









我们知道PostgreSQL中的表存储结构属于堆表(Heap Table),这是与MYSQL不同的(MYSQL中聚集索引表Clustering Index)。那么堆表和聚集索引表到底有什么不同,我们就一起来学习一下。
首先我们了解一下什么是堆表,以下关于堆表的描述来自SQL Server关于堆表的说明
什么是堆表?
SQL Server关于堆表的描述如下,
- 没有聚集索引的表
- 堆表在sys.partitions里有1条index_id = 0 的记录
- 数据存储没有任何的顺序,插入数据也没顺序
- 由于数据没有任何顺序,查询数据会非常慢
- 数据页之间没有相互链接
- 从数据页读取数据,需要从IAM(Index Allocation Map)页里找页号
- 在sys.system_internals_allocation_units系统视图里,first_iam_page列,指向IAM页链中的第一个IAM页,它用来管理堆表的空间分配
- 因为没有聚集索引,碎片不能通过重建索引(rebuilding the index)处理
- SQL Server使用IAM页在堆结构里导航。分配给堆的页没有任何的顺序,且不相互链接。数据页之间唯一的逻辑关联是存在IAM页里的信息。
抛开SQL Server本身的一些用法以外,我们可以总结出来堆表具有的主要特点是:数据存储没有任何顺序,需要借助索引页来提升查询数据性能。下图也是一个示例说明需要通过索引页(IAM)来寻找对应的堆表数据页。
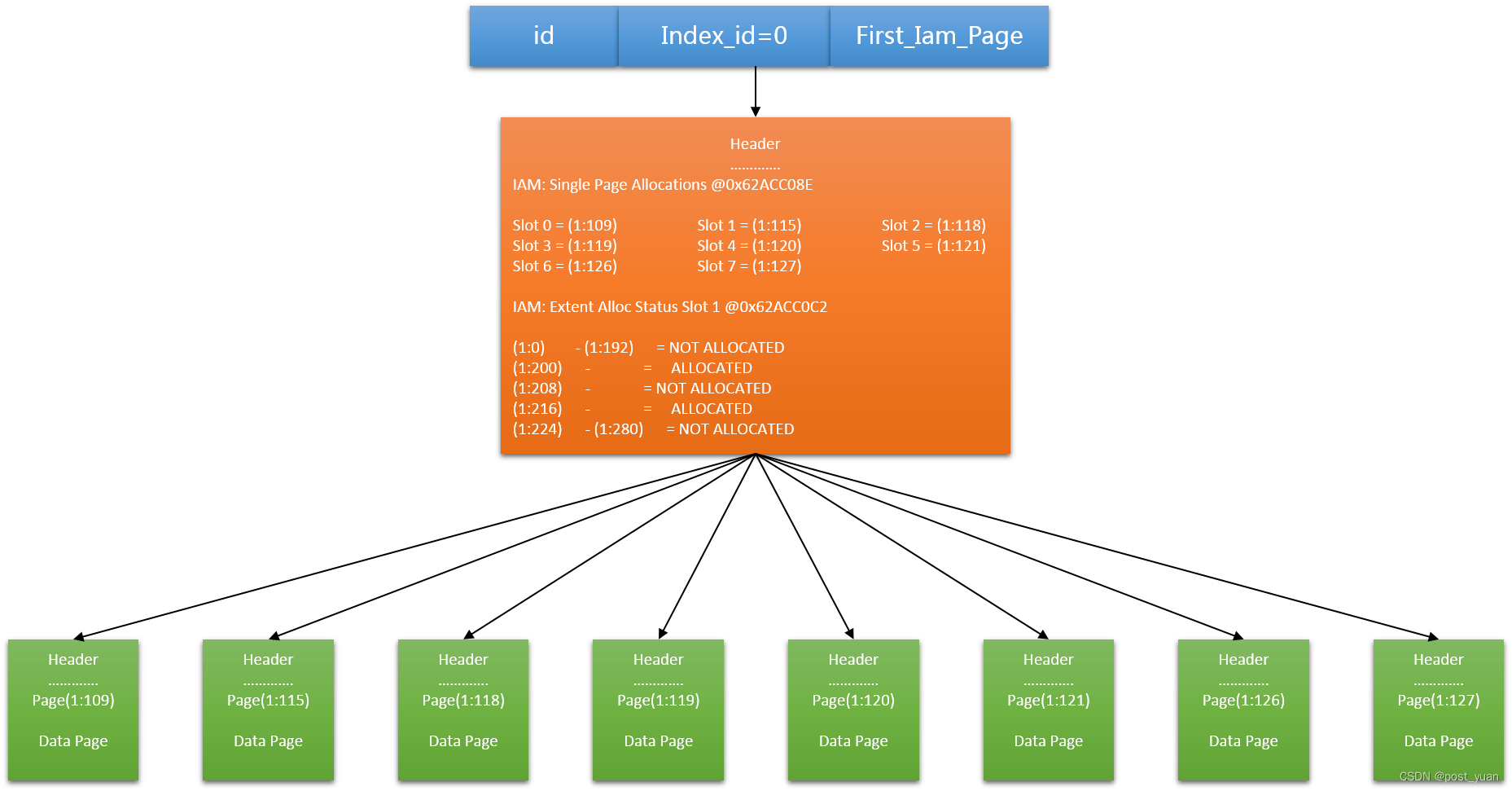
PostgreSQL中的堆表结构
OK,上述了解完什么是堆表之后,我们再来学习一下PG中的堆表。在PG数据库中,一个数据文件是由多个固定长度的页(或者称为块)组成,每个页的默认大小为8KB。在每个文件内部,这些页都有一个从0开始的页编号(block number)。当文件被填充时,PG通过增加一个新的空页到文件末尾来增加文件大小。
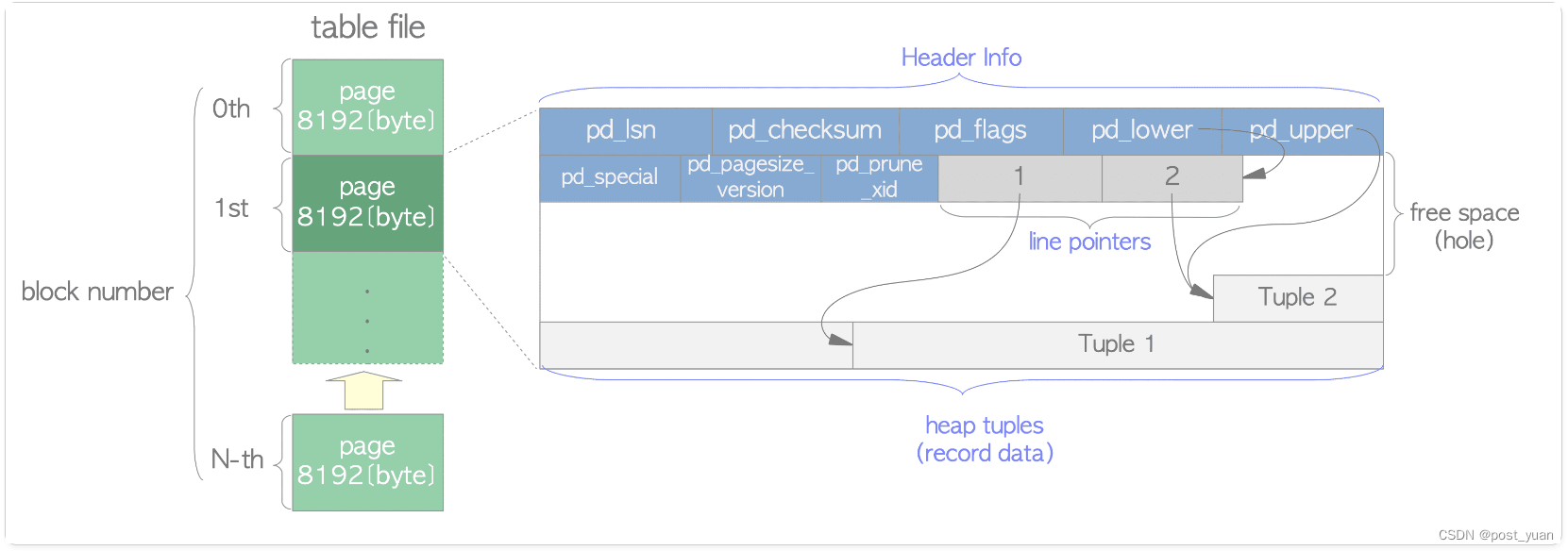
上图示例描述一个数据文件的内部结构,从图中可以看出,一个表文件内部由从0至N编号的页面构成,每个页为8KB。右边则是每个页面的内部构成。每个页面包括以下内容:
- heap tuples -即heap表中的数据记录。这些记录是从页面的底端向上存放的。每个tuple内部的结构我们单独再描述。
- line pointers -每个line pointer由4个字节表示,是一个指向具体某一条heap tuple的指针,也被称为item pointer。Line pointers组成一个简单的数组,负责索引到对应记录。每个line pointer在block内是从1开始进行编号,也被称为偏移号(offset number)。当一个新的记录被添加到页面时,就会增加一个新的line pointer与之对应。
- header data -即页面的头信息,放在页面的开始部分。由24字节表示,其中包含一些页面描述的通用信息。主要的内容有:
(1)pd_lsn -保存页面上次修改生成的XLOG的LSN信息。8字节的无符号整数,与WAL机制有关。
(2)pd_checksum -保存页面的checksum值(9.3及之后版本)。
(3)pd_lower,pg_upper -pd_lower指向line pointers的末尾位置,pd_upper指向最新的heap tuple位置。
(4)pd_special -用于索引。如果此页面是表页面,指向页面的末尾。如果此页面是索引页面,指向特殊空间的开始(此空间根据索引的类型是BTree、GiST还是GIN保存特定的数据)。
在line pointers结尾到最新tuple开始之间的空间代表空闲空间或空洞。
为了确定表中某一个tuple的位置,PG内部使用tuple identifier(TID) 。TID由一组值构成:包括这个tuple页面的页编号block number,以及指向这个tuple的具体的偏移号offset number。即TID=block number + offset number。
下面我们具体看一个如何通过全表扫描/索引扫描来定位到需要的表记录。
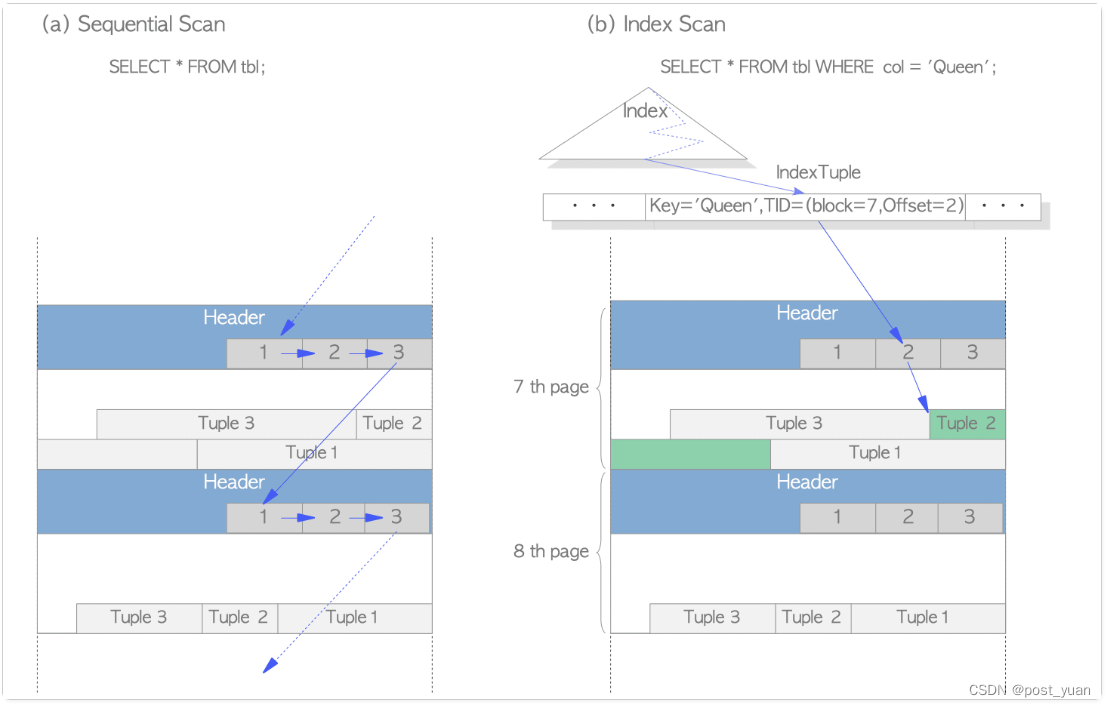
读取Heap Tuples
读取Heap Tuples通常有两种方式,按sequential scan和按B-Tree Index Scan,
- Sequential Scan - 通过扫描每个页面中所有line pointers来达到顺序读取所有页面中的tuples记录。
- B-Tree index Scan - Index文件包括Index tuples,每个Index tuple由一个index key和一个指向对应heap tuple的TID构成。根据key找到对应的Index tuple时,利用对应的TID来读取对应的heap tuple。比如在下图中,所获取的index tuple对应的TID为(block=7,offset=2),表示对应的heap tuple是表对应的第7个页面中的第2个tuple记录。
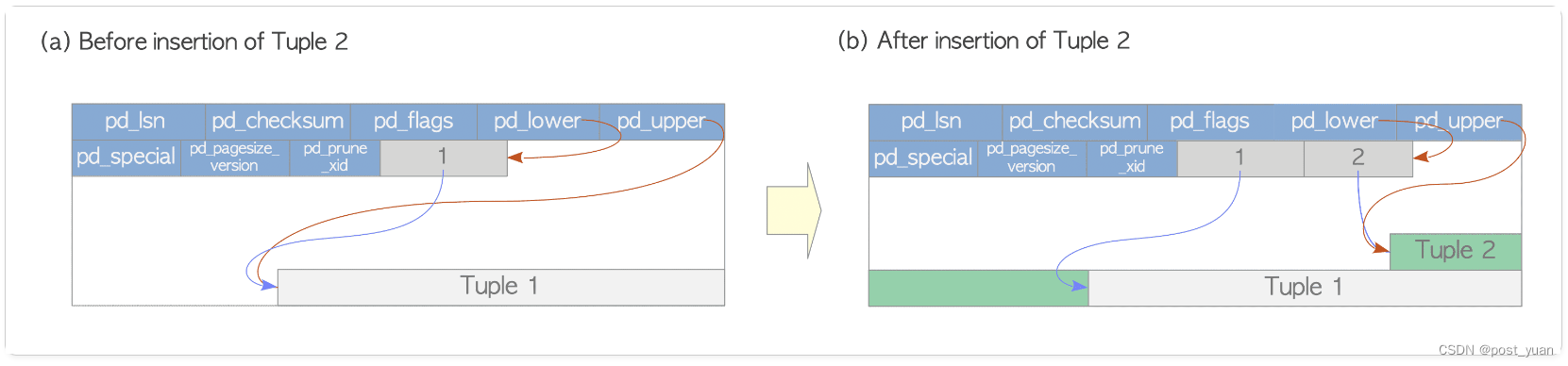
写入Heap Tuples
根据上述内容,我们知道写入heap tple是从一个页面的底部往上写,每写入一条heap tuple会同时写一个对应的指针即line pointer,同时也会更新其他相关的页面Head信息。具体的说,假如开始一个页面中只包含一条记录Tuple 1,当写入Tuple 2时,这个Tuple会被放置在Tuple 1前面。第2个line pointer被写入放置在第一个line pointer后面并指向Tuple 2。pd_lower会被更新指向第2个line pointer末尾,pd_upper会被更新指向Tuple 2的开始位置。其余的页面header数据如pd_lsn,pg_checksum,pg_flag等会相当的被写入对应的新值。















 3944
3944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











