






传统的基于边缘信息的模板匹配其计算得分的公式如下所示:


这是一个累加公式,对于原图的每一个有效像素位置,以其为中心或左上角起点(图像中的坐标一般是X方向从左向右,Y方向从上到下),在原图中覆盖模板宽度和高度大小的范围内,按照模板有效特征点的位置和梯度信息,逐点和原图对应位置的梯度信息进行上述累加符号内的计算,在进行完累加后,再次求平均值得到有效像素位置的实际得分。
我们抛开累加的过程,单独看看逐点的计算式。
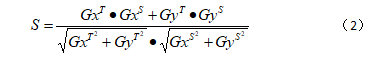
为了表述和绘图方便,我们把上述公式用下面的符号简化下:
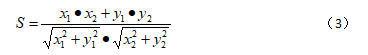
即x1和y1模板图的X和Y方向x2和y2梯度,x2和y2原图对应的X和Y方向梯度。
我们把x1、y1、x2、y2绘制到一个二维平面图中,如下图所示:
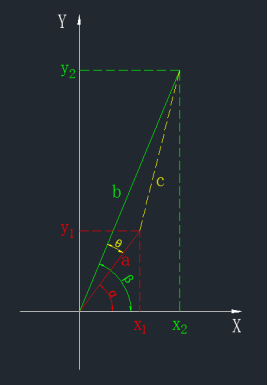
上述图中,红色线条表示x1和y1对应的向量,其长度用a表示,绿色线条表示x2和y2对应的向量,其长度用b表示。两个向量之间的夹角用θ表示。
另外,α表示红色向量和X轴之间的夹角,β表示绿色向量和Y轴之间的夹角。c表示红色和绿色向量终点之间的长度。
根据数学中的余弦定理,a、b、c以及θ之间有如下关系:
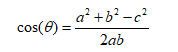
再根据勾股定理,我们进一步展开有:
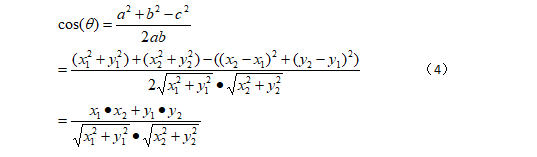
比较公式(4)和公式(3),我们可以看到两者的结果完全相同,因此,求每个点的得分也等同于求对应的梯度向量的夹角余弦。
注意到,要获取θ,我们可以先获得α和β值,然后通过
Θ = β - α
获取,而α和β可以使用atan2函数获取。
通常,模板的信息都是离线计算的,因此,每个特征点的α(模板)值可以提前计算。但是β值需要通过类似于atan2之类的函数实时计算。
得到Θ值后,可以直接使用cos函数计算余弦值,即得到该点的得分。
实际上,无论是atan2函数也好,还是cos函数也好,其内部都是由很多浮点指令组合而成的,非常耗时,不利于程序的实现和效果。
这里提出一个加速的方案,我们称之为十六角度量化的夹角余弦匹配,她的核心还是基于信息论中的香农采样定理。
我们先说一个简单的事情。
在我们的匹配过程中,总得分是由m个特征点各自得分累加后求平均值获取的,因此,如果各自的得分有小幅度的偏差,对总得分的影响应该很小,这样,我们可以先这样想,如果我们把0到360角度分为360等份(cos是以360度一个周期震动的函数),即每等份的差距是1度,然后在计算α和β时,也把得到的角度四舍五入到最接近的等份,这样,我们可以提前建立起一个360*360的查找表,输入α和β的值,就能查到对应cos值了。
这种查表的精度其实还是相当高的,但是这个表太大,查表时的cachemiss相对来说有点严重。
当我们以22.5度为每等份的差距时,可以把360度量化为16等份,此时,对应的表只有16*16=256个元素,查表的效率就非常高了,不过精度损失相对来说就严重一些,但是,实际的验证表面这种损失对匹配的结果影响是完全在可接受范围内的。

这个构成相当于把0到22.5度的向量就直接标记为索引0,22.5到45之间的角度标为1,45到67.5之间的角度标为2,67.5到90度之间的角度标为3,依次类推。
以22.5为间距进行标记的过程的另外一个优势是,可以不用先使用耗时的atan2函数得到角度后再来计算索引值,而是可以根据有关x1和y1(图像数据中x1和y1通常是整数)的数值关系做直接的判断,这种判断也是整形的计算,效率相对来说比较高,具体的可以再代码里看到。
那么表格是如何建立的呢,比如α对应的索引是2,β对应的索引是4,那么表中的内容是什么呢?这个也很简单,就是直接使用
cos(4 * 22.5 - 2 * 22.5) = 0.707117987607051 得到。
为了进一步提高速度,尽量减少浮点的计算,我们可以把这个表的得分设计为整形值,比如将表的得分统一乘以一个较大的整数,而后舍去成绩得到的小数部分,仅仅保留整数部分,这样表格数据就可以完全用整数来表示了,这个时候,只需要在最后计算得分的时候统一除以刚刚放大的整数就可以了,比如刚才的浮点就可以用下面的整数代替:
0.707117987607051 * 63 = 44.5484332192442 四舍五入取整45。
再仔细的考虑下,刚刚建立的是二维表,实际上,这个过程还可以使用一维表进行,因为如果把0到360度角度量化为16个等份,那么模版和原图匹配时的不同的角度差异值只会有31种可能(-15、-14、-13..........0、1、2.......13、14、15),每种取值都有固定的得分,因此,只需要构建一个31个元素的表格,然后根据差异的索引在查表就可以了。注意考虑到索引必须为正值,这个差异的索引应该等于β - α+15。、
使用一维表的方案还可以进一步进行推广。因为二维表必须考虑表的维度,他和量化的等份数成平方关系,太大了这个表的元素太多,一方面占用内存,另外还存在较为严重的cachemiss,但是如果仅仅是一维表,则这方面的顾虑就少了很多,比如我们就以1度为划分间隔,把0到360度划分为360份,这样需要的一维表的大小为719个元素,这个大小无论从内存还是cachemiss角度来考虑都是可以接受的。这样做带来的好处就是计算出的每个位置的得分值和真正的得分是更为接近的。
当然,具体使用多少个等份量化,还和其他一些因素有关,比如使用8/16/32角度量化,在PC上可以使用某些特殊指令集加速查表的过程,而其他的角度则不行。使用二维表有的时候更易处理一些特殊情况,比如原图中不需要参与匹配的一些特殊点。而使用一维表可能需要使用分支语句处理,从来带来性能损伤。
关于余弦相似性,正好昨天博客园也有一篇文章有涉及,大家可以参考下:十分钟搞懂机器学习中的余弦相似性
如果想时刻关注本人的最新文章,也可关注公众号:

翻译
搜索
复制















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









