







《高级计算机视觉》期末样题汇总
《高级计算机视觉》期末样题汇总
说明:电子科技大学2022年研究生课程《高级计算机视觉》期末样题。
1. 游程编码
给出下列数据,写出按照行的方向的游程长度编码。
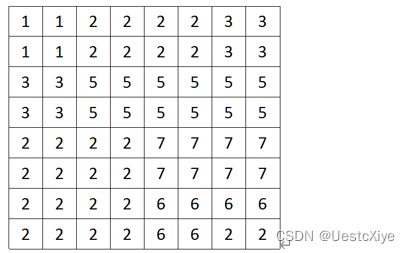
答:
(1,2),(2,4),(3,2)
(1,2),(2,4),(3,2)
(3,2),(5,6)
(3,2),(5,6)
(2,4),(7,4)
(2,4),(7,4)
(2,4),(6,4)
(2,4),(6,2),(2,2)
2. Shannon-Fano coding
(a)Complete the following table using the Shannon-Fano Algorithm.

(b) What is the entropy of this source, and in what units? Compare to the above result.

3. 计算
Suppose an alphabet consists of 6 symbols {a, b, c, d, e, f}, and the probability for each of the symbol is 1/6 (note, log2(3) = 1.585).
- What is the entropy for this set?
- Draw the Shannon-Fano tree for this set. What is the average bitrate?
- Draw the Huffman tree for this set. What is the average bitrate?
- How many bits would we need without compression, assuming fixed-length codewords? What is the compression ratio, compared to the Huffman tree?
答:
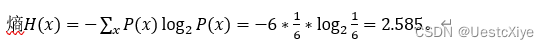
- Shannon-Fano tree:
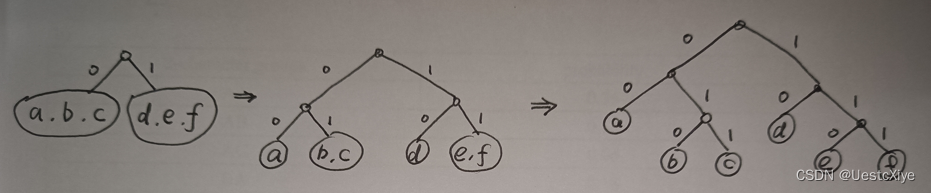
average bitrate=(2*2bit+4*3bit)/6=2.667bit.
- Huffman tree:
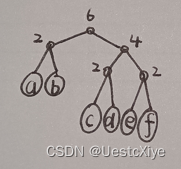
average bitrate=(2*2bit+4*3bit)/6=2.667bit.
- 假设码字长度固定,如果不进行压缩,我们需要6*3bit=18bit。与哈夫曼树相比,压缩比是18bit/16bit=1.125。
4. “checkerboard” image
Calculate the entropy of a “checkerboard” image in which half of the pixels are BLACK and half of them are WHITE.
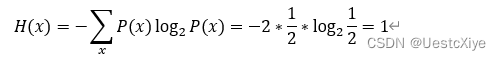
5. Huffman Coding
(a) Construct a binary Huffman code for a source S with three symbols A, B and C, having probabilities 0.6, 0.3, and 0.1, respectively. What is its average codeword length, in bits per symbol? What is the entropy of this source?
(b) Let’s now extend this code by grouping symbols into 2-character groups. Compare the performance now, in bits per original source symbol, with the best possible.
答:
(a)
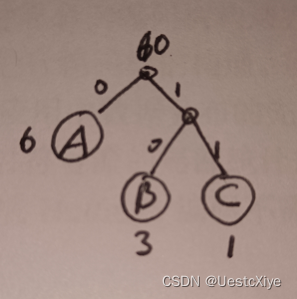
average codeword length=(2*2bit+1*1bit)/3=1.667bit.
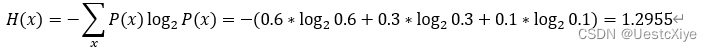
(b)
| 2-character groups | probability |
|---|---|
| AA | 0.36 |
| AB | 0.18 |
| AC | 0.06 |
| BA | 0.18 |
| BB | 0.09 |
| BC | 0.03 |
| CA | 0.06 |
| CB | 0.03 |
| CC | 0.01 |
Huffman tree:
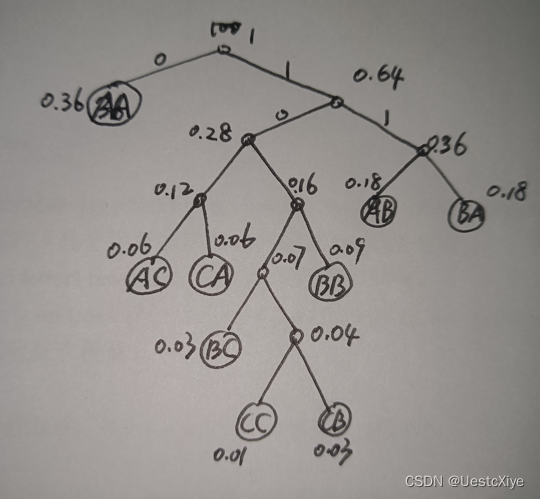
average codeword length=(1*1bit+2*3bit+3*4bit+1*5bit+2*6bit)/9=4bit

the best possible average codeword length is 2.5909bit, and the average codeword length of 2-character groups with Huffman coding is 4bit.
6. Adaptive Huffman Coding
a) What are the advantages of Adaptive Huffman Coding compared to the original Huffman Coding algorithm?
- 原始的Huffman算法给出了一种静态的编码树构造方案,要求在实际编码之前统计被编码对象中符号出现的几率,并据此进行编码树的构造。所以应用此方案时必须对输入符号流进行两遍扫描,而在大多数多媒体应用中数据分布的先前统计数据是不可行的。
- 另外,静态编码树构造方案不能对符号流的局部统计规律变化做出反应,因为它从始至终都使用完全不变的编码树。而自适应Huffman编码不需要事先构造Huffman树,而是随着编码的进行,逐步构造Huffman树。同时,这种编码方案对符号的统计也动态进行,随着程序的运行,同一个符号的编码可能发生改变(变得更长或更短)。
- 再者就静态编码在储存或传输Huffman编码结果之前,还必须先储存或传输Huffman编码树,自适应霍夫曼编码则不需要,这大大节省了内存开销。
b) Assume that the Adaptive Huffman Coding is used to code an information source S with a vocabulary of four letters (a, b, c, d). Before any transmission, the initial coding is a = 00, b =01, c = 10, d = 11. As in the example illustrated in the following figure, a special symbol NEW will be sent before any letter if it is to be sent the first time.
Adaptive Huffman Tree e after sending letters aabb

After that, the additional bitstream received by the decoder for the next few letters is 01010010101.
- What are the additional letters received?
- Draw the adaptive Huffman trees after each of the additional letters is received.
答:
接收到的后续的几个字母分别是:b(01),a(01),c(00 10),c(101)。
从图定位到01为b,然后b的权值+1,此时b的节点权值变为3>a(2),b与a交换位置。
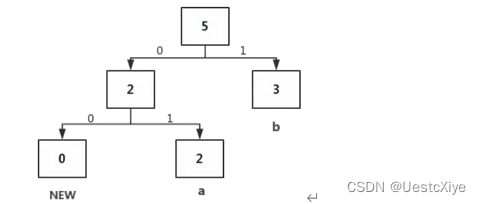
从上图定位到01为a,然后a权值+1,此时a的节点权值变为3=b(3),树的节点不做变动。
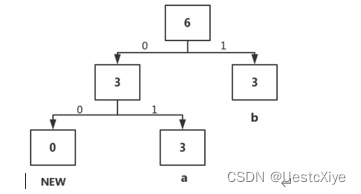
根据上图定位到00是new,意味着有新字符的加入,然后根据下面的10知道新加入的字符是c,然后用包含c和new的子树替换旧的new节点,然后将a的父节点的权值+1变为4>b(3),与b交换位置。
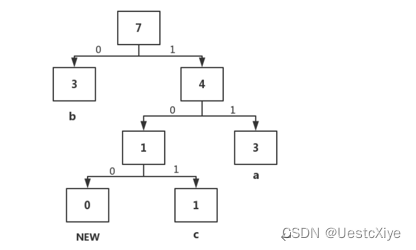
根据上图定位到c,然后将相应的节点权值分别+1,发现没有需要置换的节点和子树。
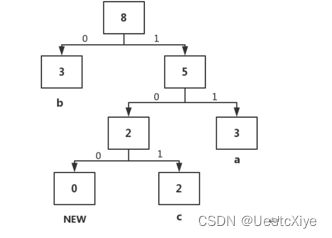
7. LZW
Consider the dictionary-based LZW compression algorithm. Suppose the alphabet is the set of symbols {0,1}. Show the dictionary (symbol sets plus associated codes) and output for LZW compression of the input 0110011.
答:
对于字符串0110011。初始字典为{0, 1}。
| 步骤 | 前缀 | 后缀 | 词 | 存在对应码 | 输出 | 码 |
|---|---|---|---|---|---|---|
| 1 | 0 | (, 0) | ||||
| 2 | 0 | 1 | (0, 1) | no | 0 | 2 |
| 3 | 1 | 1 | (1, 1) | no | 1 | 3 |
| 4 | 1 | 0 | (1, 0) | no | 1 | 4 |
| 5 | 0 0 (0, 0) no 0 5 | |||||
| 6 | 0 | 1 | (0, 1) | yes | ||
| 7 | 2 | 1 | (2, 1) | no | 2 | 6 |
| 8 | 1 | 1 | (1, 1) | yes |
输出:0,1,1,0,2,1。对应生成的码表:
| 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|
| (0, 1) | (1, 1) | (1, 0) | (0, 0) | (2, 1) |

8. LZW
Suppose we have a small 8-bit grayscale image, with all pixels equal to the same pixel value, say 113. Consider the performance of an LZW compression scheme. First initialize codes in the dictionary with pixel values, 0…255. Use 9-bit codes.
For a 4×4 uniform image made of pixel values which are all 113, how many bits will LZW (or WINZIP) use for a compressed version of the image? Explain in detail, using an LZW table. What is the compression ratio?
Hint: recall that the LZW coding algorithm is

答:
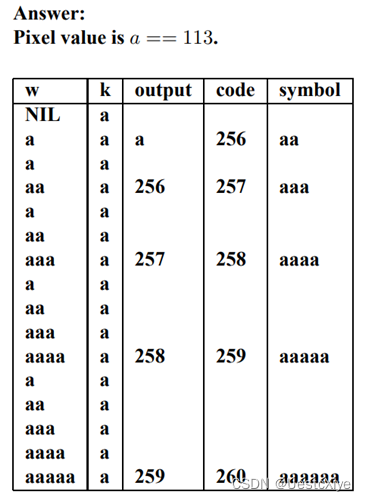
Thus we end up with 5 codes output (at 9 bits each), as opposed to 16 uncompressed 8-bit pixels. Therefore the compression ratio is 128/45 = 2.8444.
9. Huffman coding and Arithmetic coding
Suppose we wish to transmit the 10-character string “MULTIMEDIA”. The characters in the string are chosen from a finite alphabet of 8 characters.
(a) What are the probabilities of each character in the source string?
(b) Compute the entropy of the source string.
(c) If the source string is encoded using Huffman coding, draw the encoding tree and compute the average number of bits needed.
(d) If the source string MULTIMEDIA is now encoded using Arithmetic coding, what is the codeword in fractional decimal representation? How many bits are needed for coding in binary format? How does this compare to the entropy?
答:
(a)
P(A)=P(D)=P(E)=P(L)=P(T)=P(U)=1/10, P(I)=P(M)=1/5.
(b)
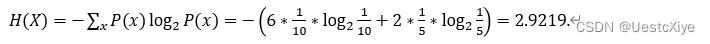
(c) Huffman tree:
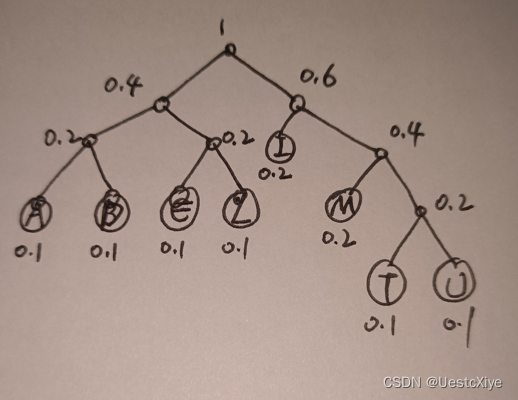
average bitrate=(1*2bit+5*3bit+2*4bit)/8=3.125bit
(d)
初始化:
A:[0,0.1), D:[0.1,0.2), E:[0.2,0.3), I:[0.3,0.5), L:[0.5,0.6), M:[0.6,0.8), T:[0.8,0.9), U:[0.9,1).
M:
A:[0.6,0.62), D:[0.62,0.64), E:[0.64,0.66), I:[0.66,0.7), L:[0.7,0.72), M:[0.72,0.76), T:[0.76,0.78), U:[0.78,0.8).
U:
A:[0.78,0.782), D:[0.782,0.784), E:[0.784,0.786), I:[0.786,0.79), L:[0.79,0.792), M:[0.792,0.796), T:[0.796,0.798), U:[0.798,0.8).
L:
A:[0.79,0.7902), D:[0.7902,0.7904), E:[0.7904,0.7906), I:[0.7906,0.791), L:[0.791,0.7912), M:[0.7912,0.7916), T:[0.7916,0.7918), U:[0.7918,0.792).
T:
A:[0.7916,0.79162), D:[0.79162,0.79164), E:[0.79164,0.79166), I:[0.79166,0.7917), L:[0.7917,0.79172), M:[0.79172,0.79176), T:[0.79176,0.79178), U:[0.79178,0.7918).
I:
A:[0.79166,0.791664), D:[0.791664,0.791668), E:[0.791668,0.791672), I:[0.791672,0.79168), L:[0.79168,0.791684), M:[0.791684,0.791692), T:[0.791692,0.791696), U:[0.791696,0.7917).
M:
A:[0.791684,0.7916848), D:[0.7916848,0.7916856), E:[0.7916856,0.7916864), I:[0.7916864,0.791688), L:[0.791688,0.7916888), M:[0.7916888,0.7916904), T:[0.7916904,0.7916912), U:[0.7916912,0.791692).
E:
A:[0.7916856,0.79168568), D:[0.79168568,0.79168576), E:[0.79168576,0.79168584), I:[0.79168584,0.791686), L:[0.791686,0.79168608), M:[0.79168608,0.79168624), T:[0.79168624,0.79168632), U:[0.79168632,0.7916864).
D:
A:[0.79168568,0.791685688), D:[0.791685688,0.791685696), E:[0.791685696,0.791685704), I:[0.791685704,0.79168572), L:[0.79168572,0.791685728), M:[0.791685728,0.791685744), T:[0.791685744,0.791685752), U:[0.791685752,0.79168576).
I:
A:[0.791685704,0.7916857056), D:[0.7916857056,0.7916857072), E:[0.7916857072,0.7916857088), I:[0.7916857088,0.791685712), L:[0.791685712,0.7916857136), M:[0.7916857136,0.7916857168), T:[0.7916857168,0.7916857184), U:[0.7916857184,0.79168572).
A:
A:[0.791685704,0.79168570416), D:[0.79168570416,0.79168570432), E:[0.79168570432,0.79168570448), I:[0.79168570448,0.7916857048), L:[0.7916857048,0.79168570496), M:[0.79168570496,0.79168570528), T:[0.79168570528,0.79168570544), U:[0.79168570544,0.7916857056).
最终的目标区间为:[0.791685704,0.7916857056),我们在这个区间内,任意选一个小数,便可以作为最终的编码小数。但是计算机只能识别0和1,所以我们再将小数转成二进制。我们的诉求是进行最短压缩,所以我们从[0.791685704,0.7916857056)选一个二进制表示最短的小数。这里我们选定0.791685705073178,二进制为:0.110010101010101111101010000101,去掉整数位0以及小数点后,最终的二进制编码为110010101010101111101010000101,长度为30位,平均比特率为3,十分接近熵(2.9219)。
10. Huffman coding and Arithmetic coding
Suppose the alphabet is [A;B;C], and the known probability distribution is PA = 0.5; PB =0.4; PC = 0.1. For simplicity, let’s also assume that both encoder and decoder know that the length of the messages is always 3, so there is no need for a terminator. How many bits are needed to encode the message BBB by Huffman coding? How many bits are needed to encode the message BBB by arithmetic coding?
Huffman tree:
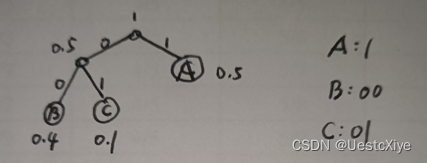
BBB需要6bit。
Arithmetic coding:
初始化:A:[0,0.5), B:[0.5,0.9), C:[0.9,1).
B:A:[0.5,0.7), B:[0.7,0.86), C:[0.86,0.9).
B:A:[0.7,0.78), B:[0.78,0.844), C:[0.844,0.86).
B:A:[0.78,0.812), B:[0.812,0.8376), C:[0.8376,0.844).
最终的目标区间为[0.78,0.844),在这个区间的任意一个小数都能作为BBB的编码,我们的诉求是进行最短压缩,所以我们从[0.78,0.844)选一个二进制表示最短的小数。这里我们选定0.8125,二进制为:0.1101,去掉整数位0以及小数点后,最终的二进制编码为1101,长度为4bit,比哈夫曼编码少2bit。
11. Arithmetic coding
Assume there is an information source with four characters and their frequencies as follows: A:(10%), B:(40%), C:(20%), and D:(30%). When an encoded message 0.514 is received, what the original string (3 characters) should be?
答:
初始化:
A:[0,0.1), B:[0.1,0.5), C:[0.5,0.7), D:[0.7,1).
因为0.514在E的区间,所以E是第一个字符,再对E的区间按比例划分:
A:[0.5,0.52), B:[0.52,0.6), C:[0.6,0.64), D:[0.64,0.7).
因为0.514在A的区间,所以A是第二个字符,再对A的区间按比例划分:
A:[0.5,0.502), B:[0.502,0.51), C:[0.51,0.514), D:[0.514,0.52).
因为0.514在D的区间,所以D是第三个字符。故原字符串为EAD。
12. 查询
假设一个图像检索系统数据库中有10个图像,其中包含“猫”的图像有5个。对于一个输入“猫”的查询图像Q,图像检索模型的目的是检索到数据库中所有的5个“猫”的图像。假设针对查询图像Q,小李设计了模型M1返回的10个图像的排序为{+,+,-,+,+,-,-,-,-,+}, 小张设计了模型M2返回的10个图像的排序为{+,-,+,+,+,+,-,-,-,-},[注:+表示是“猫”的图片,-表示不是“猫”的图片]。试画出两位同学设计的检索模型的准确率-召回率曲线(Precision-Recall Curve),并判断哪位同学设计的模型更准确一些并说明原因。
[注: 准确率与召回率的定义分别为:Precision = #relevant / #returned; Recall = #relevant / #total relevant]
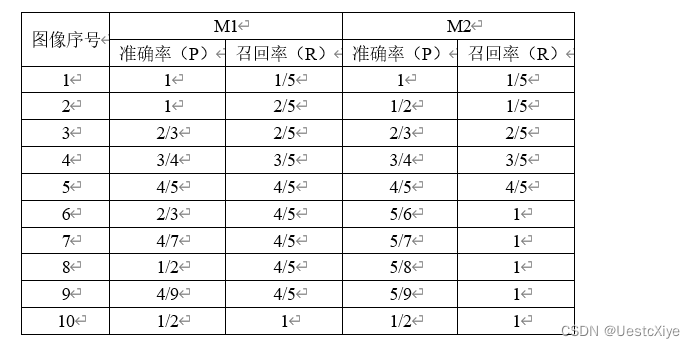
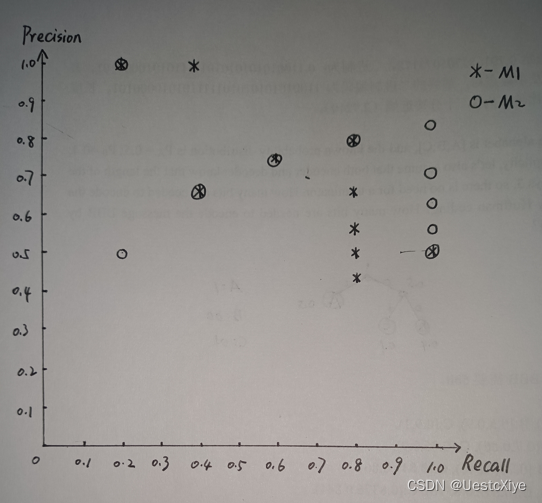
M2的PR曲线完全包住了M1的PR曲线,则可断言M2的性能优于M1。
13. 查询
分别用“√ ”和“×”代表与查询相关和不相关的文档:
(a) 假设针对查询1,有5个相关的文档,搜索引擎检索对查询1的排序(Ranking #1)结果为√×√××√××√√,求其平均准确率(Average Precision);
(b) 假设针对查询2,有3个相关的文档,搜索引擎对查询1的排序(Ranking #2)结果为×√××√×√×××,求其平均准确率(Average Precision);
(c) 求该搜索引擎对两次查询的均值平均准确率(Mean Average Precision)。
(a)
| 查询序号 | 准确率(P) |
|---|---|
| 1 | 1 |
| 2 | 1/2 |
| 3 | 2/3 |
| 4 | 1/2 |
| 5 | 2/5 |
| 6 | 1/2 |
| 7 | 3/7 |
| 8 | 3/8 |
| 9 | 4/9 |
| 10 | 1/2 |
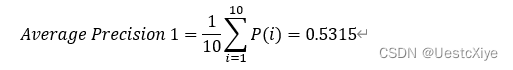
(b)
| 查询序号 | 准确率(P) |
|---|---|
| 1 | 0 |
| 2 | 1/2 |
| 3 | 1/3 |
| 4 | 1/4 |
| 5 | 2/5 |
| 6 | 1/3 |
| 7 | 3/7 |
| 8 | 3/8 |
| 9 | 3/9 |
| 10 | 3/10 |
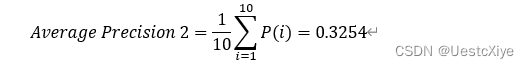
(c)
Mean Average Precision=1/2 (Average Precision 1+Average Precision 2)=0.4284.
14. 傅立叶变换
傅立叶变换是对图像的频率域信息进行操作的一种重要方法,在对图像进行傅立叶变换后,幅度谱和相位谱分别包含图像的什么信息?如果舍弃相位谱会对图像造成什么影响?如果将幅度谱均匀衰减到原幅度谱的一半,并和相位谱一起重建图像,和原图像相比会有什么变化?
答:
f(x)为连续可积函数,其傅立叶变换定义为:
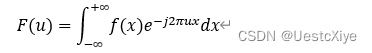
通常f(x)的傅立叶变换为复数,可有通用表示式为:F(u)=R(u)+jI(u),R(u)、I(u)分别称为傅立叶变换F(u)的实部和虚部。
其中,|F(u)|=√(R^2 (u)+I^2 (u))称为 f(x)的幅度谱,Φ(u)=arctan (I(u))/R(u) 称为 f(x)的相位谱。
图像的幅度谱代表的是图像各像素点的亮度信息,即该像素应该显示什么颜色。幅度谱虽然存储了各个像素点的幅值信息,但是原像素点的位置已经被打乱,所以仅凭幅度谱是没有办法重构原图像的。幅度谱的中心是低频部分,越亮的地方代表的幅度越大。
相位谱记录的是所有点的相位信息,它保留了图像的边缘以及整体结构的信息,没有它将无法从品频谱还原出原图像。
幅度谱只包含图像的灰度信息,对图像内容起决定性作用的是图像的相位谱。利用相位谱记录的位置信息和幅度谱记录的亮度信息,就可以用双谱重构的方法恢复出原图像。
舍弃相位谱,只用幅度谱逆傅里叶变换出来的图像只有一个亮点,无法恢复出原图像。
如果将幅度谱均匀衰减到原幅度谱的一半,并和相位谱一起重建图像,和原图像相比,亮度为原图像的一半。
15. 积分图像
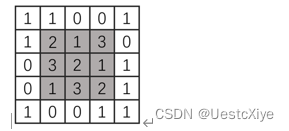
下图展示了5×5大小的图像像素矩阵。
(1)请用文字解释积分图像的定义,并说明其与传统图像表示的区别与特点;
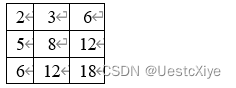
(2)计算该图像中阴影3×3区域对应的积分图。
答:
对于一幅灰度的图像,积分图像中的任意一点(x,y)的值是指从图像的左上角到这个点的所构成的矩形区域内所有的点的灰度值之和,表示如下:
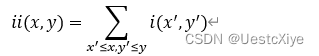
传统图像的每个点的灰度值为该像素本身灰度i(x,y),而积分图的每个点的灰度值为ii(x,y)。积分图算法由Crow在1984年首次提出,是为了在多尺度透视投影中提高渲染速度。积分图算法是一种快速计算图像区域和以及图像区域平方和的算法。它的核心思想就是对每一个图像建立起自己的积分图查找表,在图像处理的阶段就可以根据预先建立积分图查找表直接查找从而实现对均值卷积的线性时间计算。做到了卷积执行的时间与窗口大小无关。
该图像中阴影3×3区域对应的积分图:
















 3044
3044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











