







在开始讲解PySpark程序启动原理之前,我们先来了解一下Spark的一些概念和特性。
1. Spark的核心概念
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。例如一次排序测试中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛。
2. Spark 的特性
Hadoop 的核心是分布式文件系统 HDFS 和计算框架 MapReduces。Spark 可以替代 MapReduce,并且兼容 HDFS、Hive 等分布式存储层,良好的融入 Hadoop 的生态系统。
Spark 执行的特点
中间结果输出:Spark 将执行工作流抽象为通用的有向无环图执行计划(DAG),可以将多 Stage 的任务串联或者并行执行。
数据格式和内存布局:Spark 抽象出分布式内存存储结构弹性分布式数据集 RDD,能够控制数据在不同节点的分区,用户可以自定义分区策略。
任务调度的开销:Spark 采用了事件驱动的类库 AKKA 来启动任务,通过线程池的复用线程来避免系统启动和切换开销。
Spark 的优势
速度快,运行工作负载快 100 倍。Apache Spark 使用最先进的 DAG 调度器、查询优化器和物理执行引擎,实现了批处理和流数据的高性能。
易于使用,支持用 Java、Scala、Python、R 和 SQL 快速编写应用程序。Spark 提供了超过 80 个算子,可以轻松构建并行应用程序。您可以从 Scala、Python、R 和 SQL shell 中交互式地使用它。
普遍性,结合 SQL、流处理和复杂分析。Spark 提供了大量的库,包括 SQL 和 DataFrames、用于机器学习的 MLlib、GraphX 和 Spark 流。您可以在同一个应用程序中无缝地组合这些库。
各种环境都可以运行,Spark 在 Hadoop、Apache Mesos、Kubernetes、单机或云主机中运行。它可以访问不同的数据源。您可以使用它的独立集群模式在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和数百个其他数据源中的数据。
3. Spark分布式运行架构
Spark程序简单来说它的分布式运行架构,大致上是把任务发布到Driver端,然后Spark解析调度并封装成一个个的小Task,分发到每一个Executor上面去run,Task包含计算逻辑、数据等等,基础架构以及执行顺序如下两图:
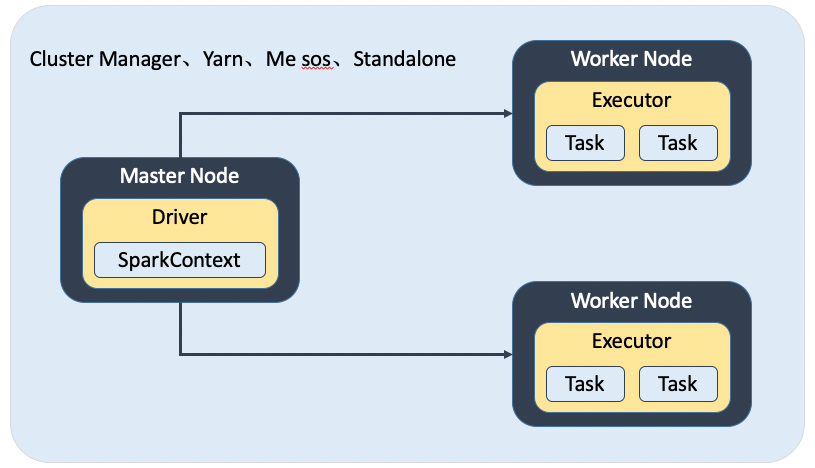
图来自:https://www.cnblogs.com/xia520pi/p/8695141.html
4. Spark任务调度分析
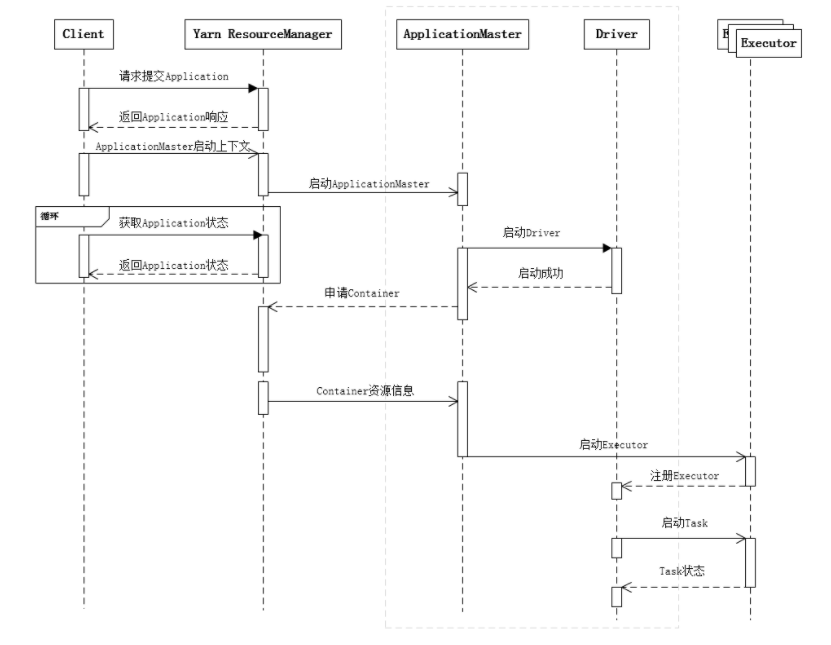
Spark拿到我们的一个任务,是会先发布到Driver端,Driver端拆分任务逻辑放入不同的Task,若干个Task组成一个Task Set,根据Executor资源情况分配任务。大概的逻辑是上面这样子的,不过,我们在看YARN日志的时候,经常性地会看到Job、Stage、Task,它们的关系是怎么样的呢?可以看下图:
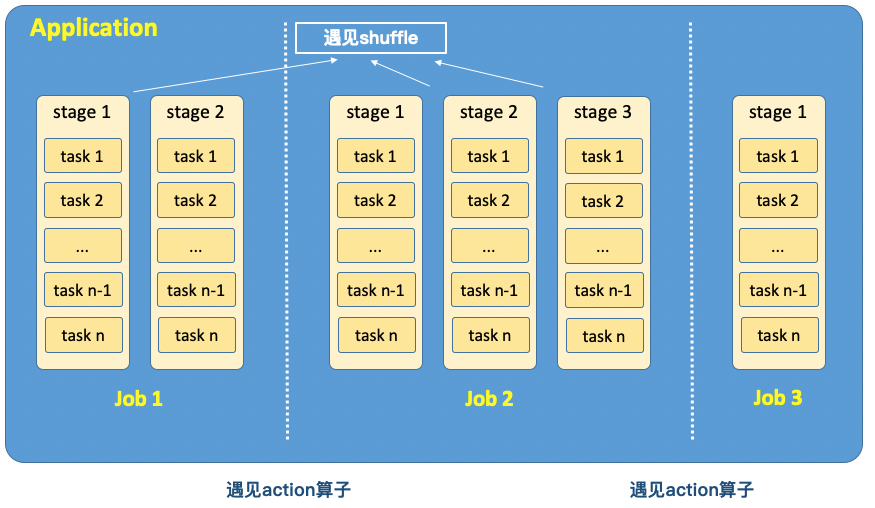
简单来说,Job包含Stage,Stage包含Task,其中Job的划分看Action,Stage划分看Shuffle。我们来复习下常用RDD算子,如下图:

这里敲黑板划重点:
1、Action算子:collect、collectAsMap、reduce、countByKey、take、first等。
2、Shuffle操作:Shuffle指的是数据从Map Task输出到Reduce Task的过程,作为连接Map和Reduce两端的桥梁。它需要把Map端不同Task的数据都拉取到一个Reduce Task,十分消耗IO和内存。Shuffle操作可以分为Map端的数据准备和Reduce端的数据拷贝,称之为Shuffle Write和Shuffle read。而rdd宽依赖操作就会引起Shuffle过程。
3、常见的宽依赖(Wide Dependencies)操作有:reduceByKey、groupBykey、join、
4、常见的窄依赖(Narrow Dependencies)操作有:map、filter、flatMap、union等
5、哪里并行?我们常说的并行指的是同一个Stage内并行,Stage之间是存在依赖关系的,属于串行操作。
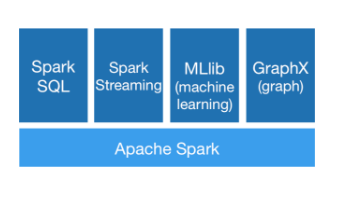
5. Spark 生态系统 —— BDAS
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。其核心框架是 Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库 MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。
6. PySpark与Spark的关系
Spark支持很多语言的调用,包括了Java、Scala、Python等,其中用Python语言编写的Spark API就是PySpark。它在Spark最外层封装了一层Python API,借助了Py4j来实现Spark底层API的调用,从而可以实现实现我们直接编写Python脚本即可调用Spark强大的分布式计算能力。
7. PySpark分布式运行架构
与Spark分布式运行架构一致,不过就是外围多了一层Python API。用户通过实例化Python的SparkContext对象,接着Py4j会把Python脚本映射到JVM中,同样地实例化一个Scala的SparkContext对象,然后Driver端发送Task任务到Executor端去执行,因为Task任务中可能会包含一些Python的函数,所以每一个Task都是需要开启一个Python进程,通过Socket通信方式将相关的Python函数部分发送到Python进程去执行。

综上所述,PySpark是借助于Py4j实现了Python调用Java从而来驱动Spark程序的运行,这样子可以保证了Spark核心代码的独立性,但是在大数据场景下,如果代码中存在频繁进行数据通信的操作,这样子JVM和Python进程就会频繁交互,可能会导致我们的任务失败。所以,如果面对大规模数据还是需要我们使用原生的API来编写程序(Java或者Scala)。但是对于中小规模的,比如TB数据量以下的,直接使用PySpark来开发还是很爽的。
8. 程序启动步骤实操
一般我们在生产中提交PySpark程序,都是通过spark-submit的方式提供脚本的,也就是一个shell脚本,配置各种Spark的资源参数和运行脚本信息,和py脚本一并提交到调度平台进行任务运行,其中shell脚本模版如下:
#!/bin/bash
basePath=$(cd "$(dirname )"$(cd "$(dirname "$0"): pwd)")": pwd)
spark-submit \
--master yarn \
--queue samshare \
--deploy-mode client \
--num-executors 100 \
--executor-memory 4G \
--executor-cores 4 \
--driver-memory 2G \
--driver-cores 2 \
--conf spark.default.parallelism=1000 \
--conf spark.yarn.executor.memoryOverhead=8G \
--conf spark.sql.shuffle.partitions=1000 \
--conf spark.network.timeout=1200 \
--conf spark.python.worker.memory=64m \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.crossJoin.enabled=True \
--conf spark.dynamicAllocation.enabled=True \
--conf spark.shuffle.service.enabled=True \
--conf spark.scheduler.listenerbus.eventqueue.size=100000 \
--conf spark.pyspark.driver.python=python3 \
--conf spark.pyspark.python=python3 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=python3 \
--conf spark.sql.pivotMaxValues=500000 \
--conf spark.hadoop.hive.exec.dynamic.partition=True \
--conf spark.hadoop.hive.exec.dynamic.partition.mode=nonstrict \
--conf spark.hadoop.hive.exec.max.dynamic.partitions.pernode=100000 \
--conf spark.hadoop.hive.exec.max.dynamic.partitions=100000 \
--conf spark.hadoop.hive.exec.max.created.files=100000 \
${bashPath}/project_name/main.py $v_var1 $v_var2有的时候,我们想直接通过PySpark调用SQL脚本,那么可以通过spark-sql命令启动,shell脚本就可以这样子写:
#!/bin/bash
echo "依次打印:v_yesterday,v_2days_ago"
echo $v_yesterday
echo $v_2days_ago
V_SCRIPT_PATH=$(dirname $0);
V_PROC_NAME=main.sql;
spark-sql \
--name yourappname \
--master yarn \
--queue samshare \
--deploy-mode client \
--num-executors 50 \
--executor-memory 8G \
--executor-cores 2 \
--driver-cores 1 \
--driver-memory 16G \
--conf spark.default.parallelism=400 \
--conf spark.rpc.message.maxSize=1024 \
--conf spark.sql.shuffle.partitions=400\
--conf spark.sql.autoBroadcastJoinThreshold=314572800\
--conf spark.hadoop.hive.exec.dynamic.partition=true \
--conf spark.hadoop.hive.exec.dynamic.partition.mode=nonstrict \
--hiveconf v_yesterday=${v_yesterday} \
--hiveconf v_2days_ago=${v_2days_ago} \
-f ${V_SCRIPT_PATH}/${V_PROC_NAME}我们在main函数里,也就主程序中要怎么启动PySpark呢?可以通过下面的方式:
# -*- coding: utf-8 -*-
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import HiveContext
from pyspark.sql.functions import col, lit, udf
from pyspark.sql.types import StringType, MapType
import pandas as pd
conf = SparkConf() \
.setAppName("your_appname") \
.set("hive.exec.dynamic.partition.mode", "nonstrict")
sc = SparkContext(conf=conf)
hc = HiveContext(sc)
"""
your code
"""最后,如果数据结果需要保存下来,我们假设是保存到Hive,那么可以参考下面两种方式:
# 方式1: 结果为Python DataFrame
result_df = pd.DataFrame([1,2,3], columns=['a'])
save_table = "tmp.samshare_pyspark_savedata"
# 获取DataFrame的schema
c1 = list(result_df.columns)
# 转为SparkDataFrame
result = hc.createDataFrame(result_df.astype(str), c1)
result.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
# 方式2: 结果为SparkDataFrame
list_values = [['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]]
Spark_df = spark.createDataFrame(list_values, ['name', 'age', 'score'])
print(Spark_df.show())
save_table = "tmp.samshare_pyspark_savedata"
# 方式2.1: 直接写入到Hive
Spark_df.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
# 方式2.2: 注册为临时表,使用SparkSQL来写入分区表
Spark_df.createOrReplaceTempView("tmp_table")
write_sql = """
insert overwrite table {0} partitions (pt_date='{1}')
select * from tmp_table
""".format(save_table, "20210520")
hc.sql(write_sql)
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)Reference
PySpark 的背后原理 https://www.cnblogs.com/xia520pi/p/8695652.html
Spark Scheduler内部原理剖析 https://www.cnblogs.com/xia520pi/p/8695141.html
Spark大数据实战课程——实验楼
















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









