







 本文详细解读了Unicode编码体系,包括Unicode的起源、Unicode字符集的分类(如BMP和辅助平面)、编码模型层次,以及表意文字和字符编码的相关概念。适合理解字符处理在跨语言环境中的关键作用。
本文详细解读了Unicode编码体系,包括Unicode的起源、Unicode字符集的分类(如BMP和辅助平面)、编码模型层次,以及表意文字和字符编码的相关概念。适合理解字符处理在跨语言环境中的关键作用。
Unicode编码详解(一):Unicode简介及其分类
本文为原创文章,转载请注明出处,或注明转载自“黄邦勇帅(原名:黄勇)
本文是对《C++语法详解》一书相关章节的增补,以增强读者对字符的理解,因为《C++语法详解》引用的标准过于老旧。
《C++语法详解》网盘地址:
https://pan.baidu.com/s/1dIxLMN5b91zpJN2sZv1MNg
本文摘自本人所作《Unicode编码和双向算法(bidi)详解》网盘地址
链接:https://pan.baidu.com/s/1LLKv22jQPmeba1XUCm0xoQ?pwd=a3x8
提取码:a3x8
有兴趣的读者可参阅本人所著《C++语法详解》一书,电子工业出版社出版,该书语法示例短小精悍,对查阅C++知识点相当方便,并对语法原理进行了透彻、深入详细的讲解,可确保读者彻底弄懂C++的原理,彻底解惑C++,使其知其然更知其所以然。此书是一本全面了解C++不可多得的案头必备图书。
由于本人能力有限,文中难免有错漏之处,望广大读者指出更正,不胜感激
一、基本知识
1、Unicode
Unicode又称为统一码、万国码、单一码,是国际组织制定的旨在容纳全球所有字符的编码方案,包括字符集、编码方案等,它为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台的要求。Unicode制定的内容非常多,为便于讲解,本文仅对Unicode字符集和Unicode编码方案重点讲解
2、ISO 10646与通用字符集(Universal Character Set,UCS)
历史上,除了Unicode在试图制定全球统一的通用字符集外,国际标准化组织 ( ISO )也在制定相应的标准,其中通用多八位编码字符集(Universal Multiple-Octet Coded Character Set ),简称通用字符集(Universal Character Set,UCS)就是由ISO制定的ISO 10646标准所定义的字符集,是与Unicode并行的标准。最初,ISO与Unicode各自开发各自的项目,后来,双方意识到世界不需要两个不兼容的字符集,于是,双方进行了整合,并使彼此制定的标准相互兼容,以使两者保持一致,直到现在,两个组织都存在,并且各自独立公布各自的标准,但二者基本是一致的,不过Unicode的知名度比UCS更大,应用也更广泛。直至2020年3月,Unicode的版本为Unicode 13.0.0
二、基本术语及专业基础知识
1、字符
本文所指的字符是文字和符号的总称,包括文字、数字、字母、标点符号、图形符号等。
2、表意文字和象形文字
表意文字是指将意思置换成形状来表示的文字的统称,所以,表意文字只要看到一个文字的形状就能理解想要表达的意思。表意文字有很多,如汉字、彝文、东巴文等。注意:象形文字属于表意文字中的一种
3、CJK统一表意文字(CJK Unified Ideographs)简介
CJK是中国(Chinese)、日本(Japanese)和韩国(Korean)的缩写,其目的是要把分别来自中文、日文、韩文、越文等,本质和意义相同、形状一样或稍异的表意文字于ISO 10646及Unicode标准内赋予相同编码。顾名思义,CJK能够支持中、日、韩三种文字。
三、计算机怎样处理字符
计算机只能处理二进制数字,那么怎样处理字符呢?可以想到的最简单的办法就是在字符和数字之间进行映射(编码),即,只需把字符想办法转换为二进制数字就行了,比如将字符“A”映射为10进制整数65,然后再将65直接映射为二进制数0100 0001,同理,可将“B”映射为66等,这样计算机就能处理字符A了,这里的“映射”在计算机中被称为“编码”,现在的计算机就是使用这种简单的思想处理字符的,只是其具体过程更复杂,至此,可能大家会产生出以下问题:
- 为什么要进行两次编码,直接编码为二进制不是更省事吗?其实这很简单,第一次编码准确的说其实就是为每个字符编了一个号,这个编号可方便人们使用,编号通常是10进制或16进制数,这样在以后指定某个字符时,可以直接使用数字来指定这个字符,很明显,直接使用二进制更不方便,比如,对于ASCII字符集,可以方便的使用65表示字符“A”,显然,使用二进制数0100 0001更不方便。
- 现在可能又有人会问了,为什么要使用编号来指定字符,而不是直接指定字符呢?比如,字符“A”,为什么要用编号65呢,直接用“A”不是更方便?对于英文字母这些常见的字符,直接使用字符当然更方便,但对于不是经常使用或者难输入、难显示、不显示的字符(比如积分号、求和符号、零宽度空格、回车换行符等),那么使用编号就更方便了。
- 一个二进制比特串,比如0100 0001,为什么不会被处理为整数65,而被处理为字符“A”呢?这与该比特串的类型有关,如果类型为整型,则计算机就会被解释为整数65,若为字符型,就会被解释为字符了,同理,若为浮点型,则会按浮点型的规则解释这个比特串。
四、Unicode编码模型(Unicode的编码思想)
Unicode编码被分为表1的几个层次

1
以上5个层次被称为Unicode编码模型,其实也是Unicode编码实现的步骤,下面分别对5个层次作一简介,后文会分别作详细介绍。
2、第一层:抽象字符表ACR(Abstract Character Reertoire)
ACR用于确定可以编码的字符的范围(即,确定支持哪些字符)
3、第二层:编号(编码)字符集CSS(Coded Character Set)
- 为每个字符编一个唯一的编号,从而形成一个庞大的“字符编号对”的集合,这个集合就是编号字符集CSS。比如,将大写字母A编号为整数65,B编号为66等,注意:Unicode字符的编号是使用16进制数表示的。需要注意的是,编号字符集仅仅规定了每个字符的编号,并未将编号转换为二进制串
- 翻译问题 Coded Character
Set通常翻译为“编码字符集”,但由于此步骤的特征,翻译为“编号字符集”更为贴切,还可避免与之后转换为二进制时的“编码”相混淆。
4、第三层:字符编码方式CEF(Character Encoding Form,或翻译为字符编码表)
把字符编号编码为逻辑上的码元序列(即,逻辑字符编码),注意:码元序列已经是一个二进制串了,常见编码方式有UTF-8,UTF-16,UTF-32,本文将此步骤的三种编码方式统称为Unicode编码。
5、第四层:字符编码方案CES(Character Encoding Scheme)
将逻辑上的码元序列映射为物理上的字节序列(即,物理字符编码),字节序列仍是一个二进制串,此步骤的主要目的是确字码元序列的字节序,字节序确定之后就可以直接由计算机处理、存储了,由于UTF-8编码不存在字节序问题,所以使用UTF-8编码的字符不需要经过此层。
6、第五层:传输编码语法TES(Transfer encoding Syntax)
将字节序列进一步编码处理,以适合于在网络中传输。此步骤不是本文的内容,不作讲解
五、抽象字符表ACR(Abstract Character Repertoire)
1、抽象字符表是Unicode支持的所有抽象字符的集合,用于确定字符的范围,即Unicode需要支持哪些字符。
2、字符表分为是封闭的字符表和开放的字符表,封闭的字符表不允许添加新的字符,比如ASCII字符表;开放的字符表允许不断的添加新的字符,Unicode字符表就是开放字符表,另外,代码页在一定程度上也是开放的。
六、编号(编码)字符集CSS(Coded Character Set)
本小节很重要,讲解了重要概念:编号、码点、码点空间
1、前文已讲过,此步骤的主要目的就是为字符编号(或称为编码),此步骤形成的“字符编号对”集合,称为编号字符集CSS
2、易混概念—字符集、字符编号、字符编码
字符集、字符编号、字符编码经常混用,这三者在本文中有一定区别,
- 字符集是字符与编号对的集合,此处是一种狭义的理解,因为,并不是所有编号都一定有字符与之对应,详见后文。
- 字符编号是对字符所分配的一个数值
- 字符编码是指将字符编号转换为二进制串的方法。
3、需要注意的是,编号有多种表示方式,可使用10进制、16进制整数表示,也可使用坐标的形式表示,坐标形式的编号,通常以二维表的形式来描述,如图1所示。在图1中,字符A的坐标为(0100,0001),其对应的二进制数值为0100 0001,转换为10进制为65,即,字符A的编号为10进制的65,二进制的0100 0001

4、编号空间(Code Space,或称为代码空间、码点空间)
- 码点空间是指设定的字符编号的上限值,该值通常大于等于抽象字符表中的字符数目,从0到上限值之间的范围称为码点空间,编号空间可以有多种描述方法,比如GB2312汉字的编号空间是94*94,ISO-8859-1的码点空间是256或28等,
- 注意,码点空间还被定义为字符集中所有码点(见下一小点)数量的总和,其实这两种定义方式基本是一致的,编号一般是非负整数,通常情况下,编号上限值就表示或者可通过其计算出码点数量总和
5、代码点(Code Point,简称码点)和码点值
- 码点是指码点空间中的一个位置,该位置所代表的数值就是码点值。注意,码点和码点值是有区别的(但是经常混用)
- 注意,码点值的总数(码点空间)通常是大于等于字符总数的,这意味着,并不是所有码点值都有一个字符与之对应。
- Unicode将码点大致分为:字符码点、非字符码点、保留码点。
- 字符编号与码点值的区别
字符编号是为字符所分配的码点,使用字符编号一定有一个字符与之对应,但码点值却不一定有与之对应的字符,可见,字符编号与码点之间是有区别的(但是经常混用)。
6、码点值的表示
码点值通常使用“U+十六进制数”的形式来表示,这样,就可以使用码点值来表示一个字符了(虽然有些码点值不一定有字符对应,但更直接),比如中文“汉”字的码点值是U+6C49等,通常将码点值 (如U+6C49) 称为Unicode字符,虽然这样不够准确,但现实中普遍都这样称呼。
7、易混概念----码点与码点值
“码点”和“码点值”是有区别的,码点指的是位置,码点值指的是值。但是,经常使用码点表示码点值,这应根据上下文来区别。
8、特别注意
- 在Unicode标准中,码点与字符并不一定总是一一对应的,在Unicode标准中,一个字符有可能有多个码点,比如U+51C9与U+F977都是同一个字符“凉”,这主要是为了兼容韩国字符集的标准。
- 也有可能由多个码点来表示一个字符,最常见的就是组合字符,比如,以下字符
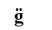
是由基本字符g
(U+0067)和U+0308(这个字符称为组合字符)组合而成,虽然以上字符是由两个Unicode码点组成,但现实中,人们会认为这是一个字符。以上由两个码点组合而成的字符称为“用户感知字符”(这是Unicode对字符的一种理解方法)。
9、Unicode字符集的概念
- 从以上讲解可见,字符集可理解为一张或多张二维表,表中行与列的交点(即,码点)分配一个编号(码点值),除了某些特殊码点值外,每个码点唯一对应于一个字符(注意,并不是每个码点值都有字符与之对应)。现实中,通常直接使用码点值代替字符编号,这样做虽然不够准确,但更直接。
- 本文所讲的Unicode字符集是指的码点空间和与之对应的抽像字符表所形成的集合,也就是说,Unicode字符集包含抽象字符表中的字符、与字符对应的码点、以及没有与字符对应的码点。
- 从以上讲解可以看到,Unicode字符集仅仅为每个字符分配了一个代码点(即,编号),但是,并不是每个代码点都有字符与之相对应(因为码点空间通常大于等于字符总数),若忽略掉没有对应字符的代码点,则Unicode字符集可简单理解为“为每个字符分配了一个数值”,总之,Unicode字符集与计算机并没有直接的联系。后文讲解的编码,主要目的是把码点转换为二进制串,这就牵涉到一些算法的问题,而且与计算机硬件也有一定的关系,所以,编码就会与计算机打交道了,因此,也需要知道一些计算机知识,特别是字节序。
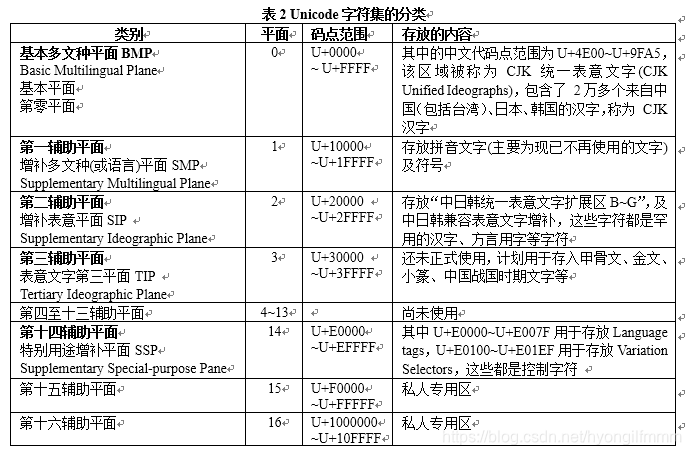
七、Unicode字符集的分类-----平面
1、平面
Unicode字符集被分成多个区,Unicode将“区”称为平面
2、Unicode字符集被划分为 17 个平面(即,17个区,编号为 0-16 ),且具有以下特点
- 每个平面有216 = 65536个代码点,因此,整个Unicode字符集共有17 × 65536 = 111 4112 个码点。
- 整个Unicode字符集的码点空间为U+000000 ~ U+10FFFF
- 每个平面的码点范围可表示为U+xx0000 ~ U+xxFFFF,其中xx表示16进制的0x00到0x10,比如,平面0的码点范围为U+000000 ~ U+00FFFF,平面2的码点范围为U+020000 ~ U+02FFFF,平面15的码点范围为U+0F0000 ~ U+0FFFFF
- 再次注意:并不是每个码点就一定对应有一个字符,因为,目前Unicode字符集中有很多码点都还未被使用。
3、17个平面又分为以下两类平面
①、基本多文种平面 ( Basic Multilingual Plane,BMP,或称为基本多语言平面、基本平面、第零平面、平面0)
- BMP平面位于第0平面,代码点范围为U+0000~U+FFFF
- BMP平面基本包含了世界上正在使用的常用字符,因此,平常使用的字符一般都位于BMP平面上。
- BMP平面中的中文代码点范围为U+4E00 ~ U+9FA5,该区域被称为CJK统一表意文字(CJK Unified
Ideographs),包含了 2万多个来自中国(包括台湾)、日本、韩国的汉字,称为 CJK (Chinese Japanese
Korean) 汉字。注意,象形文字属于表意文字的一种。 - 专用区域:U+E000 ~ U+F8FF(共6400个码点)是BMP平面的专用区域,被保留为专用。
- 代理区域:U+D800 ~ U+DFFF(共2048个码点)是BMP平面的代理区域,该区域在UTF-16编码时会使用到。
②、辅助平面(或称为增补平面)
- 辅助平面被留作扩展之用或用来表示一些特殊的字符(比如,不常用的象形文字或远古时期的文字等),这些字符通常被称为增补字符。
- 辅助平面位于平面1 ~ 16,即码点在U+010000 ~ U+10FFFF范围的字符都是增补字符
- 辅助平面是从Unicode 3.1 开始对BMP进行的扩展。
4、辅助平面又分为以下几类
①、第一辅助平面,也称为增补多文种平面(Supplementary Multilingual Plane,SMP)
位于平面1,用于存放拼音文字(主要为现已不再使用的文字)及符号,其代码点范围为U+10000 ~ U+1FFFF
②、第二辅助平面、也称为增补表意平面(Supplementary Ideographic Plane,SIP)
位于平面2,其代码点范围为U+20000 ~ U+2FFFF,用于存放“中日韩统一表意文字扩展区B ~ G”,及中日韩兼容表意文字增补,这些字符都是罕用的汉字、方言用字等字符。
③、第三辅助平面,又称为表意文字第三平面(Tertiary Ideographic Plane,TIP),还未正式使用,计划用于存入甲骨文、金文、小篆、中国战国时期文字等。
④、第四至十三辅助平面尚未使用
⑤、第十四辅助平面又称为特别用途补充平面(Supplementary Special-purpose Pane,SSP),代码点范围为U+E000 ~ U+EFFFF,其中U+E0000 ~ U+E007F用于存放Language tags,U+E0100 ~ U+E01EF用于存放Variation Selectors,这些都是控制字符
⑥、第十五和十六辅助平面是私人专用区,其代码点范围分别为U+F0000 ~ U+FFFFF,U+1000000 ~ U+10FFFF
5、表2为Unicode字符集的分类总结
本文作者:黄邦勇帅(原名:黄勇)


















 6813
6813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









