






这个东西是个非常古老的算法了,大概是2008年的东西,参考资料也有很多,不过基本上都是重复的。最近受一个朋友的需求,前后大概用了二十多天时间去研究,也有所成果,在这里简单的予以记录。
图像修复这个东西目前流行的基本都是用深度学习来弄了,而且深度学习的效果还是非常不错的(大部分情况下优于传统算法)。
PatchMatch本身并不是图像修复的算法,他只是描述了一套流程用于快速在两幅图之间找到近似的相似的块,主要包括随机初始化,然后传播,再随机搜索三个步骤,关于这部分描述可以直接看论文或者在百度上搜索PatchMatch,有一大堆相关的解释,我这里不想过多描述。
关于这个论文,大家可以搜索文章: PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing
而图像修复本身的过程除了PatchMatch外,还有很多其他的东西。一般情况下,这种应用场景都是客户手工指定一个区域,我们需要把这个区域的东西去掉并填充(不管原来这里是什么样子的,区域内部原有的信息完全不考虑),填充后的结果要和周边的环境自然的融为一体。关于这方面的步骤,论文里本身描述的不多,但是相关的代码可以在github上找到很多,我这里提供几个链接供大家参考:
https://github.com/vacancy/PyPatchMatch
https://github.com/liqing7/Inpaint/tree/master/Inpaint
github里一堆这样的代码,但是翻来翻去其实都是一个娘生的,里面的实现方式大同小异,而且基本上都是基于opencv实现的,里面的代码呢也是绕来绕去,重实现,不重流程和效率。我的工程也是参考了这些东西,并且使用C++脱离opencv独立予以实现,因此工作量大了很多。
我这里就我在提取并稍作优化这个算法的一些过程予以记录和描述,免得时间久了后自己都不太记得是怎么回事了。
一、Inpaint的基本流程。
1、用户标记的区域视为孔洞,里面没有任何的信息了,那要从现有的周边像素填充这个孔洞,采用的办法是,建立图像金字塔,在金字塔下采样的过程中,图像变小,孔洞也在变小,下采样就涉及到领域,当领域覆盖了孔洞边缘时,也必然有部分领域涉及到了孔洞周边的有效像素区域,此时以有效像素区域的信息加权填充缩小后的孔洞,这样不断的侵蚀,直到所有的孔洞在金字塔图像中都消失了,这个金字塔的层数就足够了(不管孔洞有多大,当金字塔在变为大小2像素、1像素的过程中孔洞肯定会消失)。
2、由最小的金字塔层开始,目标和源都设置为相同值,然后随机初始化PatchMatch里的NNF场,接着使用传播和随机扩散最小化NNF的误差,这个时候就可以利用这个NNF来初步构建目标图像(是个迭代过程,叫做EM迭代)。
3、在迭代的最后一步,做个上采样,并且做点精细化的工作(权重累加),然后到金字塔的上一层,在这一层时,初始的NNF就不要随机化了,而是可以有下一层的NNF通过最近邻插值获取,这样获取的数据比随机初始化的要更为接近理论的结果,就要就可以减少这一层的传播和随机扩散的迭代次数。
4、就这样一层一层的往上处理,得到最终的结果。
二、参考代码中一些细节
1、删除不必要的过程
我们贴一下论文里的一些描述先:
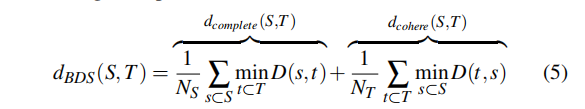
void init_kDistance2Similarity() {
double base[11] = {1.0, 0.99, 0.96, 0.83, 0.38, 0.11, 0.02, 0.005, 0.0006, 0.0001, 0};
int length = (PatchDistanceMetric::kDistanceScale + 1);
kDistance2Similarity.resize(length);
for (int i = 0; i < length; ++i)
{
double t = (double) i / length;
int j = (int) (100 * t);
int k = j + 1;
double vj = (j < 11) ? base[j] : 0;
double vk = (k < 11) ? base[k] : 0;
kDistance2Similarity[i] = 1;// vj + (100 * t - j) * (vk - vj);
}
}
这个函数的目的是根据两个块之间的距离来计算一个在[0,1]之间的相似权重。但是这个函数设计的不是很好,代码里块之间的距离是一个介于0和65535之间的数,这个权重也是个65536的表,但是问题是,这个表在后段大部分的值全为0,就表示他们毫无贡献了,这个可能造成的一个问题时图像出现莫名其妙的内容,而且如果遇到加权时的像素点权重都是0,这个点的计算就无效了。因此,需要适当的修改这个函数。
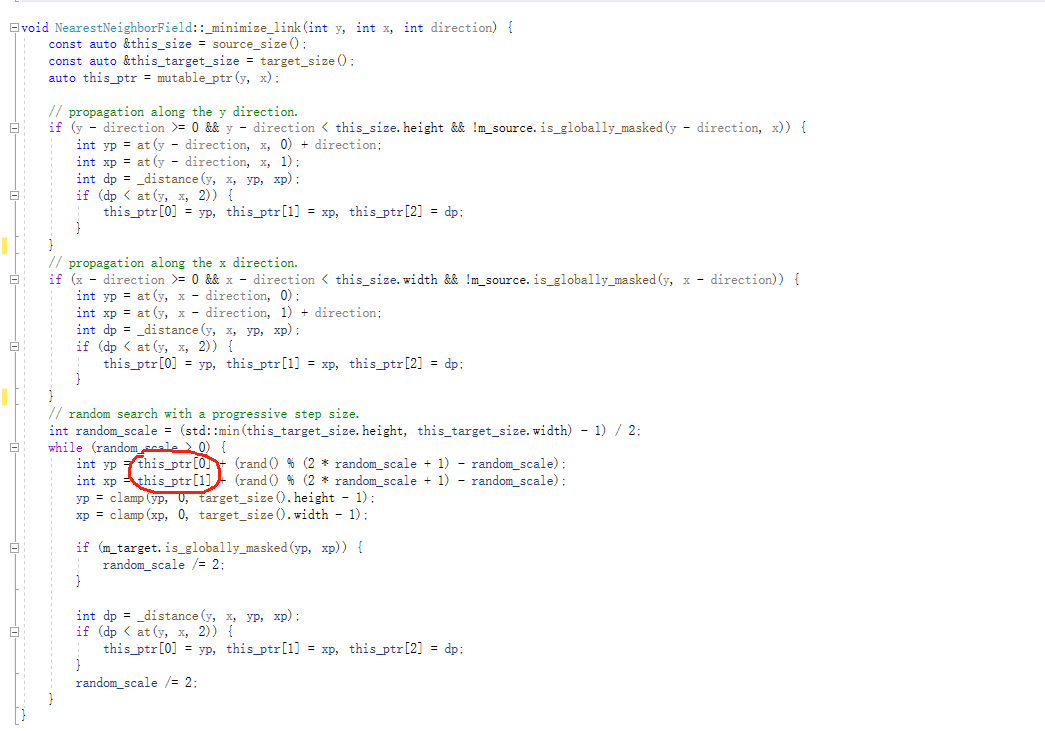
b、在NNF的minimize过程中,特别是随机扩散的代码里,上面我给出的链接里用了两种不同的方法,
其中一种是:
另外一个是:
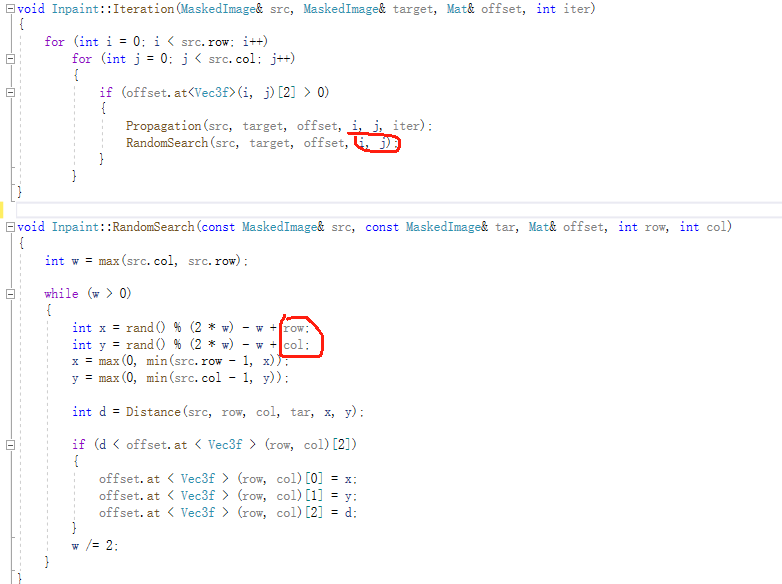
两者的不同是,一个在随机搜索的时候的中心点是经过传播后得到更优的点,一个就是原始的中心点, 我这边测试呢使用原始的中心点得到的图形的清晰度更高,不知道这个是个什么道理。
3、一些其他的细节的理解
a、在参考代码里,对于距离的计算,除了常规的欧式距离外,有些版本还加入了对于边缘的权重的考量,比如下面的代码:
mptry[j] = (ptry1[j] / 2 - ptry2[j] / 2) + 128;
mptrx[j] = (ptrx1[j] / 2 - ptrx2[j] / 2) + 128;
这是简单的计算水平和垂直方向的梯度,而且这个公式的设计让他们的值自然的位于0和255之间,这样就能起到和像素的RGB在同一个有效的值范围和空间内,使得他们的权重自然就相同了。
b、对于块的大小,感觉大部分情况半径为2就比较合适,也就是计算5*5的领域,一般就能满足范围。
c、在下采样时,这个函数还是比较关键,不太能用向双线性插值这种只涉及到2*2领域的算法,参考代码给出的时一个6*6的领域,为什么用偶数领域,这个是基于什么考虑呢(其实常用的图像缩放算法都是偶数范围内领域,双向性是2*2, 三次立方是4*4),我采用的是5*5的领域,感觉这样比较集中。
d、参考代码里的下采样图的大小都是 SrcW / 2这种的,这种如果原图是51像素,则下一层就只有25个像素了,我个人感觉还是不合理,而是应该采用(SrcW + 1) / 2这种方式处理,而且我测试呢,如果采用SrcW / 2方式,对于图像宽度和高度是偶数的图,出来的结果就是模糊一些(这个东西和很多因素有关,但是我测试的环境确实有这个现象)。
e、虽然作者说patchmatch很快就会收敛,但是毕竟他只是近似算法,不是完全的准确,因此,每次执行后的结果都不他一样,所以实用的还是需要多点几次看那次结果更为合适)。
f、早期的photoshop里有一个智能填充,其实现方式和patchmatch也是类似的。
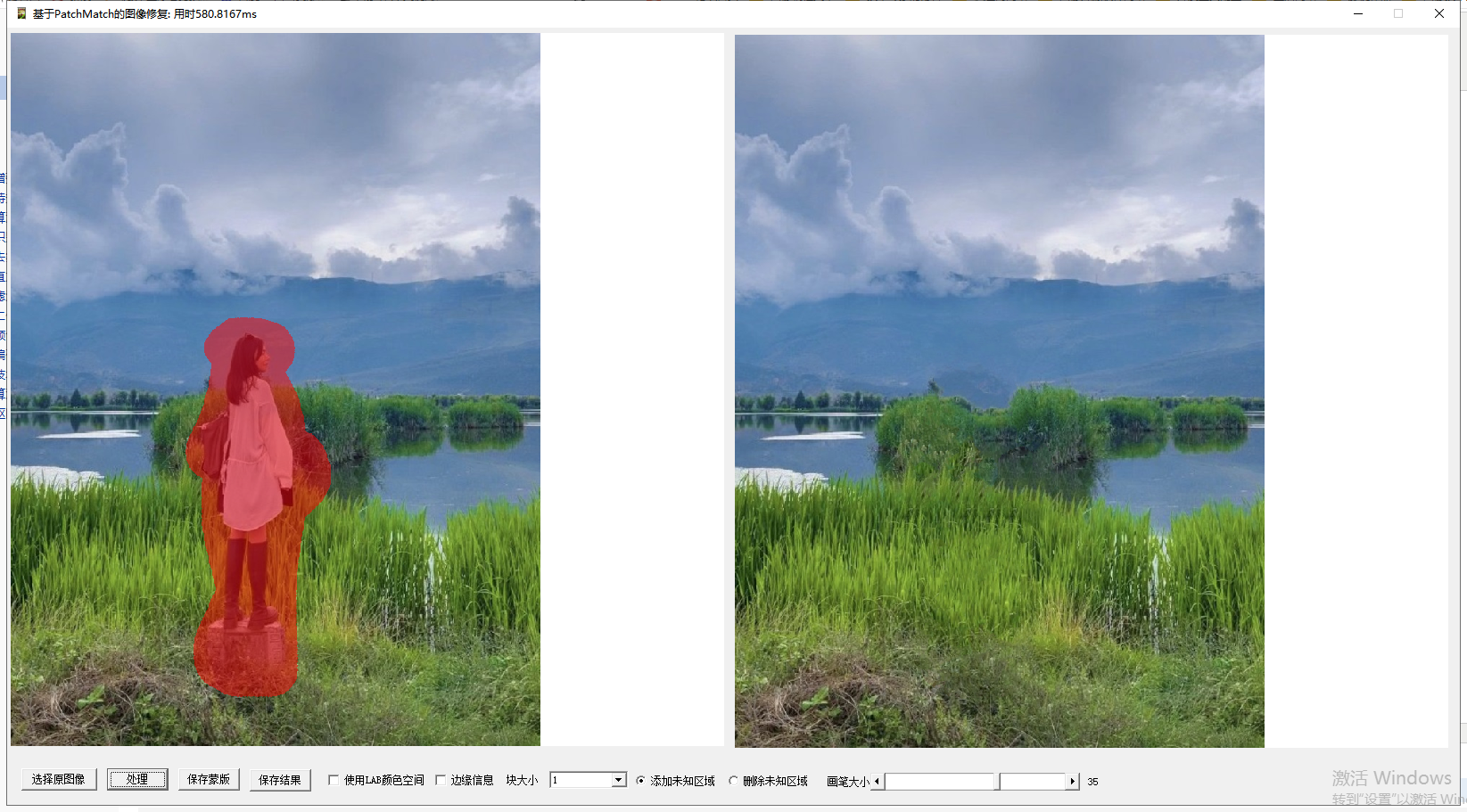
三、实测的效果
经过多个版本迭代,目前已经实现了一个简单的测试DEMO,这里选几个效果比较明显的看一下:




对于没有强烈边界的区域,可以看出整体还是不错的,不够目前的效果还是有些模糊,当然也有一些不太成功的案例。
目前我在美图秀秀和Photoshop中都有看到类似这样的功能,美图秀秀里有个智能抠图,应该是使用AI做的,大部分情况下都不错,不过对于刚才那个油菜花的图就有点失效了,如下图所示:
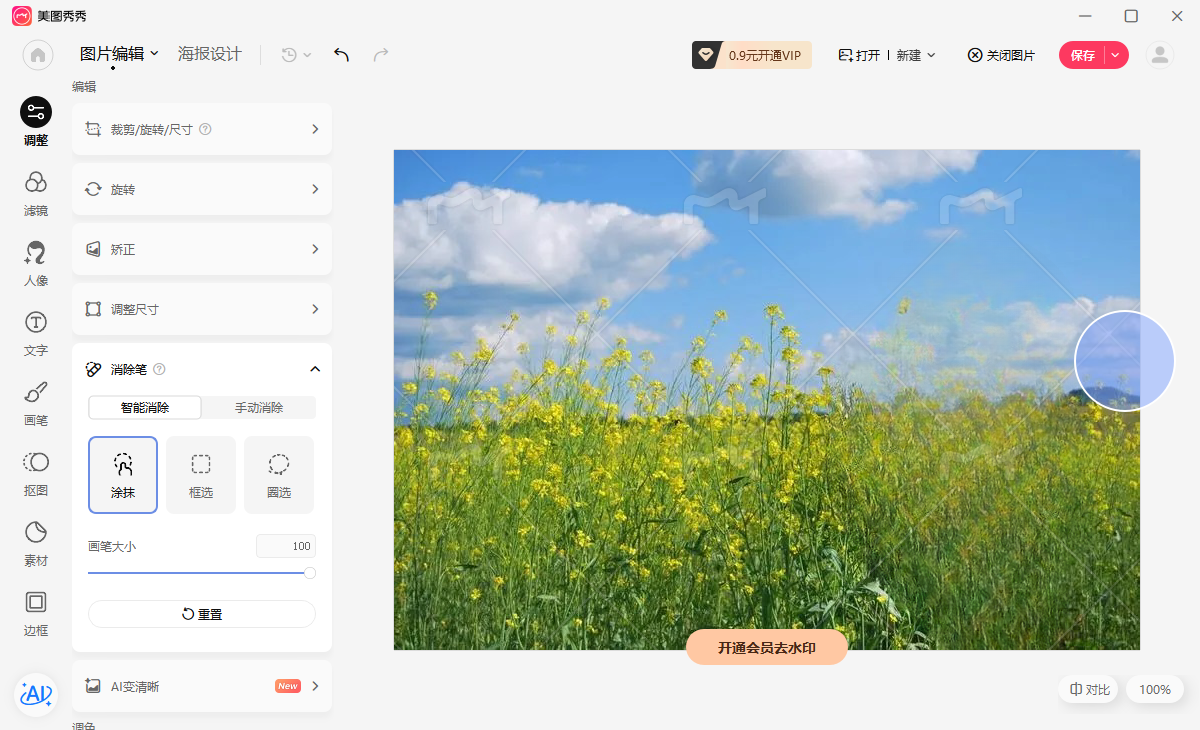
不晓得是他的模型问题,还是这个AI本身就做不太好。
我提供一个测试DMEO,有兴趣的朋友可以弄着玩:https://files.cnblogs.com/files/Imageshop/PatchMatch.rar?t=1724314207&download=true
如果想时刻关注本人的最新文章,也可关注公众号:

翻译
搜索
复制















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









