






Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
.jpg")
扫码关注添加客服
进Python社群▲

扫码关注添加客服
进Java社群▲
作者丨小小明
来源丨数据分析与统计学之美
作者:小小明

简介:Pandas数据处理专家,10余年编码经验,至今已帮助过百名以上数据从业人员解决工作实际遇到的问题,其中数据处理和办公自动化问题涉及的行业包括会计、审计、HR、气象工作人员、教师、律师、运营,以及各行业的数据分析师和专做数据分析案例的公众号号主。若你在数据处理的问题上遇到什么困难,欢迎与我交流。
目录
准备数据
Pandas直接保存数据
Pandas的Styler对表格着色输出
Pandas使用xlsxwriter引擎保存数据
xlsxwriter按照指定样式写出Pandas对象的数据
Pandas自适应列宽保存数据
相关资料
总结
准备数据
import pandas as pd
from datetime import datetime, date
df = pd.DataFrame({'Date and time': [datetime(2015, 1, 1, 11, 30, 55),
datetime(2015, 1, 2, 1, 20, 33),
datetime(2015, 1, 3, 11, 10),
datetime(2015, 1, 4, 16, 45, 35),
datetime(2015, 1, 5, 12, 10, 15)],
'Dates only': [date(2015, 2, 1),
date(2015, 2, 2),
date(2015, 2, 3),
date(2015, 2, 4),
date(2015, 2, 5)],
'Numbers': [1010, 2020, 3030, 2020, 1515],
'Percentage': [.1, .2, .33, .25, .5],
})
df['final'] = [f"=C{i}*D{i}" for i in range(2, df.shape[0]+2)]
df结果:
| Date and time | Dates only | Numbers | Percentage | final | |
|---|---|---|---|---|---|
| 0 | 2015/1/1 11:30 | 2015/2/1 | 1010 | 0.1 | =C2*D2 |
| 1 | 2015/1/2 1:20 | 2015/2/2 | 2020 | 0.2 | =C3*D3 |
| 2 | 2015/1/3 11:10 | 2015/2/3 | 3030 | 0.33 | =C4*D4 |
| 3 | 2015/1/4 16:45 | 2015/2/4 | 2020 | 0.25 | =C5*D5 |
| 4 | 2015/1/5 12:10 | 2015/2/5 | 1515 | 0.5 | =C6*D6 |
Pandas直接保存数据
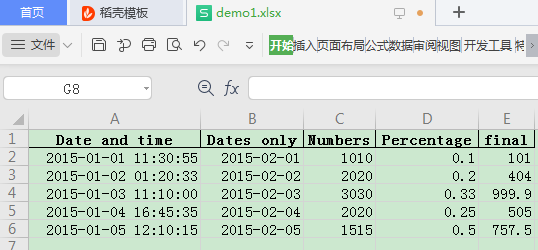
对于这个pandas对象,如果我们需要将其保存为excel,有那些操作方式呢?首先,最简单的,直接保存:
df.to_excel("demo1.xlsx", sheet_name='Sheet1', index=False)效果如下:
但如果我们想要给这个excel在保存时,同时指定一些特殊的自定义格式又该怎么做呢?这时就可以使用ExcelWriter进行操作,查看API文档发现两个重要参数:
date_format : str, default None
Format string for dates written into Excel files (e.g. 'YYYY-MM-DD').
datetime_format : str, default None
Format string for datetime objects written into Excel files. (e.g. 'YYYY-MM-DD HH:MM:SS').
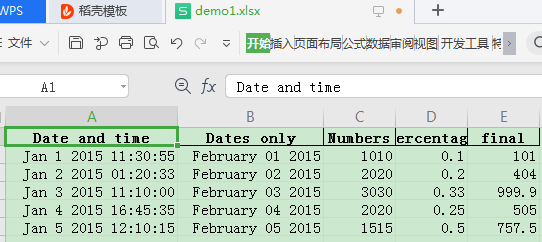
这说明对于日期类型数据,都可以通过这两个参数指定特定的显示格式,那么我们采用以下方式才创建ExcelWriter,并保存结果:
writer = pd.ExcelWriter("demo1.xlsx",
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
df.to_excel(writer, sheet_name='Sheet1', index=False)
writer.save()可以看到excel保存的结果中,格式已经确实的发生了改变:
Pandas的Styler对表格着色输出
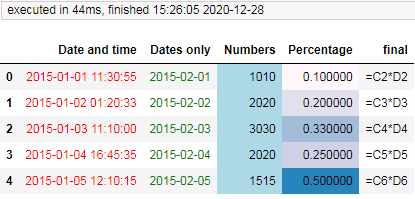
如果我们想对指定的列的数据设置文字颜色或背景色,可以直接pandas.io.formats.style工具,该工具可以直接对指定列用指定的规则着色:
df_style = df.style.applymap(lambda x: 'color:red', subset=["Date and time"]) \
.applymap(lambda x: 'color:green', subset=["Dates only"]) \
.applymap(lambda x: 'background-color:#ADD8E6', subset=["Numbers"]) \
.background_gradient(cmap="PuBu", low=0, high=0.5, subset=["Percentage"])
df_style显示效果:
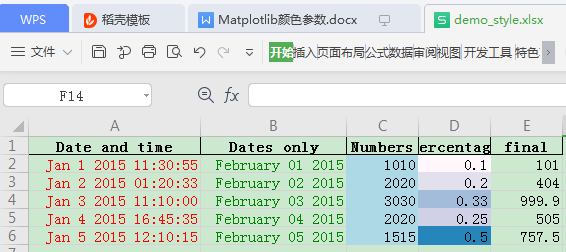
writer = pd.ExcelWriter("demo_style.xlsx",
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
df_style.to_excel(writer, sheet_name='Sheet1', index=False)
writer.save()保存效果:
虽然Pandas的Styler样式还包括设置显示格式、条形图等功能,但写入到excel却无效,所以我们只能借助Pandas的Styler实现作色的功能,而且只能对数据着色,不能对表头作色。
Pandas使用xlsxwriter引擎保存数据
进一步的,我们需要将数值等其他类型的数据也修改一下显示格式,这时就需要从ExcelWriter拿出其中的workbook进行操作:
writer = pd.ExcelWriter("demo1.xlsx")
workbook = writer.book
workbook结果:
<xlsxwriter.workbook.Workbook at 0x52fde10>
从返回的结果可以看到这是一个xlsxwriter对象,说明pandas默认的excel写出引擎是xlsxwriter,即上面的ExcelWriter创建代码其实等价于:
pd.ExcelWriter("demo1.xlsx", engine='xlsxwriter')关于xlsxwriter可以参考官方文档:https://xlsxwriter.readthedocs.org/
下面的代码即可给数值列设置特定的格式:
writer = pd.ExcelWriter("demo1.xlsx",
engine='xlsxwriter',
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
worksheet.set_column('A:A', 19)
worksheet.set_column('B:B', 17)
format1 = workbook.add_format({'num_format': '#,##0.00'})
format2 = workbook.add_format({'num_format': '0%'})
worksheet.set_column('C:C', 8, format1)
worksheet.set_column('D:D', 11, format2)
worksheet.set_column('E:E', 6, format1)
writer.save()效果:
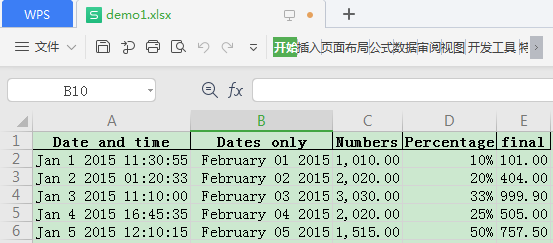
关于set_column方法:

worksheet.set_column('C:C', 8, format1) 表示将C列的列宽设置为8个字符,并采用format1的样式,当然 format1 = workbook.add_format({'num_format': '#,##0.00'}) 就是表示生成一个指定的格式对象。
xlsxwriter按照指定样式写出Pandas对象的数据
假如,我现在希望能够定制excel表头的样式,并给数据添加边框。我翻遍了xlsxwriter的API文档发现,并没有一个可以修改指定范围样式的API,要修改样式只能通过set_column修改列,或者通过set_row修改行,这种形式的修改都是针对整行和整列,对于显示格式还能满足条件,但对于背景色和边框之类的样式就不行了,这点上确实不如openpyxl方便,但xlsxwriter还有个优势,就是写出数据时可以直接指定样式。
下面看看如何直接通过xlsxwriter保存指定样式的数据吧:
import xlsxwriter
workbook = xlsxwriter.Workbook('demo2.xlsx')
worksheet = workbook.add_worksheet('sheet1')
# 创建列名的样式
header_format = workbook.add_format({
'bold': True,
'text_wrap': True,
'valign': 'top',
'fg_color': '#D7E4BC',
'border': 1})
# 从A1单元格开始写出一行数据,指定样式为header_format
worksheet.write_row(0, 0, df.columns, header_format)
# 创建一批样式对象
format1 = workbook.add_format({'border': 1, 'num_format': 'mmm d yyyy hh:mm:ss'})
format2 = workbook.add_format({'border': 1, 'num_format': 'mmmm dd yyyy'})
format3 = workbook.add_format({'border': 1, 'num_format': '#,##0.00'})
format4 = workbook.add_format({'border': 1, 'num_format': '0%'})
# 从第2行(角标从0开始)开始,分别写出每列的数据,并指定特定的样式
worksheet.write_column(1, 0, df.iloc[:, 0], format1)
worksheet.write_column(1, 1, df.iloc[:, 1], format2)
worksheet.write_column(1, 2, df.iloc[:, 2], format3)
worksheet.write_column(1, 3, df.iloc[:, 3], format4)
worksheet.write_column(1, 4, df.iloc[:, 4], format3)
# 设置对应列的列宽,单位是字符长度
worksheet.set_column('A:A', 19)
worksheet.set_column('B:B', 17)
worksheet.set_column('C:C', 8)
worksheet.set_column('D:D', 12)
worksheet.set_column('E:E', 6)
workbook.close()上面的代码应该都比较好理解,header_format和formatN是创建的样式对象,write_row用于按行写出数据,write_column用于按列写出数据,set_column则是用于设置整列的列宽和样式(没传入的不设置)。
运行结果如下:
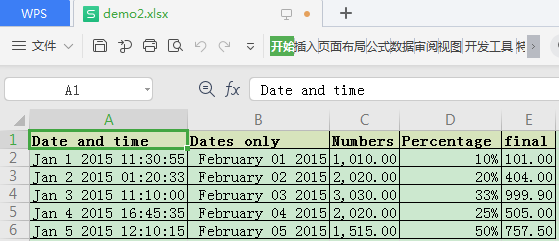
Pandas使用openpyxl引擎保存数据
pandas的默认写出引擎是xlsxwriter,那么是不是可以修改为其他引擎呢?答案是可以,下面我们使用 openpyxl 实现同样的效果。
关于openpyxl可参考:https://openpyxl.readthedocs.org/
也可以直接参考黄同学编写的文档(中文,相对也比较全面):https://blog.csdn.net/weixin_41261833/article/details/106028038
writer = pd.ExcelWriter("demo3.xlsx",
engine='openpyxl',
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
workbook结果:
<openpyxl.workbook.workbook.Workbook at 0x16c6bb70>
从上述打印结果可以看到,从engine指定为'openpyxl'后,workbook已经是 openpyxl 对象了。
与 xlsxwriter 不同的是 openpyxl 只能对逐个单元格设置样式,而xlsxwriter只能指定行或指定列或写入数据指定样式。
下面首先修改表头的样式:
import itertools
from openpyxl.styles import Alignment, Font, PatternFill, Border, Side, PatternFill
font = Font(name="微软雅黑", bold=True)
alignment = Alignment(vertical="top", wrap_text=True)
pattern_fill = PatternFill(fill_type="solid", fgColor="D7E4BC")
side = Side(style="thin")
border = Border(left=side, right=side, top=side, bottom=side)
for cell in itertools.chain(*worksheet["A1:E1"]):
cell.font = font
cell.alignment = alignment
cell.fill = pattern_fill
cell.border = border上述代码引入的了itertools.chain方便迭代出每个单元格,而不用写多重for循环。
下面再修改数值列的格式:
for cell in itertools.chain(*worksheet["A2:E6"]):
cell.border = border
for cell in itertools.chain(*worksheet["C2:C6"], *worksheet["E2:E6"]):
cell.number_format = '#,##0.00'
for cell in itertools.chain(*worksheet["D2:D6"]):
cell.number_format = '0%'最后给各列设置一下列宽:
worksheet.column_dimensions["A"].width = 20
worksheet.column_dimensions["B"].width = 17
worksheet.column_dimensions["C"].width = 10
worksheet.column_dimensions["D"].width = 12
worksheet.column_dimensions["E"].width = 8最后保存即可:
writer.save()整体完整代码:
from openpyxl.styles import Alignment, Font, PatternFill, Border, Side, PatternFill
import itertools
writer = pd.ExcelWriter("demo3.xlsx",
engine='openpyxl',
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
font = Font(name="微软雅黑", bold=True)
alignment = Alignment(vertical="top", wrap_text=True)
pattern_fill = PatternFill(fill_type="solid", fgColor="D7E4BC")
side = Side(style="thin")
border = Border(left=side, right=side, top=side, bottom=side)
for cell in itertools.chain(*worksheet["A1:E1"]):
cell.font = font
cell.alignment = alignment
cell.fill = pattern_fill
cell.border = border
for cell in itertools.chain(*worksheet["A2:E6"]):
cell.border = border
for cell in itertools.chain(*worksheet["C2:C6"], *worksheet["E2:E6"]):
cell.number_format = '#,##0.00'
for cell in itertools.chain(*worksheet["D2:D6"]):
cell.number_format = '0%'
worksheet.column_dimensions["A"].width = 20
worksheet.column_dimensions["B"].width = 17
worksheet.column_dimensions["C"].width = 10
worksheet.column_dimensions["D"].width = 12
worksheet.column_dimensions["E"].width = 8
writer.save()最终效果:
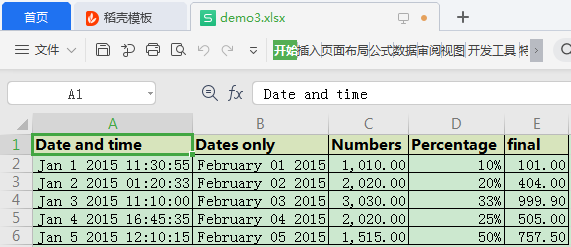
从上述代码可以看到,openpyxl 修改样式时相对xlsxwriter来说麻烦了太多,特别是修改一个表头就需要创建5个对象。
openpyxl加载数据模板写出Pandas对象的数据
虽然 openpyxl 直接写出数据指定样式相对xlsxwriter麻烦,但 openpyxl 还有个巨大的优势就是可以读取已有的excel文件,在其基础上修改。
那我们就完全可以先将模板数据写入到一个excel,然后加载这个模板文件进行修改,所以上面那个固定不变的表头,我们就可以事先创建好:
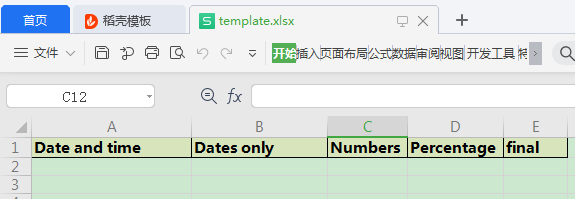
然后加载模板,再写入:
(经测试ExcelWriter无法对已经存在的工作表进行操作,会创建新的工作表,所以这里直接使用openpyxl自己的API)
from openpyxl import load_workbook
workbook = load_workbook('template.xlsx')
worksheet = workbook["Sheet1"]
# 添加数据列,i表示当前的行号,用于后续格式设置
for i, row in enumerate(df.values, 2):
worksheet.append(row.tolist())
# 批量修改给写入的数据的单元格范围加边框
side = Side(style="thin")
border = Border(left=side, right=side, top=side, bottom=side)
for cell in itertools.chain(*worksheet[f"A2:E{i}"]):
cell.border = border
# 批量给各列设置指定的自定义格式
for cell in itertools.chain(*worksheet[f"A2:A{i}"]):
cell.number_format = 'mmm d yyyy hh:mm:ss'
for cell in itertools.chain(*worksheet[f"B2:B{i}"]):
cell.number_format = 'mmmm dd yyyy'
for cell in itertools.chain(*worksheet[f"C2:C{i}"], *worksheet[f"E2:E{i}"]):
cell.number_format = '#,##0.00'
for cell in itertools.chain(*worksheet[f"D2:D{i}"]):
cell.number_format = '0%'
workbook.save(filename="demo4.xlsx")最终效果:
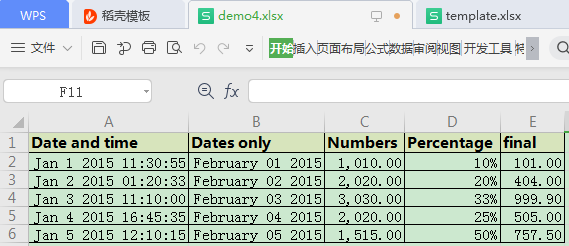
可以明显的看到openpyxl在加载模板后,可以省掉表头设置和列宽设置的代码。
Pandas自适应列宽保存数据
大多数时候我们并不需要设置自定义样式,也不需要写出公式字符串,而是直接写出最终的结果文本,这时我们就可以使用pandas计算一下各列的列宽再保存excel数据。
例如我们有如下数据:
df = pd.DataFrame({
'Region': ['East', 'East', 'South', 'North', 'West', 'South', 'North', 'West', 'West', 'South', 'West', 'South'],
'Item': ['Apple', 'Apple', 'Orange', 'Apple', 'Apple', 'Pear', 'Pear', 'Orange', 'Grape', 'Pear', 'Grape',
'Orange'],
'Volume': [9000, 5000, 9000, 2000, 9000, 7000, 9000, 1000, 1000, 10000, 6000, 3000],
'Month': ['July', 'July', 'September', 'November', 'November', 'October', 'August', 'December', 'November', 'April',
'January', 'May']
})
df
结果:
| Region | Item | Volume | Month | |
|---|---|---|---|---|
| 0 | East | Apple | 9000 | July |
| 1 | East | Apple | 5000 | July |
| 2 | South | Orange | 9000 | September |
| 3 | North | Apple | 2000 | November |
| 4 | West | Apple | 9000 | November |
| 5 | South | Pear | 7000 | October |
| 6 | North | Pear | 9000 | August |
| 7 | West | Orange | 1000 | December |
| 8 | West | Grape | 1000 | November |
| 9 | South | Pear | 10000 | April |
| 10 | West | Grape | 6000 | January |
| 11 | South | Orange | 3000 | May |
使用pandas来进行计算各列列宽,思路是计算出每列的字符串gbk编码(Windows下的Excel软件默认使用gbk编码)后的最大字节长度:
# 计算表头的字符宽度
column_widths = (
df.columns.to_series()
.apply(lambda x: len(x.encode('gbk'))).values
)
# 计算每列的最大字符宽度
max_widths = (
df.astype(str)
.applymap(lambda x: len(x.encode('gbk')))
.agg(max).values
)
# 计算整体最大宽度
widths = np.max([column_widths, max_widths], axis=0)
widths
结果:
array([6, 6, 6, 9], dtype=int64)
下面将改造一下前面的代码。
首先,使用xlsxwriter引擎自适应列宽保存数据:
writer = pd.ExcelWriter("auto_column_width1.xlsx", engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1', index=False)
worksheet = writer.sheets['Sheet1']
for i, width in enumerate(widths):
worksheet.set_column(i, i, width)
writer.save()
然后,使用openpyxl引擎自适应列宽保存数据(openpyxl引擎设置字符宽度时会缩水0.5左右个字符,所以干脆+1):
from openpyxl.utils import get_column_letter
writer = pd.ExcelWriter("auto_column_width2.xlsx", engine='openpyxl')
df.to_excel(writer, sheet_name='Sheet1', index=False)
worksheet = writer.sheets['Sheet1']
for i, width in enumerate(widths, 1):
worksheet.column_dimensions[get_column_letter(i)].width = width+1
writer.save()
结果:
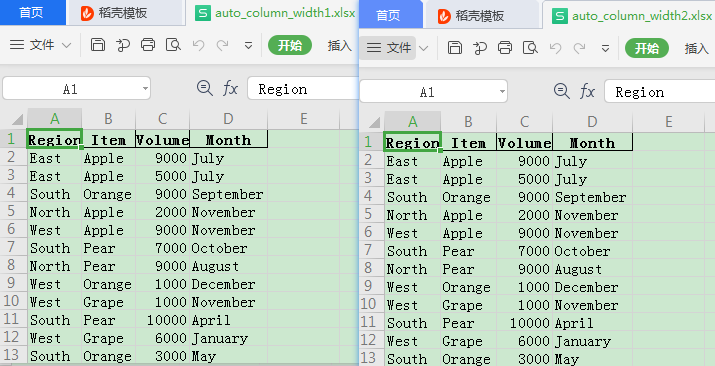
可以看到列宽设置的都比较准确。
相关资料
1. python读写Excel文件的那些库
来源:http://www.python-excel.org/
openpyxl
读取和写入EXCEL2010文件的包(即.xlsx)
文档:https://openpyxl.readthedocs.org/
xlsxwriter
拥有丰富的特性,支持图片/表格/图表/筛选/格式/公式等,功能与openpyxl相似,优点是相比 openpyxl 还支持 VBA 文件导入,迷你图等功能,缺点是不能打开/修改已有文件,意味着使用 xlsxwriter 需要从零开始。支持EXCEL2010文件(即.xlsx) 文档:https://xlsxwriter.readthedocs.org/GitHub:https://github.com/jmcnamara/XlsxWriter
pyxlsb
专门用于读取 xlsb格式的excel文件 GitHub:https://github.com/willtrnr/pyxlsb
pylightxl
用于读取xlsx 和xlsm格式的excel文件,或写入xlsx格式的excel文件 文档:https://pylightxl.readthedocs.io/en/latest/GitHub:https://github.com/PydPiper/pylightxl
xlrd
用于读取xls格式的excel文件的库 文档:http://xlrd.readthedocs.io/en/latest/GitHub:https://github.com/python-excel/xlrd
xlwt
用于写入xls格式的excel文件的库 文档:http://xlwt.readthedocs.io/en/latest/Examples:https://github.com/python-excel/xlwt/tree/master/examplesGitHub:https://github.com/python-excel/xlwt
xlutils
用于配合xlrd和xlwt的工具库,包括样式的复制 文档:http://xlutils.readthedocs.io/en/latest/GitHub:https://github.com/python-excel/xlutils
必须安装 Microsoft Excel应用程序后才能使用的库:
xlwings
xlwings是开源,用Python替代VBA自动化操作Excel,同时支持Windows和MacOS。在Windows平台下,通过xlwings在Python中编写UDF可以实现在Excel中调用Python。xlwings PRO是一个具有附加功能的商业插件。
主页:https://www.xlwings.org/文档:https://docs.xlwings.org/en/stable/GitHub:https://github.com/xlwings/xlwings
2. Excel单元格自定义格式参数含义
一、代码结构组
代码结构组成分为四个部分,中间用";"号分隔,具体如下:正数格式;负数格式;零格式;文本格式
二、各个参数的含义
1、"G/通用格式":以常规的数字显示,相当于"分类"列表中的"常规"选项。
G/通用格式10显示为10;10.1显示为10.1。
2、"0":数字占位符。如果单元格的内容大于占位符,则显示实际数字,如果小于点位符的数量,则用0补足。
000001234567显示为1234567;123显示为00123
00.000100.14显示为100.140;1.1显示为01.100
0000-00-0020050512显示为2005-05-12
3、"#":数字占位符。只显有意义的零而不显示无意义的零。小数点后数字如大于"#"的数量,则按"#"的位数四舍五入。
###.##12.1显示为12.10;12.1263显示为12.13
4、"?":数字占位符。在小数点两边为无意义的零添加空格,对齐结果为以小数点对齐,另外还用于对不等到长数字的分数。
??.??结果自动以小数点对齐:
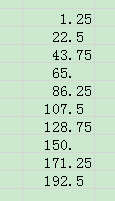
#??/??原数据:
1.25
22.5
43.75
65展示效果:
5/4
45/2
175/4
65/1 5、".":小数点。如果外加双引号则为字符。
0.#11.23显示为11.2
6、"%":百分比。
#%0.1显示为10%
7、",":千位分隔符。数字使用千位分隔符。如在代码中","后空,则把原来的数字缩小1000倍。
#,###"10000"显示为"10,000"
#,"10000"显示为"10"
#,,"1000000"显示为"1"
8、"@":文本占位符。如果只使用单个@,作用是引用原始文本,要在输入数字数据之前自动添加文本,使用自定义格式为:"文本内容"@;要在输入数字数据之后自动添加文本,使用自定义格式为:@"文本内容"。@符号的位置决定了Excel输入的数字数据相对于添加文本的位置。如果使用多个@,则可以重复文本。
"集团"@"部"财务 显示为:集团财务部
@@@财务 显示为:财务财务财务
9、*:重复下一次字符,直到充满列宽。
@*-"ABC"显示为"ABC-------------------"(仅在office中生效,wps中无效果)
10、[颜色]:用指定的颜色显示字符。可有八种颜色可选:红色、黑色、黄色,绿色、白色、兰色、青色和洋红。
[青色];[红色];[黄色];[兰色]显示结果为正数为青色,负数显示红色,零显示黄色,文本则显示为兰色
11、[颜色N]:是调用调色板中颜色,N是0~56之间的整数。
[颜色3]单元格显示的颜色为调色板上第3种颜色。
12、[条件]:可以单元格内容判断后再设置格式。条件格式化只限于使用三个条件,其中两个条件是明确的,另个是"所有的其他"。条件要放到方括号中。必须进行简单的比较。
[>0]"正数";[=0]"零";"负数"13、"!":显示"""。由于引号是代码常用的符号。在单元格中是无法用"""来显示出来"""。要想显示出来,须在前加入"!"
#!""10"显示"10""
#!"!""10"显示"10"""
14、时间和日期代码
"YYYY"或"YY":按四位(1900~9999)或两位(00~99)显示年;
"MM"或"M":以两位(01~12)或一位(1~12)表示月;
"DD"或"D":以两位(01~31)或一位(1-31)来表示天;
"YYYY-MM-DD"。2005年1月10日显示为:"2005-01-10";
"YY-M-D"。2005年10月10日显示为:"05-1-10";
"AAAA":日期显示为星期;
"H"或"HH":以一位(0~23)或两位(01~23)显示小时;
"M"或"MM":以一位(0~59)或两位(01~59)显示分钟;
"S"或"SS":以一位(0~59)或两位(01~59)显示秒;
"HH:MM:SS":"23:1:15"显示为"23:01:15";
总结
经过上面的演示,大家应该对openpyxl和xlsxwriter都有了一个比较直观的认知,这两个库大家觉得到底哪个更方便呢?
欢迎在下方留言或讨论。

程序员专栏 扫码关注填加客服 长按识别下方二维码进群

近期精彩内容推荐:



在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









