







论文名称:When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
ArXiv网址:https://arxiv.org/abs/2212.10511
官方GitHub项目:https://github.com/AlexTMallen/adaptive-retrieval
本文是2023年ACL论文,关注理解LLM中存储的知识(knowledge probing)。
本文中的知识指的是三元组: (subject, relationship, object)
本文发现LLM不擅长长尾事实知识,但这可以用检索增强的方法解决。增大模型尺寸只能增加模型对常见知识的理解。本文提出了一种检索增强方法Adaptive Retrieval,根据知识常见程度自适应选择是否检索,可以提高指标,减少推理代价。
本文主要考虑subject和relationship的常见程度。(为了仅用输入信息就实现判断)
文章目录
1. 研究背景和观察结果
LLM存储的知识(parametric knowledge)有记不住长尾实体、幻觉、知识落后于时代的问题,可以用检索文本(non-parametric knowledge)来解决
在常见实体上,加了检索反而不如不加:
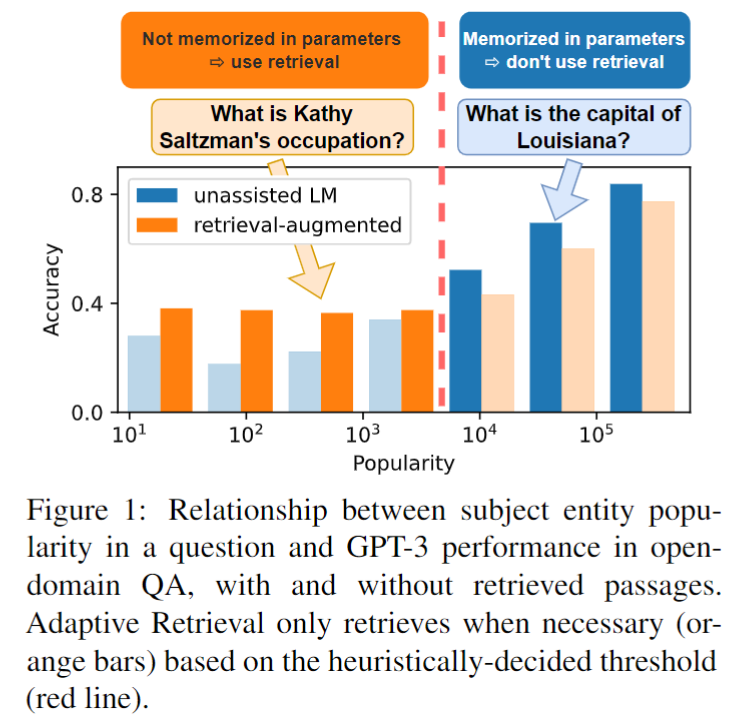
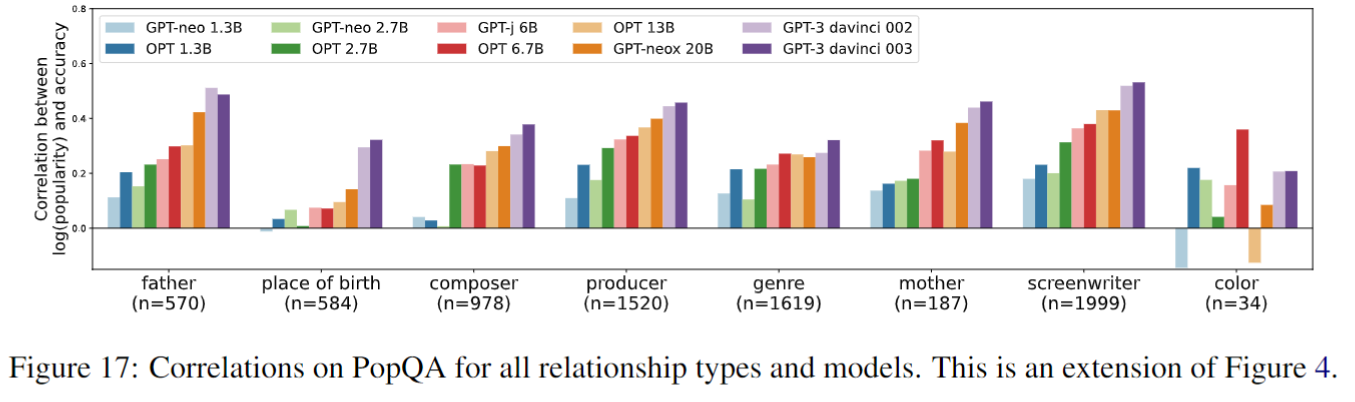
扩大模型尺寸不能直接解决长尾问题(模型尺寸越大,subject流行度和准确率的相关性越大)
(图像见后文)
2. knowledge-probling实验
1. 任务
零样本/少样本open-domain QA
本文用的是decoder-only模型。encoder-only模型可能会采用[MASK]的形式来解决问题。
仅用prompt工程,不更新模型参数。
Q: <question> A:
2. 数据集
open-domain entity-centric QA datasets
-
PopQA(14k样本,关注长尾实体)
构建方法:
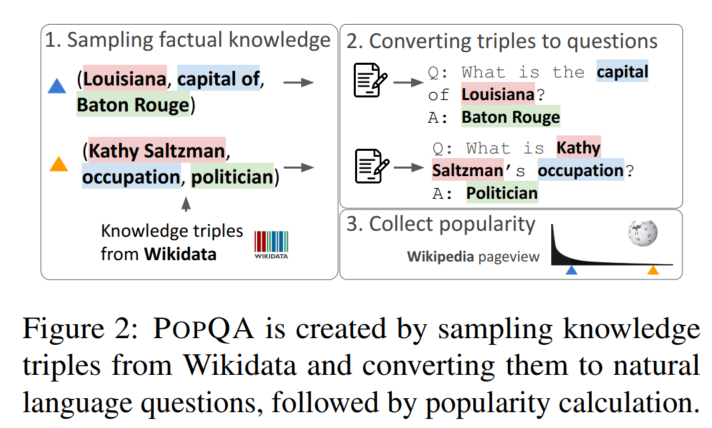
(文中说具体用什么template不太影响结果)

-
EntityQuestions
出处:(2023 EMNLP) Simple Entity-Centric Questions Challenge Dense Retrievers
数据集的长尾分布:
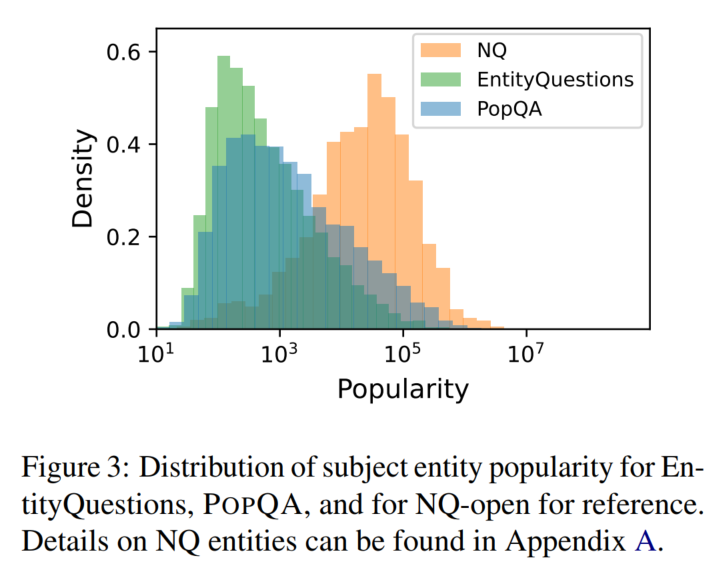
3. 实验用的backbone LLM
GPT-Neo
1.3 2.7 6 20
(2022 BigScience) GPT-NeoX-20B: An Open-Source Autoregressive Language Model
OPT
1.3 2.7 6.7 13
(2022 Meta) OPT: Open Pre-trained Transformer Language Models
GPT-3
davinci-002, davinci-003
(2020 NeurIPS) Language Models are Few-Shot Learners
(本文没用T5是因为T5预训练就已经用过QA了)
GPT-3用的是zero-shot,另外两个模型用的是15-shot(因为贵)
4. 实验结果
评估指标:准确率(输出文本中包含了任意一个object就算正确)
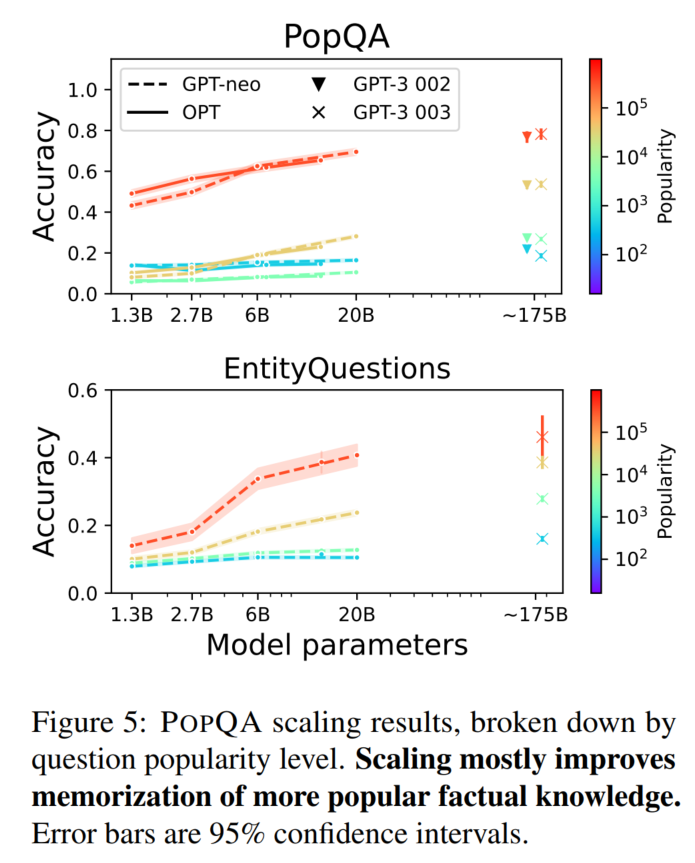
PopQA
结论:LM规模越大越好,subject越常见越好。relationship对效果的影响可能是因为有些relationship格外好猜
从subject实体名猜结果的参考文献:(2020 EMNLP Findings) E-BERT: Efficient-Yet-Effective Entity Embeddings for BERT (2021 ACL) Knowledgeable or Educated Guess? Revisiting Language Models as Knowledge Bases
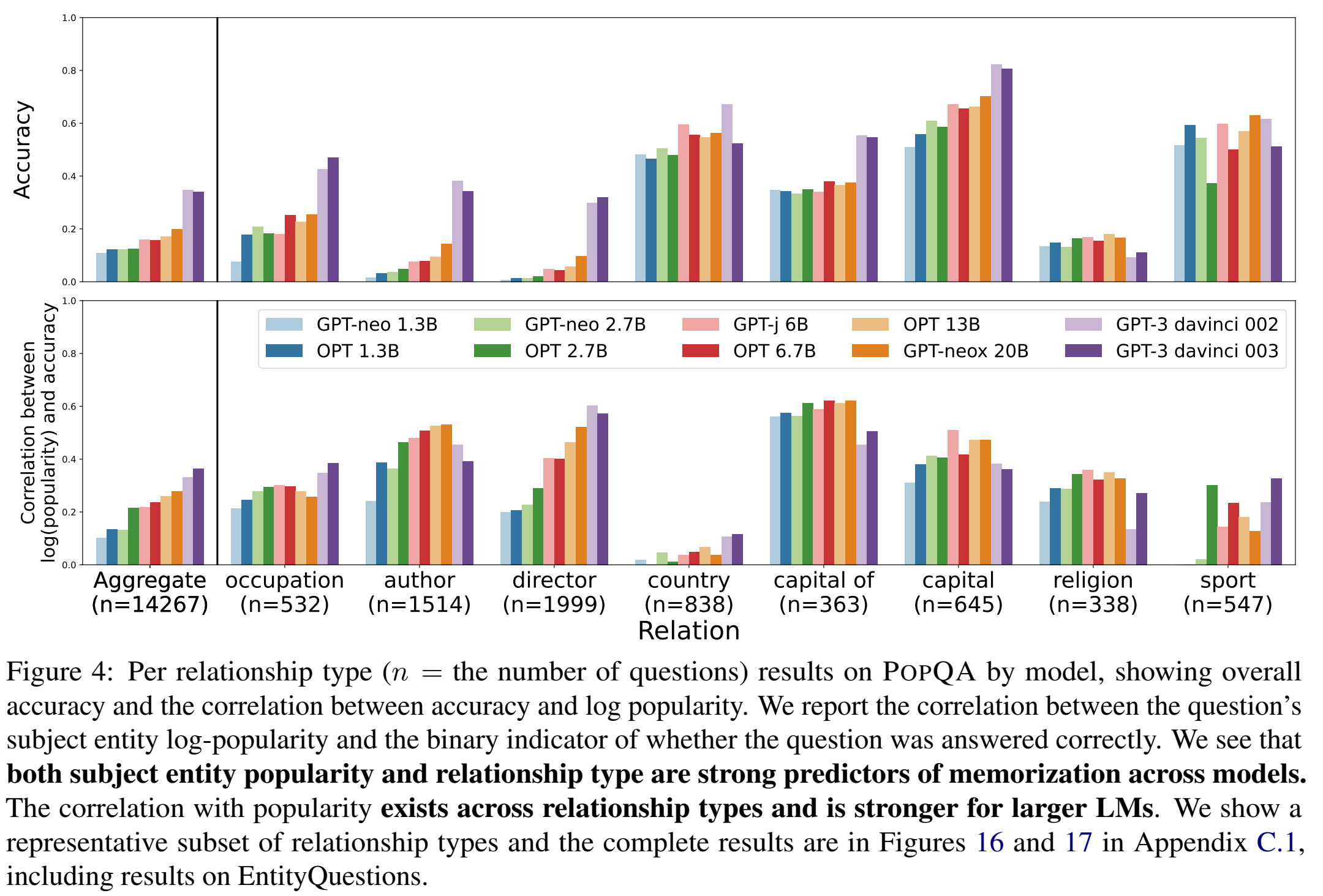
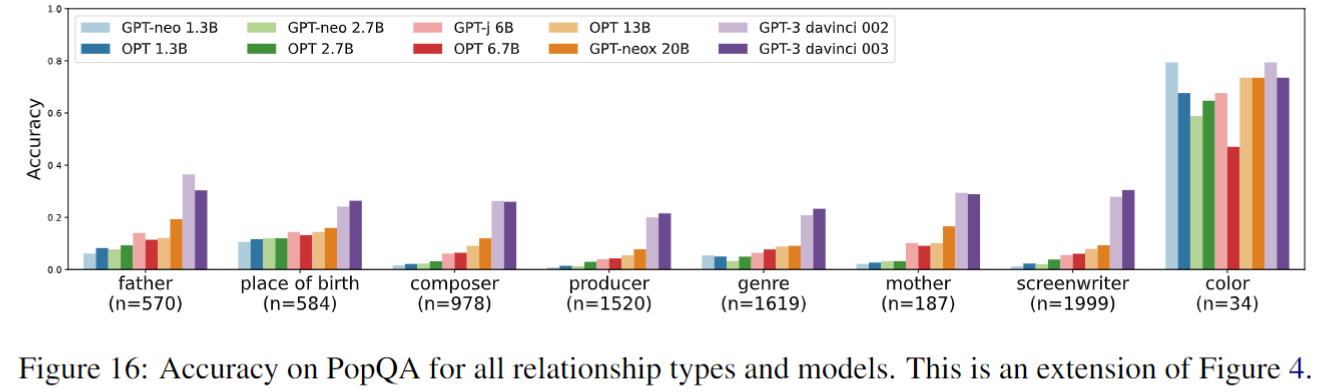
EntityQuestions
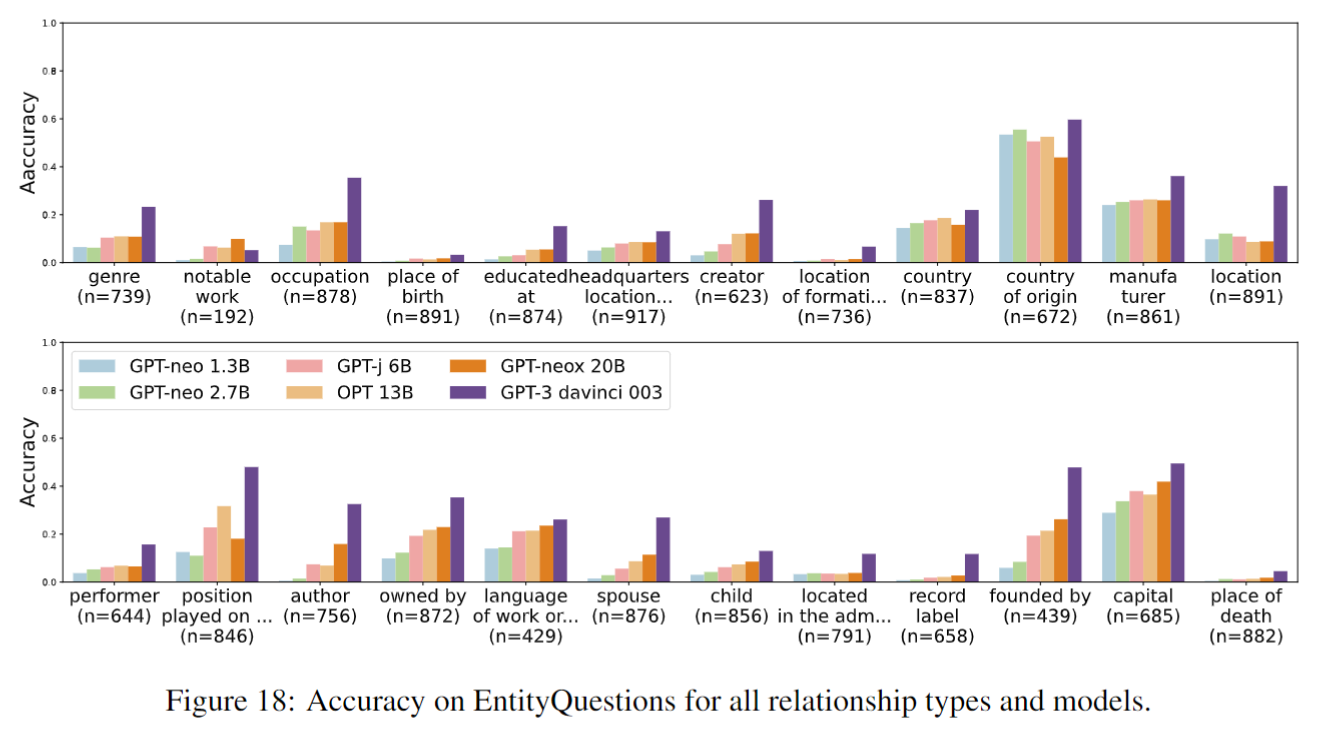
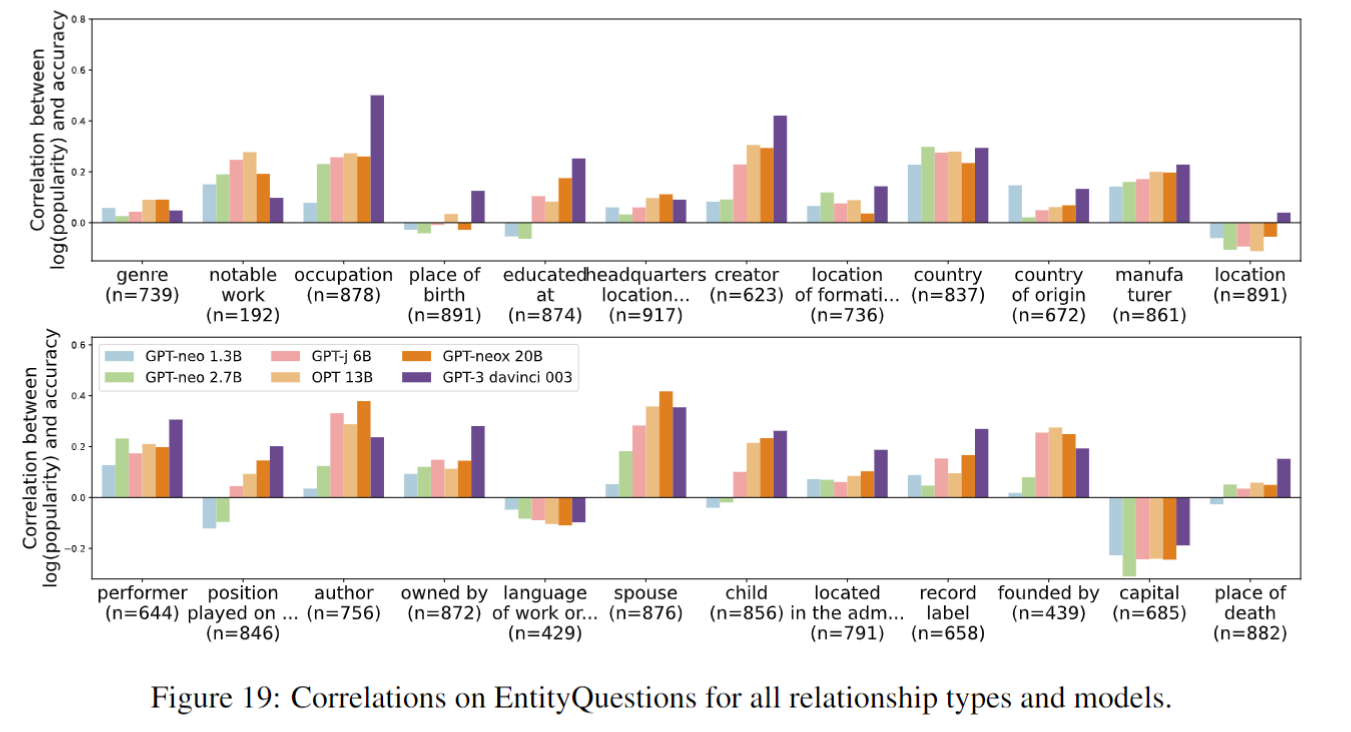
scale也对低频样本没啥用(提升不多):
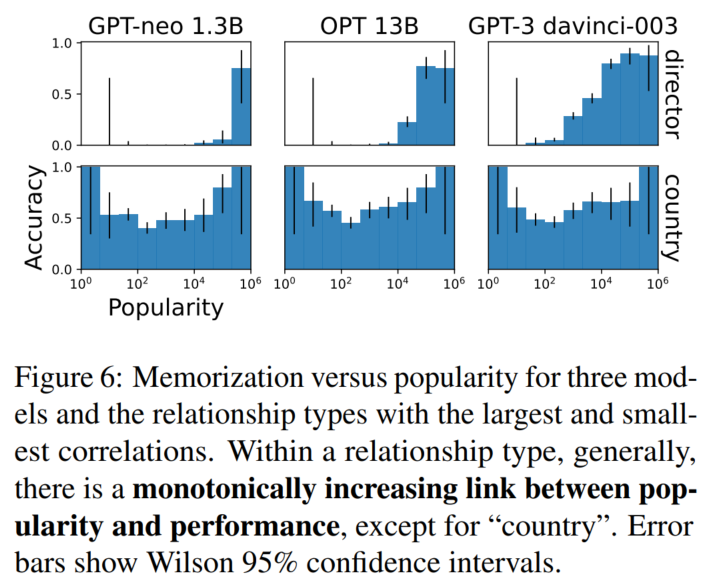
不同模型在不同relationship上,不同popularity样本的准确率:(country是靠猜的)
3. 传统RAG实验
1. 实验设置
增强输入:检索维基百科中问题的相关文本(仅选一个自然段)
扩大上下文本来就能提高效果。参考资料:(2021 EACL) Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (2022 NAACL) Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks
2. 检索模型
BM25
(2009 Foundations and Trends in Information Retrieval) The Probabilistic Relevance Framework: BM25 and Beyond
Contriever:预训练的检索模型
(2023 TMLR) Unsupervised Dense Information Retrieval with Contrastive Learning
parametric augmentation method, GenRead
(2023 ICLR) Generate rather than Retrieve: Large Language Models are Strong Context Generators
所以一共是4×10个LM
3. 实验结果
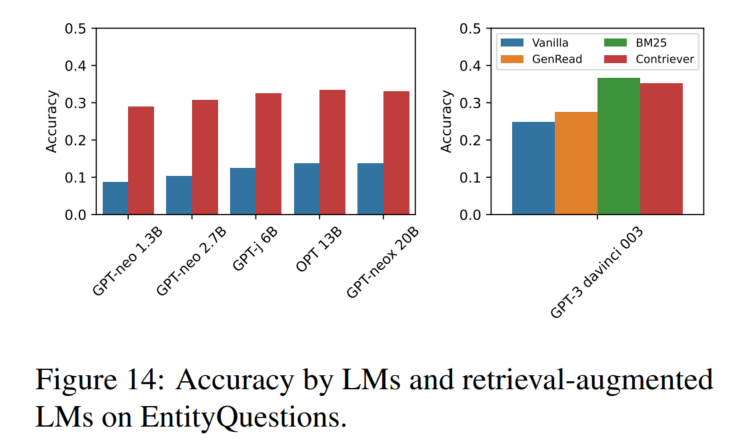
检索模型加上去能提升效果:
PopQA:
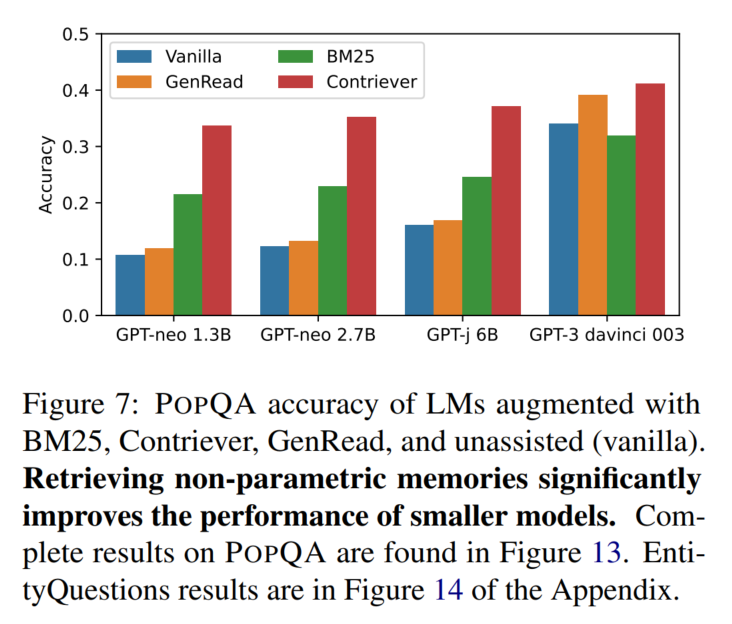
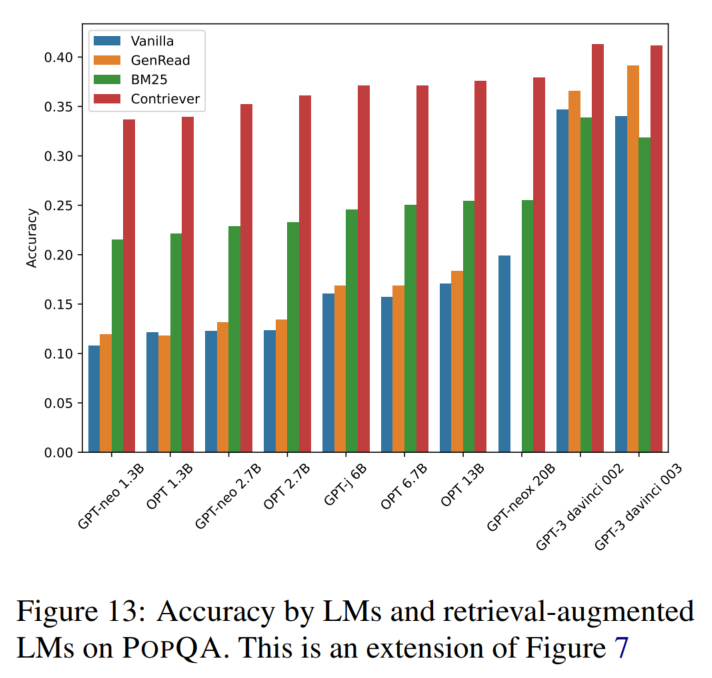
EntityQuestions:
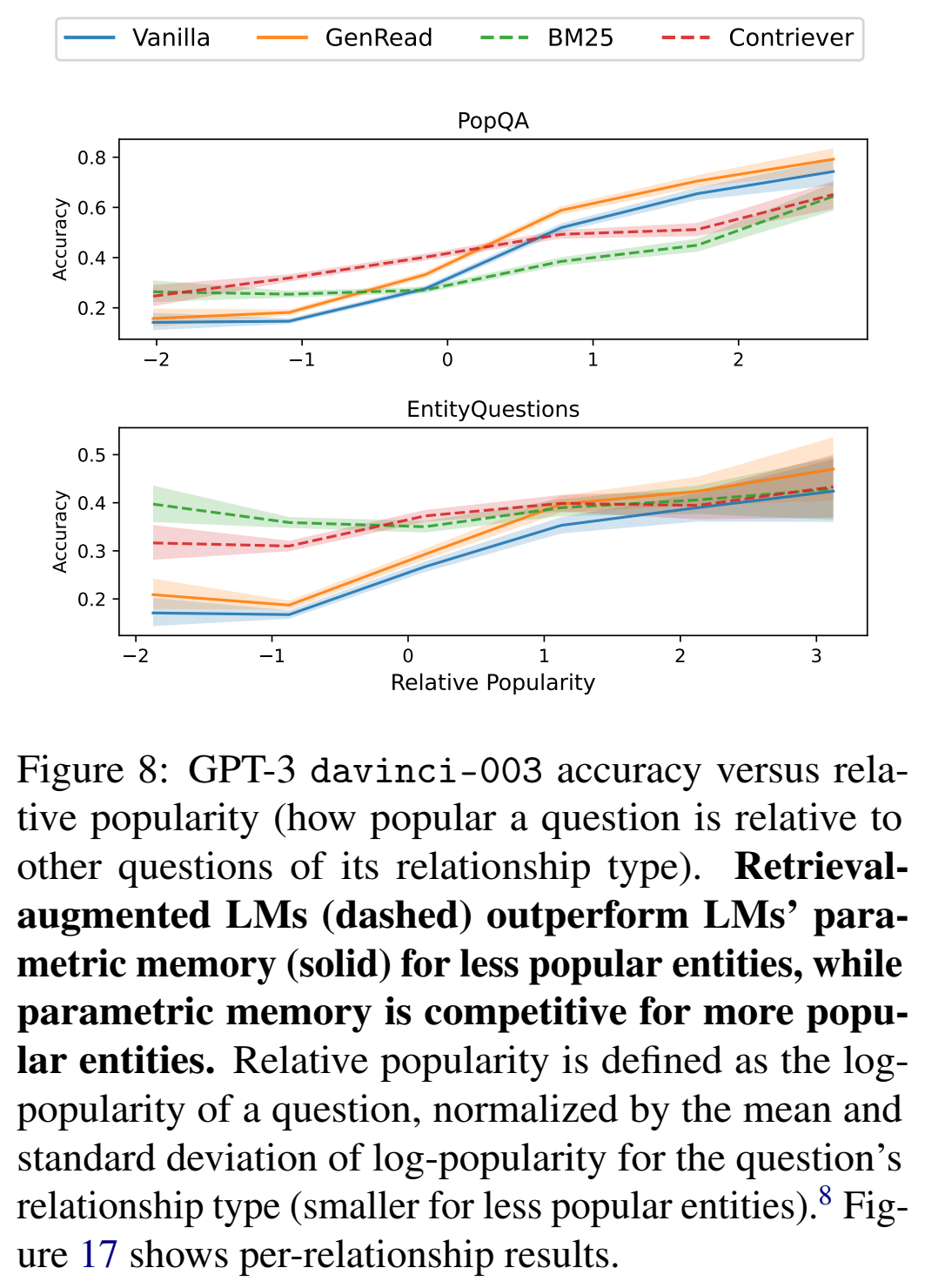
加不加检索这2种准确率与popularity之间的关系:
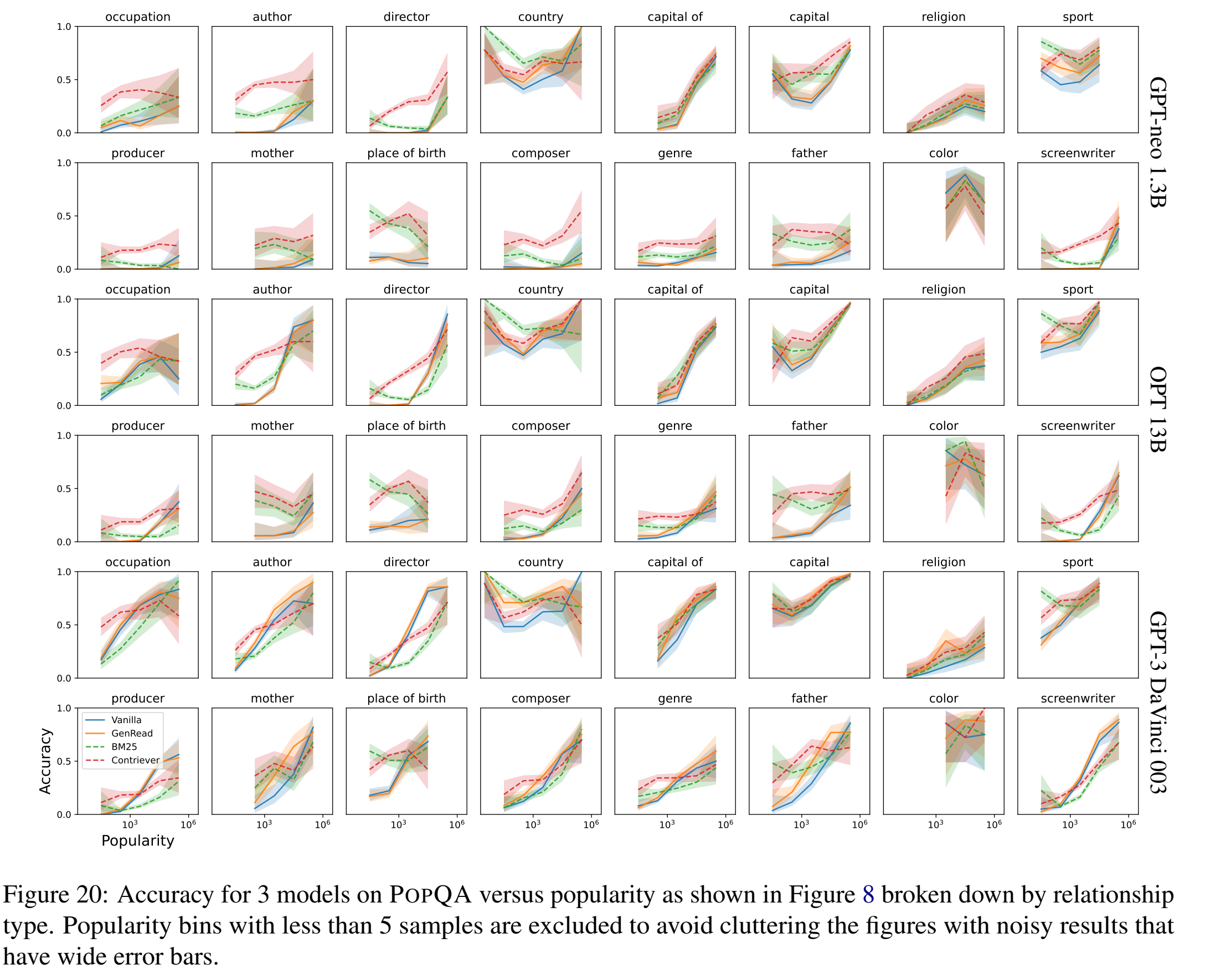
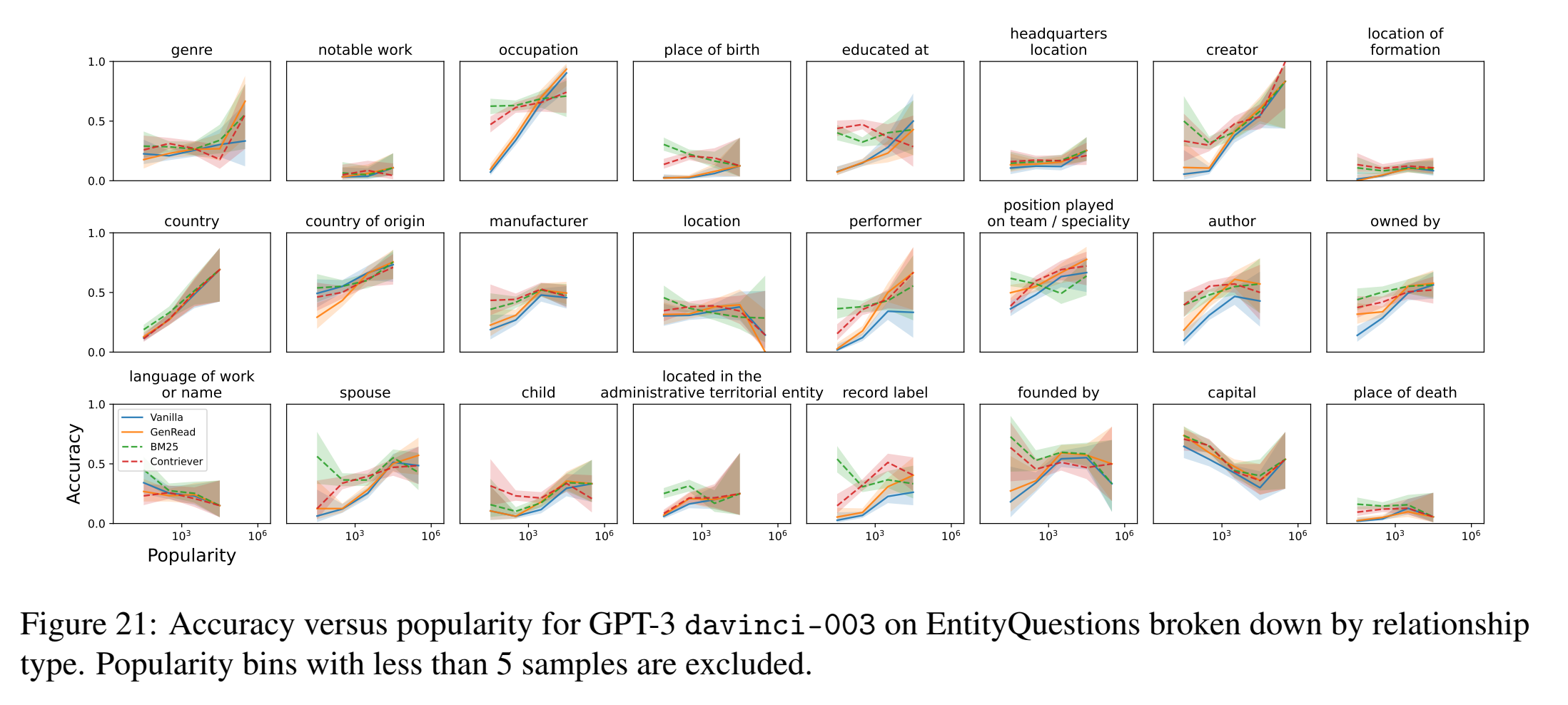
上图按照relationship分别绘图:
在流行实体上,检索结果可能会误导模型:
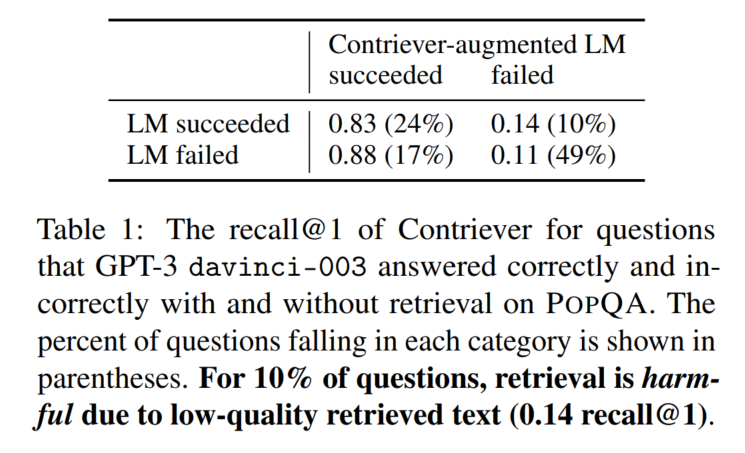
上述现象的案例分析:
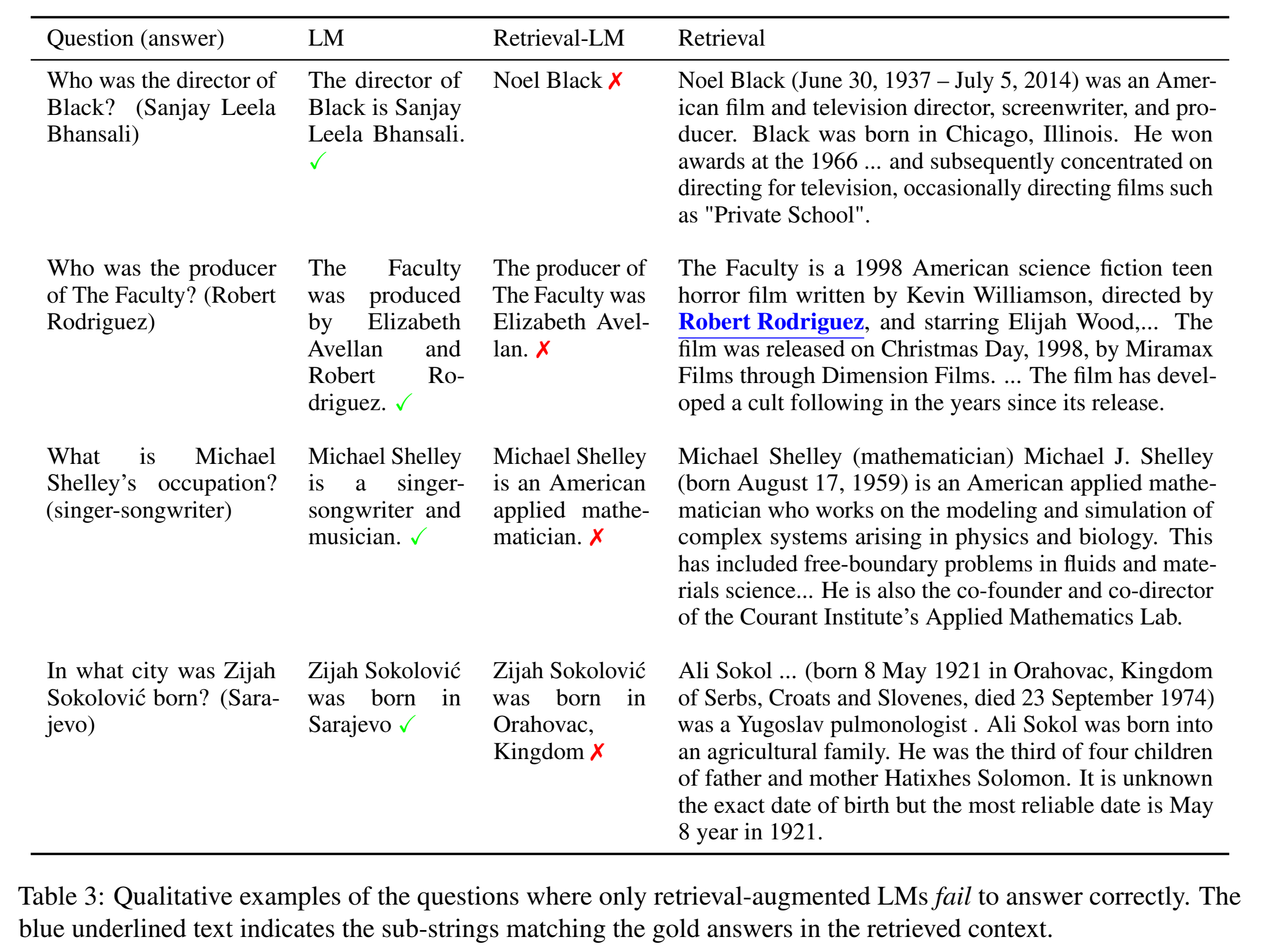
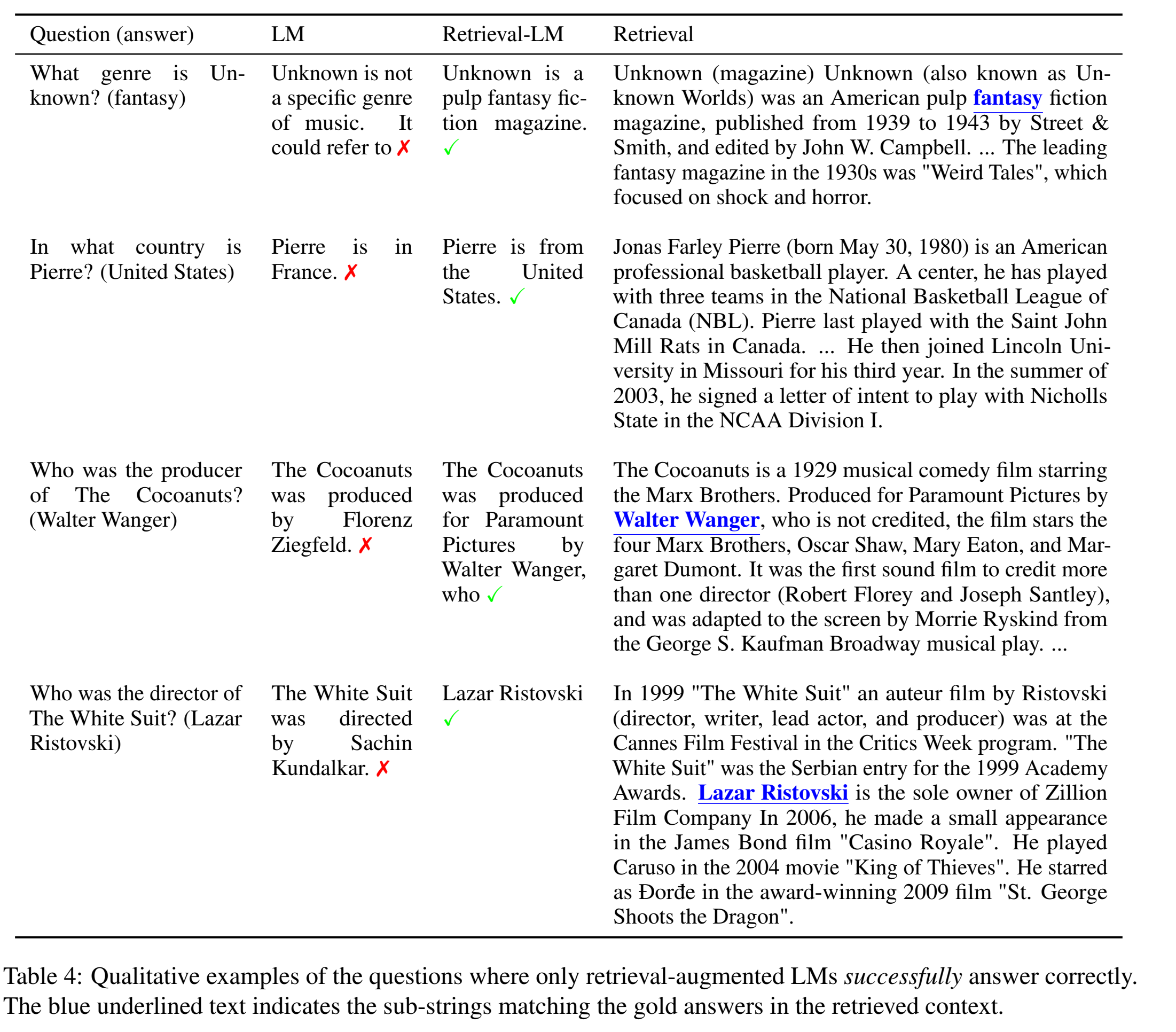
4. Adaptive Retrieval
对popularity低于阈值的问题进行检索,其他问题不检索。
阈值通过验证集计算得到(每个relationship都不一样)。
实验结果
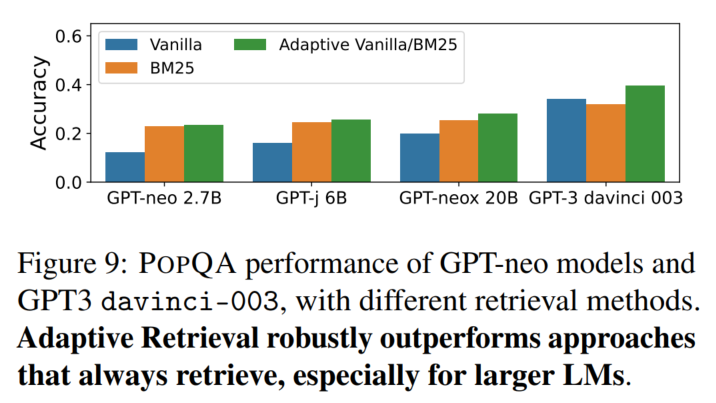
(文字说最好的效果叠的是Contriever,不知道为什么图上写的是BM25)
模型越大,需要检索的问题越少(阈值变化):
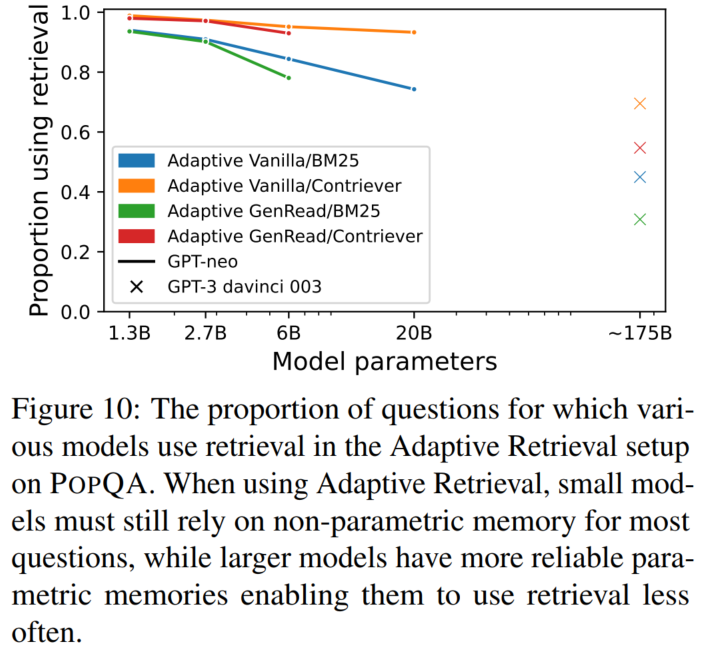
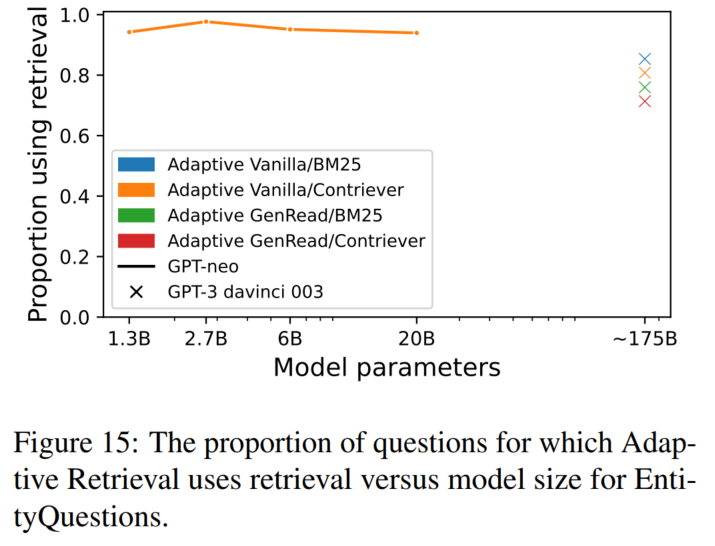
减少推理代价(跟需要说很多话的检索模型相比)
用时:
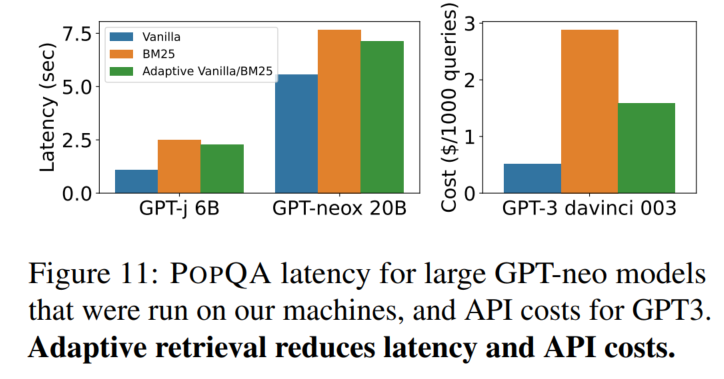
价格:
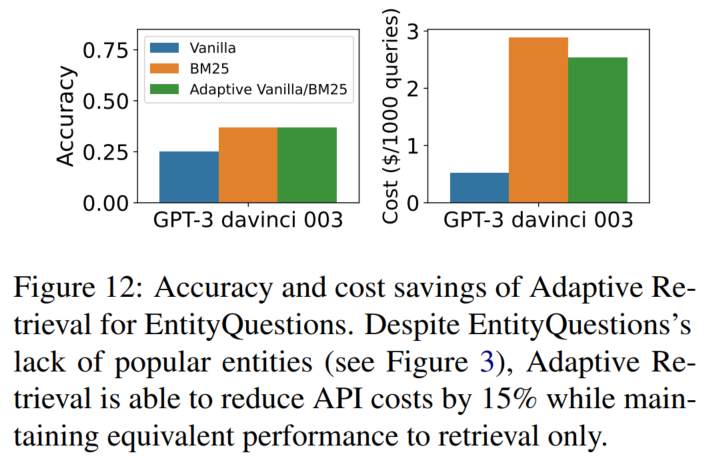
5. 讨论
- 作者提到的:
- 实验用的数据集是人造的,不一定能泛化到真实场景下。
- 效果与pipeline有关
- popularity这个概念time-dependent
- subject和relationship的类型
- 隐私保护和对少数群体的偏见
- 我的思考:检索怎么都是加文本啊文本已经很长了(卡脖子卡脖子)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











