







上一个python爬虫爬取百度百科有关python词条的100个页面的例子,这次我们要爬取的是糗事百科的24小时热门页面的每个段子的内容,点赞数和评论数,对于爬取糗事百科和百度百科的主要不同在于糗事百科需要我们模拟浏览器登陆,普通的登陆并不会返回我们想要的内容,我们一起探讨一下。
我们先按照爬取百度百科的方式获取一下糗事百科的页面信息
import urllib.request
url='http://www.qiushibaike.com/hot/'
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)我们会得到如下的错误信息:
http.client.RemoteDisconnected: Remote end closed connection without response
这个错误信息告诉我们服务器不响应我们,我们不能与服务器建立连接。
这个主要是由于糗事百科添加了Header的检验,我们得通过模拟浏览器的形式进行连接,只需要我们在request的时候添加一个header就可以正常爬取了
import urllib.request
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36r)'
header = {'User-Agent': user_agent}
url='http://www.qiushibaike.com/hot/'
request=urllib.request.Request(url,headers=header)
response=urllib.request.urlopen(request)
print(response.getcode())结果正常运行:

接下来的就是我们的爬虫程序了,我在start函数内返回了两个list型数据实现词条和点赞数评论数的匹配,朋友们也可以试试用二维函数来实现这样的匹配,废话不多说,上代码。
import re
import urllib.request
from bs4 import BeautifulSoup
import urllib.parse
class Spider(object):
def __init__(self):
self.user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36r)'
self.headers = {'User-Agent': self.user_agent}
def start(self,url):
try:
request=urllib.request.Request(url,headers=self.headers)
response=urllib.request.urlopen(request)
data=response.read()
datas=[]
dataa=[]
soup = BeautifulSoup(data, 'html.parser', from_encoding='utf-8')
links = soup.find_all('div',class_='content')
Links=soup.find_all('i',class_='number')
for link in links:
datas.append(link.find('span').get_text())
for link in Links:
dataa.append(link.get_text())
return datas,dataa
except Exception as e:
print(e)
url='http://www.qiushibaike.com/hot/'
spider=Spider()
ff,dd=spider.start(url)
i=0
cc=''
while cc=='':
print('词条:'+ff[i])
print('本词条的点赞数:'+dd[2*i])
print('本词条的评论数:'+dd[2*i+1])
i=i+1
cc=input()
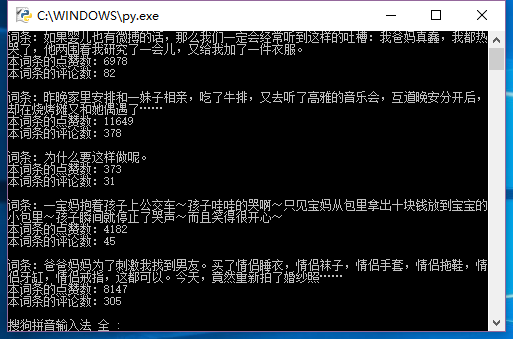
运行结果呢,如下图所示:
希望能和大家多多交流!!!















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









