






标准ASCII码的最高位作为奇偶校验位
ASCII码:8位,基本是英语国家字符
Unicode——是一种字符集规范,但是只指定了每个字符的“大小”,却没有规定每个字符所用字节数。
这就有了不同的Unicode实现——字符编码
UTF-8——Unicode Transformation Format ——8 bit
这个8bit——1B就是每个Unit大小,UTF-8使用1-4个Byte表示一个字符。而编码规则很简单:

前面的1的个数就是当前字符所用字节数目(若是一个字节,就没有1),因为UTF-8只使用1-4个字节表示Unicode字符,所以最多占用第一个字节的高位4个1(上图中最后一行),之后的规则是:在第一个字节后补一个0,在后面所有字节的开头补10,剩余部分(图中的x)填充真正的Unicode字符的二进制01流。但是考虑到”填不满“的情况,如字符A——0011 0001,绝对值就是11 0001这样填进一个字节中即图中第一行 —— 0xxxxxxx中最低位就多了个0,肯定不行。于是就采取这样的策略——低位对齐向高位填充,如果没有填充完,就补0。
BTW,其实也可以看到为什么UTF-8在一个字节时不使用01xxxxxx的形式——这样不是1到4个字节的标准都统一了吗?这当然是为了兼容ASCII码,1个字节不再统计使用1来标记当前字符所用字节个数,直接上个0,这样一来还是可以识别——只要检测到最高为0那就是占一个字节的字符,又能达到使用一个字节表示所有原ASCII的目的——美国或者说英语国家的小心思啊,哎。当然也可以想见,UTF-8这样的编码规则下,ASCII码的最高位是固定了的,不能够作为奇偶效验位了。
参考:ASCII,Unicode和UTF-8终于找到一个能完全搞清楚的文章了
当然,还经常看到UTF-16,其实看了UTF-8的实现以后,UTF-16也很好理解——基本单元为16bit——2 Byte,这样一个Unicode字符需要2个字节或者4个字节。
但是,可以看到,我们最常使用的记事本其实还有多种编码方式:
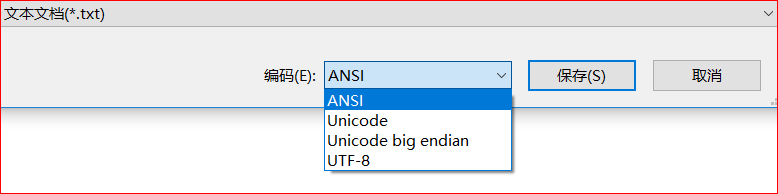
ANSI——选择该项,相当于告诉Windows自动采用当前Windows系统版本对应的编码方式:简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。即自动适配。
Unicode——可能会有人疑惑:之前不是说Unicode是字符集,不是编码规范吗——UTF-8或者UTF-16才是,为什么这里直接出现了和UTF-8平行的Unicode编码?其实这个Unicode指的并不是Unicode字符集标准,而默认指的另外一种Unicode实现——UCS-2标准,它直接用两个字节存字符的Unicode码,并且没有UTF-8或UTF-16标注前缀那些东西,直接放二进制流就好。
Unicode big endian——使用Unicode默认使用小端模式,这个选项是改为大端模式。
UTF-8就不用说了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









