







针对二分类问题而言,会得到如下4个值,其中预测Positive-1和Negative-0,True和False描述预测的对错:
- TP: True Positive 将正类预测为正类
- FN: False Negative 将正类预测为负类
- FP: False Positive 将负类预测为正类
- TN: True Negative 将负类预测为负类
| 正样本 | 负样本 | 合计 | |
|---|---|---|---|
| 正样本 | TP | FP | P(预测为正样本) |
| 负样本 | FN | TN | N(预测为负样本) |
| 合计 | T | F | T+F 或 P+N |
混淆矩阵
- 直观呈现以上四种情况的样本数
真阳性率(True Positive Rate, TPR)
- 也叫敏感性(sensitivity)
- TPR = TP/(TP+FN) = TP/T
- 真阳性率,即实际有病,但根据筛检被判为有病的百分比;
假阳性率(False Positive Rate, FPR)
- 也叫特异性(specificity)
- FPR = FP/(FP + TN) = FP/F
- 假阳性率,即实际无病,但根据筛检被判为有病的百分比;
准确率(accuracy)
- 准确率是针对样本而言的,标志预测正确样本占所有样本的比例。
- accuracy = (TP+TN)/(TP+FN+FP+TN)
- 解释:预测正确包括两种可能,一种就是把正类预测为正类(TP),另一种就是把负类预测为负类(TN)。
- 在不平衡分类问题中难以准确度量:比如98%的正样本只需全部预测为正即可获得98%准确率。
精确率(precision)
- 也叫查准率
- 精确率是针对预测结果而言的,表示预测为正的样本中有多少是真正的正样本。
- precision = TP/(TP+FP) = TP/P
- 解释:预测为正就有两种可能,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。
召回率(recall)
- 也叫查全率
- 召回率是针对样本而言的,它表示的是样本中的正例有多少被预测正确了。
- recall = TP/(TP + FN) = TP/T
- 解释:样本为正有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
ROC曲线(Receiver Operating Characteristic Curve)
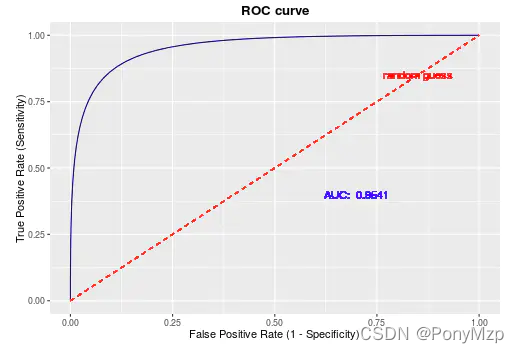
ROC曲线的横坐标为假阳性率(False Positive Rate, FPR),纵坐标为真阳性率(True Positive Rate, TPR)
- ROC曲线的4个点和1条线
-
第一个点,(0,1),即FPR=0,TPR=1,这意味着无病的没有被误判,有病的都全部检测到,这是一个完美的分类器,它将所有的样本都正确分类。
-
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
-
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,没病的没有被误判但有病的全都没被检测到,即全部选0
-
类似的,第四个点(1,1),分类器实际上预测所有的样本都为1。
-
经过以上的分析可得到:ROC曲线越接近左上角,该分类器的性能越好。
相比于其他的P-R曲线(精确度和召回率),ROC曲线有一个巨大的优势就是,当正负样本的分布发生变化时,其形状能够基本保持不变,而P-R曲线的形状一般会发生剧烈的变化,因此该评估指标能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。
AUC(Area under roc Curve)
- ROC曲线面积,0.5-1之间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









