







本文的内容python3自我实现代码见最下方的代码
============以下转载自:http://blog.csdn.net/w93223010/article/details/20358683===============
本节的内容主要是如何使用一个Python 写的一个 HTML/XML的解析器——BeautifulSoup,用它将上一节生成的result文件(就是抓取保存的网页源码)中所需的内容取出。关于BeautifulSoup的简介和下载安装请参考黄聪仁兄的博客。另附BeautifulSoup的中文文档
先上代码:
第1行在程序中引入了BeautifulSoup。
第3至6行是文件操作,将result1.html文件中的内容读取到html变量中。
第8、9行使用BeautifulSoup对html变量进行格式化,并使用find_all方法获取到所需的数据对象。
第10、11行将获取的“产品名称”信息全部展示出来。
对上段的代码进一步解释:
首先,第一个需求是获取如图2-1所示的产品的产品名称信息,即“NewFashion Men Slim Fit Cotton V-Neck Short Sleeve Casual T-Shirt Tops”。
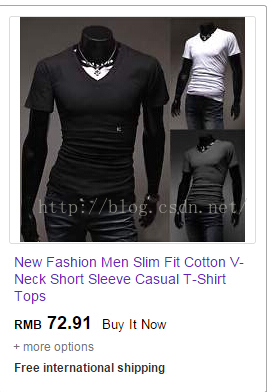
图2-1
其次,观察result1.html中的源代码发现,与48个产品相对应,产品名称全部放在class为gvtitle的48个div内,如图2-2所示。因此使用find_all方法查询出所有含class属性值为gvtitle的div,以列表的形式存入gvtitle变量中。

图2-2
之后,进一步观察图2-2中html文件的结构,发现“New Fashion Men Slim Fit Cotton V-Neck Short Sleeve Casual T-ShirtTops”这行文本就放在div标签内的a标签中,所以在代码的第10行用.a.text获取并展示。上段程序运行结果如图2-3。
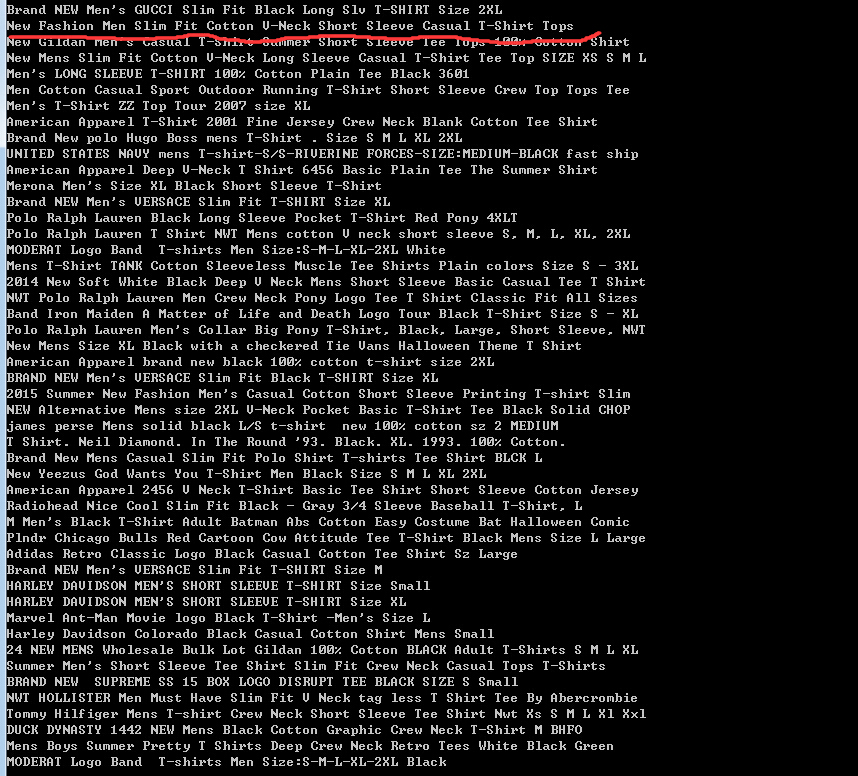
图2-3
接下来修改代码,进一步获取产品的价格信息。这部分使用了正则表达式,关于正则表达式的知识请参考——正则表达式入门教程
代码如下:
第1行引入正则表达式
第4至7行定义了一个方法,功能是使用正则表达式对BeautifulSoup获取来的数据进一步筛选。
第19行使用find_all方法获取到所需的价格。不过观察result1.html中的源码发现,class为amt的span中的数据不如第15行获取的数据那么规则,所以在第21行调用了getItems方法对数据进一步筛选,获得价格。
程序运行结果如图2-4,不过有些产品获取到了2个价格。这是因为有些产品下有多个子产品,这两个数值表示的是最低价和最高价,如图2-5。
为求结果集简单,就将两值取平均值作为最终值。
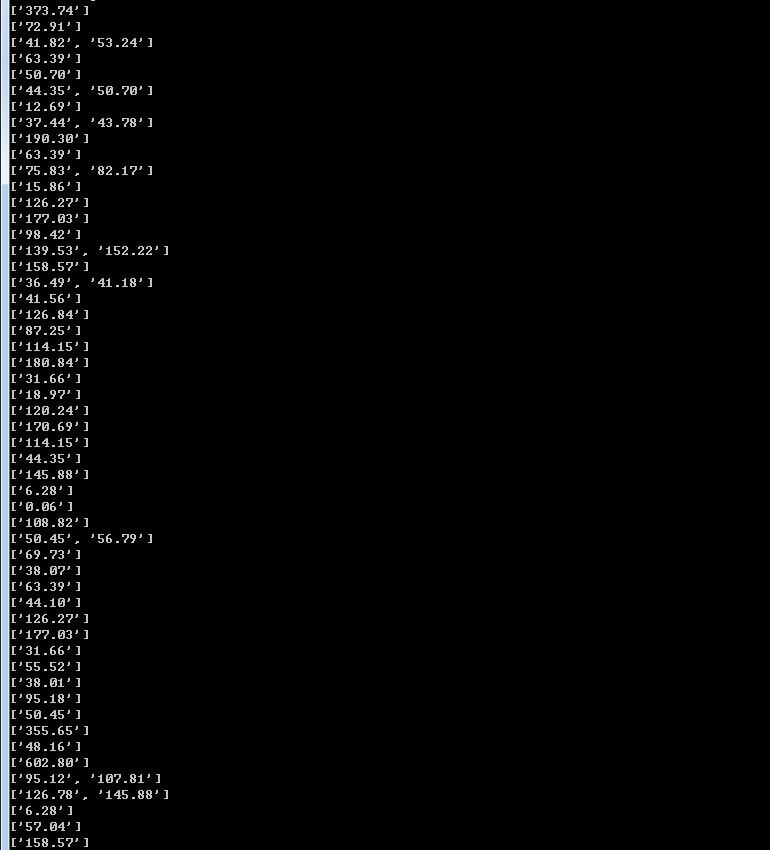
图2-4
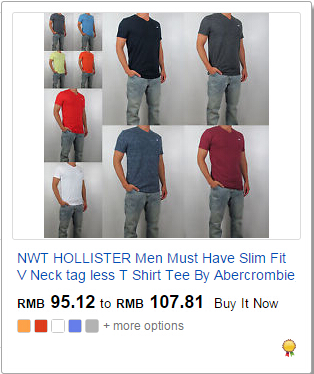
图2-5
修改代码,最后如下:
第31至40行古怪的输出代码是为了删除掉产品名称中有时会出现的“™”符号,暂时没想到更好的办法,恳请各位童鞋指教。
===============================以下是python3的实现代码==================================
#下载网页源码并写入文件
import urllib.request
url = "http://www.ebay.com/sch/TShirts-/15687/i.html?Style=Basic%2520Tee&_dcat=15687&Color=Black&_pgn=1"
req = urllib.request.Request(url)
html_open = urllib.request.urlopen(req)
html_data = html_open.read()
html = str(html_data.decode("utf8")) #先read再decode
html = html.replace("\xa0"," ")
html = html.replace("\xa9"," ")
html.encode("gbk") #写入txt中尽量用gbk编码
file_name = "f:/test/1.txt"
file_open = open(file_name, "a") #将网页源码写入1.txt中
file_open.write(html)
file_open.close()#用bs解析页面并提取数据信息_商品名称
from bs4 import BeautifulSoup
pagepath = "f:/test/pagecode.txt"
pagedata = open(pagepath)
html = pagedata.read()
pagedata.close()
bs = BeautifulSoup(html,"lxml")
gvtitle = bs.find_all("div", attrs={"class":"gvtitle"}) #返回列表形式gvtitle
for title in gvtitle:
print(title.a.text)#用bs解析页面并提取数据信息_商品价格
from bs4 import BeautifulSoup
pagepath = "f:/test/pagecode.txt"
pagedata = open(pagepath)
html = pagedata.read()
pagedata.close()
bs = BeautifulSoup(html,"lxml")
gvtitle = bs.find_all("div", attrs={"class":"gvprices"}) #返回列表形式gvpricesd
for title in gvtitle:
print(title.span.text)#以上两端代码的汇总实现:用bs解析页面并提取数据信息_商品名称+价格(bs+正则)
import re
from bs4 import BeautifulSoup
pagepath = "f:/test/pagecode.txt"
pagedata = open(pagepath)
html = pagedata.read()
pagedata.close()
def getItems(html):
pattern = re.compile("(\d+.\d*)") #正则表达式
items = re.findall(pattern,html)
if len(items)==2:
ret = (float(items[0])+float(items[1]))/2 #如果价格是一个区间计算平均值
else:
ret = items[0]
return ret
bs=BeautifulSoup(html, "lxml")
gvtitle=bs.find_all('div',attrs={'class':'gvtitle'})
for title in gvtitle:
print (title.a.text )
prices=bs.find_all('span',attrs={'class':'amt'})
for pri in prices:
result=getItems(str(pri))
print (result)














 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









