







写在前面
最近翻看了博客的草稿,很久很久之前准备写关于函数装饰器的总结……今天终于有时间动手写,本来想接着以前的草稿,结果看了后,对内容非常不满意……全部删了……
主要是那时对函数装饰器的理解还是一知半解,所以不好写,也就拖着没完成。赶上肺炎疫情严重而变得超长的假期,我终于把函数装饰器,以及函数装饰器依赖的闭包技术给看懂了……于是,现在便是最好的总结时机。
引入函数装饰器的目的
我第一次接触这个概念,是使用wxpy这个库的时候,这个库有个register()的装饰器,功能是负责从网页版的微信接收消息,并返回通知。然后,我们自定义的函数,比如收到消息后,把消息打印或是转发给谁,都由这个register()装饰。
采取这种模式,对wxpy包设计者和作为使用者的我们,都有好处
- wxpy设计者,并不需要我们要设计怎样的函数(操作),需要多少参数,他统统不用管,他只负责把必须的操作封装起来就好
- 对于使用包的我们来说,更有好处,我们根本不需要知道怎么获取微信收到的信息,就能自定义各种收到消息的操作
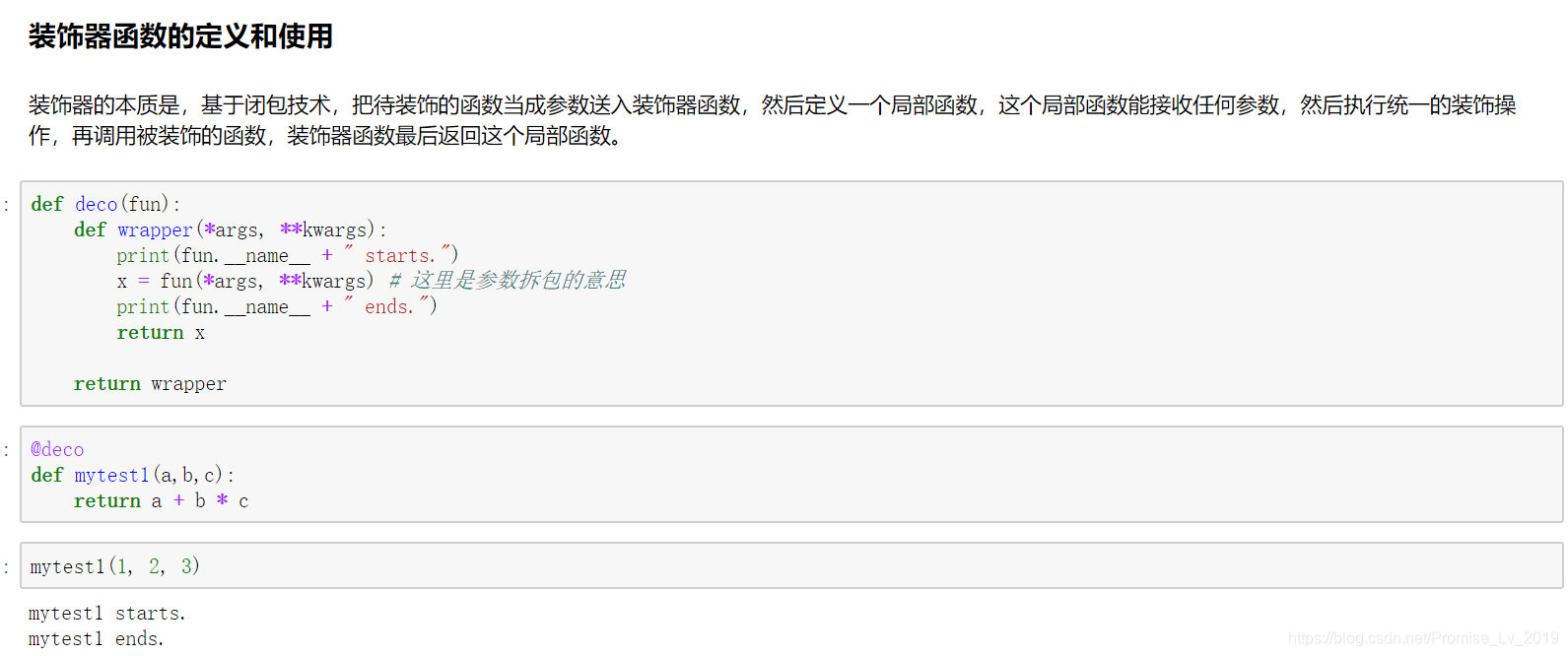
函数装饰器的定义
def deco(fun): # 装饰器只有一个参数,就是待装饰的函数
def wrapper(*args, **kwargs):
print(fun.__name__ + " starts."
x = fun(*args, **kwargs) # 拆分实参
print(fun,__name__ + " ends."
return x # 确保wrapper连返回值也保持跟fun一致
return wrapper
# 函数修饰的使用
def myfun1(a,b):
return a +b
myfun1_deco = deco(myfun1)
代码分析
- myfun1_deco 最后指向 wrapper
- wrapper(*args, **args), 作用跟它的名字一样,包裹,它利用了python匹配任意位置实参和关键字实参的技术, 保证它的参数跟 myfun1一致
- 返回值也保持一致
- 唯一不同的是, wrapper 的行为,多出了我们希望它输出函数开始和结束的时间。
- 使用装饰器好处显而易见,我们不用修改已有的函数定义,便能给他们增加新功能。
更方便的写法
@deco
def myfunc1(a, b, c):
return a + b * c
接下来直接调用 myfunc1(1, 2, 3), 就会附带输出函数开始和结束的标志。
实例代码
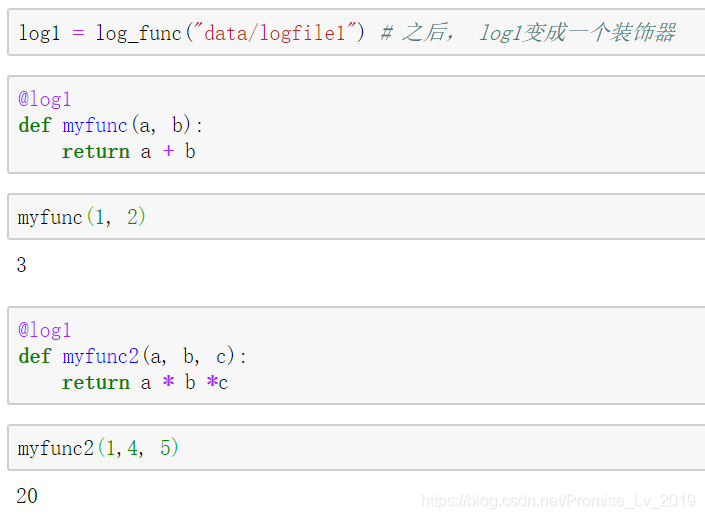
实用场景:把函数的调用轨迹输入日志
def log_func(fname): # 负责指定文件
def deco(fun):
def wrapper(*args, **kwargs):
logfile.write(fun.__name__ + " starts.\n")
logfile.flush() # 冲刷缓存区,让文件写入
x = fun(*args, **kwargs) # 拆分实参
logfile.write(fun.__name__ + " ends.\n")
logfile.flush()
return x # 保持跟被装饰函数一样
return wrapper
if fname[-4: ] != ".log":
fname = fname + ".log"
logfile = open(fname, "w")
return deco
对应的日志文档

闭包技术
这里非常简略的提及。
任何变量都有生存期,比如一个定义在函数内部的变量,当函数调用完成,这个变量就消失了。
闭包技术,就是说,一个变量是定义在局部的,然而,当他结束调用,这个变量依旧存在,可以使用,比如上面 logc_fname(fname) 这个函数, 我们在这个内部建立了 写文件对象 logfile, 之后装饰了函数后,这个局部变量一直可以用。这就是基于闭包技术。
不过,仔细观察,一切都不复杂也应该这么设计,因为 logc_fname 返回的是一个它里面定义的局部函数啊!它有可能使用到相应的局部变量, 如果不能让这个被返回的函数使用它对应的的局部变量,该函数就运行不了,一切也就失去意义了。














 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









