






前期准备
进入zookeeper的bin目录,启动zookeeper,并查看状态
zkServer.sh start
zkServer.sh status进入Kafka的bin目录,启动Kafka
kafka-server-start.sh $KAFKA_HOME/config/server.properties另打开两个终端,一个作为消费者,一个作为生产者
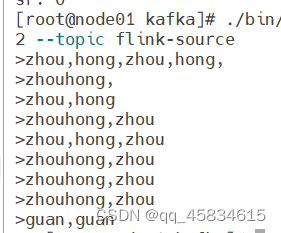
启动生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic flink-source启动消费者
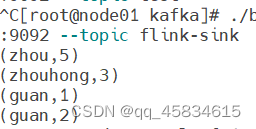
kafka-console-consumer.sh -bootstrap-server localhost:9092 --topic flink-sink代码编写
package KafkaWithFlink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.util.Properties;
/**
* Create by zhh on 2022/9/5.
* 使用Flink的Kafka Source对接数据,进行词频统计,将统计结果通过Kafka Sink输出到Kafka中,使用Kafka消费中终端作为输出
*/
public class wordCount {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","192.168.32.222:9092");
properties.setProperty("group.id","test");
//kafka生产者
String consumerTopic="flink-source";
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(consumerTopic, new SimpleStringSchema(), properties);
//kafka消费者
String produceTopic = "flink-sink";
FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer<>(produceTopic, new SimpleStringSchema(), properties);
//source阶段
DataStreamSource<String> source = env.addSource(kafkaConsumer);
//transformation阶段
SingleOutputStreamOperator<String> flatSource = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> out) throws Exception {
String[] splits = s.split(",");
for (String split : splits) {
out.collect(split);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> mapSource = flatSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s,1);
}
});
//相同键相加,需要是keyed的数据
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = mapSource.keyBy(x -> x.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
//将tuple2数据map为String
SingleOutputStreamOperator<String> result = reduce.map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return "(" + value.f0 + "," + value.f1 + ")";
}
});
result.print();
//Sink阶段
result.addSink(kafkaProducer);
env.execute();
}
}
最终在生产者终端输入数据,则可以在消费者端得到结果















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









