







专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
即插即用,LUT性能增强模块-RCLUT(2023,ICCV)
本文将从头开始对RCLUT: Reconstructed Convolution Module Based Look-Up Tables for Efficient Image
Super-Resolution,这篇轻量超分算法进行讲解。参考资料如下:
[1]. RCLUT论文地址
[2]. RCLUT代码地址
一、研究背景
RCLUT提出的原因在于:LUT方法按照串并联LUT的思路在scaling law上的效率比较低,需要大量的存储量或计算量才可以增大一点感受野RF,为了更高效率的提升感受野,作者提出了一个RC模块,中文名为重构卷积,重构卷积可以使用极小的代价来大幅提升RF,作者利用这个RC模块集成到前面讲到的SRLUT,MuLUT上均有PSNR和主观效果的提升。
二、RCLUT方法
RCLUT也是一个带串并联的LUT结构,如下图所示。

第一个stage会使用3x3、5x5、7x7的RC模块处理,后续使用各种类型的Conv Block处理后相加并平均,第二个stage是stack了一个相同的结构,得到最终结果。
2.1 RC模块
下图是RC模块的示意图。

可以看到一个(N,N)的窗口中,使用一个FC将通道进行升维,处理后变成了(N,N,C)的tensor,之后再使用一个FC通道进行降维,变成1通道回到原始NXN的一个窗口,最终使用一个avg_pool,得到RC module的结果,可以看到通过一个avg_pool和N*N个1D LUT得到了NxN的感受野。作者将这个过程用公式表示:
z
(
m
+
i
,
m
+
j
)
=
W
i
j
′
T
(
W
i
j
T
x
(
m
+
i
,
n
+
j
)
+
b
i
j
)
+
b
i
j
′
y
m
n
=
1
N
2
∑
i
=
0
N
−
1
∑
j
=
0
N
−
1
z
(
m
+
i
,
m
+
j
)
.
\begin{aligned} z_{(m+i, m+j)} & =W_{i j}^{\prime T}\left(W_{i j}^{T} x_{(m+i, n+j)}+b_{i j}\right)+b_{i j}^{\prime} \\ y_{m n} & =\frac{1}{N^{2}} \sum_{i=0}^{N-1} \sum_{j=0}^{N-1} z_{(m+i, m+j)} . \end{aligned}
z(m+i,m+j)ymn=Wij′T(WijTx(m+i,n+j)+bij)+bij′=N21i=0∑N−1j=0∑N−1z(m+i,m+j).
第一个公式中
m
m
m和
n
n
n是当前该计算特征图的坐标,
i
i
i,
j
j
j是大小为NxN窗口内的索引,
W
i
j
T
W_{i j}^{T}
WijT和
b
i
j
b_{i j}
bij是第一个FC的权重,
W
i
j
′
T
W_{i j}^{\prime T}
Wij′T和
b
i
j
′
b_{i j}^{\prime}
bij′是第二个FC的权重,第二个公式则是一个avg_pooling,将上面求的各个结果进行一个平均,这里有一个疑问是
z
(
m
+
i
,
m
+
j
)
z_{(m+i, m+j)}
z(m+i,m+j)的下标,均是
m
m
m,不确定是不是公式错误,看代码之后,博主本人认为是写错了,应该是
z
(
m
+
i
,
n
+
j
)
z_{(m+i, n+j)}
z(m+i,n+j),有不同理解的朋友可以讨论。
当然,这两个FC计算的过程可以用LUT表来进行替换,因此替换后的计算公式可以用下式表示。
V
′
=
1
N
2
∑
i
=
0
N
2
−
1
(
L
U
T
i
[
I
i
]
)
\mathbf{V}^{\prime}=\frac{1}{N^{2}} \sum_{i=0}^{N^{2}-1}\left(L U T_{i}\left[I_{i}\right]\right)
V′=N21i=0∑N2−1(LUTi[Ii])
这里的N与上面一样,代表窗口大小,
L
U
T
i
LUT_i
LUTi则是这NxN个中其中一个,通过查询当前的输入可以得到结果,因此这里作者用的是一个1D LUT,总的1D LUT尺寸是
2
8
∗
N
2
2^{8}*N^{2}
28∗N2。
2.2 Conv模块
在RCLUT的总结构中,我们还可以看到有Conv Block4-1、Conv Block4-4以及Conv Block1-4,如下图所示。
可以看到Conv Block4-1其实就是一个2x2,输出为1个,Conv Block 4-4则是2x2的kernel_size,搭配输出为4个,Conv Block1-4是输入为1个,输出为4个。
以上两个模块的排列组合就可以构成最后的RCLUT了。
2.3 感受野大小的讨论
这里假设RCLUT在2个stage上的RC模块感受野分别是
N
1
/
N
2
N_1/N_2
N1/N2,Conv Block分别是
M
1
/
M
2
M_1/M_2
M1/M2,带有旋转的情况下,RCLUT的感受野可以得到:
R
F
1
=
2
(
M
1
+
N
1
−
1
)
RF_1=2(M_1+N_1 - 1)
RF1=2(M1+N1−1)
R
F
2
=
2
(
(
R
F
1
−
1
)
/
2
+
M
2
+
N
2
−
1
)
−
1
=
2
M
1
+
2
M
2
+
2
N
1
+
2
N
2
−
7
RF_2=2((RF_1-1)/2+M_2 + N_2 - 1)-1=2M_1+2M_2+2N_1+2N_2-7
RF2=2((RF1−1)/2+M2+N2−1)−1=2M1+2M2+2N1+2N2−7
对于MuLUT来说,则是:
R
F
2
′
=
2
(
(
(
2
M
1
−
1
)
−
1
)
/
2
+
M
2
−
1
)
−
1
=
2
M
1
+
2
M
2
−
3
RF_2'=2(((2M_1-1)-1)/2+M_2 - 1)-1=2M_1+2M_2-3
RF2′=2(((2M1−1)−1)/2+M2−1)−1=2M1+2M2−3
对于RCLUT来说
N
1
/
N
2
N_1/N_2
N1/N2以及
M
1
/
M
2
M_1/M_2
M1/M2分别是7,7,2,1,因此可以计算出感受野分别是27x27,对于MuLUT来说
M
1
/
M
2
M_1/M_2
M1/M2分别是2,2,因此可以计算出感受野分别是9x9。
三、实验结果
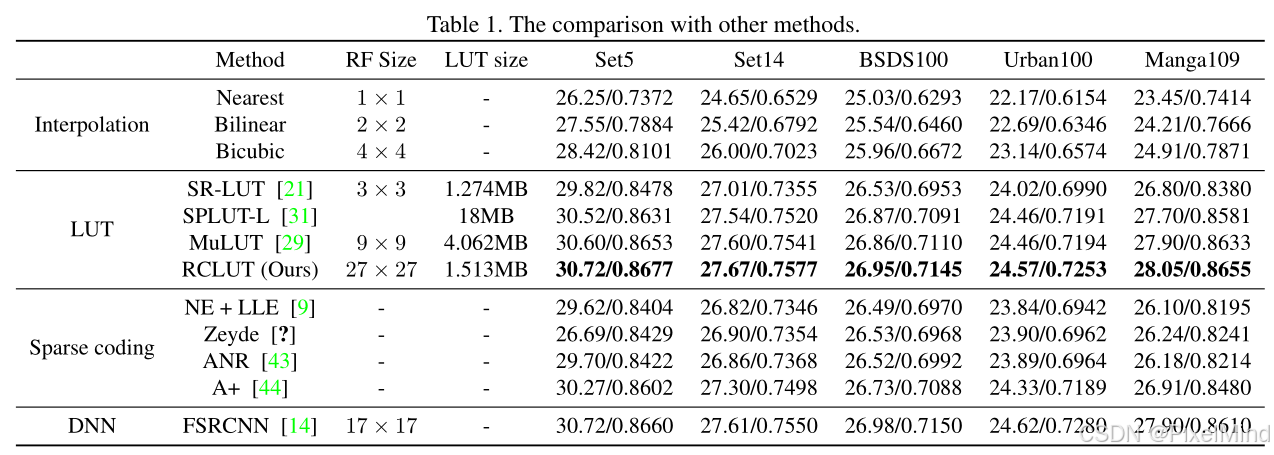
定量的实验结果显示:RCLUT以极低的LUT Size和高的RF,超过了当时最先进MuLUT的效果。
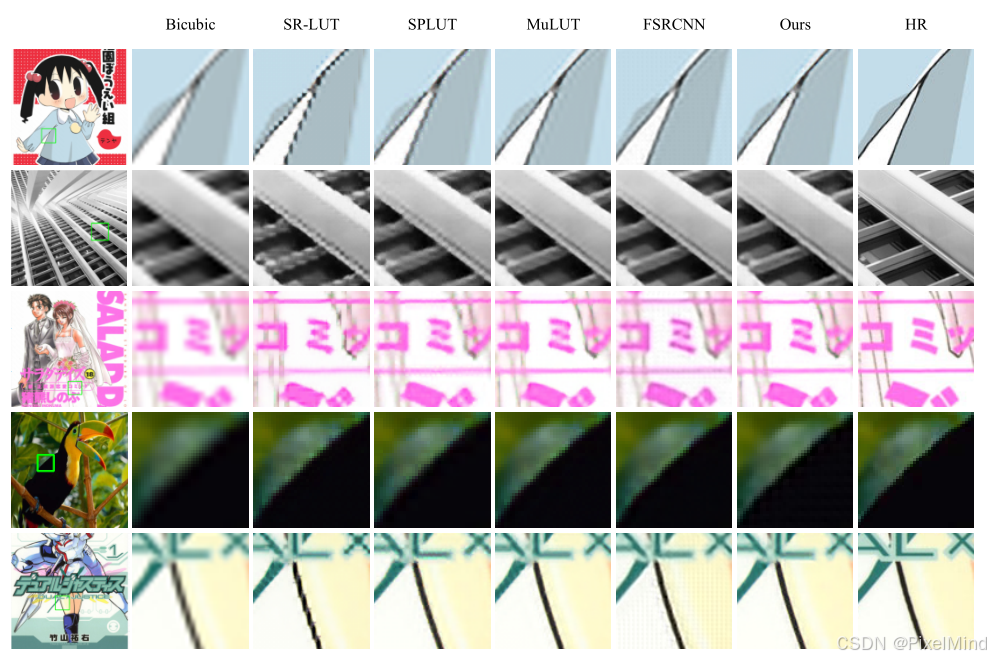
定性的实验结果显示,该方法还是比传统插值要更好,比FSRCNN初期的DNN的方法要更好,比专栏前面讲到的各种LUT方法都要好。
接下来作者进行了消融实验:
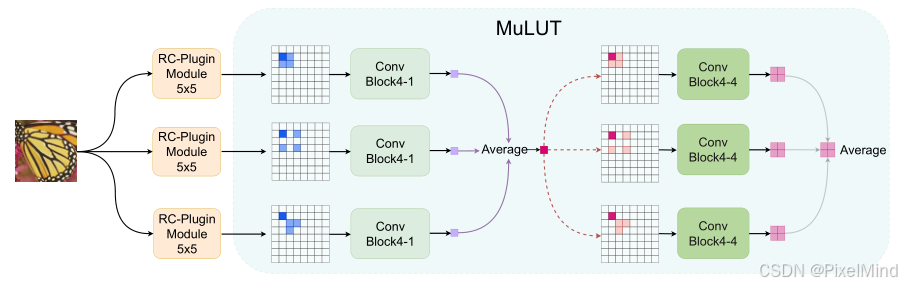
1)RC模块作为插件插入到MULUT中:

加入RC-5对于MuLUT来说提升是明显的,但是增加的存储量很小,1.245kB,这里的计算是通过以下的图。
前面我们讲过了一个RC模块的大小是
2
8
∗
N
2
2^{8}*N^{2}
28∗N2,这是在量化系数为1时,如果我们选用间隔为16,则大小在RC5上可以进一步减小到
17
∗
5
2
=
0.415
k
b
17*5^{2}=0.415kb
17∗52=0.415kb,则三个就是1.245kb。
2)RC模块中的实现,对于FC层的重要性检验:
 这里可以看到如果直接去做Avg池化,RF的理论大小也是OK的,但是效果上会存在一个骤降,因此RC模块是重要的,当然Conv Block的模块加了肯定也是效果会更好的,尤其是使用4-4的设置时。
这里可以看到如果直接去做Avg池化,RF的理论大小也是OK的,但是效果上会存在一个骤降,因此RC模块是重要的,当然Conv Block的模块加了肯定也是效果会更好的,尤其是使用4-4的设置时。
3)RC模块加入到SRLUT中:

RC模块对于SRLUT时有明显效果提升的,同时对于存储量的增强很少,但是RC模块增大的收益有限。
4)RCLUT分支的测试,RCLUT-3_5指,RC模块3紧跟着RC模块5,后面同理:

效果上是堆叠越多效果越好,最后一行是作者使用到的一个结构,对于第5行,可以看到深度对于宽度来说很重要。
5)耗时的测试:

增加的不多,是一个非常有效,即插即用的模块。
四、总结
- RCLUT提出了一个RC模块来提升网络的感受野,用了极小的代价提升了原始MULUT和SRLUT的一个效果。
- RCLUT的理论感受野已经提升至27x27,比MULUT、和SPLUT提升不少,但实际效果的提升有限,毕竟用于提升感受野的算子还是avg池化。
代码部分将会单起一篇进行解读。(未完待续)
感谢阅读,欢迎留言或私信,一起探讨和交流。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









