






泛型
在定义类、接口、方法时,同时声明了一个或多个类型变量(如:<E>),称为泛型类、泛型接口、泛型方法,它们统称为泛型。
接下来,我们以ArrayList集合来认识一下泛型。
泛型类
首先,我们打开Java官方的API文档去看看。
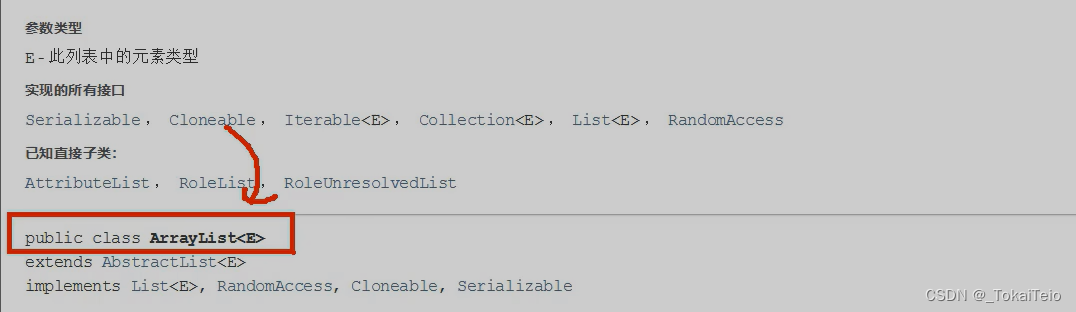
可见<E>,也就是说ArrayList是一个泛型类。
我们在IDEA中去写一个ArrayList类
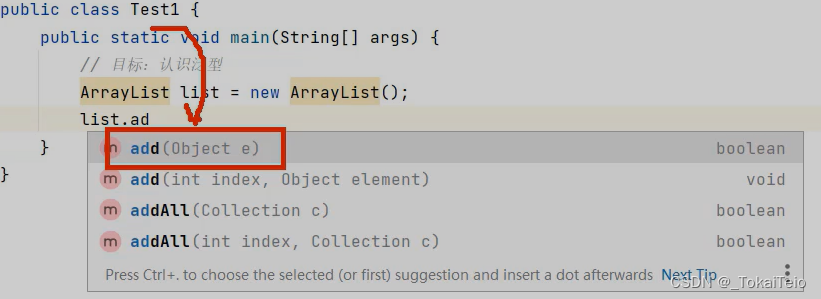
此时,我们没有为这个集合去使用他的泛型,然后去调用他添加数据的add方法,没有添加泛型时,add方法默认可以添加Object类型,也就是所有类型

如果我们想遍历list集合中的所有数据,现在get方法是根据索引去提取集合中的数据,返回的类型是Object类型。
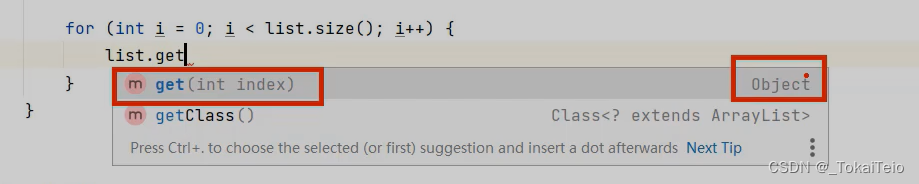
由于返回的是Object类型,所有不可以使用String类型的变量来接收。
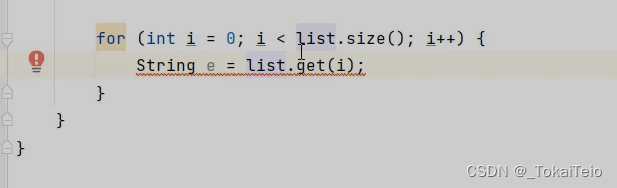
我们可以用强制转换来解决。 String e = (String) list.get(i);
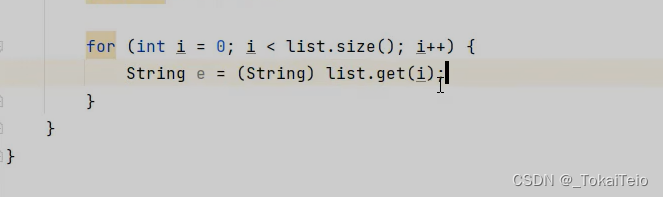
如果我们只想操作字符串类型的数据,我们就可以对集合使用泛型。
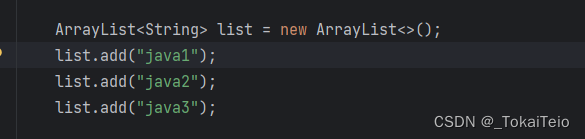
这个时候add方法只能添加String类型的数据。泛型可以在我们的编译阶段,也就是写代码的时候,约束我们能够操作的数据类型。
注意,从JDK1.7开始,后面的<>中的数据类型可以不声明。
泛型的原理
泛型的原理可以简单地描述为以下几个步骤:
-
定义泛型类型或方法:在代码中使用特殊的语法来定义一个泛型类型或方法。例如,可以使用尖括号 “<>” 来定义一个泛型类或方法。
-
使用泛型参数:在定义了泛型类型或方法后,可以在代码中使用泛型参数来代表一个具体的类型。这个泛型参数可以在类、方法或接口中使用。
-
编译时类型检查:在编译时,编译器会对泛型代码进行类型检查,确保泛型参数的使用是类型安全的。这意味着在使用泛型方法或类型时,编译器会检查传递的实际参数类型是否与泛型参数相符。
-
类型擦除:在编译后的代码中,泛型的类型信息会被擦除。这意味着泛型类型在运行时被擦除为它的上界或 Object 类型。
-
自动类型转换:在使用泛型时,编译器会自动进行类型转换,以保证类型的一致性。这样可以避免手动进行类型转换的繁琐工作。
总体而言,泛型的原理就是使用类型参数来代表一个具体的类型,编译器在编译时对泛型代码进行类型检查,并在运行时自动进行类型转换,以实现代码的重用和类型安全性。
泛型接口
泛型接口是一种接口,它使用泛型类型参数来定义一种可以支持多种类型的接口。通过使用泛型参数,可以在接口中定义与特定类型无关的方法或属性,从而提高代码的灵活性和可重用性。
在定义泛型接口时,需要使用泛型参数来表示接口中的类型。可以在接口名称后的尖括号 “<>” 中定义一个或多个泛型参数。例如,interface MyInterface<T> 表示一个有一个泛型参数的接口。
泛型接口的泛型参数可以用于方法的参数类型、方法的返回类型或接口的属性类型。在实现泛型接口时,可以指定具体的类型来替代泛型参数。
以下是一个示例:
// 定义一个泛型接口
interface MyInterface<T> {
T process(T input);
}
// 实现泛型接口
class StringProcessor implements MyInterface<String> {
public String process(String input) {
return input.toUpperCase();
}
}
// 使用泛型接口
public class Main {
public static void main(String[] args) {
MyInterface<String> processor = new StringProcessor();
String result = processor.process("example");
System.out.println(result); // 输出 "EXAMPLE"
}
}在上述示例中,MyInterface<T> 是一个泛型接口,使用泛型参数 T 来定义方法 process 的参数类型和返回类型。StringProcessor类实现了 MyInterface<String>,并实现了 process 方法。在主函数中,我们创建了一个 StringProcessor 的实例,并将其赋值给 MyInterface<String> 类型的变量 processor。然后,我们使用 processor 的 process 方法对字符串进行处理,并输出结果。
泛型接口允许我们在定义接口时不用具体指定类型,而是在实现接口时指定具体的类型。这样可以提高代码的灵活性和可重用性,使得接口能够处理各种类型的数据。















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









