









为什么要使用Hive?
hadoop中的mr有缺点(Mapper:的输出,就是把键相同的合并起来;sql:语句;
Reduce:诊对一个键相同的多个值,进行处理;聚合函数;(词频:sum);(order by))
需要自己编程,不方便,hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行,使MapReduce变得更加简单。
Hive的特点
可扩展:Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
容错:良好的容错性,节点出现问题SQL仍可完成执行
Hive的运行模式
1.数据库:access,virtutal fox,sqlserver,mysql,sqlite,postgresql,oracle;
2.Local模式.此模式连接到一个In-Memory的数据库Derby,一般用于UnitTest.
3.单用户模式.通过网络连接到一个数据库中,是最常使用到的模式.

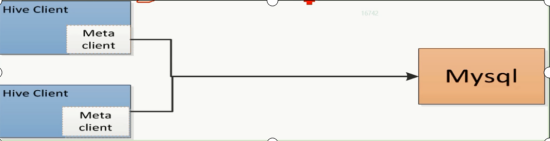
4.多用户模式:远程服务器模式.用于非java客户端访问元数据库(metastore),在服务器端启动metaStoreServer,客户端利用thrift协议通过metaStoreServer访问元数据库
Hive 架构图


- 用户接口主要有三个:Cli,Client和WebGUI,其中最常用的是cli,cli启动的时候会同时启动一个hive副本,client是hive客户端,用户连接到hiveServer.在启动client模式的时候,需要指出hiveServer所在的节点,并且在该节点启动hiveServer.WUI是通过浏览器也能访问Hive
- Hive将元数据(数据库,表)存储在数据库表(真实的数据库,mysql)中,如mysql,derby.hive中元数据包含表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的目录等.数据库(Mysql)中并不存储Hive的记录;
- 解释器,编译器,优化器完成sql查询语句从词法分析,语法分析,编译,优化以及查询计划的生成.生成的查询计划存储在hdfs中,并在随后有mapreduce调用执行.
- Hive数据存储在hdfs中,大部分数据查询,计算由mapreduce完成(包含*的查询,比如select* from tbl不会生成mapreduce任务)
- 元数据(hive中看到的库,表)存储到真实的数据库(mysql);记录存储到了hdfs上; 经常使用的mysql:表,记录,库都存储到文件系统中(NTFS)
- hive的客户端连接服务器走的是thrift协议;====http==https;传输的内容大小比较小;
Hive架构:
- 用户在hive中输入了一个SQL语句;要么转成Mr执行,要么直接查询文件;
- 编译器:将一个hive Ql转换操作符(在hive中写的sql语句;hive QL,hql)
- 操作符是Hive的最小处理单元(sql语句中的一个语法;from,left join,>,<,orderby )
- 每个操作符代表hdfs一个操作或者一道mapreduce作业.
类型

Hive内部表和外部表的区别?
我们再创建外部表的时候要加个关键字 external
内部表 : 当我们在hive中使用命令删除hive表时 hive所对应的hdfs的目录会被删除 元数据库中的数据 也被删除
外部表 : 在hive中删除了外部表 而外部表所对应的hdfs目录不会被删除 元数据库被删除
hive常用的文件格式有哪些?
Avro,ORC,Parquet,textfile,json等
相关命令
1.初始化操作:bin/schematool -dbType mysql -initSchema
(# 初始化之前最好把之前的数据库删除掉 rm -rf derby.log metastore_db/)
2.启动服务器:
bin/hive --service metastore
nohup bin/hive --service metastore & (后台启动)
3.启动客户端
bin/hive
4.停止服务
Kill -9 进程号
5.Web页面访问
http://node7-4:10001/
6.切换数据库
use 数据库名称 ;
7.查看在哪个数据库
select current_database() ;
8.查看所有表
show tables;
9.描述库
desc database 数据库名称 ;
describe formatted 表名 ;
10.查看单张表
desc 表名 ;
11.修改表名
alter table 原来的表名 rename to 新表名 ;
12.删除表
drop table 表名 ;
delete from 表名 ;(相当于删除文件中的某个内容;)
truncate table 表名 ;(表里面的记录全部干掉;;直接删除文件)
13.查询记录
select * from 表名 ;
四.创建表(简单的):
>create table 表名
>(
>id int comment '这是id',
>name string comment '这是名字',
>age tinyint ,
>score double ,
>createTime timestamp
>)
>comment '这是表的注释';( 带格式的--事务 )
>create table 表名
>(
>id int ,
>name string,
>age smallint,
>scroe double,
>createTime timestamp
>)
>-- 记录行的分隔符
>row format delimited
>-- 列的分隔符
>fields terminated by ','
>-- 存储文件的格式;textfile是默认的,写与不写都是一样的
>stored as textfile ;(创建类型复杂表)
>create table 表名
>(
i>d int ,
>name string,
>age smallint,
>scroe double,
>-- 地址;容器,泛型
>address array<string>,
>-- map爱好;容器,泛型
>hobby map<string,string>,
>createTime string
>)
>-- 记录行的分隔符
>row format delimited
>-- 列的分隔符
>fields terminated by ','
>-- 数组的拆分
>collection items terminated by '-'
>-- map
>map keys terminated by ':'
>-- 存储文件的格式;textfile是默认的,写与不写都是一样的
>stored as textfile ;(分区)
>partitioned by (sex string)
>多个分区,分区的规则,指定列进行分区,分区的列不允许出现在小括号中;(分区可以有多个)
partitioned by (sex string,adress string)















 6827
6827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









