







 HDFS的Centralized Cache Management特性允许用户强制缓存文件到内存,提高读取效率。文章介绍了如何通过Cache Directive和Cache Pool命令管理缓存,以及开启Short-Circuit Local Reads的重要性。测试表明,开启Short-Circuit特性可显著加速读取,但Centralized Cache Management在特定环境下效果不明显,可能受到内存使用和系统缓存策略的影响。
HDFS的Centralized Cache Management特性允许用户强制缓存文件到内存,提高读取效率。文章介绍了如何通过Cache Directive和Cache Pool命令管理缓存,以及开启Short-Circuit Local Reads的重要性。测试表明,开启Short-Circuit特性可显著加速读取,但Centralized Cache Management在特定环境下效果不明显,可能受到内存使用和系统缓存策略的影响。
-
概述
HDFS作为Hadoop底层存储架构实现,提供了高可容错性,以及较高的吞吐量等特性。在Hadoop 2.3版本里,HDFS提供了一个新特性——Centralized Cache Management。该特性能够让用户显式地把某些HDFS文件强制映射到内存中,防止被操作系统换出内存页,提高内存利用效率,有效加快文件访问速度。对于Hive来说,如果对某些SQL查询里需要经常读取的表格文件进行缓存,通常能够提升运行效率。
-
架构介绍
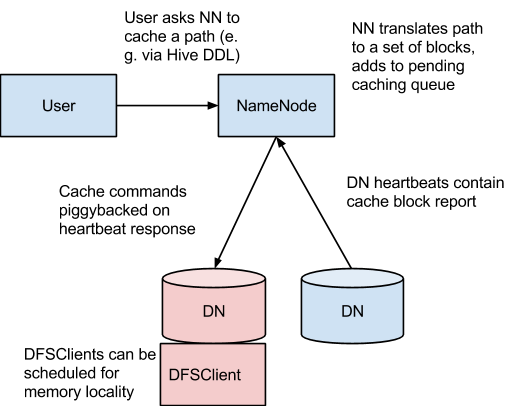
NameNode主要负责协调所有DataNode的堆外内存。DataNode会按照一定的时间间隔通过heartbeat向NameNode汇报所缓存的文件block块记录。NameNode会接收用户缓存或清空某个路径的缓存命令,然后通过heartbeat通知含有对应文件block的DataNode进行缓存。
NameNode提供一个缓存池(cache pools)来方便管理缓存命令(cache directives),缓存命令负责决定具体进行缓存的路径。
目前缓存只能够在文件夹或者文件的粒度进行控制。文件块和子块缓存仍然在计划开发中。
-
缓存命令接口
具体用法和参数意义参见官网介绍,这里只作简单介绍。
Cache directive命令
-
addDirective
添加一个新的cache directive。如: hdfs cacheadmin -addDirective -path <path> -pool <pool-name>
- removeDirective
移除一个cache directive。如:hdfs cacheadmin -removeDirective <id>
-
removeDirectives
移除指定路径的每个cache directive。如:hdfs cacheadmin -removeDirectives <path>
-
listDirectives
列出cache directive。如: hdfs cacheadmin -listDirectives
Cache pool命令
-
addPool
添加新的内存池。如:hdfs cacheadmin -addPool <name>
-
modifyPool
修改缓存池的metadata。如:hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
-
removePool
移除缓存池,同时也会移除在缓存池里的路径。如: hdfs cacheadmin -removePool <name>
-
listPools
显示缓存池信息。如:hdfs cacheadmin -listPools [-stats] [<name>]
-
实践与思考
上面的内容基本从官网简单摘取过来,这节才是本文章的重点,也是真正的干货所在。
首先要注意的是,官网没有说明的一点,要读取到cache到内存的文件block,必须要首先开启Short-Circuit Local Reads特性。该特性简单来说,就是对于在读取文件位于相同节点的时候,能够避免建立TCP socket,直接读取位于磁盘上的文件block。需要注意的是,该特性有两种不同实现方案(HDFS-2246和HDFS-347),其中,HDFS-347是Hadoop 2.x的重新实现方案,并且只有这个方案才可以读取Cache到内存的文件block。
在配置Cache的过程中,由于DataNode需要强制锁定文件映射到内存中,需要设置hdfs-site.xml参数dfs.datanode.max.locked.memory参数(单位bytes)。另外要注意的是通常还需要更改操作系统参数ulimit -l(单位KB),否则DataNode在启动的时候会抛出异常。
为了能够更加深入理解这个特性带来的性能影响,在测试环境下进行了简单的测试。
测试环境是一个有3个节点的小集群。2个NameNode(启用NameNode HA特性),3个DataNode。其中Active NameNode(93)总共有12G内存,8个Intel(R) Xeon(R) CPU 2.50GHz;另外backup NameNode(24)和DataNode(25)均只有4GB内存,4个Intel(R) Xeon(R) CPU 2.00GHz。
为了能够减少干扰,更加清晰地了解该特性带来的性能变化,并且注意到要使用该特性,必须使用一个全新的API来进行读取操作,因此写了一个简单的读HDFS文件的测试程序来测量耗时。
对于一个约400MB大小的HDFS文件,进行读取,得出数据如下:
|
|
Non Short-Circuit(ms)
|
Short-Circuit(ms)
|
|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2743
2743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









