间(1000-3000),(3000-5000),(5000-7000), (7000-9000),假设(5000-7000)这个区间的收入人数最多,那么即使呈现出这种分布的情况,我们的四个桶里边的记录也应该大致相同,也就是不会根据原始数据的分布呈现出可见的规律。
散列文件组织:通过计算搜索码值上的散列函数直接获得包含该搜索码记录的磁盘块地址。
散列索引组织:通过计算搜索码值上的散列函数获得与它关联的指针。
2、桶溢出
如果不断地插入数据,桶就会没有空间,出现溢出的情况。一般桶溢出分两种情况,一种是桶不足,一种是桶偏斜,也就是有的桶满了,有的桶没有满。
处理桶溢出的方法:系统分配一个溢出桶,将插入的记录放在溢出桶中,然后将所有的溢出桶用链表链接起来。如果要查找记录的话,会查找这个链表中的所有桶中的记录。
3、散列索引
散列索引是将搜索码及其相应的指针组织成散列文件结构。
![]()















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









