







1.Spark 源码相关目录介绍
spark 源码下载地址:https://github.com/apache/spark 选择自己需要阅读的分支(github网速慢可以到我这里下:https://gitee.com/zsmas10/sparksource),目前spark 版本已经到3.0.0,因为目前线上使用的主要版本为2.4, 所以当前阅读源码还是以2.4 为主。 下图为整个spark源码的目录结构:
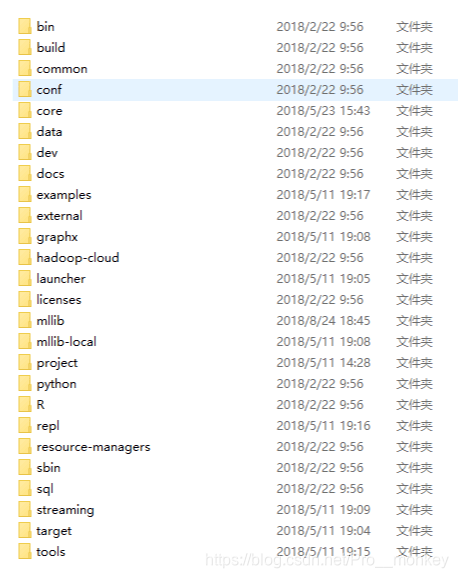
bin 目录下存放的spark运行shell 相关的脚本,包括pyspark,sprkR,spark-shell,spark-sql等脚本。通过其中一个pyspark脚本分析,如何启动这些脚本的。
- 查看pyspark脚本,pyspark最后通过 spark-submit pyspark-shell-main --name “PySparkShell” “$@”
- 跟踪spark-submit脚本分析,spark-submit 最终调用 spark-class org.apache.spark.deploy.SparkSubmit “$@”
- 跟踪spark-class 文件,关键代码 “ R U N N E R " − X m x 128 m − c p " RUNNER" -Xmx128m -cp " RUNNER"−Xmx128m−cp"LAUNCH_CLASSPATH” org.apache.spark.launcher.Main “$@” 其中RUNNER 调用java的命令, LAUNCH_CLASSPATH 为基础jar包
- 可以查看到最终调用的 org.apache.spark.launcher.Main 关键类,后续分析该类
接下来,简单介绍下几个主要的目录:
- core 目录下存放的spark的核心代码,java 和 scala两部分代码组成,核心模块
- data 目录下存放一些文本数据文件,用于mllib、graphx、streaming等模块测试用。
- mllib 机器学习相关模块代码
- R sparkR核心代码
- python pyspark 核心代码
- sql sparkSQL 核心代码
- streaming spark_streaming 核心代码
- sbin spark集群启动相关命令
2.Spark 集群启动相关脚本
主要开一下sbin 目录下start-master.sh脚本,该脚本主要启动spark集群中master角色。查看该启动脚本,其中关键性代码
"${SPARK_HOME}/sbin" /spark-daemon.sh start $CLASS 1 \
--host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT \
$ORIGINAL_ARGS
其中 $CLASS 为 org.apache.spark.deploy.master.Master 该类存在于spark-core 模块下。分析core下的包org.apache.spark.deploy.master.Master,Master类中查看main 方法
def main(argStrings: Array[String]) {
Thread.setDefaultUncaughtExceptionHandler(new
SparkUncaughtExceptionHandler( exitOnUncaughtException = false))
Utils.initDaemon(log)
val conf = new SparkConf
val args = new MasterArguments(argStrings, conf)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host,args.port, args.webUiPort, conf) rpcEnv.awaitTermination()}
Main 方法中主要有startRpcEnvAndEndpoint 方法,该方法主要创建 Master的 RPC环境。
首先看一下new SparkConf Master 启动的配置信息,会读取以 spark. 开头的系统属性,作为启动的参数。
而MasterArguments 很明显即为Master 启动创建的参数配置。
重点关注 RPC 环境的创建过程,因为SPARK_RPC通信环境,在Netty上封装了一层,以RpcEndpoint 为基础,会在后面单独介绍。
/**
* Start the Master and return a three tuple of:
* (1) The Master RpcEnv master rpc 环境
* (2) The web UI bound port master的 web ui 端口
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
val portsResponse = masterEndpoint.askSync[BoundPortsResponse](BoundPortsRequest)
// 返回三个值
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)}
在该方法中,创建一个rpc通信环境,传入参数 host,port 等参数,通过 RpcEnvFactory 工厂类创建,由于在在spark2.4 版本中,rpc通信中主要使用netty框架,因此RPC创建主要由 NettyRpcEnvFactory 实现,具体RPC通信如何实现,在后面的文档中说明。 在startRpcEnvAndEndpoint 方法中返回三个值,masterRpc rpcEndpoint用于和slave进行交互, webUI 及 portsResponse.restPort 。 最后在main方法中执行rpcEnv.awaitTermination() 开启守护进程,一直等待。
整个Master的启动流程图,如下: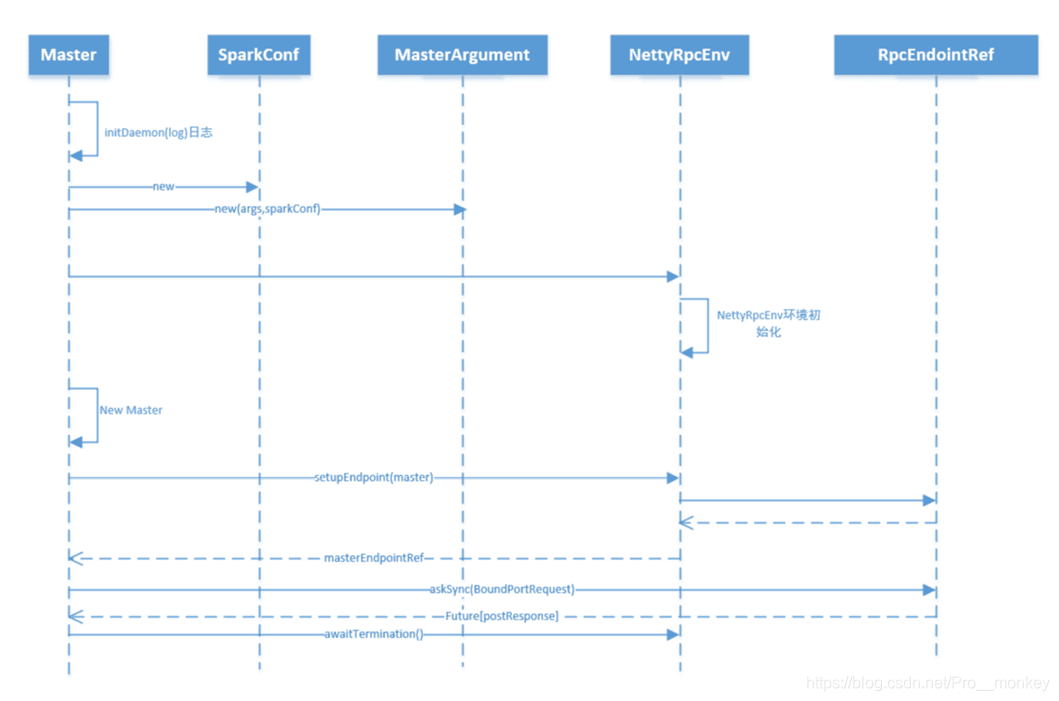
3.slave 启动脚本分析
查看start-slave.sh 与start-master.sh 类似,主要是通过spark-daemon.sh 脚本,
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS $WORKER_NUM \
--webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@"
slave 启动主要启用 org.apache.spark.deploy.worker.Worker 类,查看Worker 启动和Master 启动类似。
4.spark-daemon 分析
在 Master 和 Slave 启动的脚本中,有一个重要的脚本spark-daemon.sh, 启动过程中,都是调用 spark-daemon.sh start 启动对应的Master 和 Worker 类.
4.1 spark-daemon.sh脚本
spark-daemon 通过脚本名称可以知道该脚本Run a Spark command as a daemon 其中核心命令
case $option in
(submit)
run_command submit "$@"
;;
(start)
run_command class "$@"
;;
Master与Slave启动过程中,都是调用daemon start命令,可以看到脚本命令中,case "$mode"的选择。
case "$mode" in
(class)
execute_command nice -n "$SPARK_NICENESS" "${SPARK_HOME}"/bin/spark-class "$command" "$@"
;;
(submit)
execute_command nice -n "$SPARK_NICENESS" bash "${SPARK_HOME}"/bin/spark-submit --class "$command" "$@"
;;
(*)
echo "unknown mode: $mode"
exit 1
;;
esac
根据mode判断是调用spark-class还是调用spark-submit命令,由于在启动集群脚本中,基本都是class命令,所以调用spark-class文件
4.2 spark-class 脚本
观察上述命令,其中调用/bin/spark-class 脚本,运行相关的启动类。 在 /bin/spark-class 脚本中主要有两个部分
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
通过build_command 生成了要执行的shell命令; launcher模块中的 org.apache.spark.launcher.Main 下
if (className.equals("org.apache.spark.deploy.SparkSubmit")) {
try {
builder = new SparkSubmitCommandBuilder(args);
} catch (IllegalArgumentException e) {
printLaunchCommand = false;
System.err.println("Error: " + e.getMessage());
System.err.println();
MainClassOptionParser parser = new MainClassOptionParser();
try {
parser.parse(args);
} catch (Exception ignored) {
// Ignore parsing exceptions.
}
List<String> help = new ArrayList<>();
if (parser.className != null) {
help.add(parser.CLASS);
help.add(parser.className);
}
help.add(parser.USAGE_ERROR);
builder = new SparkSubmitCommandBuilder(help);
}
} else {
builder = new SparkClassCommandBuilder(className, args);
}
}
看出sparkSubmit 和其它的命令都是在这里生成具体的SparkClassComand,仔细跟踪代码,会调用一个SparkClassCommandBuilder的class中的buildCommand方法
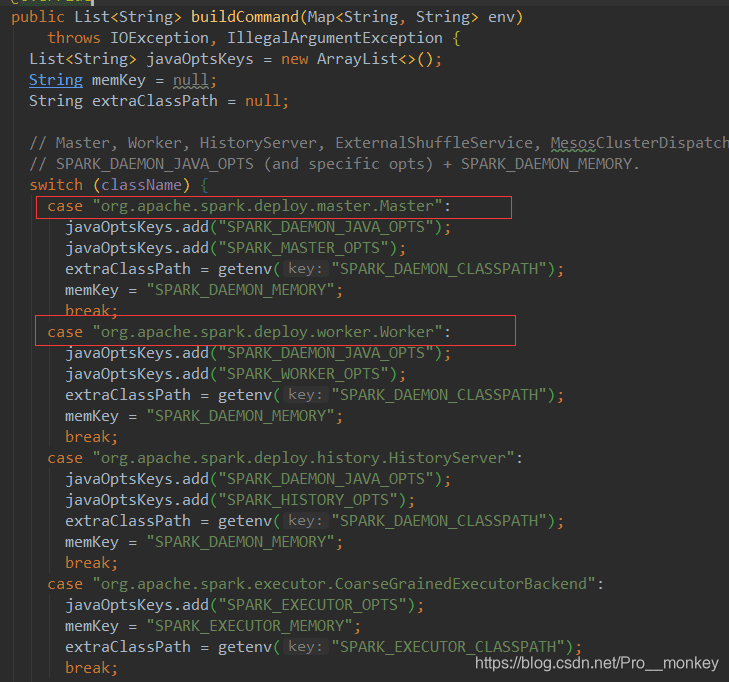
这里会根据不同的类生成具体的java执行方法。 在class类中完成了命令的组装之后;回到spark-class脚本中,通过 exec “${CMD[@]}” 启动进程执行org.apache.spark.launcher.Main返回的命令 可以看到Master启动脚本
"$sbin"/spark-daemon.sh start org.apache.spark.deploy.master.Master 1 \
--ip $SPARK_MASTER_IP --port $SPARK_MASTER_PORT \
--webui-port $SPARK_MASTER_WEBUI_PORT
这样就执行调用Master类的main方法,开启了Master的启动过程,整个Master的启动过程还算是比较清晰,在Master中还有一个关键方法 onStart()

看一下OnStart()这个方法,Master启动的逻辑在这个里面实现,但是onStart() 方法在什么时候调用,这个一直没有出现。同时在Master的main方法中也没有调用记录,那这个方法如何启动的?后面会研究分析Master启动与RPC通信。

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









