







一、总述
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎。它能从项目一开始就赋予你的数据以搜索、分析和探索的能力,这是通常没有预料到的。 它存在还因为原始数据如果只是躺在磁盘里面根本就毫无用处。
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
二、索引
1.建立索引
PUT person
{
"settings" : {
"number_of_replicas": 1,
"number_of_shards": 1,
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
, "mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
2.删除索引
DELETE person
3.查询索引
GET person
4.查询所有索引
GET _cat/indices?v
三、索引别名alias
创建别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "person",
"alias": "person1"
}
}
]
}
通配符创建别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "person-*",
"alias": "person1"
}
}
]
}
删除别名
POST /_aliases
{
"actions": [
{
"remove": {
"index": "person",
"alias": "person1"
}
}
]
}
四、文档
1.添加单个文档
POST person/_doc/1
{
"name":"jack",
"age":18
}
2.不指定id添加文档
POST person/_doc
{
"name":"jack",
"age":18
}
3.批量添加文档(不会分词)
POST _bulk
{"index":{"_index":"person","_id":"4"}}
{"doc":{"name":"jack1"}}
{"index":{"_index":"person","_id":"4"}}
{"doc":{"name":"jack2"}}
4.修改文档
# 根据id直接修改,会使其他的域清空,比如age
PUT user/_doc/1
{
"name":"jack1"
}
# 指定修改某个field,其他的field不受影响
POST person/_update/1
{
"doc":{
"name":"rose"
}
}
- 为什么执行某个field使用POST请求,而不是PUT请求
最主要的原因是PUT方法具有幂等性,局部更新不满足幂等性(多次执行更新具有相同结果)。假如某个文档具有name和age两个字段,使用PUT进行全部更新,则每次更新的结果都会一样,具有幂等性。如果使用PUT进行局部更新name,期间age被另外一个更新过,那么多次更新的结果不一致,不满足幂等性。
5.删除文档
DELETE user/_doc/1
五、查询
- 通过id
GET person/_doc/6
- 通过ids
GET person/_search
{
"query": {
"ids": {
"values": [1,6]
}
}
}
- match匹配
#查询所有
GET person/_search
{
"query": {
"match_all": {}
}
}
#匹配查询,会将查询条件分词
GET person/_search
{
"query": {
"match": {
"address": "湖北省"
}
}
}
#boolmatch,直接匹配query里面的条件且同时满足
GET person/_search
{
"query": {
"match": {
"address": {
"query": "湖北 我爱武汉",
"operator": "and"
}
}
}
}
#boolmatch,直接匹配query里面的条件,一个满足就行
,GET person/_search
{
"query": {
"match": {
"address": {
"query": "省 我爱武汉",
"operator": "or"
}
}
}
}
#multi_match多域查询,查询条件会分词
GET person/_search
{
"query": {
"multi_match": {
"query": "我爱湖北",
"fields": ["address","job"]
}
}
}
- term查询
#查询条件不分词
GET person/_search
{
"query": {
"term": {
"address": {
"value": "河南省"
}
}
}
}
- prefix查询
#prefix
#词条以指定的value为前缀的
GET emp/_search
{
"query": {
"prefix": {
"address": {
"value": "武"
}
}
}
}
- wildcard查询
#wildcard
任意个数
GET emp/_search
{
"query": {
"wildcard": {
"address": {
"value": "武汉*"
}
}
}
}
确定个数
GET emp/_search
{
"query": {
"wildcard": {
"address": {
"value": "武汉??"
}
}
}
}
- range查询
//查询某一区间的数值 (10,20)
POST person/_search
{
"query": {
"range": {
"age": {
"gte": 32,
"lte": 36
}
}
}
}
- 分页查询
POST z/_search
{
"from": 2,
"size": 2,
"query": {
"match_all": {
}
}
}
- must:求交集
must not:取反
should:并集
#must 多个查询单元必须同时匹配
GET z/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"address": {
"value": "湖北省"
}
}
},
{
"range": {
"balance": {
"gte": 5600,
"lte": 6000
}
}
}
]
}
}
}
#must not 多个查询单元必须都不匹配
GET z/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"address": "湖北湖南"
}
},
{
"range": {
"age": {
"gte": 30,
"lte": 36
}
}
}
]
}
}
}
#should:多个查询单元满足其中一个条件即可
GET z/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"address": "湖北湖南"
}
},
{
"range": {
"age": {
"gte": 30,
"lte": 36
}
}
}
]
}
}
}
- 高亮查询
#单个域的高亮
GET z/_search
{
"query": {
"match": {
"address": "湖北教育"
}
},
"highlight": {
"fields": {
"address": {}
},
"pre_tags": "<font color='red'>",
"post_tags": "</font>"
}
}
#多个域的高亮
GET z/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"address": "湖北"
}
},
{
"match": {
"email": "hattiebond"
}
}
]
}
},
"highlight": {
"fields": {
"address": {},
"email": {}
},
"pre_tags": "<font color='red'>",
"post_tags": "</font>"
}
}
- 条件查询
GET shopping/_search?q=category:iPhone
六、JavaApi整合Elasticsearch
1.回顾springboot
- 使用maven创建springboot工程
- 首先锁定spirngboot版本
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
- 其次要配置web启动类依赖,这样@SpringBootApplication才能够启动
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
- 创建启动类springApp,使用注解@SpringBootApplication,main方法中添加SpringApplication.run(esApp.class,args);
-
使用springboot的单元测试,则test.class需要和springApp在同一级(不是同一个)的文件夹下。并且加上@SpringBootTest注解
-
使用springBoot注解自动装配,不能new示例,一旦new之后,该实例就是null。即使是本类下,也不能new

-
避免硬编码,可以将一些字段添加到配置文件中,通过配置类实现注入,比如elasticsearch的参数可以通过配置类引入
- yml文件如下(注意空格):
elasticsearch:
host: 127.0.0.1
port: 9200
userName: elastic
passWord: elastic
- es依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.2</version>
</dependency>
- java代码如下,设置过账户和密码:
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class getBean {
private String host;
private int port;
private String userName;
private String passWord;
public String getUsername() {
return userName;
}
public void setUsername(String userName) {
this.userName = userName;
}
public String getPassword() {
return passWord;
}
public void setPassword(String passWord) {
this.passWord = passWord;
}
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
@Bean
public RestHighLevelClient client() {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(userName, passWord)); //es账号密码
return new RestHighLevelClient(
RestClient.builder(
new HttpHost(host, port)
).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
}));
}
}
- 使用spring的ioc管理bean实例,在进行注入时,加上@Autowired时不能将属性变为static,图中为错误示范

七、linux安装es。注意:阿里云启动es会占用很大的cpu,并且会使服务器宕机,不清楚为什么
- 首先linux下不能使用root用户运行es,需要创建一个新用户
adduser esuser #创建esuser用户
su esuser #切换到esuser用户
- es靠后的版本自带jdk,使用虚拟机的jdk1.8不能满足需求,所以需要修改配置,改为es自带的jdk版本。
- 进入elasticsearch-env的配置文件
cd /usr/software/elasticsearch-7.15.2/bin
vi elasticsearch-env
- 在文件第一行添加:
JAVA_HOME="/usr/software/elasticsearch-7.15.2/jdk"

八、使用kibana导入csv文件
- 步骤:Machine Learning -> import data ->选择本地文件
- 如果csv文件存在中文,导入的时候会乱码,可以使用notepad++打开csv文件,将编码格式转换为UTF-8,再重复上述步骤

九、docker安装es和kibana
# 启动es
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" --name es elasticsearch:7.6.2
# 启动kibana
docker run --name kibana -e ELASTICSEARCH_URL=http://127.0.0.1:9200 -p 5601:5601 -d kibana:7.6.2
- 注意:此时访问kibana可能会提示这种: Kibana server is not ready yet,解决办法如下:
- 首先查看es的容器内部网络
[root@iZwz9bbmlfbm8e53rmdyldZ dev-conf]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b289648aa942 kibana:7.6.2 "/usr/local/bin/dumb…" 13 minutes ago Up 3 minutes 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
14f84950ce5c elasticsearch:7.6.2 "/usr/local/bin/dock…" 13 minutes ago Up 13 minutes 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp es
[root@iZwz9bbmlfbm8e53rmdyldZ dev-conf]# docker inspect 14f84950ce5c
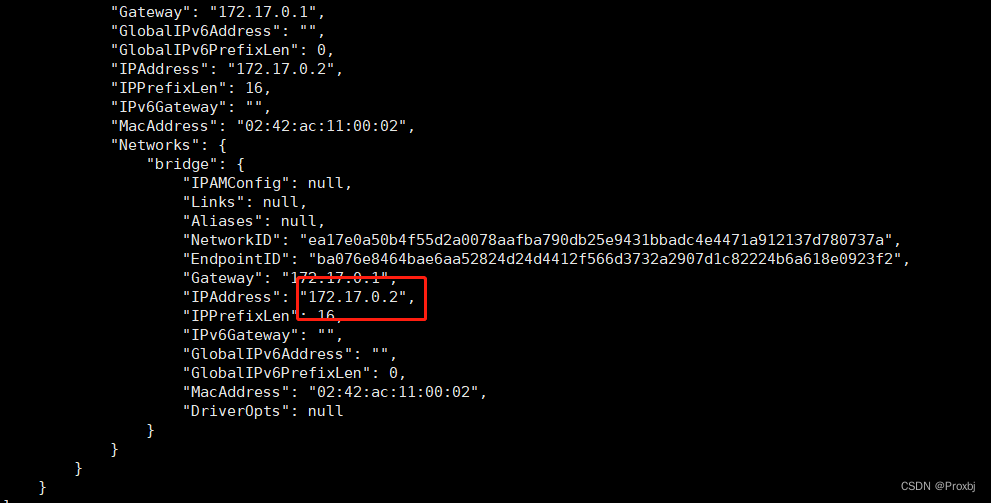
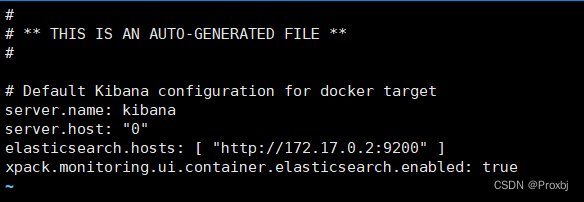
- 进入kibana容器的config的kibana.yml,将http://elasticsearch:9200替换为容器内部的ip(本机的ip也行)
十、API操作
- 索引操作API
@Autowired
private RestHighLevelClient client;
/**
* 测试创建索引
*/
@Test
void createIndex() throws IOException {
// 索引客户端
IndicesClient indicesClient = client.indices();
// 创建索引的请求
CreateIndexRequest indexTest = new CreateIndexRequest("index_test");
CreateIndexResponse createIndexResponse = indicesClient.create(indexTest, RequestOptions.DEFAULT);
boolean acknowledged = createIndexResponse.isAcknowledged();
if (acknowledged){
System.out.println("success");
}else{
System.out.println("error");
}
}
/**
* 测试查询索引
*/
@Test
void getIndex() throws IOException {
IndicesClient indicesClient = client.indices();
GetIndexRequest indexTest = new GetIndexRequest("index_test");
GetIndexResponse getIndexResponse = indicesClient.get(indexTest, RequestOptions.DEFAULT);
Map<String, Settings> settings = getIndexResponse.getSettings();
System.out.println(settings);
}
/**
* 测试删除索引
*/
@Test
void delIndex() throws Exception{
IndicesClient indices = client.indices();
DeleteIndexRequest indexTest = new DeleteIndexRequest("index_test");
AcknowledgedResponse delete = indices.delete(indexTest, RequestOptions.DEFAULT);
if (delete.isAcknowledged()){
System.out.println("success");
}else{
System.out.println("error");
}
}
- 文档操作API
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-document-index.html















 2783
2783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









