







在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dwd层依旧回写到kafka中。
1.分流维度表sink到hbase
上一篇的结果是维度数据在侧输出流hbaseDs,事实数据在主流filterDs中,如下:
//5.动态分流,事实表写会kafka,维度表写入hbase
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(TableProcess.SINK_TYPE_HBASE){};
//创建自定义mapFunction函数
SingleOutputStreamOperator<JSONObject> kafkaTag = filterDs.process(new TableProcessFunction(hbaseTag));
DataStream<JSONObject> hbaseDs = kafkaTag.getSideOutput(hbaseTag);
filterDs.print("json str --->>");
处理流程如下:
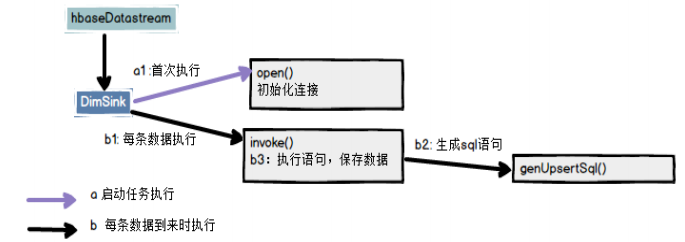
自定义RickSinkFunction类:DimSink.java
- 初始化phoenix连接
- 保存数据
1.1 配置
在BaseDbTask任务中,我们已经获取到hbase的输出流,然后就可以开始hbase的一系列操作了。
添加phoenix依赖包
<!-- phoenix -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
修改hbase-site.xml,因为要用单独的 schema,所以在 Idea 程序中也要加入 hbase-site.xml
为了开启 hbase 的 namespace 和 phoenix 的 schema 的映射,在程序中需要加这个配置文件,另外在 linux 服务上,也需要在 hbase 以及 phoenix 的 hbase-site.xml 配置文件中,加上以上两个配置,并使用 xsync 进行同步。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
</property>
<property>
<name>hbase.table.sanity.checks</name>
<value>false</value>
</property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>
1.2 创建命名空间
在phoenix中执行
create schema GMALL_REALTIME;
1.3 DimSink.java
自定义addSink类
package com.zhangbao.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Strings;
import com.zhangbao.gmall.realtime.common.GmallConfig;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* @author: zhangbao
* @date: 2021/9/4 12:23
* @desc: 将维度表写入hbase中
**/
@Log4j2
public class DimSink extends RichSinkFunction<JSONObject> {
private Connection conn = null;
@Override
public void open(Configuration parameters) throws Exception {
log.info("建立 phoenix 连接...");
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
log.info("phoenix 连接成功!");
}
@Override
public void invoke(JSONObject jsonObject, Context context) throws Exception {
String sinkTable = jsonObject.getString("sink_table");
JSONObject data = jsonObject.getJSONObject("data");
PreparedStatement ps = null;
if(data!=null && data.size()>0){
try {
//生成phoenix的upsert语句,这个包含insert和update操作
String sql = generateUpsert(data,sinkTable.toUpperCase());
log.info("开始执行 phoenix sql -->{}",sql);
ps = conn.prepareStatement(sql);
ps.executeUpdate();
conn.commit();
log.info("执行 phoenix sql 成功");
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("执行 phoenix sql 失败!");
}finally {
if(ps!=null){
ps.close();
}
}
}
}
//生成 upsert sql
private String generateUpsert(JSONObject data, String sinkTable) {
StringBuilder sql = new StringBuilder();
//upsert into scheme.table(id,name) values('11','22')
sql.append("upsert into "+GmallConfig.HBASE_SCHEMA+"."+sinkTable+"(");
//拼接列名
sql.append(StringUtils.join(data.keySet(),",")).append(")");
//填充值
sql.append("values('"+ StringUtils.join(data.values(),"','")+"')");
return sql.toString();
}
}
然后在主程序中加入
//6. 将维度表写入hbase中
hbaseDs.addSink(new DimSink());
1.4 测试
-
需要启动的服务
hdfs、zk、kafka、Maxwell、hbase,BaseDbTask.java
-
修改配置数据:gmall2021_realtime.table_process
INSERT INTO `gmall2021_realtime`.`table_process` (`source_table`, `operate_type`, `sink_type`, `sink_table`, `sink_columns`, `sink_pk`, `sink_extend`) VALUES ('base_trademark', 'insert', 'hbase', 'dim_base_trademark', 'id,tm_name', 'id', NULL);此条配置数据代表,如果表base_trademark有插入数据,就把数据同步到hbase中,自动建表,作为维度数据。
-
修改业务库中表数据:gmall2021.base_trademark
INSERT INTO `gmall2021`.`base_trademark` (`id`, `tm_name`, `logo_url`) VALUES ('15', '55', '55'); -
查看phoenix数据:
select * from GMALL_REALTIME.BASE_TRADEMARK;
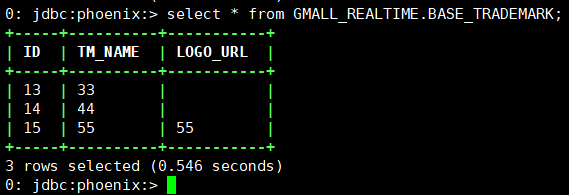
数据已经实时同步到hbase中。
2.分流事实表sink到kafka
2.1 MyKafkaUtil定义新方法
在MyKafkaUtil中定义新的生产者方法,可动态指定topic,如果不指定则生产到默认topic:default_data
/**
* 动态生产到不同的topic,如果不传topic,则自动生产到默认的topic
* @param T 序列化后的数据,可指定topic
*/
public static <T> FlinkKafkaProducer<T> getKafkaBySchema(KafkaSerializationSchema<T> T){
Properties pros = new Properties();
pros.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,KAFKA_HOST);
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC,T,pros,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
在主任务BaseDbTask中使用
//7. 将事实数据写回到kafka
FlinkKafkaProducer<JSONObject> kafkaBySchema = MyKafkaUtil.getKafkaBySchema(new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka serialize open");
}
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
String sinkTopic = jsonObject.getString("sink_table");
return new ProducerRecord<>(sinkTopic, jsonObject.getJSONObject("data").toString().getBytes());
}
});
kafkaTag.addSink(kafkaBySchema);
2.2 测试
-
需要启动的服务
hdfs、zk、kafka、Maxwell、hbase,BaseDbTask.java
-
修改配置信息:gmall2021_realtime.table_process
INSERT INTO `gmall2021_realtime`.`table_process` (`source_table`, `operate_type`, `sink_type`, `sink_table`, `sink_columns`, `sink_pk`, `sink_extend`) VALUES ('order_info', 'insert', 'kafka', 'dwd_order_info', 'id,consignee,consignee_tel,total_amount,order_status,user_id,payment_way,delivery_address,order_comment,out_trade_no,trade_body,create_time,operate_time,expire_time,process_status,tracking_no,parent_order_id,img_url,province_id,activity_reduce_amount,coupon_reduce_amount,original_total_amount,feight_fee,feight_fee_reduce,refundable_time', 'id', NULL);表示表order_info有插入数据,就会同步到kafka中,topic为dwd_order_info。
-
启动kafka消费者,查看是否有数据进来
[zhangbao@hadoop101 root]$ cd /opt/module/kafka/bin/[zhangbao@hadoop101 bin]$ ./kafka-console-consumer.sh --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic dwd_order_info -
最后启动业务数据生成服务:mock-db-0.0.1-SNAPSHOT.jar
记得先修改配置文件的生成日期:2021-09-12
最后查看kafka消费者可以看到有数据产生,说明流程已经走通。
3.算子选择简介
| function | 可转换结构 | 可过滤数据 | 侧输出 | open | 可以使用状态 | 输出至 |
|---|---|---|---|---|---|---|
| MapFunction | Yes | 下游算子 | ||||
| FilterFunction | Yes | 下游算子 | ||||
| RichMapFunction | Yes | Yes | Yes | 下游算子 | ||
| RichFilterFunction | Yes | Yes | Yes | 下游算子 | ||
| ProcessFunction | Yes | Yes | Yes | Yes | Yes | 下游算子 |
| SinkFunction | Yes | Yes | 外部 | |||
| RichSinkFunction | Yes | Yes | Yes | Yes | 外部 |















 1898
1898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









